教學課程:使用聚合函數
適用於:✅Microsoft網狀架構✅Azure 數據✅總管 Azure 監視器✅Microsoft Sentinel
聚合函數 可讓您將數據從多個數據列分組並合併為摘要值。 摘要值取決於所選的函式,例如計數、最大值或平均值。
在本教學課程中,您將了解如何:
本教學課程中的範例會使用StormEvents可在說明叢集中公開使用的數據表。 若要使用您自己的數據進行探索, 請建立您自己的免費叢集。
本教學課程中的範例會使用StormEvents可在天氣分析範例數據中公開使用的數據表。
本教學課程是以第一個 教學課程 Learn 一般運算符為基礎。
必要條件
若要執行下列查詢,您需要具有範例數據的存取權的查詢環境。 您可以使用下列其中一項:
- Microsoft帳戶或Microsoft Entra 使用者身分識別
- 具有Microsoft網狀架構功能的容量的網狀架構工作區
使用摘要運算子
summarize 運算符對於對您的數據執行匯總至關重要。 運算子會 summarize 根據 by 子句將數據列分組在一起,然後使用提供的聚合函數結合單一數據列中的每一個群組。
使用 summarize 計數匯總函式,依狀態尋找事件數目。
StormEvents
| summarize TotalStorms = count() by State
輸出
| 州/省 | TotalStorms |
|---|---|
| 德克薩斯州 | 4701 |
| 堪薩斯州 | 3166 |
| 愛荷華州 | 2337 |
| 伊利諾州 | 2022 |
| 密蘇里州 | 2016 |
| ... | ... |
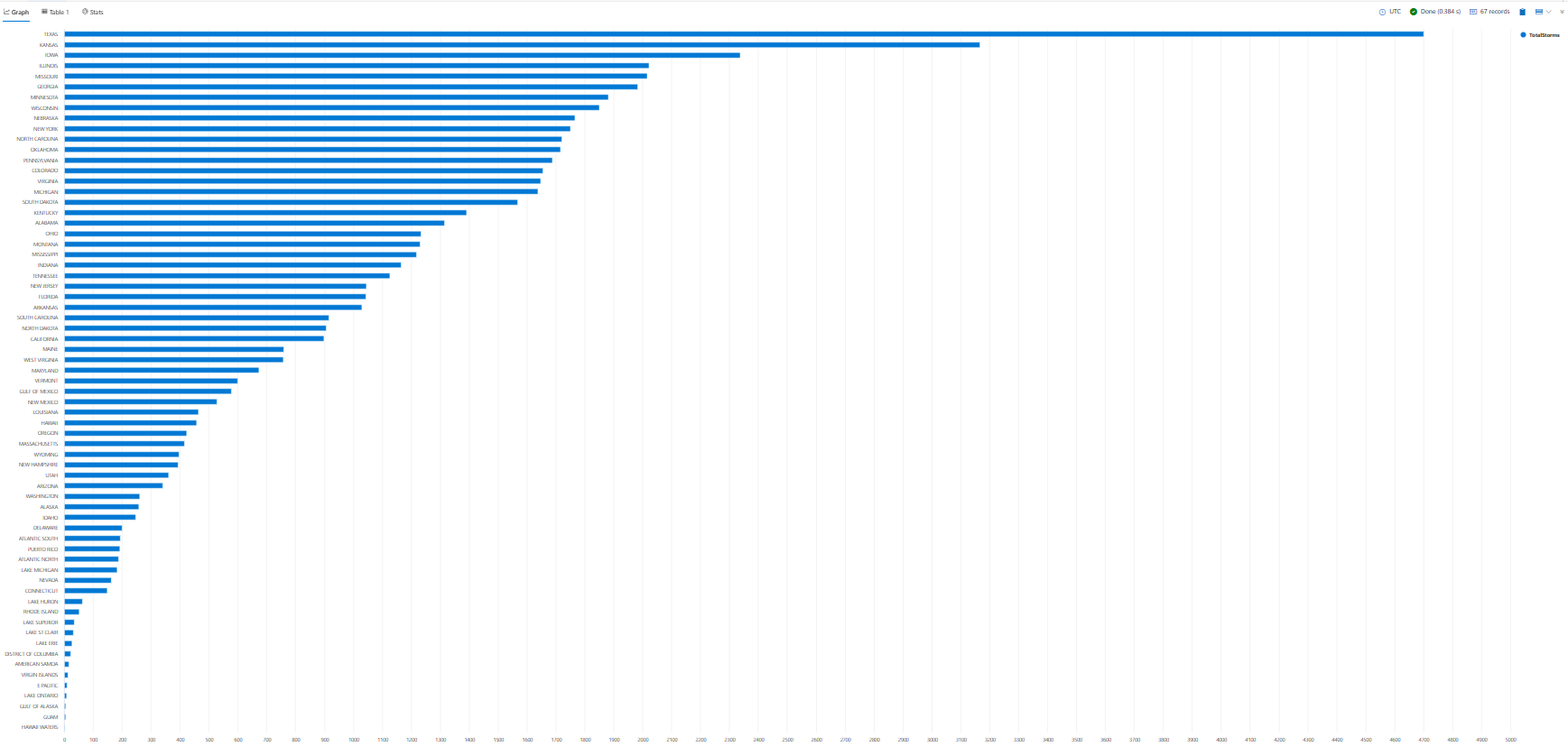
將查詢結果可視化
在圖表或圖表中可視化查詢結果可協助您識別數據中的模式、趨勢和極端值。 您可以使用轉譯運算符來執行這項操作。
在整個教學課程中,您將會看到如何使用 render 來顯示結果的範例。 目前,讓我們使用 render 來查看條形圖中上一個查詢的結果。
StormEvents
| summarize TotalStorms = count() by State
| render barchart
有條件地計算數據列
分析數據時,請使用 countif() 根據特定條件來計算數據列,以瞭解有多少數據列符合指定的準則。
下列查詢會使用 countif() 來計算造成損壞的風暴計數。 然後,查詢會 top 使用 運算符來篩選結果,並顯示由暴風雨造成最高作物損毀的狀態。
StormEvents
| summarize StormsWithCropDamage = countif(DamageCrops > 0) by State
| top 5 by StormsWithCropDamage
輸出
| 州/省 | StormsWithCropDamage |
|---|---|
| 愛荷華州 | 359 |
| 內布拉斯加州 | 201 |
| 密西西比州 | 105 |
| 北卡羅來那州 | 82 |
