建立 Direct Lake 的 Lakehouse
本文說明如何建立 lakehouse、在 Lakehouse 中建立 Delta 數據表,然後在 Microsoft Fabric 工作區中建立 lakehouse 的基本語意模型。
開始建立 Direct Lake 的湖房之前,請務必閱讀 Direct Lake 概觀。
建立 Lakehouse
在 Microsoft Fabric 工作區中,選取 新增>更多選項,然後在 數據工程中,選取 Lakehouse 磚塊。
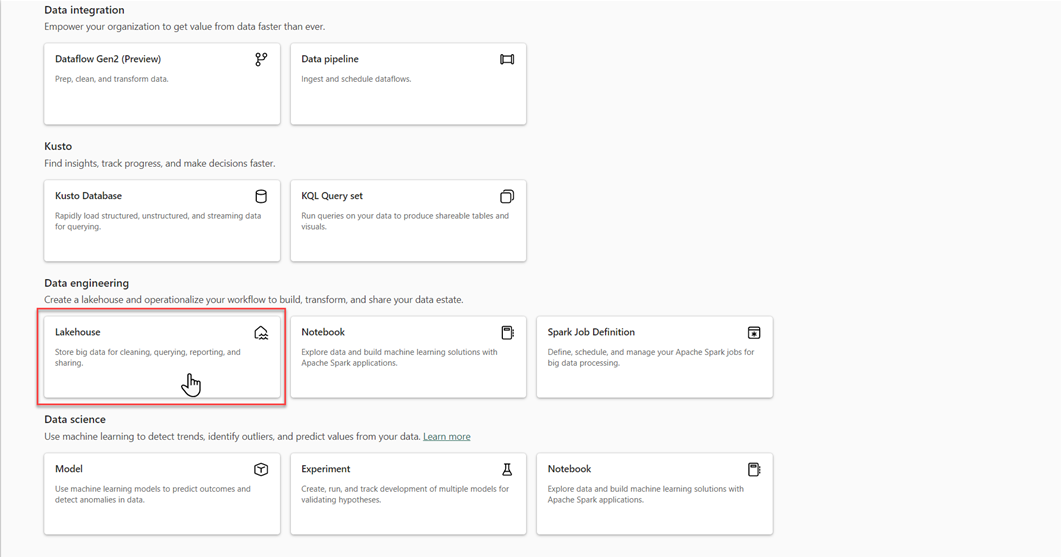
在 [新增 lakehouse] 對話框中,輸入名稱,然後選取 [建立]。 名稱只能包含英文字母、數字和底線。
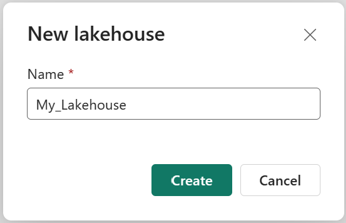
確認已建立新的 Lakehouse 並成功開啟。
在 Lakehouse 中建立 Delta 數據表
