從 Batch AI 遷移至 Azure Machine Learning 服務
Azure Batch AI 服務將在 3 月淘汰。 Batch AI 的大規模定型與計分功能目前已在 Azure Machine Learning 服務中提供,其已於 2018 年 12 月 4 日正式推出。
除了許多其他機器學習功能,Azure Machine Learning 服務還包括雲端式受控計算目標來對機器學習服務模型進行定型、部署和評分。 此計算目標稱為 Azure Machine Learning Compute。 立即開始遷移並加以使用。 您可以透過其 Python SDK、命令列介面及 Azure 入口網站來與 Azure Machine Learning 服務進行互動。
從預覽 BatchAI 升級至正式運作的 Azure Machine Learning 服務,可透過估算器和資料存放區等更容易使用的概念讓您獲得更好的體驗。 此外,也可保證 GA 層級的 Azure 服務 SLA 和客戶支援。
Azure Machine Learning 服務也導入了像是自動化機器學習、超參數調整和 ML 管線等新功能,可運用在大部分的大規模 AI 工作負載中。 無須切換至不同服務即可部署定型模型的能力,有助於完成從資料準備 (使用資料準備 SDK) 到運算化和模型監視的資料科學迴圈。
開始遷移
若要避免中斷您的應用程式並受益於最新功能,請在 2019 年 3 月 31 日之前採取下列步驟:
建立 Azure Machine Learning 服務工作區並開始使用:
設定用來為模型定型的 Azure Machine Learning Compute。
更新您的指令碼以使用 Azure Machine Learning Compute。 下列各節會說明用於 Batch AI 的常見程式碼如何對應至 Azure Machine learning 的程式碼。
建立工作區
在 Azure BatchAI 中使用 configuration.json 初始化工作區的概念,類似於在 Azure Machine Learning 服務中使用組態檔的概念。
在 Batch AI 中,您採用下列方式:
sys.path.append('../../..')
import utilities as utils
cfg = utils.config.Configuration('../../configuration.json')
client = utils.config.create_batchai_client(cfg)
utils.config.create_resource_group(cfg)
_ = client.workspaces.create(cfg.resource_group, cfg.workspace, cfg.location).result()
在 Azure Machine Learning 服務中,可以嘗試:
from azureml.core.workspace import Workspace
ws = Workspace.from_config()
print('Workspace name: ' + ws.name,
'Azure region: ' + ws.location,
'Subscription id: ' + ws.subscription_id,
'Resource group: ' + ws.resource_group, sep = '\n')
此外,您也可以藉由指定如下的組態參數,直接建立工作區
from azureml.core import Workspace
# Create the workspace using the specified parameters
ws = Workspace.create(name = workspace_name,
subscription_id = subscription_id,
resource_group = resource_group,
location = workspace_region,
create_resource_group = True,
exist_ok = True)
ws.get_details()
# write the details of the workspace to a configuration file to the notebook library
ws.write_config()
請參閱 SDK 參考文件以深入了解 Azure Machine Learning 工作區類別。
建立計算叢集
Azure Machine Learning 支援多個計算目標,其中有些由服務管理,有些則可連結至您的工作區,例如 HDInsight 叢集或遠端 VM。 深入了解各種計算目標。 建立 Azure BatchAI 計算叢集的概念,與在 Azure Machine Learning 服務中建立 AmlCompute 叢集相對應。 建立 Amlcompute 時會採用計算組態,這類似於在 Azure Batch AI 中傳遞參數。 要注意的一點是,自動調整在 AmlCompute 叢集上預設為開啟,而在 Azure Batch AI 中則預設為關閉。
在 Batch AI 中,您採用下列方式:
nodes_count = 2
cluster_name = 'nc6'
parameters = models.ClusterCreateParameters(
vm_size='STANDARD_NC6',
scale_settings=models.ScaleSettings(
manual=models.ManualScaleSettings(target_node_count=nodes_count)
),
user_account_settings=models.UserAccountSettings(
admin_user_name=cfg.admin,
admin_user_password=cfg.admin_password or None,
admin_user_ssh_public_key=cfg.admin_ssh_key or None,
)
)
_ = client.clusters.create(cfg.resource_group, cfg.workspace, cluster_name, parameters).result()
在 Azure Machine Learning 服務中,可以嘗試:
from azureml.core.compute import ComputeTarget, AmlCompute
from azureml.core.compute_target import ComputeTargetException
# Choose a name for your CPU cluster
gpu_cluster_name = "nc6"
# Verify that cluster does not exist already
try:
gpu_cluster = ComputeTarget(workspace=ws, name=gpu_cluster_name)
print('Found existing cluster, use it.')