| 密蘇里州 | 78 |
將數據分組到 bin
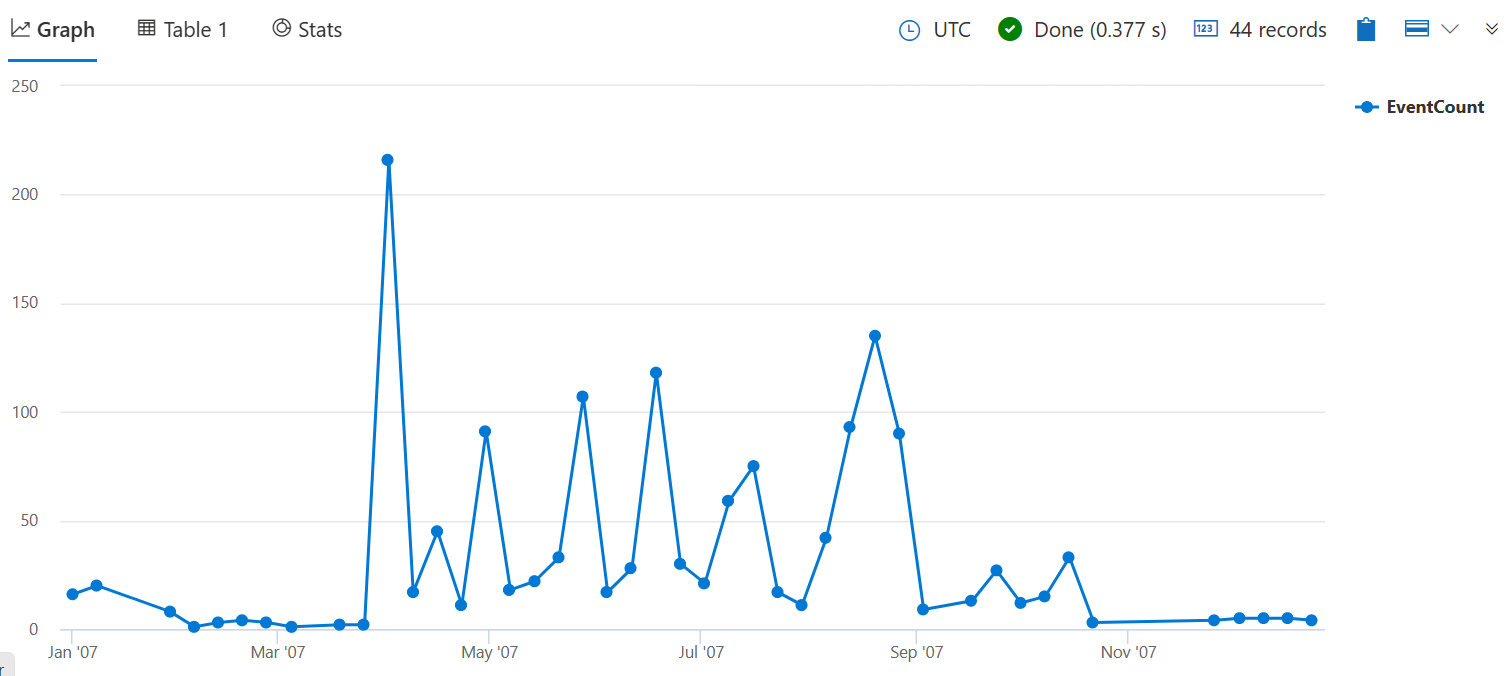
若要依數值或時間值匯總,您必須先使用 bin() 函式將數據分組為 bin。 使用 bin() 可協助您瞭解值在某個範圍內分佈的方式,並在不同期間之間進行比較。
下列查詢會計算在 2007 年每周造成作物損壞的風暴數目。 自 7d 變數代表一周,因為函式需要有效的 時間範圍 值。
StormEvents
| where StartTime between (datetime(2007-01-01) .. datetime(2007-12-31))
and DamageCrops > 0
| summarize EventCount = count() by bin(StartTime, 7d)
輸出
| StartTime | EventCount |
|---|---|
| 2007-01-01T00:00:00Z | 16 |
| 2007-01-08T00:00:00Z | 20 |
| 2007-01-29T00:00:00Z | 8 |
| 2007-02-05T00:00:00Z | 1 |
| 2007-02-12T00:00:00Z | 3 |
| ... | ... |
將 新增 | render timechart 至查詢結尾,以將結果可視化。
注意
bin() 與其他 floor() 程式設計語言中的函式類似。 它會將每個值減少到您提供之最接近的模數倍數,並允許 summarize 將數據列指派給群組。
計算最小值、最大值、平均和總和
若要深入瞭解造成作物破壞的暴風雨類型,請計算 每個事件類型的 min()、 max()和 avg() 作物損壞,然後依平均損壞來排序結果。
請注意,您可以在單 summarize 一運算符中使用多個聚合函數來產生數個計算數據行。
StormEvents
| where DamageCrops > 0
| summarize
MaxCropDamage=max(DamageCrops),
MinCropDamage=min(DamageCrops),
AvgCropDamage=avg(DamageCrops)
by EventType
| sort by AvgCropDamage
輸出
| EventType | MaxCropDamage | MinCropDamage | AvgCropDamage |
|---|---|---|---|
| 結霜/凍結 | 568600000 | 3000 | 9106087.5954198465 |
| 野火 | 21000000 | 10000 | 7268333.333333333 |
| 乾旱 | 700000000 | 2000 | 6763977.8761061952 |
| 洪水 | 500000000 | 1000 | 4844925.23364486 |
| 雷暴風 | 22000000 | 100 | 920328.36538461538 |
