開發、評估和評分超市銷售的預測模型
本教學課程提供 Microsoft Fabric 中 Synapse 資料科學工作流程的端對端範例。 此案例會建置預測模型,使用歷史銷售資料來預測超市的產品類別銷售。
預測是銷售中的關鍵資產。 它會結合歷史資料和預測方法,提供未來趨勢的深入解析。 預測可以分析過去的銷售以識別模式,並從取用者行為中學習,以最佳化詳細目錄、生產和行銷策略。 此主動式方法可增強動態市集中企業的適應性、回應能力和整體績效。
本教學課程涵蓋了下列步驟:
- 載入資料
- 使用探索式資料分析來了解和處理資料
- 使用開放原始碼的軟體套件訓練機器學習模型,並使用 MLflow 和 Fabric 自動記錄功能來追蹤實驗
- 儲存最終的機器學習模型,並進行預測
- 使用 Power BI 視覺效果顯示模型效能
必要條件
取得 Microsoft Fabric 訂用帳戶。 或註冊免費的 Microsoft Fabric 試用版。
登入 Microsoft Fabric。
使用首頁左下方的體驗切換器,切換至 Fabric。
![體驗切換器功能表的螢幕擷取畫面,顯示選取 [資料科學] 的位置。](media/tutorial-data-science-prepare-system/switch-to-data-science.png)
- 如有必要,請建立 Microsoft Fabric lakehouse,如在 Microsoft Fabric 中建立 lakehouse 中所述。
遵循筆記本中的指示
您可以選擇下列選項之一,以遵循筆記本中的指示操作:
- 在 Synapse 資料科學體驗中開啟並執行內建筆記本
- 將筆記本從 GitHub 上傳至 Synapse 資料科學體驗
開啟內建筆記本
本教學課程隨範例銷售趨勢預測筆記本。
若要開啟本教學課程的範例筆記本,請遵循 準備系統以進行數據科學教學課程中的指示,。
開始執行程式碼之前,請務必 將 lakehouse 附加至筆記本。
從 GitHub 匯入筆記本
本教學課程隨附 AIsample - Superstore Forecast.ipynb 筆記本。
若要開啟本教學課程隨附的筆記本,請遵循 為數據科學教學課程準備系統的指示, 將筆記本匯入工作區。
如果您想要複製並貼上此頁面中的程式碼,則可以建立新的筆記本。
開始執行程式碼之前,請務必將 Lakehouse 連結至筆記本。
步驟 1:載入資料
資料集包含各種產品的 9,995 個銷售執行個體。 它也包含 21 個屬性。 此資料表來自此筆記本中使用的 Superstore.xlsx 檔案:
| 資料列識別碼 | 訂單識別碼 | 訂單日期 | 出貨日期 | 出貨模式 | 客戶識別碼 | 客戶名稱 | 區段 | Country | 縣/市 | 州/省 | 郵遞區號 | 區域 | 產品識別碼 | 類別 | 子類別 | 產品名稱 | Sales | 數量 | 折扣 | 收益 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 4 | US-2015-108966 | 2015 年 10 月 11 日 | 2015 年 10 月 18 日 | 標準類別 | SO-20335 | Sean O'Donnell | 消費者 | 美國 | 羅德岱堡 | 佛羅里達州 | 33311 | 南 | FUR-TA-10000577 | 傢俱 | 資料表 | retford CR4500 系列超薄矩形資料表 | 957.5775 | 5 | 0.45 | -383.0310 |
| 11 | CA-2014-115812 | 2014 年 6 月 9 日 | 2014 年 6 月 9 日 | 標準類別 | 標準類別 | Brosina Hoffman | 消費者 | 美國 | Los Angeles | 加州 | 90032 | West | FUR-TA-10001539 | 傢俱 | 資料表 | Chromcraft 矩形會議資料表 | 1706.184 | 9 | 0.2 | 85.3092 |
| 31 | US-2015-150630 | 2015 年 9 月 17 日 | 2015 年 9 月 21 日 | 標準類別 | TB-21520 | Tracy Blumstein | 消費者 | 美國 | 費城 | 賓夕法尼亞州 | 19140 | 東 | OFF-EN-10001509 | 辦公用品 | 信封 | Poly 字串系結信封 | 3.264 | 2 | 0.2 | 1.1016 |
定義這些參數,以便您搭配不同的資料集使用此筆記本:
IS_CUSTOM_DATA = False # If TRUE, the dataset has to be uploaded manually
IS_SAMPLE = False # If TRUE, use only rows of data for training; otherwise, use all data
SAMPLE_ROWS = 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_ROOT = "/lakehouse/default"
DATA_FOLDER = "Files/salesforecast" # Folder with data files
DATA_FILE = "Superstore.xlsx" # Data file name
EXPERIMENT_NAME = "aisample-superstore-forecast" # MLflow experiment name
下載資料集並上傳至 Lakehouse
此程式碼會下載公開可用的資料集版本,然後將其儲存在 Fabric Lakehouse 中:
重要
在執行筆記本之前,請確定已將 Lakehouse 新增至筆記本。 否則,您會收到錯誤。
import os, requests
if not IS_CUSTOM_DATA:
# Download data files into the lakehouse if they're not already there
remote_url = "https://synapseaisolutionsa.blob.core.windows.net/public/Forecast_Superstore_Sales"
file_list = ["Superstore.xlsx"]
download_path = "/lakehouse/default/Files/salesforecast/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
設定 MLflow 實驗追蹤
Microsoft Fabric 會在訓練時自動擷取機器學習模型的輸入參數和輸出計量值。 這會擴充 MLflow 自動記錄功能。 此資訊接著會記錄到工作區,以便您使用 MLflow API 或工作區中的對應實驗來存取並視覺化該資訊。 若要深入了解自動記錄,請參閱 Microsoft Fabric 中的自動記錄。
若要關閉筆記本工作階段的 Microsoft Fabric 自動記錄,請呼叫 mlflow.autolog() 並設定 disable=True:
# Set up MLflow for experiment tracking
import mlflow
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(disable=True) # Turn off MLflow autologging
從 Lakehouse 讀取未經處理資料
從 Lakehouse 的 [檔案] 區段讀取未經處理資料。 為不同的日期元件新增更多資料行。 使用相同的資訊來建立資料分割的差異資料表。 由於未經處理資料會儲存為 Excel 檔案,因而您必須使用 pandas 來讀取:
import pandas as pd
df = pd.read_excel("/lakehouse/default/Files/salesforecast/raw/Superstore.xlsx")
步驟 2:執行探索式資料分析
匯入程式庫
在任何分析之前,匯入必要的程式庫:
# Importing required libraries
import warnings
import itertools
import numpy as np
import matplotlib.pyplot as plt
warnings.filterwarnings("ignore")
plt.style.use('fivethirtyeight')
import pandas as pd
import statsmodels.api as sm
import matplotlib
matplotlib.rcParams['axes.labelsize'] = 14
matplotlib.rcParams['xtick.labelsize'] = 12
matplotlib.rcParams['ytick.labelsize'] = 12
matplotlib.rcParams['text.color'] = 'k'
from sklearn.metrics import mean_squared_error,mean_absolute_percentage_error
顯示未經處理資料
手動檢閱資料的子集,以進一步了解資料集本身,並使用 display 函數來列印 DataFrame。 此外,Chart 檢視可以輕鬆地將資料集的子集視覺化。
display(df)
該筆記本主要著重於預測 Furniture 類別銷售。 由此會加速計算,並協助顯示模型的效能。 不過,此筆記本會使用適應性技術。 您可以擴充這些技術來預測其他產品類別的銷售狀況。
# Select "Furniture" as the product category
furniture = df.loc[df['Category'] == 'Furniture']
print(furniture['Order Date'].min(), furniture['Order Date'].max())
預先處理資料
真實世界的商務案例通常需要預測三個不同類別的銷售狀況:
- 特定產品類別
- 特定客戶類別
- 產品類別與客戶類別的特定組合
首先,卸除不必要的資料行以預處理資料。 某些資料行 (Row ID、Order ID、Customer ID 和 Customer Name) 由於沒有影響,沒有必要性。 我們想要針對特定產品類別 (Furniture),預測整個州和區域的整體銷售額,因此我們可以卸除 State、Region、Country、City 和 Postal Code 資料行。 若要預測特定位置或類別的銷售量,您可能需要相應地調整預處理步驟。
# Data preprocessing
cols = ['Row ID', 'Order ID', 'Ship Date', 'Ship Mode', 'Customer ID', 'Customer Name',
'Segment', 'Country', 'City', 'State', 'Postal Code', 'Region', 'Product ID', 'Category',
'Sub-Category', 'Product Name', 'Quantity', 'Discount', 'Profit']
# Drop unnecessary columns
furniture.drop(cols, axis=1, inplace=True)
furniture = furniture.sort_values('Order Date')
furniture.isnull().sum()
資料集按天構建。 我們必須重新取樣資料行 Order Date,因為我們想要開發模型,按月預測銷售額。
首先,依 Furniture 將 Order Date 類別分組。 然後,計算每個群組的 Sales 資料行總和,以判定每個唯一 Order Date 值的總銷售額。 使用 Sales 頻率重新取樣 MS 資料行,按月彙總資料。 最後,計算每個月的平均銷售值。
