在 機器學習 Studio 中建立您的第一個數據科學實驗(傳統版)
適用於: 機器學習 Studio(傳統版)
機器學習 Studio(傳統版) Azure 機器學習
Azure 機器學習
重要
Machine Learning 工作室 (傳統) 的支援將於 2024 年 8 月 31 日結束。 建議您在該日期之前轉換成 Azure Machine Learning。
自 2021 年 12 月 1 日起,您將無法建立新的 Machine Learning 工作室 (傳統) 資源。 在 2024 年 8 月 31 日之前,您可以繼續使用現有的 Machine Learning 工作室 (傳統) 資源。
ML 工作室 (傳統) 文件即將淘汰,未來將不再更新。
在本文中,您會在 機器學習 Studio 中建立機器學習實驗,以根據不同變數預測汽車的價格,例如製造和技術規格。
如果您不熟悉機器學習,適用於初學者的影片系列 資料科學 是使用日常語言和概念進行機器學習的絕佳簡介。
本快速入門會遵循實驗的預設工作流程:
取得資料
機器學習服務中您需要的第一件事是數據。 有數個範例數據集隨附於 Studio(傳統版),您可以使用,也可以從許多來源匯入數據。 在此範例中,我們將使用工作區中包含的範例數據集 汽車價格數據(Raw)。。 此數據集包含各種個別汽車的專案,包括製造、型號、技術規格和價格等資訊。
提示
您可以在 Azure AI 資源庫中找到下列實驗的工作複本。 移至您的第一個數據科學實驗 - 汽車價格預測,然後按兩下 [在 Studio 中開啟],將實驗複本下載到您的 機器學習 Studio (傳統) 工作區。
以下是如何將數據集放入實驗中。
按兩下 [機器學習 Studio (傳統) 視窗底部的 [+新增],以建立新的實驗。 選取 [實驗>空白實驗]。
實驗會提供您在畫布頂端看到的預設名稱。 選取此文字,並將其重新命名為有意義的內容,例如 汽車價格預測。 此名稱不必是唯一的。
實驗畫布左側是數據集和模組的調色盤。 在此調色盤頂端的 [搜尋] 方塊中輸入 汽車 ,以尋找標示為 汽車價格數據 (Raw) 的數據集。 將此數據集拖曳至實驗畫布。
若要查看此數據的外觀,請按兩下汽車資料集底部的輸出埠,然後選取[ 可視化]。
![按一下輸出埠,然後選取[可視化]](media/create-experiment/select-visualize.png)
提示