except ComputeTargetException:
compute_config = AmlCompute.provisioning_configuration(vm_size='STANDARD_NC6',
vm_priority='lowpriority',
min_nodes=1,
max_nodes=2,
idle_seconds_before_scaledown='300',
vnet_resourcegroup_name='<my-resource-group>',
vnet_name='<my-vnet-name>',
subnet_name='<my-subnet-name>')
gpu_cluster = ComputeTarget.create(ws, gpu_cluster_name, compute_config)
gpu_cluster.wait_for_completion(show_output=True)
請參閱 SDK 參考文件以深入了解 AMLCompute 類別。 請注意,在上述組態中,只有 vm_size 和 max_nodes 是必要屬性,其餘屬性 (如 VNets) 僅供進階叢集設定之用。
監視叢集的狀態
此作業在 Azure Machine Learning 服務中更為簡單直接,顯示如下。
在 Batch AI 中,您採用下列方式:
cluster = client.clusters.get(cfg.resource_group, cfg.workspace, cluster_name)
utils.cluster.print_cluster_status(cluster)
在 Azure Machine Learning 服務中,可以嘗試:
gpu_cluster.get_status().serialize()
取得儲存體帳戶的參考
在 Azure Machine Learning 服務中,資料儲存體 (如 Blob) 的概念已透過 DataStore 物件而獲得簡化。 根據預設,Azure Machine Learning 服務工作區會建立儲存體帳戶,但您也可以在建立工作區的過程中連結自己的儲存體。
在 Batch AI 中,您採用下列方式:
azure_blob_container_name = 'batchaisample'
blob_service = BlockBlobService(cfg.storage_account_name, cfg.storage_account_key)
blob_service.create_container(azure_blob_container_name, fail_on_exist=False)
在 Azure Machine Learning 服務中,可以嘗試:
ds = ws.get_default_datastore()
print(ds.datastore_type, ds.account_name, ds.container_name)
請參閱 Azure Machine Learning 服務文件以深入了解如何註冊其他儲存體帳戶,或取得其他已註冊資料存放區的參考。
下載及上傳資料
使用任一項服務時,您都可以使用上述的資料存放區參考輕鬆地將資料上傳至儲存體帳戶。 在 Azure BatchAI 中,我們也可將訓練指令碼部署為檔案共用的一部分,但在 Azure Machine Learning 服務中,您將可了解如何將其指定為工作組態的一部分。
在 Batch AI 中,您採用下列方式:
mnist_dataset_directory = 'mnist_dataset'
utils.dataset.download_and_upload_mnist_dataset_to_blob(
blob_service, azure_blob_container_name, mnist_dataset_directory)
script_directory = 'tensorflow_samples'
script_to_deploy = 'mnist_replica.py'
blob_service.create_blob_from_path(azure_blob_container_name,
script_directory + '/' + script_to_deploy,
script_to_deploy)
在 Azure Machine Learning 服務中,可以嘗試:
import os
import urllib
os.makedirs('./data', exist_ok=True)
download_url = 'https://s3.amazonaws.com/img-datasets/mnist.npz'
urllib.request.urlretrieve(download_url, filename='data/mnist.npz')
ds.upload(src_dir='data', target_path='mnist_dataset', overwrite=True, show_progress=True)
path_on_datastore = ' mnist_dataset/mnist.npz' ds_data = ds.path(path_on_datastore) print(ds_data)
建立實驗
如前所述,Azure Machine Learning 服務在實驗方面的概念與 Azure Batch AI 相似。 每個實驗可以有個別的執行,類似於我們在 Azure BatchAI 中的作業。 Azure Machine Learning 服務也允許每個父執行之下有個別子執行的階層。
在 Batch AI 中,您採用下列方式:
experiment_name = 'tensorflow_experiment'
experiment = client.experiments.create(cfg.resource_group, cfg.workspace, experiment_name).result()