建立新的 Lakehouse 之後,您必須建立至少一個 Delta 數據表,讓 Direct Lake 可以存取某些數據。 Direct Lake 可以讀取 parquet 格式的檔案,但為了達到最佳效能,最好使用 VORDER 壓縮方法來壓縮數據。 VORDER 會使用 Power BI 引擎的原生壓縮演算法來壓縮數據。 如此一來,引擎就可以儘快將數據載入記憶體。
有多種選擇可以將資料載入 Lakehouse,例如資料管線和腳本。 下列步驟會使用 PySpark,依據 Azure 開放數據集,將 Delta 數據表新增至資料湖倉。
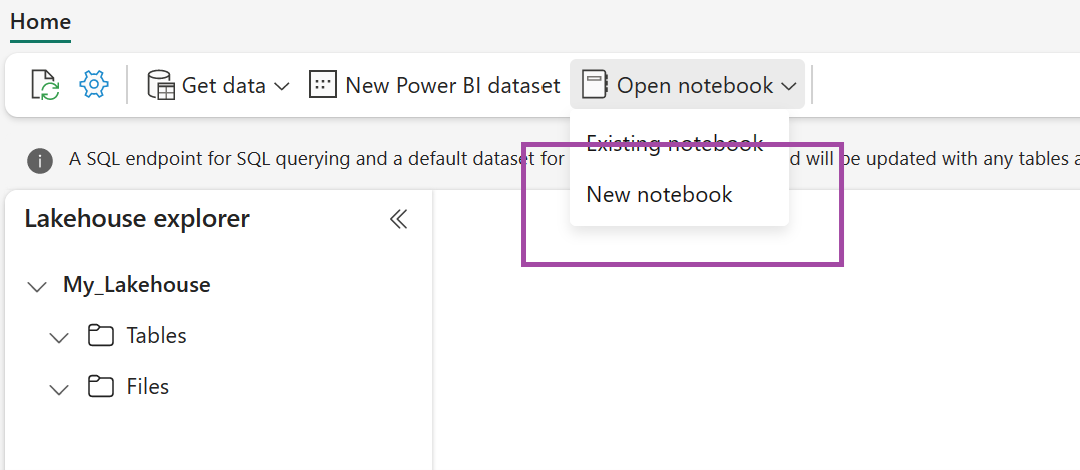
在新建立的 lakehouse 中,選取 [開啟筆記本],然後選取 [新增筆記本]。
將下列代碼段複製並貼到第一個程式代碼數據格中,讓SPARK存取開啟的模型,然後按下 Shift + Enter 以執行程式代碼。
# Azure storage access info blob_account_name = "azureopendatastorage" blob_container_name = "holidaydatacontainer" blob_relative_path = "Processed" blob_sas_token = r"" # Allow SPARK to read from Blob remotely wasbs_path = 'wasbs://%s@%s.blob.core.windows.net/%s' % (blob_container_name, blob_account_name, blob_relative_path) spark.conf.set( 'fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name), blob_sas_token) print('Remote blob path: ' + wasbs_path)確認程式代碼已成功輸出遠端 Blob 路徑。
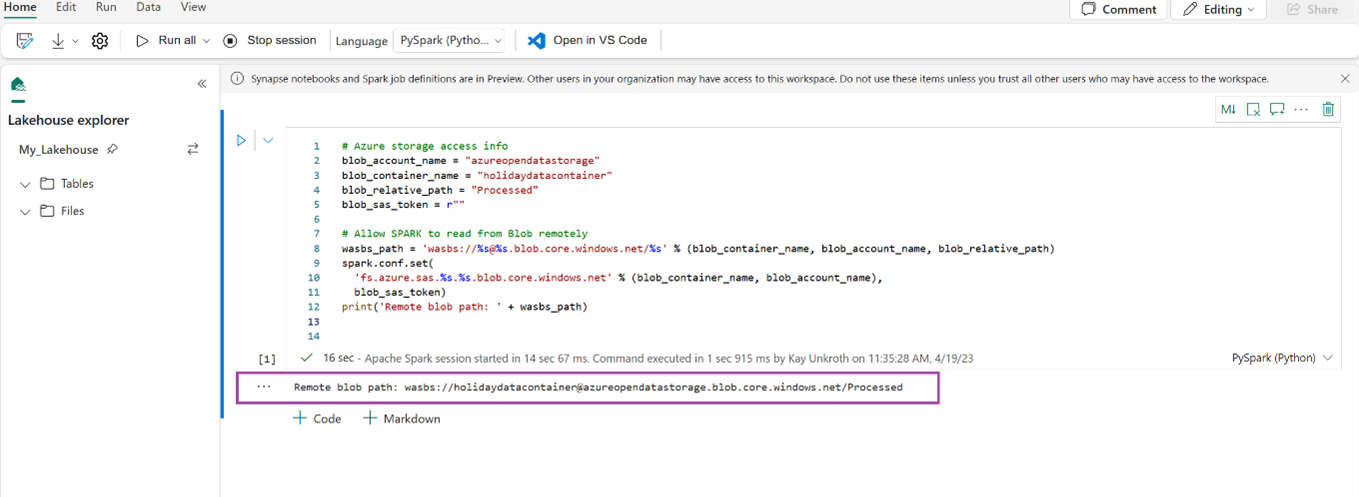
將下列程式代碼複製並貼到下一個資料格中,然後按下 Shift + Enter。
# Read Parquet file into a DataFrame. df = spark.read.parquet(wasbs_path) print(df.printSchema())確認程式代碼已成功輸出 DataFrame 架構。