數據集和模組具有以小圓圈表示的輸入和輸出埠 - 頂端的輸入埠、底部的輸出埠。 若要透過實驗建立數據流,您將將某個模組的輸出埠連接到另一個模組的輸入埠。 您可以隨時按兩下資料集或模組的輸出埠,以查看資料流中該點的數據外觀。
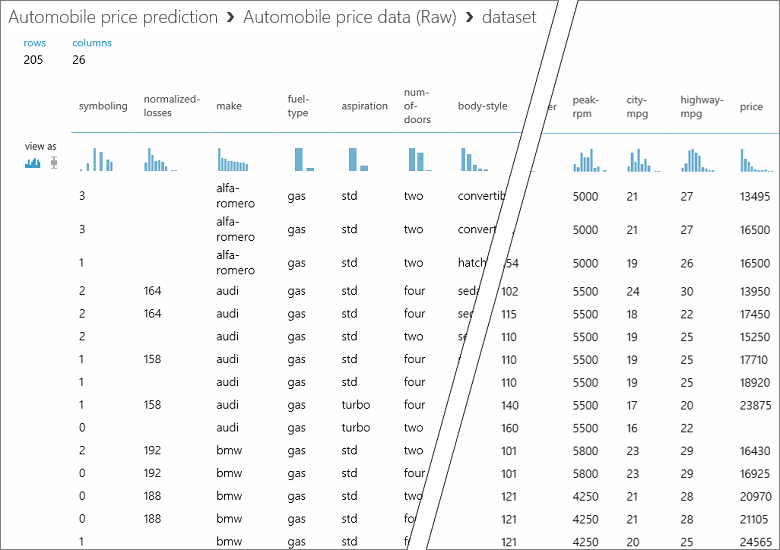
在此數據集中,每個數據列都代表汽車,而與每個汽車相關聯的變數會顯示為數據行。 我們將使用特定汽車的變數來預測極右數據行(標題為「價格」的數據行 26 的價格。
按兩下右上角的 x 以關閉視覺效果視窗。
準備資料
數據集通常需要一些前置處理,才能進行分析。 您可能已經注意到各種數據列數據行中有遺漏的值。 必須清除這些遺漏值,模型才能正確分析數據。 我們將移除任何遺漏值的數據列。 此外, 標準化損失數據 行有大量的遺漏值,因此我們會從模型中排除該數據行。
提示
清除輸入數據中的遺漏值是使用大部分模組的必要條件。
首先,我們會新增模組,以完全移除 標準化損失數據 行。 然後,我們新增另一個模組,以移除任何遺失數據的數據列。
在模組選擇區頂端的搜尋方塊中輸入 選取 數據行,以尋找 [ 選取數據集 中的數據行] 模組。 然後將牠拖曳至實驗畫布。 此課程模組可讓我們選取要在模型中包含或排除的數據行。
將汽車價格數據的輸出埠 (Raw) 資料集連接到選取資料集中的數據行的輸入埠。
![將 [選取數據集中的數據行] 模組新增至實驗畫布並加以連線](media/create-experiment/type-select-columns.png)
按兩下 [選取資料集中的數據行] 模組,然後按下 [屬性] 窗格中的 [啟動數據行選取器]。
點選左方的 [ 使用規則]
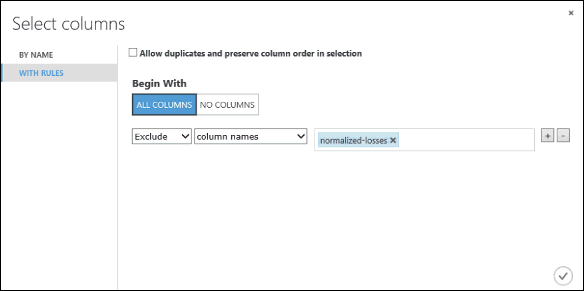
在 [開頭為] 底下,按兩下 [所有數據行]。 這些規則會引導 選取數據集 中的數據行,以傳遞所有數據行(但我們將排除的那些數據行除外)。
從下拉式清單中,選取 [ 排除 ] 和 [資料行名稱],然後按下文字框中。 隨即顯示資料列清單。 選取 標準化損失,並將其新增至文本框。
按兩下複選標記 (確定) 按鈕,關閉資料行選取器(右下角)。
現在,[選取數據集中的數據行] 的屬性窗格表示,除了正規化損失之外,它會通過數據集中的所有數據行。
![[屬性] 窗格顯示已排除 「正規化損失」數據行](media/create-experiment/showing-excluded-column.png)
提示