在 Azure Machine Learning 服務中,可以嘗試:
from azureml.core import Experiment
experiment_name = 'tensorflow_experiment'
experiment = Experiment(ws, name=experiment_name)
提交工作
建立實驗之後,您可以透過幾種不同的方式提交執行。 在此範例中,我們將嘗試使用 TensorFlow 建立深度學習模型,並且使用 Azure Machine Learning 服務估算器來建立。 估算器就是基礎執行組態的簡單包裝函式,可方便您提交執行,目前僅支援 Pytorch 和 TensorFlow。 透過資料存放區的概念,您也將發現掛接路徑的指定會變得多麼容易
在 Batch AI 中,您採用下列方式:
azure_file_share = 'afs'
azure_blob = 'bfs'
args_fmt = '--job_name={0} --num_gpus=1 --train_steps 10000 --checkpoint_dir=$AZ_BATCHAI_OUTPUT_MODEL --log_dir=$AZ_BATCHAI_OUTPUT_TENSORBOARD --data_dir=$AZ_BATCHAI_INPUT_DATASET --ps_hosts=$AZ_BATCHAI_PS_HOSTS --worker_hosts=$AZ_BATCHAI_WORKER_HOSTS --task_index=$AZ_BATCHAI_TASK_INDEX'
parameters = models.JobCreateParameters(
cluster=models.ResourceId(id=cluster.id),
node_count=2,
input_directories=[
models.InputDirectory(
id='SCRIPT',
path='$AZ_BATCHAI_JOB_MOUNT_ROOT/{0}/{1}'.format(azure_blob, script_directory)),
models.InputDirectory(
id='DATASET',
path='$AZ_BATCHAI_JOB_MOUNT_ROOT/{0}/{1}'.format(azure_blob, mnist_dataset_directory))],
std_out_err_path_prefix='$AZ_BATCHAI_JOB_MOUNT_ROOT/{0}'.format(azure_file_share),
output_directories=[
models.OutputDirectory(
id='MODEL',
path_prefix='$AZ_BATCHAI_JOB_MOUNT_ROOT/{0}'.format(azure_file_share),
path_suffix='Models'),
models.OutputDirectory(
id='TENSORBOARD',
path_prefix='$AZ_BATCHAI_JOB_MOUNT_ROOT/{0}'.format(azure_file_share),
path_suffix='Logs')
],
mount_volumes=models.MountVolumes(
azure_file_shares=[
models.AzureFileShareReference(
account_name=cfg.storage_account_name,
credentials=models.AzureStorageCredentialsInfo(
account_key=cfg.storage_account_key),
azure_file_url='https://{0}.file.core.windows.net/{1}'.format(
cfg.storage_account_name, azure_file_share_name),
relative_mount_path=azure_file_share)
],
azure_blob_file_systems=[
models.AzureBlobFileSystemReference(
account_name=cfg.storage_account_name,
credentials=models.AzureStorageCredentialsInfo(
account_key=cfg.storage_account_key),
container_name=azure_blob_container_name,
relative_mount_path=azure_blob)
]
),
container_settings=models.ContainerSettings(
image_source_registry=models.ImageSourceRegistry(image='tensorflow/tensorflow:1.8.0-gpu')),
tensor_flow_settings=models.TensorFlowSettings(
parameter_server_count=1,
worker_count=nodes_count,
python_script_file_path='$AZ_BATCHAI_INPUT_SCRIPT/'+ script_to_deploy,
master_command_line_args=args_fmt.format('worker'),
worker_command_line_args=args_fmt.format('worker'),
parameter_server_command_line_args=args_fmt.format('ps'),
)
)
在 Azure BatchAI 中,作業本身的提交是透過 create 函式執行的。
job_name = datetime.utcnow().strftime('tf_%m_%d_%Y_%H%M%S')