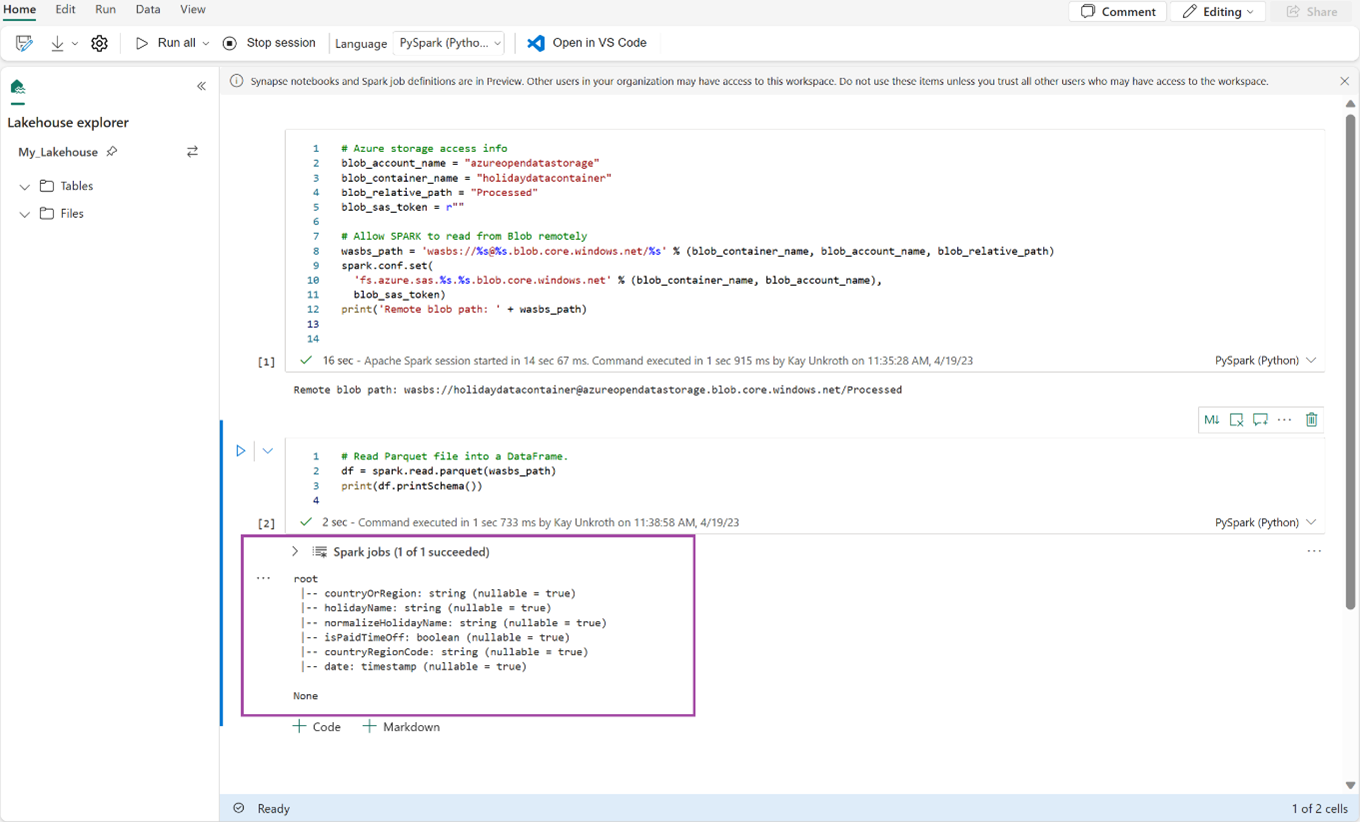
將下列幾行複製並貼到下一個儲存格中,然後按 Shift + Enter。 第一個指令會啟用 VORDER 壓縮方法,而下一個指令會將 DataFrame 儲存為 Lakehouse 中的 Delta 數據表。
# Save as delta table spark.conf.set("spark.sql.parquet.vorder.enabled", "true") df.write.format("delta").saveAsTable("holidays")確認所有SPARK作業都順利完成。 展開SPARK作業清單以檢視更多詳細資料。
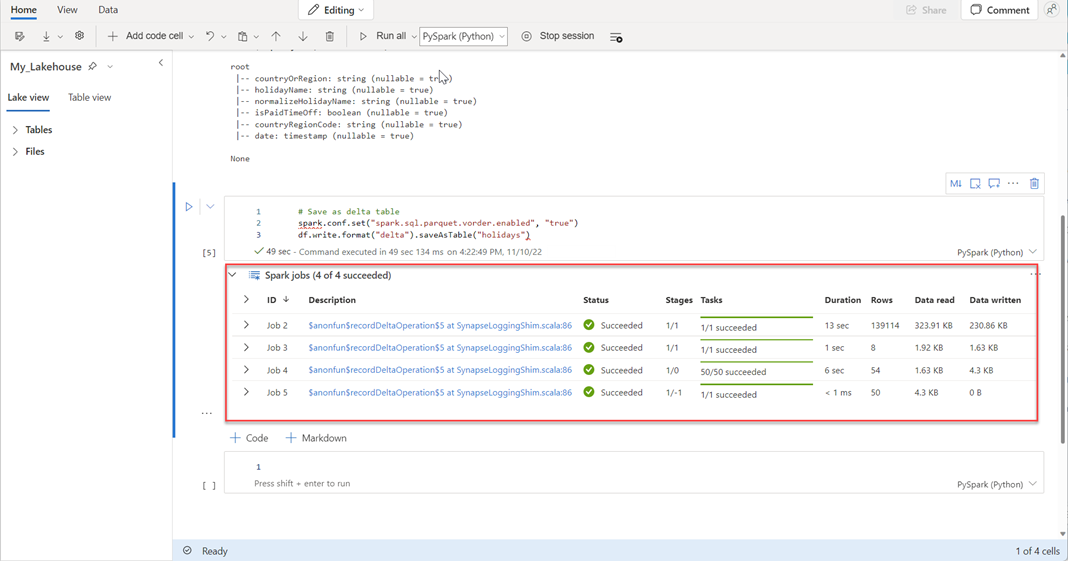
若要確認數據表已成功建立,請在左上方區域中,選取 數據表旁的省略號 (...),然後選取 [重新整理],然後展開 [數據表] 節點。
