Power BI 中的高密度折線圖取樣
Power BI 中的取樣演算法可改善取樣高密度資料的視覺效果。 例如,您可以利用零售商店的銷售結果來建立折線圖,而每間商店每年都會有 10,000 張以上的銷售收據。 這類銷售資訊的折線圖會對每間商店的資料進行取樣,並建立多數列的折線圖,進而代表基礎資料。 請務必為該資料選取有意義的表示法,以說明銷售隨著時間的變化。 這是視覺化高密度資料的常見做法。 本文說明高密度資料取樣的詳細資料。
注意
Power BI Desktop 和 Power BI 服務可使用本文所述的高密度取樣演算法。
高密度折線圖取樣的運作方式
先前,Power BI 已透過決定性方式選取完整基礎資料範圍中的範例資料點集合。 例如,具有跨一個日曆年度之視覺效果的高密度資料,視覺效果中可能會顯示 350 個範例資料點,並會選取每個資料點,確保視覺效果中已呈現完整資料範圍。 為了協助您了解情況,假設已繪製一年期間的股價,並選取 365 個資料點,建立折線圖視覺效果。 即一天一個資料點。
在此情況下,該股價每天都有許多值。 當然,每天都有最高值和最低值,但這些可能發生在股票市場開市當天的任何時間。 針對高密度折線圖取樣,如果基礎資料樣本是在每天的上午 10:30 和下午 12:00 取得,則會取得基礎資料的代表性快照,例如上午 10:30 和下午 12:00 的價格。 不過,快照集可能不會擷取當天代表性資料點的實際最高和最低股價。 在該情況和其他情況下,取樣代表基礎資料,但不一定會擷取重要點,在此情況下是每日最高和最低股價。
根據定義,取樣高密度資料可在合理範圍內快速建立互動回應的視覺效果。 視覺效果上有太多資料點會拖慢速度,並降低趨勢的可見性。 資料的取樣方式會推動取樣演算法的建立,以提供最佳的視覺效果體驗。 在 Power BI Desktop 中,此演算法提供回應、轉譯和清楚保留每個時間配量中重要點的最佳組合。
新線路取樣演算法的運作方式
高密度折線圖取樣的演算法適用於含連續 X 軸的折線圖和區域圖視覺效果。
針對高密度視覺效果,Power BI 會以聰明的方式將資料切割為高解析區塊,然後選擇重要點來代表每個區塊。 該切割高解析資料程序已經過調整,確保所產生的圖表在視覺上與轉譯所有基礎資料點並無二致,卻更為快速且更具互動性。
高密度折線圖視覺效果的最小值和最大值
針對任何視覺效果,限制如下:
3,500 是大部分視覺效果上所「顯示」的最大資料點數目,而不論基礎資料點或數列數目為何,請參閱下列清單中的「例外狀況」。 例如,如果您有 10 個各具有 350 個資料點的數列,則視覺效果已達其最大整體資料點限制。 如果您有一個數列,則演算法認為它是最佳基礎資料取樣時,最多可能有 3,500 個資料點。
任何視覺效果最多都有「60 個數列」。 如果您的數列超過 60 個,請分割資料,並建立多個各具有 60 (含) 個以下數列的視覺效果。 最好使用交叉分析篩選器,只顯示資料的各區段,但僅特定數列。 例如,如果您在圖例中顯示所有子類別,則可以在相同報表頁面上使用交叉分析篩選器,依整體類別進行篩選。
下列視覺效果類型的最大資料限制數目更高,這些是 3,500 個資料點限制的「例外狀況」:
- R 視覺效果最多為 150,000 個資料點。
- 30,000 個 Azure 地圖視覺效果的資料點。
- 某些散佈圖組態為 10,000 個資料點 (散佈圖預設為 3,500)。
- 針對使用高密度取樣的所有其他視覺效果為 3,500。 某些其他視覺效果可能會將更多資料視覺化,但不會使用取樣。
這些參數確保 Power BI Desktop 中的視覺效果會快速地轉譯,並且回應與使用者的互動,而且不會讓轉譯視覺效果的電腦上造成過度運算負荷。
評估高密度折線圖視覺效果的代表性資料點
當基礎資料點數目超過視覺效果中可以表示的最大資料點時,稱為量化的程序即會開始。 量化會將基礎資料分割成稱為量化的群組,然後反覆精簡這些量化。