| ... | ... | ... | ... |
上一個查詢的結果指出,Frost/Freeze 事件平均導致作物損失最多。 然而, bin() 查詢 顯示,農作物受損的事件大多發生在夏季。
使用 sum() 來檢查損毀的作物總數,而不是造成某些損壞的事件數量,如上一個 bin() 查詢中所做的一樣count()。
StormEvents
| where StartTime between (datetime(2007-01-01) .. datetime(2007-12-31))
and DamageCrops > 0
| summarize CropDamage = sum(DamageCrops) by bin(StartTime, 7d)
| render timechart
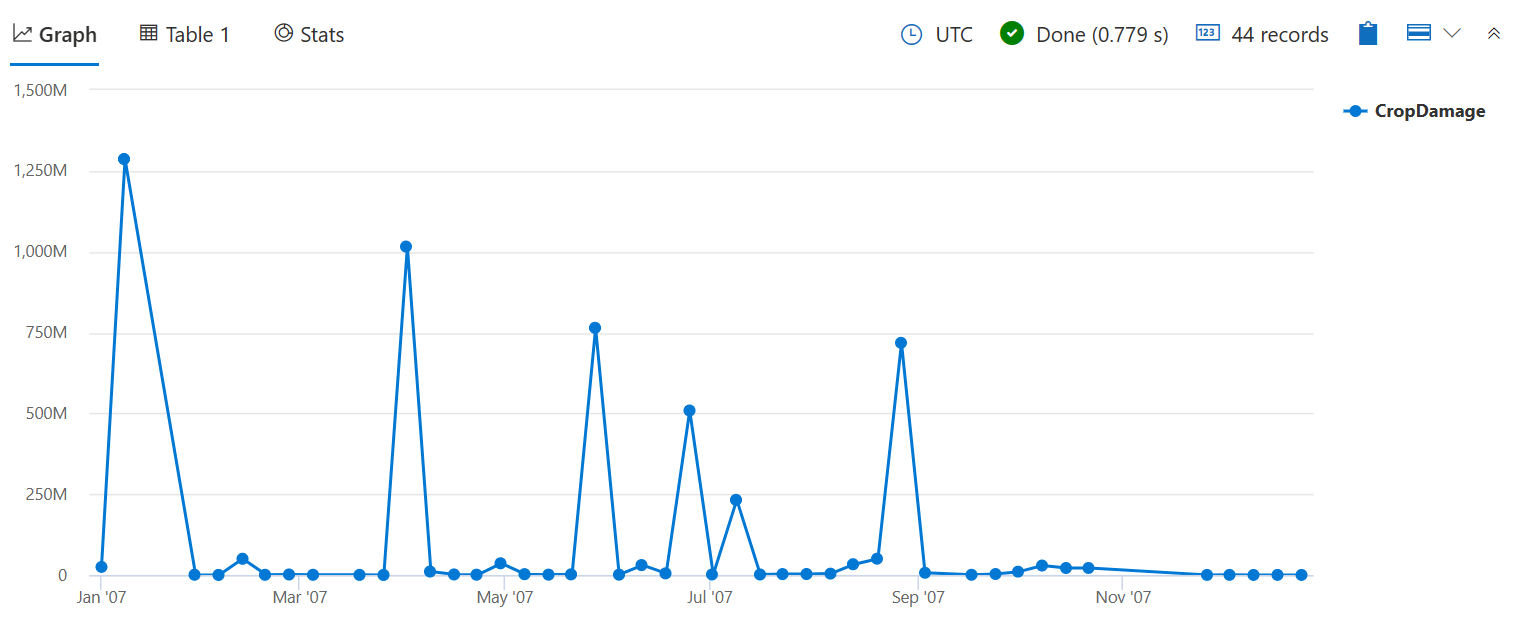
現在,你可以看到1月份的作物破壞高峰,這可能是由於霜凍/凍結。
計算百分比
計算百分比可協助您了解數據內不同值的分佈和比例。 本節涵蓋使用 Kusto 查詢語言 (KQL) 計算百分比的兩個常見方法。
根據兩個數據行計算百分比
使用 count() 和 countif 來尋找導致每個狀態作物損壞的暴風雨事件百分比。 首先,計算每個州中的風暴總數。 然後,計算每個州造成作物損壞的風暴數目。
然後,使用 extend 來計算兩個數據行之間的百分比,將暴風雨數目除以暴風雨總數和乘以 100。
若要確保您取得十進位結果,請在執行除法之前,使用 todouble() 函式,將至少一個整數計數值轉換成雙精度浮點數。
StormEvents
| summarize
TotalStormsInState = count(),
StormsWithCropDamage = countif(DamageCrops > 0)
by State
| extend PercentWithCropDamage =
round((todouble(StormsWithCropDamage) / TotalStormsInState * 100), 2)
| sort by StormsWithCropDamage
輸出
| 州/省 | TotalStormsInState | StormsWithCropDamage | PercentWithCropDamage |
|---|---|---|---|
| 愛荷華州 | 2337 | 359 | 15.36 |
| 內布拉斯加州 | 1766 | 201 | 11.38 |
| 密西西比州 | 1,218 | 105 | 8.62 |
| 北卡羅來那州 | 1721 | 82 | 4.76 |
| 密蘇里州 | 2016 | 78 | 3.87 |
| ... | ... | ... | ... |
注意
計算百分比時,請將除法中至少有一個整數值與 todouble() 或 toreal() 轉換。 這可確保由於整數除法,您不會得到截斷的結果。 如需詳細資訊,請參閱 算術運算的類型規則。