![顯示 [資料表] 節點附近 [重新整理] 命令的螢幕快照。](media/direct-lake-create-lakehouse/direct-lake-tables-node.png)
使用與上述方法或其他支援的方法相同,為您想要分析的數據新增更多 Delta 數據表。
為您的 Lakehouse 建立基本的 Direct Lake 模型
在 lakehouse 中,選取 [[新增語意模型],然後在對話框中選取要包含的數據表。
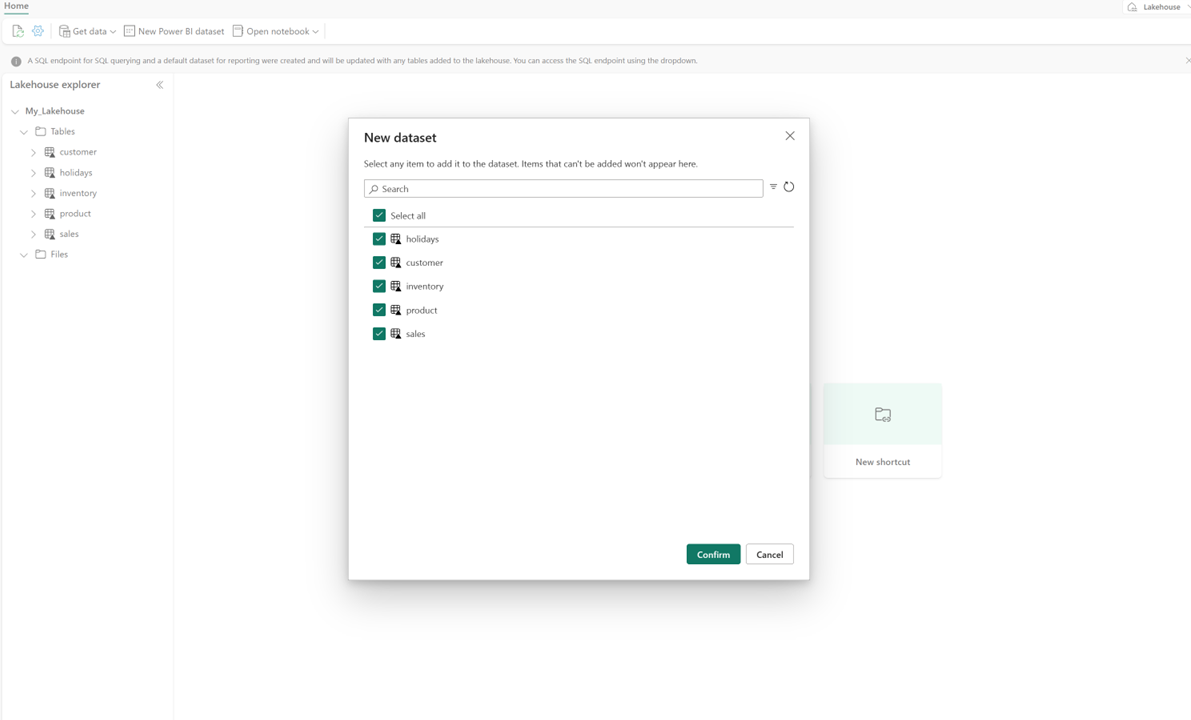
請選取 [確認] 以產生 Direct Lake 模型。 模型會根據您的 Lakehouse 名稱自動儲存在工作區內,然後自動開啟。
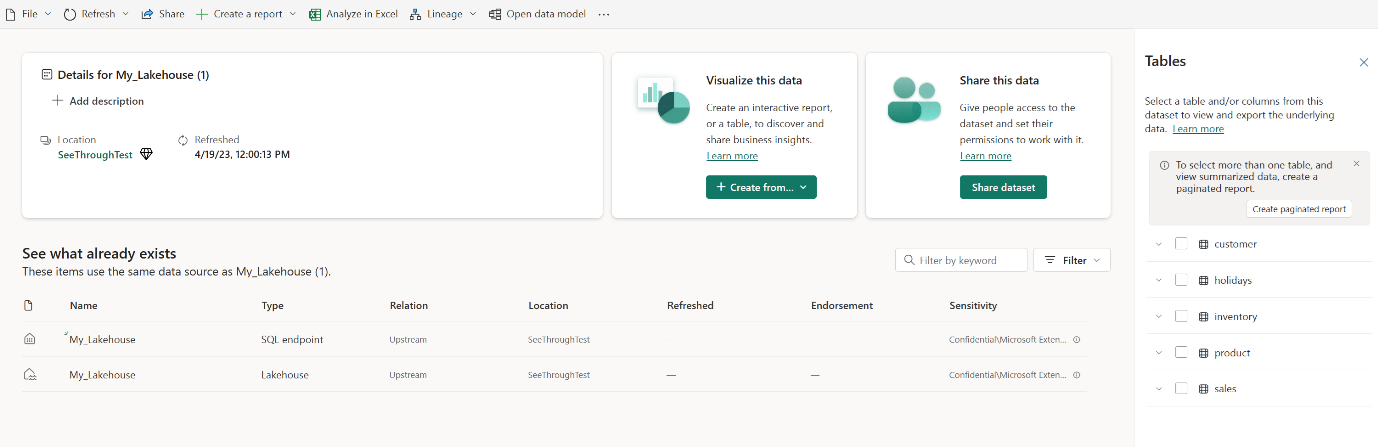
選取 [開啟數據模型 開啟 Web 模型體驗,您可以在其中新增數據表關聯性和 DAX 量值。
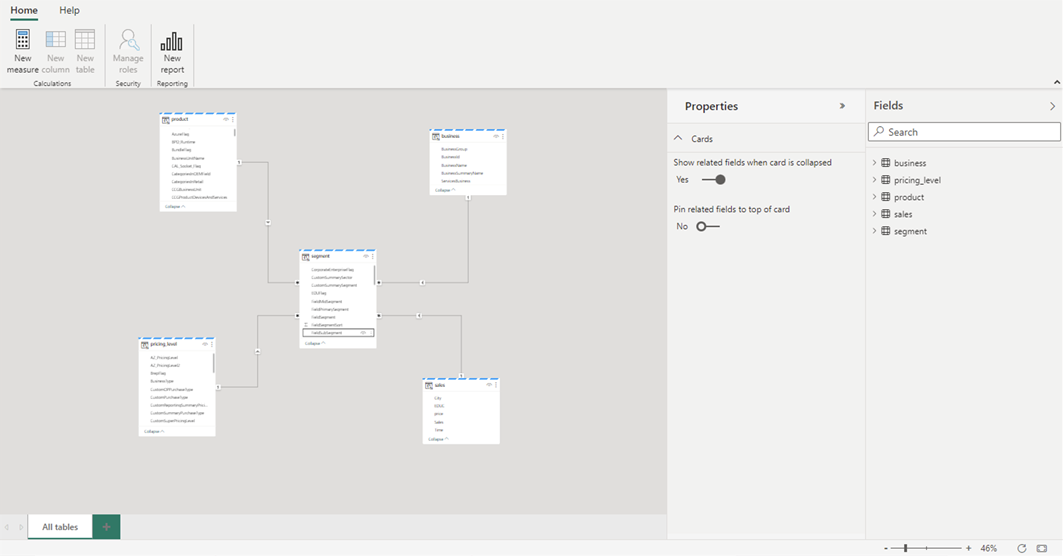
當您完成新增關聯性和 DAX 量值之後,您就可以建立報表、建置複合模型,並以與任何其他模型相同的方式透過 XMLA 端點查詢模型。