您可以按兩下模組並輸入文字,將批註新增至模組。 這可協助您一目了然地查看模組在實驗中執行的動作。 在此情況下,按兩下 [ 選取數據集 中的數據行] 模組,然後輸入批注「排除標準化損失」。
將 [清除遺漏的數據] 模組拖曳至實驗畫布,並將它 連接到 [選取數據集 中的數據行] 模組。 在 [屬性] 窗格中,選取 [清除模式] 底下的 [移除整個數據列]。 這些選項會指示 清除遺漏的數據 ,藉由移除具有任何遺漏值的數據列來清除數據。 按兩下模組並輸入批注「移除遺漏的值數據列」。
![將清除模式設定為 [清除遺漏的數據] 模組的 [移除整個數據列]](media/create-experiment/set-remove-entire-row.png)
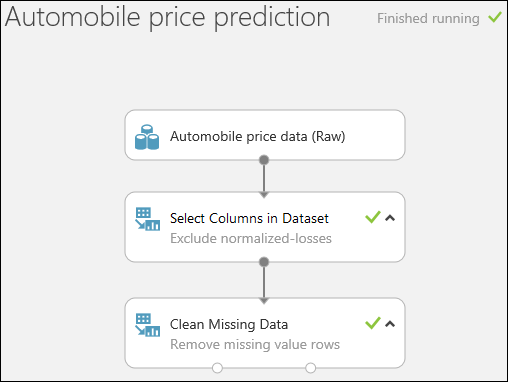
按兩下 頁面底部的 [執行] ,以執行實驗。
當實驗完成執行時,所有模組都有綠色複選標記,表示它們已順利完成。 另請注意 右上角的已完成執行 狀態。
提示
為什麼我們現在執行實驗? 藉由執行實驗,我們的數據的數據行定義會從數據集傳遞、透過 選取數據集 中的數據行模組,以及透過 清除遺漏的數據 模組。 這表示我們連線到 清除遺漏數據 的任何模組也會有相同的資訊。
現在我們有乾淨的數據。 如果您想要檢視已清除的數據集,請單擊清除遺漏數據模組的左側輸出埠,然後選取 [可視化]。 請注意, 已不再包含正規化損失數據 行,而且沒有遺漏值。
既然數據已經乾淨,我們就可以指定要在預測模型中使用哪些功能。
定義功能
在機器學習中, 功能 是您感興趣的個別可測量屬性。 在我們的數據集中,每個數據列都代表一輛汽車,而每個數據行都是該汽車的功能。
尋找一組適合用來建立預測模型的功能,需要實驗和您想要解決的問題知識。 某些功能比其他功能更適合用來預測目標。 某些功能與其他功能具有很強的相互關聯性,而且可以移除。 例如,city-mpg 和 highway-mpg 密切相關,因此我們可以保留一個並移除另一個,而不會大幅影響預測。
讓我們建置使用數據集中功能子集的模型。 您可以稍後回來並選取不同的功能、再次執行實驗,並查看您是否取得更好的結果。 但若要開始,讓我們嘗試下列功能:
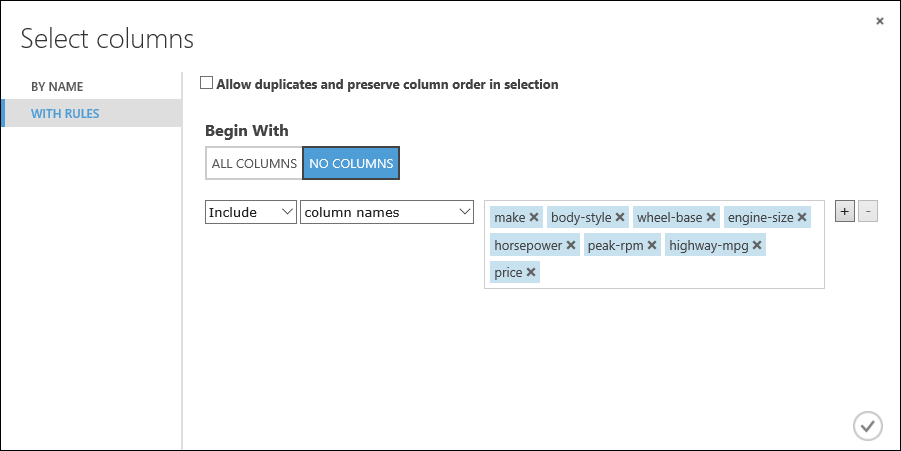
make, body-style, wheel-base, engine-size, horsepower, peak-rpm, highway-mpg, price
將另一個 選取數據集 中的數據行模組拖曳至實驗畫布。 將清除遺漏數據模組的左側輸出埠連接到選取數據集中的數據行模組的輸入。