根據數據表大小計算百分比
若要依事件類型比較 storm 數目與資料庫中的 storm 總數,請先將資料庫中的 storm 總數儲存為變數。 Let 語句 可用來定義查詢內的變數。
由於 表格式表達式語句 會傳回表格式結果,請使用 toscalar() 函式,將函式的 count() 表格式結果轉換成純量值。 然後,數值可以在百分比計算中使用。
let TotalStorms = toscalar(StormEvents | summarize count());
StormEvents
| summarize EventCount = count() by EventType
| project EventType, EventCount, Percentage = todouble(EventCount) / TotalStorms * 100.0
輸出
| EventType | EventCount | 百分比 |
|---|---|---|
| 雷暴風 | 13015 | 22.034673077574237 |
| 冰雹 | 12711 | 21.519994582331627 |
| 暴洪 | 3688 | 6.2438627975485055 |
| 乾旱 | 3616 | 6.1219652592015716 |
| 冬季天氣 | 3349 | 5.669928554498358 |
| ... | ... | ... |
擷取唯一值
使用 make_set() 將數據表中的數據列選取範圍轉換成唯一值的陣列。
下列查詢會使用 make_set() 來建立事件類型的陣列,以在每個狀態中造成死亡。 產生的數據表接著會依每個數位中的 storm 類型數目排序。
StormEvents
| where DeathsDirect > 0 or DeathsIndirect > 0
| summarize StormTypesWithDeaths = make_set(EventType) by State
| project State, StormTypesWithDeaths
| sort by array_length(StormTypesWithDeaths)
輸出
| 州/省 | StormTypesWithDeaths |
|---|---|
| 加利福尼亞州 | [“雷暴風”,“高衝浪”,“冷/風寒”,“強風”,“撕裂電流”,“熱”,“過熱”,“野火”,“塵暴”,“天文低潮”,“濃霧”,“冬季天氣”] |
| 德克薩斯州 | [“山洪”、“雷雨風”、“龍捲風”、“閃電”、“洪水”、“冰風暴”、“冬季天氣”、“撕裂電流”、“過大熱”、“濃霧”、“颶風(颱風)”、“冷/風寒”] |
| 奧克拉荷馬州 | [“山洪”、“龍捲風”、“冷/風寒”、“冬季風暴”、“大雪”、“過熱”、“冰雨”、“冬季天氣”、“濃霧”] |
| 紐約州 | [“洪水”,“閃電”,“雷暴風”,“山洪”,“冬季天氣”,“冰暴”,“極端冷/風寒”,“冬季風暴”,“大雪”] |
