整合 OneLake 與 Azure HDInsight
Azure HDInsight 是一項適用於巨量資料分析的受控雲端式服務,可協助組織處理大量資料。 本教學課程示範如何從 Azure HDInsight 叢集使用 Jupyter Notebook 連線到 OneLake。
使用 Azure HDInsight
從 HDInsight 叢集使用 Jupyter Notebook 連線到 OneLake:
建立 HDInsight (HDI) Apache Spark 叢集。 請遵循下列指示:在 HDInsight 中設定叢集。
提供叢集資訊時,請記住您的叢集登入使用者名稱和密碼,因為您稍後需要這些項目才能存取叢集。
建立使用者指派的受控識別 (UAMI):為 Azure HDInsight 建立 - UAMI,然後在 [儲存體] 畫面中選擇該項目作為身分識別。
![顯示 [儲存體] 畫面中輸入使用者指派的受控識別之位置的螢幕擷取畫面。](media/onelake-azure-hdinsight/create-hdinsight-cluster-storage.png)
將此 UAMI 存取權授與包含您項目的 Fabric 工作區。 如需決定最佳角色的說明,請參閱工作區角色。
瀏覽至您的 Lakehouse,並尋找工作區和 Lakehouse 的名稱。 您可以在 Lakehouse 的 URL 或檔案的 [屬性] 窗格中找到這些名稱。
在 Azure 入口網站中,尋找您的叢集並選取筆記本。
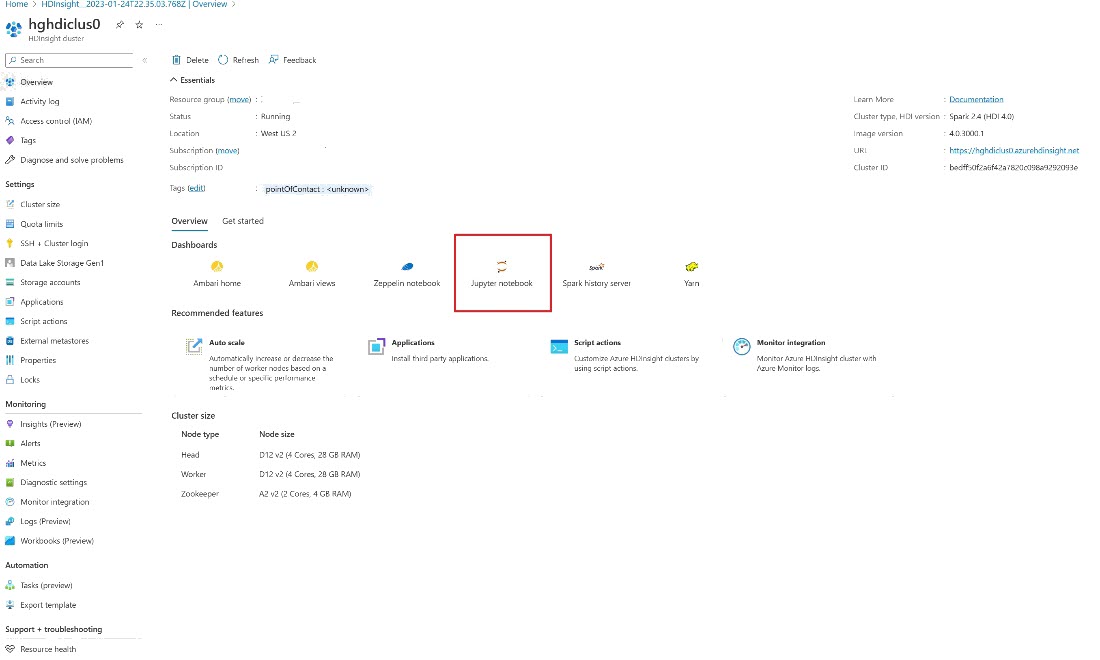
輸入您在建立叢集時所提供的認證資訊。
建立新的 Apache Spark Notebook。
將工作區和 Lakehouse 名稱複製到 Notebook 中,並為 Lakehouse 建置 OneLake URL。 現在您可以從這個檔案路徑讀取任何檔案。
fp = 'abfss://' + 'Workspace Name' + '@onelake.dfs.fabric.microsoft.com/' + 'Lakehouse Name' + '/Files/' df = spark.read.format("csv").option("header", "true").load(fp + "test1.csv") df.show()嘗試將一些資料寫入 Lakehouse。
writecsvdf = df.write.format("csv").save(fp + "out.csv")藉由檢查 Lakehouse 或讀取新載入的檔案,測試您的資料是否已成功寫入。
![顯示 [儲存體] 畫面中輸入使用者指派的受控識別之位置的螢幕擷取畫面。](media/onelake-azure-hdinsight/create-hdinsight-cluster-storage.png#lightbox)



您現在可以在 HDI Spark 叢集中使用 Jupyter Notebook,於 OneLake 中讀取和寫入資料。