按兩下模組,然後輸入「選取要預測的功能」。
按兩下 [屬性] 窗格中的 [啟動資料行選取器]。
按兩下 [ 使用規則]。
在 [開頭為] 底下,按兩下 [無數據行]。 在篩選資料列中,選取 [包含 ] 和 [資料行名稱 ],然後選取文字框中的數據行名稱清單。 此篩選會指示模組不會通過我們指定的數據行以外的任何數據行(功能)。
按下複選標記 (確定) 按鈕。
此課程模組會產生篩選的數據集,其中只包含我們想要傳遞至我們將在下一個步驟中使用的學習演算法的功能。 稍後,您可以使用不同的功能選擇來傳回並再試一次。
選擇並套用演算法
現在數據已就緒,建構預測模型是由定型和測試所組成。 我們將使用我們的數據來定型模型,然後測試模型,以查看其能夠預測價格的方式。
分類 和 回歸 是兩種類型的受監督機器學習演算法。 分類會從一組定義的類別預測答案,例如色彩(紅色、藍色或綠色)。 回歸是用來預測數位。
由於我們想要預測價格,也就是數位,因此我們將使用回歸演算法。 在此範例中,我們將使用 線性回歸 模型。
我們會提供一組包含價格的數據來定型模型。 模型會掃描數據,並尋找汽車特徵與其價格之間的相互關聯。 然後,我們將測試模型 - 我們將為其提供一組我們熟悉的汽車功能,並查看模型如何接近預測已知的價格。
我們將使用我們的數據來定型模型,並將數據分割成個別的定型和測試數據集來進行測試。
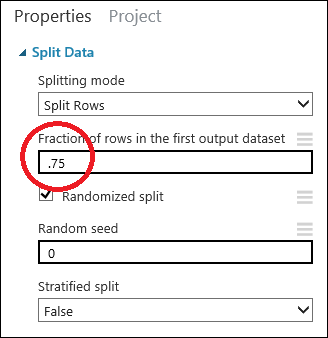
按兩下 [ 分割資料] 模組加以選取。 尋找第一個輸出數據集中的數據列分數(在畫布右側的 [屬性] 窗格中),並將其設定為0.75。 如此一來,我們將使用75%的數據來定型模型,並保留25%進行測試。
提示
藉由變更 Random 種子 參數,您可以產生不同的隨機樣本定型和測試。 此參數會控制虛擬隨機數產生器的植入。
執行實驗。 執行實驗時,選取 數據集 中的數據行和 分割數據模組會將數據 行定義傳遞給我們接下來要新增的模組。
若要選取學習演算法,請展開畫布左側模組調色盤中的 機器學習 類別,然後展開 [初始化模型]。 這會顯示數個可用來初始化機器學習演算法的模組類別。 在此實驗中,選取 [回歸] 類別下的 [線性回歸] 模組,然後將它拖曳至實驗畫布。 (您也可以在調色盤搜尋方塊中輸入「線性回歸」來尋找模組。
尋找訓練模型模組並將其拖曳至實驗畫布。 將線性回歸模組的輸出連接到定型模型模組的左側輸入,並將分割數據模組的定型數據輸出(左埠)連接到定型模型模組的右側輸入。