| 堪薩斯州 | [“雷暴風”、“暴雨”、“龍捲風”、“洪水”、“山洪”、“閃電”、“大雪”、“冬季天氣”、“暴風雪”] |
| ... | ... |
依條件貯體數據
case() 函式會根據指定的條件將數據分組為貯體。 函式會傳回第一個滿足述詞的對應結果表達式,如果沒有滿足任何述詞,則傳回最後一個表達式。
這個範例會根據公民遭受的風暴相關傷害數目來分組。
StormEvents
| summarize InjuriesCount = sum(InjuriesDirect) by State
| extend InjuriesBucket = case (
InjuriesCount > 50,
"Large",
InjuriesCount > 10,
"Medium",
InjuriesCount > 0,
"Small",
"No injuries"
)
| sort by State asc
輸出
| 州/省 | InjuriesCount | InjuriesBucket |
|---|---|---|
| 阿拉巴馬州 | 494 | 大型 |
| 阿拉斯加州 | 0 | 沒有受傷 |
| 美屬薩摩亞 | 0 | 沒有受傷 |
| 亞利桑那州 | 6 | Small |
| 阿肯色州 | 54 | 大型 |
| 大西洋北 | 15 | 中 |
| ... | ... | ... |
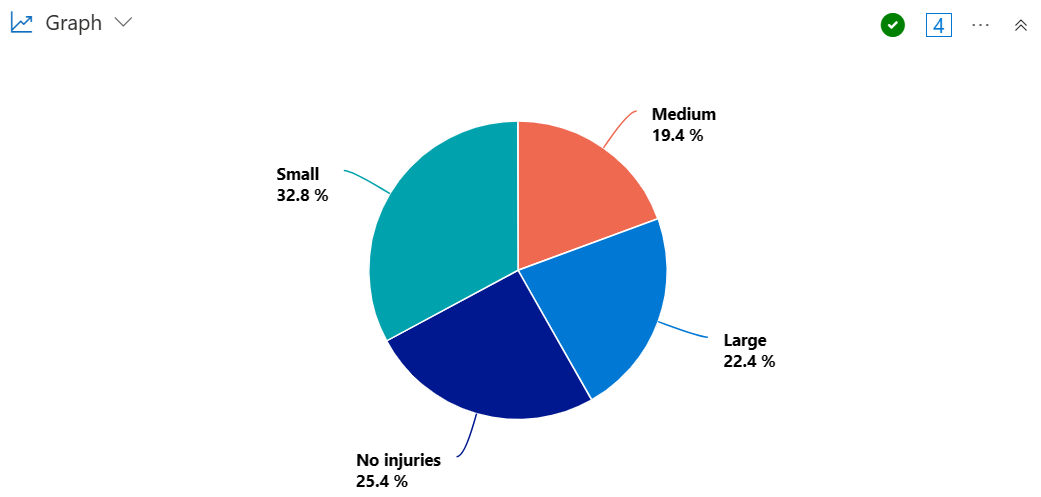
建立餅圖,以可視化出現暴風雨導致大、中型或少量受傷的狀態比例。
StormEvents
| summarize InjuriesCount = sum(InjuriesDirect) by State
| extend InjuriesBucket = case (
InjuriesCount > 50,
"Large",
InjuriesCount > 10,
"Medium",
InjuriesCount > 0,
"Small",
"No injuries"
)
| summarize InjuryBucketByState=count() by InjuriesBucket
| render piechart
在滑動視窗上執行匯總
下列範例示範如何使用滑動視窗摘要數據行。
此查詢會使用七天的滑動視窗,計算龍捲風、洪水和野火的最小、最大值和平均財產損失。 結果集中的每個記錄都會匯總前七天,而結果會在分析期間包含每天的記錄。
以下是查詢的逐步說明:
- 將每筆記錄量化為相對於的單一天
windowStart。 - 將七天新增至 bin 值,以設定每個記錄的範圍結尾。 如果值超出 和
windowEnd的範圍windowStart,請據以調整值。 - 從記錄的目前日期開始,為每個記錄建立七天的陣列。
- 使用mv-expand 從步驟 3 展開陣列,以便將每筆記錄複製到 7 筆記錄,並在兩者之間有一天的間隔。
- 執行每天的匯總。 由於步驟 4,此步驟實際上會摘要前七天。
- 將前七天排除在最終結果中,因為沒有任何七天的回溯期間。
