Power BI 語意模型擴增
語意模型擴增可協助 Power BI 提供快速的效能,而報告和儀表板則由大量對象取用。 語意模型擴增會使用 Premium 容量來裝載主要語意模型的一或多個唯讀複本。 藉由增加輸送量,唯讀複本可確保當多個使用者同時提交查詢時,效能不會變慢。
當 Power BI 建立唯讀複本時,其會將它們與主要讀寫語意模型分開。 唯讀複本會提供 Power BI 報告和儀表板查詢,且在執行寫入和重新整理作業時會使用讀寫語意模型。 在寫入和重新整理作業期間,唯讀複本會繼續為您的報告和儀表板查詢提供服務,而不會中斷。 根據預設,唯讀和讀寫語意模型會自動同步,讓唯讀複本保持最新狀態。 不過,您可以停用自動同步,並選擇在命令列中或透過指令碼手動同步。
下表顯示啟用 Power BI 語意模型擴增且停用自動同步時,每個重新整理方法的必要同步:
| 重新整理方法 | Sync |
|---|---|
| 隨選 UI | 一律同步 |
| 排定的重新整理 | 一律同步 |
| 基本 REST API | 需要手動同步 1 |
| 進階 REST API | 需要手動同步 1 |
| XMLA | 需要手動同步 1 |
1 - queryScaleOutSettings 中的 autoSyncReadOnlyReplicas 設定為 false。
複本管理
擴增會建立一個讀寫語意模型複本,並視需要建立多個唯讀複本。 所有寫入作業都會導向至讀寫複本。 這包括明確以讀寫複本為目標之工作階段的查詢,也就是不要在連接字串中使用 ?readonly。 這些查詢可能會導致讀寫複本上的互動式 CPU 使用量偏高。 在這種情況下,系統不會建立新的複本,因為以讀寫複本為目標的查詢負載無法散發至唯讀複本。
唯讀複本的數目是根據查詢取用的 RU 數目來決定。 如果需求超過目前在載入模型之節點上可用的計算資源,且維持高,可能會在另一個節點上建立額外的唯讀複本來分散負載。 不過,所有複本所耗用的 RU 總數不能超過單一模型允許在指定容量 SKU 上取用的最大 RU 數目。
例如,F64 容量上的指定語意模型將有足夠的資源在單一節點上取用該 SKU 上所有允許的 OU。 因此,F64 容量通常不會擴增超過單一隻讀複本。 另一方面,F256 和 F1024+ 容量更有可能建立第二個唯讀複本,因為單一節點可能不足以提供 F256/F1024+ 容量上允許使用的所有 SU。
QSO 的設計訴求是利用指定容量 SKU 的可用計算能力,盡可能有效率且順暢地使用最少的唯讀複本,而且不會對語意模型擁有者造成管理額外負荷。
不過,如果新增更多複本,容量上的目前負載可能會高達足以造成 節流 。 節流可防止其他唯讀複本達到持續偏高的 CPU 使用量。 在這種情況下,系統不會建立新的擴增唯讀複本。
當模型的 CU 使用量足夠減少且持續保持足夠低時,就會移除複本。
必要條件
根據預設會為您的租用戶啟用擴增,但不會針對租用戶中的語意模型啟用。 若要啟用語意模型的擴增,您必須使用 Power BI REST API。 啟用之前,必須符合下列必要條件:
已啟用租用戶的 [大型語意模型的擴增查詢] 設定 (預設值)。
您的工作區位於 Power BI Premium 的容量上:
- Premium Per User (PPU)
- Power BI Premium P SKU
- Power BI A SKU for Power BI Embedded (也稱為為您的客戶內嵌)。
- 網狀架構 F SKU
若要使用 REST API 管理語意模型,請使用 Power BI 管理 Cmdlet。 以系統管理員模式開啟 PowerShell 並執行命令來安裝:
Install-Module -Name MicrosoftPowerBIMgmt下列 (或更新版本) 應用程式、程式庫和服務版本支援連線到唯讀複本:
應用程式、程式庫或服務 版本 Microsoft Analysis Services OLE DB Provider for Microsoft SQL Server (MSOLAP) 16.0.20.201 (2022 年 3 月) Microsoft.AnalysisServices.AdomdClient (ADOMD.NET) 19.36.0 (2022 年 3 月) Power BI Desktop 2022 年 6 月 SQL Server Management Studio (SSMS) 19.0 Tabular Editor 2 2.16.6 Tabular Editor 3 3.2.3 DAX Studio 3.0.0
設定語意模型的擴增
若要了解如何啟用或停用語意模型的擴增,或使用 PowerShell 和 REST API 取得擴增狀態,請參閱設定語意模型擴增。
連線到特定的語意模型類型
啟用擴增時,系統會保留下列連線:
根據預設,Power BI Desktop 會連線到唯讀複本。
即時連線報告會連線到唯讀複本。
XMLA 用戶端應用程式預設會連線到讀寫語意模型。
在 Power BI 服務中重新整理,並使用增強式重新整理 REST API 連線到讀寫語意模型來重新整理。
您可以將下列其中一個字串附加至語意模型的 URL,以連線到唯讀複本或讀寫語意模型:
- 唯讀 -
?readonly - 讀寫 -
?readwrite
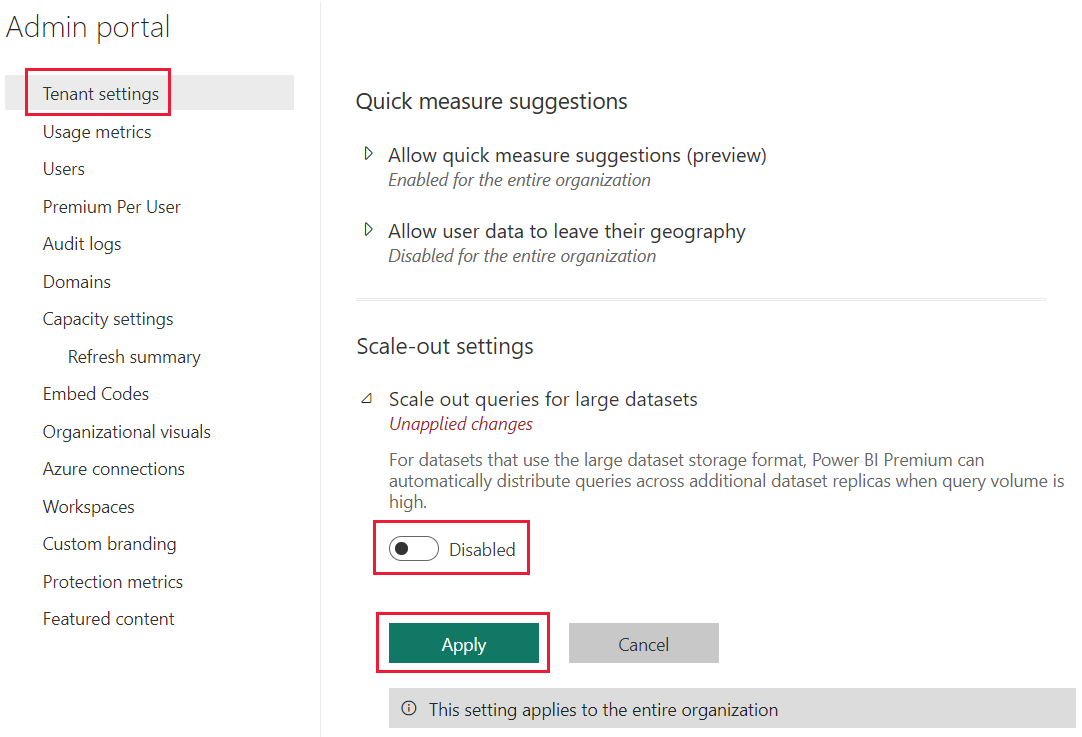
停用租用戶的語意模型擴增
根據預設,系統會針對租用戶啟用 Power BI 語意模型擴增。 Power BI 租用戶系統管理員可以停用此設定。 若要停用租用戶的語意模型擴增,請執行下列動作:
考量與限制
用戶端應用程式可以透過 XMLA 端點連線到唯讀複本,前提是它們支援連接字串中指定的模式。 用戶端應用程式也可以使用 XMLA 端點連線到讀寫執行個體。
手動和排程的重新整理一律會自動與最新版本的唯讀複本同步。 REST API 重新整理會遵循自動同步設定。 如果停用自動同步,您的語意模型必須使用手動同步 REST API 來與唯讀複本同步。
停用自動同步後,XMLA 更新和重新整理必須使用同步 REST API 與唯讀語意模型複本進行同步。
刪除 Power BI 擴增語意模型,並建立具有相同名稱的另一個語意模型時,允許在建立新的語意模型之前五分鐘的傳遞時間。 Power BI 可能需要一些時間才能移除主要語意模型的複本。
當 Power BI 語意模型擴增啟用且
autoSyncReadOnlyReplicas=false時,不支援對下列功能的變更:- 新增或刪除角色
- 更新任何角色的角色成員資格集
- 修改資料來源
- 刪除 DirectQuery 或雙重資料表所使用的資料來源
- 物件層級安全性 (OLS) 或動態資料列層級安全性 (RLS) 運算式的變更
若要變更這些功能,請停用擴增,並允許在重新啟用之前進行幾分鐘的變更。
使用動態管理檢視 (DMV) TMSCHEMA_ROLE_MEMBERSHIPS 資料列集探索角色成員資格,在針對唯讀複本執行時不會傳回任何結果。
使用即時連線的報告一律會連線到唯讀複本,即使連接字串使用
?readwrite也一樣。 不過,在 Power BI Desktop 中,使用?readwrite連線到讀寫複本的即時連線報告。DBSCHEMA_CATALOGS 和 DISCOVER_XML_METADATA 動態管理檢視 (DMV) 資料列集,會在連接字串中使用
?readonly時傳回讀寫複本資訊。SQL Server Profiler 不適用於
?readonly連接字串。即使自動同步已關閉 (
AutoSync=Off),這些作業仍會觸發自動同步。- 將工作區從一個容量移轉至另一個容量。
- 切換 (或輪替) 用於攜帶您自己的加密金鑰 (BYOK) 的金鑰版本。
- 將語意模型的工作區從不使用 BYOK 的容量移至使用 BYOK 的容量。
- 將語意模型的工作區從使用 BYOK 的容量移至不使用 BYOK 的容量。
- 使用公用 XMLA 端點還原語意模型。