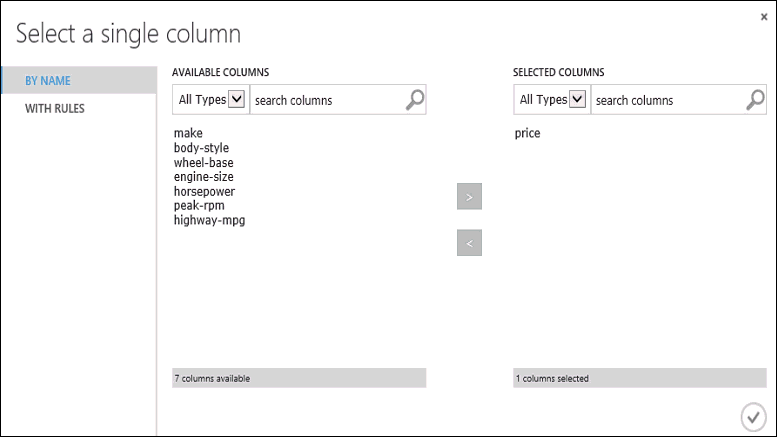
按兩下 [定型模型] 模組,按兩下 [屬性] 窗格中的 [啟動資料行選取器],然後選取價格數據行。 Price 是模型要預測的值。
您可以將價格數據行從 [可用的數據行] 清單移至 [選取的數據行] 清單,以選取數據行選取器中的價格數據行。
執行實驗。
我們現在有定型的回歸模型,可用來為新的汽車數據評分,以進行價格預測。
預測新的汽車價格
既然我們已使用 75% 的數據來定型模型,我們可以使用它來為其他 25% 的數據評分,以查看模型函式有多好。
尋找評分模型模組並將其拖曳至實驗畫布。 將定型模型模組的輸出連接到評分模型的左側輸入埠。 將分割數據模組的測試資料輸出(右埠)連接到評分模型的正確輸入埠。
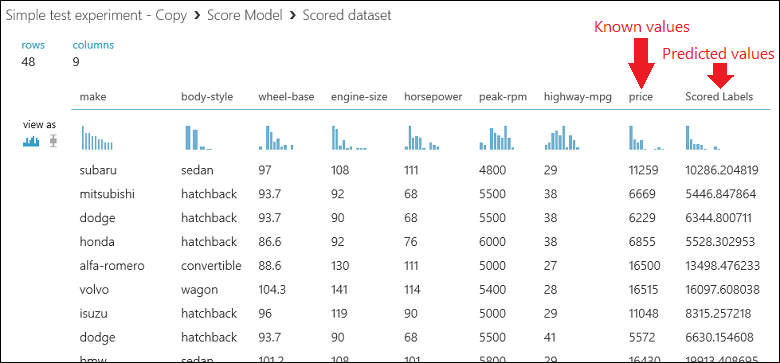
按兩下評分模型的輸出埠,然後選取 [可視化],執行實驗並檢視評分模型模組的輸出。 輸出會顯示價格的預測值,以及測試數據中的已知值。
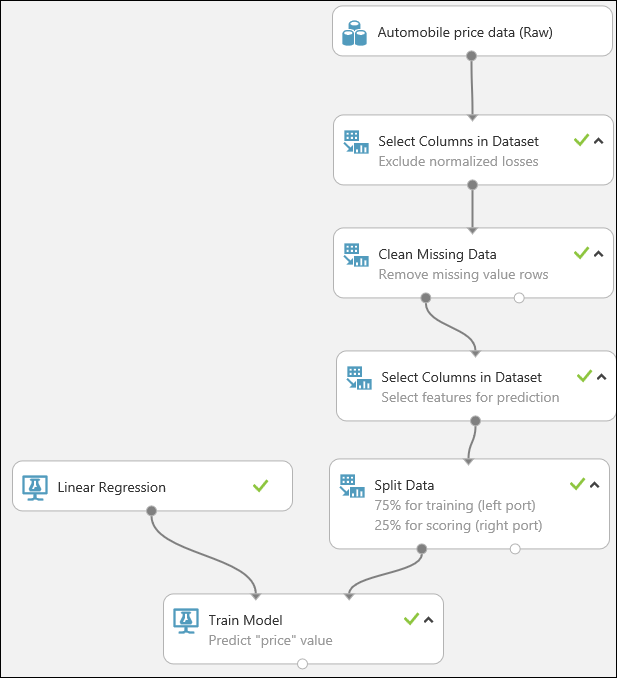
最後,我們會測試結果的品質。 選取評估模型模組並將其拖曳至實驗畫布,並將評分模型模組的輸出連接到評估模型的左側輸入。 最終實驗看起來應該像這樣:
執行實驗。
若要檢視評估模型模組的輸出,請單擊輸出埠,然後選取 [可視化]。
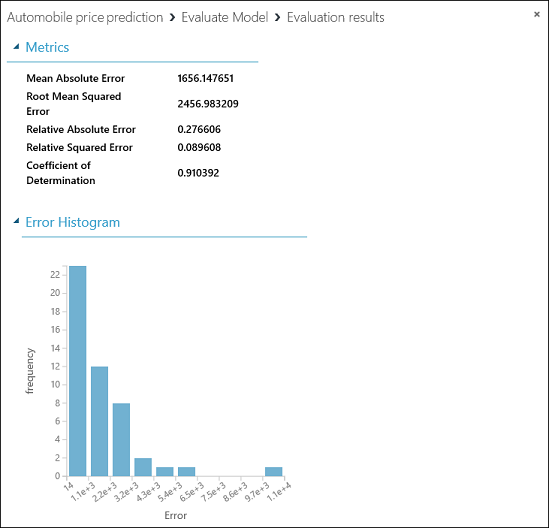
我們的模型會顯示下列統計資料:
- 平均絕對誤差(MAE):絕對誤差 的平均值( 錯誤 是預測值與實際值之間的差異)。
- 均方根誤差 (RMSE):對測試資料集所做的平方誤差預測平均值進行平方根。
- 相對絕對誤差:相對於實際值與所有實際值之平均值之間的絕對差異的絕對誤差平均值。
- 相對平方誤差:相對於實際值與所有實際值之平均值之間的平方差異的平方誤差平均值。
- 判定係數:也稱為 R 平方值,這是一個統計計量,指出模型如何符合數據。
針對每個誤差統計資料,越小越好。 較小的值表示預測更符合實際值。 對於 [判斷係數],其值越接近 1(1.0),預測越好。
清除資源
如果您不再需要使用本文建立的資源,請將其刪除,以避免產生任何費用。 瞭解如何在文章中匯出 和刪除產品內用戶數據。
下一步
在本快速入門中,您已使用範例數據集建立簡單的實驗。 若要探索更深入地建立和部署模型的程式,請繼續進行預測性解決方案教學課程。