let windowStart = datetime(2007-07-01);
let windowEnd = windowStart + 13d;
StormEvents
| where EventType in ("Tornado", "Flood", "Wildfire")
| extend bin = bin_at(startofday(StartTime), 1d, windowStart) // 1
| extend endRange = iff(bin + 7d > windowEnd, windowEnd,
iff(bin + 7d - 1d < windowStart, windowStart,
iff(bin + 7d - 1d < bin, bin, bin + 7d - 1d))) // 2
| extend range = range(bin, endRange, 1d) // 3
| mv-expand range to typeof(datetime) // 4
| summarize min(DamageProperty), max(DamageProperty), round(avg(DamageProperty)) by Timestamp=bin_at(range, 1d, windowStart), EventType // 5
| where Timestamp >= windowStart + 7d; // 6
輸出
下列結果數據表會截斷。 若要查看完整的輸出,請執行查詢。
| 時間戳記 | EventType | min_DamageProperty | max_DamageProperty | avg_DamageProperty |
|---|---|---|---|---|
| 2007-07-08T00:00:00Z | 龍捲風 | 0 | 30000 | 6905 |
| 2007-07-08T00:00:00Z | 洪水 | 0 | 200000 | 9261 |
| 2007-07-08T00:00:00Z | 野火 | 0 | 200000 | 14033 |
| 2007-07-09T00:00:00Z | 龍捲風 | 0 | 100000 | 14783 |
| 2007-07-09T00:00:00Z | 洪水 | 0 | 200000 | 12529 |
| 2007-07-09T00:00:00Z | 野火 | 0 | 200000 | 14033 |
| 2007-07-10T00:00:00Z | 龍捲風 | 0 | 100000 | 31400 |
| 2007-07-10T00:00:00Z | 洪水 | 0 | 200000 | 12,263 |
| 2007-07-10T00:00:00Z | 野火 | 0 | 200000 | 11694 |
| ... | ... | ... |
後續步驟
現在您已熟悉常見的查詢運算符和聚合函數,請繼續進行下一個教學課程,以瞭解如何從多個數據表聯結數據。