此演算法會建立最多量化,以建立視覺效果的最大細微性。 在每個量化內,此演算法會尋找最小和最大資料值,確保可以擷取重要值和重大值,例如極端值,並將其顯示在視覺效果中。 根據量化結果以及 Power BI 的後續資料評估,判斷視覺效果 X 軸的最小解析,確保視覺效果的最大細微性。
如前所述,每個數列的最小細微性是 350 個點,而大部分視覺效果的最大值為 3,500。 例外狀況列在上一個段落中。
每個量化都是由兩個資料點表示,而它們會成為量化在視覺效果中的代表性資料點。 資料點就是該量化的最高值和最低值。 透過選取最高值和最低值,量化程序可確保擷取任何重要最高值或重大最低值,並將其轉譯在視覺效果中。
如果這聽起來需要進行許多分析來確保偶而擷取到極端值,並將其正確地顯示在視覺效果中,那就沒錯。 這正是需要新演算法和量化流程的原因。
工具提示和高密度折線圖取樣
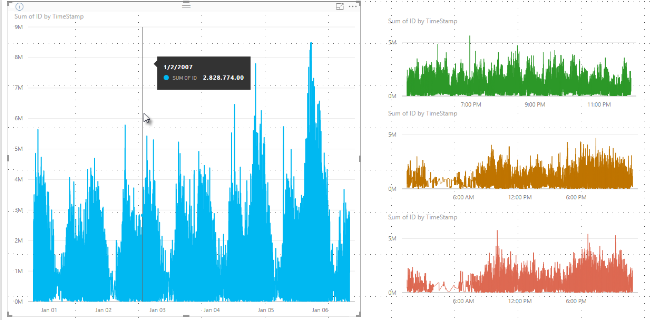
請務必注意,此量化流程會擷取並顯示指定量化中的最小值和最大值,且可能會影響當將滑鼠游標暫留在資料點上方時,工具提示顯示資料的方式。 若要解釋如何及為何發生這種情況,讓我們回到股價範例。
假設您要根據股價建立視覺效果,且要比較兩支不同股票,這兩支股票都是使用高密度取樣。 每個數列的基礎資料都有許多資料點。 例如,也許您每天每秒擷取股票價格。 高密度折線圖取樣演算法會個別執行每個數列的量化。
現在,假設第一支股票的價格在 12:02 時上彈,然後在 10 秒之後快速恢復。 這是重要的資料點。 量化該股票時,12:02 的最高值會是該量化的代表性資料點。
不過,對於第二支股票而言,12:02 在此時包含的量化中不高也不低。 也許三分鐘後會出現包含 12:02 之量化的高值和低值。 在此情況下,建立折線圖並將滑鼠停留在 12:02 上方時,您會在工具提示中看到第一支股票的值。 這是因為它跳到 12:02,且該值已選取為該量化的高資料點。 不過,您不會在工具提示中的 12:02 看到第二支股票的任何值。 這是因為第二支股票沒有 12:02 所包含量化的最高值或最低值。 因此第二支股票在 12:02 沒有可顯示的資料,所以不會顯示任何工具提示資料。
工具提示很常發生這種情況。 特定量化的最高值和最低值可能未與平均縮放的 X 軸值點完全相符,工具提示不會顯示該值。
如何開啟高密度折線圖取樣
根據預設,演算法為 [開啟]。 若要變更此設定,請前往 [格式] 窗格的 [一般] 卡片,您會在底端看到 [高密度取樣] 滑桿。 選取滑桿以切換 [開啟] 或 [關閉]。
![高密度折線圖取樣的螢幕擷取畫面,其中顯示 [格式] 窗格、[一般] 和 [高密度取樣] 的指標。](media/desktop-high-density-sampling/high-density-sampling-04.png)
考量與限制
高密度折線圖取樣的演算法是 Power BI 的一項重要改善,但在使用高密度值和資料時,您必須知道下列幾點考量。
如果使用游標對齊代表性資料,則因為細微性提高和量化程序,所以工具提示只可能會顯示值。 如需詳細資訊,請參閱本文的工具提示和高密度折線圖取樣一節。
整體資料來源的大小太大時,演算法會消除數列 (圖例項目),以容納資料匯入最大值條件約束。
- 在此情況下,演算法會依字母順序排序圖例數列,並依字母順序往下顯示圖例項目清單,直到達到資料匯入最大值,而且不會匯入其他數列。
基礎資料集超過 60 個數列 (最大數列數目) 時,新演算法會依字母順序排序數列,並清除超過第 60 個依字母順序排序之數列的數列。
如果資料中的值不是 numeric 或 date/time 類型,Power BI 將不會使用演算法,並將還原為先前的非高密度取樣演算法。
演算法不支援 [顯示沒有資料的項目] 設定。
使用 SQL Server Analysis Services 2016 版或更早版本中託管之模型的即時連線時,不支援演算法。 在 Power BI 或 Azure Analysis Services 所託管的模型中支援它。