job = client.jobs.create(cfg.resource_group, cfg.workspace, experiment_name, job_name, parameters).result()
print('Created Job {0} in Experiment {1}'.format(job.name, experiment.name))
如需此訓練程式碼片段 (包括我們已上傳至前述檔案共用的 mnist_replica.py 檔案) 的完整資訊,請透過 Azure BatchAI 範例 Notebook Github 存放庫取得。
在 Azure Machine Learning 服務中,可以嘗試:
from azureml.train.dnn import TensorFlow
script_params={
'--num_gpus': 1,
'--train_steps': 500,
'--input_data': ds_data.as_mount()
}
estimator = TensorFlow(source_directory=project_folder,
compute_target=gpu_cluster,
script_params=script_params,
entry_script='tf_mnist_replica.py',
node_count=2,
worker_count=2,
parameter_server_count=1,
distributed_backend='ps',
use_gpu=True)
如需此訓練程式碼片段 (包括 tf_mnist_replica.py 檔案) 的完整資訊,請透過 Azure Machine Learning 服務範例 Notebook Github 存放庫取得。 資料存放區本身可掛接在個別節點上,或者,可在節點本身下載訓練資料。 如需關於在估算器中參考資料存放區的詳細資訊,請參閱 Azure Machine Learning 服務文件。
在 Azure Machine Learning 服務中提交執行的作業可透過 submit 函式來完成。
run = experiment.submit(estimator)
print(run)
您可以透過另一種方式為執行指定參數,也就是使用執行組態 – 特別適合用來定義自訂訓練環境。 您可以在範例 AmlCompute Notebook 中找到更多詳細資料。
監視執行
提交執行後,您可以等候執行完成,或是在 Azure Machine Learning 服務中使用可直接從程式碼叫用的 Jupyter 小工具加以監視。 您也可以藉由重複存取工作區中的各種實驗和每個實驗內的個別執行,來提取任何先前執行的內容。
在 Batch AI 中,您採用下列方式:
utils.job.wait_for_job_completion(client, cfg.resource_group, cfg.workspace,
experiment_name, job_name, cluster_name, 'stdouterr', 'stdout-wk-0.txt')
files = client.jobs.list_output_files(cfg.resource_group, cfg.workspace, experiment_name, job_name,
models.JobsListOutputFilesOptions(outputdirectoryid='stdouterr'))
for f in list(files):
print(f.name, f.download_url or 'directory')
在 Azure Machine Learning 服務中,可以嘗試:
run.wait_for_completion(show_output=True)
from azureml.widgets import RunDetails
RunDetails(run).show()
以下是小工具如何在筆記本中載入以即時查看記錄的快照: 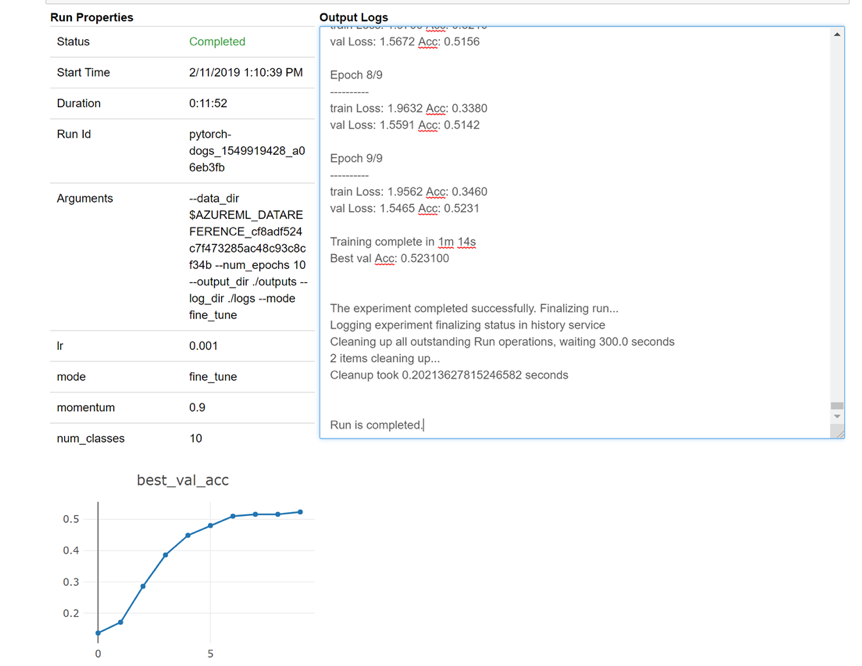
編輯叢集
刪除叢集相當簡單。 此外,如果您想要將叢集調整為更高數目的節點,或增加相應減少叢集之前的閒置等待時間,Azure Machine Learning 服務也可讓您從 Notebook 中更新叢集。 我們不允許變更叢集本身的 VM 大小,這需要在後端執行有效的新部署。
在 Batch AI 中,您採用下列方式:
_ = client.clusters.delete(cfg.resource_group, cfg.workspace, cluster_name)
在 Azure Machine Learning 服務中,可以嘗試:
gpu_cluster.delete()
gpu_cluster.update(min_nodes=2, max_nodes=4, idle_seconds_before_scaledown=600)
得到支援
Batch AI 會在 3 月 31 日淘汰,而且已封鎖新的訂用帳戶,使其無法向服務註冊,除非透過支援提出例外狀況來列入允許清單。 如有任何疑問,或是在移轉到 Azure Machine Learning 服務的過程中有任何意見,請透過 Azure Batch AI 訓練預覽版與我們連絡。
Azure Machine Learning 服務已是正式運作的服務。 這表示它附有經認可的 SLA 和各種支援方案可供選擇。
透過Azure Batch AI 服務或透過 Azure Machine Learning 服務使用 Azure 基礎結構的定價不應有所不同,因為我們只會在這兩種情況下收取基礎計算的價格。 如需詳細資訊,請參閱定價計算機。
請在 Azure 入口網站上檢視這兩項服務的可用區域。
後續步驟
使用 Azure Machine Learning 服務為模型定型設定計算目標。
檢閱 Azure 藍圖以了解其他 Azure 服務更新。