# Data preparation
furniture = furniture.groupby('Order Date')['Sales'].sum().reset_index()
furniture = furniture.set_index('Order Date')
furniture.index
y = furniture['Sales'].resample('MS').mean()
y = y.reset_index()
y['Order Date'] = pd.to_datetime(y['Order Date'])
y['Order Date'] = [i+pd.DateOffset(months=67) for i in y['Order Date']]
y = y.set_index(['Order Date'])
maximim_date = y.reset_index()['Order Date'].max()
展示 Order Date 對 Sales 類別的 Furniture 的影響:
# Impact of order date on the sales
y.plot(figsize=(12, 3))
plt.show()
在進行任何統計分析之前,須匯入 statsmodels Python 模組。 它提供類別和函數來估自許多統計模型。 它也提供類別和函數來執行統計測試和統計資料探索。
import statsmodels.api as sm
執行統計分析
時間序列會依設定間隔追蹤這些資料元素,以判定時間序列模式中這些元素的變化:
層級:代表特定時段平均值的基本元件
趨勢:描述時間序列是否隨著時間減少、保持不變或增加
季節性:描述時間序列中的週期性訊號,並尋找影響增加或減少時間序列模式的週期性發生
雜訊/殘差:是指模型無法解釋的時間序列資料中的隨機波動和變異性。
在此程式碼中,您會在預處理之後觀察資料集的那些元素:
# Decompose the time series into its components by using statsmodels
result = sm.tsa.seasonal_decompose(y, model='additive')
# Labels and corresponding data for plotting
components = [('Seasonality', result.seasonal),
('Trend', result.trend),
('Residual', result.resid),
('Observed Data', y)]
# Create subplots in a grid
fig, axes = plt.subplots(nrows=4, ncols=1, figsize=(12, 7))
plt.subplots_adjust(hspace=0.8) # Adjust vertical space
axes = axes.ravel()
# Plot the components
for ax, (label, data) in zip(axes, components):
ax.plot(data, label=label, color='blue' if label != 'Observed Data' else 'purple')
ax.set_xlabel('Time')
ax.set_ylabel(label)
ax.set_xlabel('Time', fontsize=10)
ax.set_ylabel(label, fontsize=10)
ax.legend(fontsize=10)
plt.show()
這些繪圖描述預測資料中的季節性、趨勢和雜訊。 您可以擷取基礎模式,並開發讓精確預測可適應隨機波動的模型。
步驟 3:訓練和追蹤模型
現在您已擁有可用的資料,請定義預測模型。 在此筆記本中,套用稱為具有外生因素的季節性自動迴歸整合式移動平均 (SARIMAX) 的預測模型。 SARIMAX 結合了自動迴歸 (AR) 和移動平均 (MA) 元件、季節性差異,以及外部預測器,以針對時間序列資料進行精確且靈活的預測。
您也可使用 MLflow 和 Fabric 自動記錄來追蹤實驗。 在這裡,從 Lakehouse 載入差異資料表。 您可以使用將 Lakehouse 視為來源的其他差異資料表。
# Import required libraries for model evaluation
from sklearn.metrics import mean_squared_error, mean_absolute_percentage_error
調整超參數
SARIMAX 會考慮一般自動迴歸整合式移動平均 (ARIMA) 模式 (p、d、q) 所涉及的參數,並新增季節性參數 (P、D、Q、s)。 這些 SARIMAX 模型引數分別稱為順序 (p、d、q) 和季節性順序 (P、D、Q、s)。 因此,若要訓練模型,我們必須先微調七個參數。
順序參數:
p:AR 元件的順序,代表用來預測目前值的時間序列中過去觀察的數目。一般來說,該參數應該是非負整數。 一般值的範圍是
0至3,不過也可能會有較高的值,視特定的資料特性而定。p值越高,表示模型中對過去值的記憶越長。d:差異順序,代表了時間序列需要差異的次數,以達到固定性。該參數應該是非負整數。 一般值的範圍是
0到2。d的0值表示時間序列已經固定。 較高的值表示使其固定所需的差異作業次數。q:AR 元件的順序,代表用來預測目前值的過去白雜訊誤差項的數目。該參數應該是非負整數。 一般值的範圍為
0至3,但某些時間序列可能需要較高的值。 較高的q值表示更依賴過去的誤差項來進行預測。
季節性順序參數:
-
P:AR 元件的季節性順序,類似於p,但針對季節性部分 -
D:差異的季節性順序,類似於d,但針對季節性部分 -
Q:MA 元件的季節性順序,類似於q,但針對季節性部分 -
s:每個季節性週期的時間步數 (例如,對於每年季節性的月度資料,時間步數為 12 步)
# Hyperparameter tuning
p = d = q = range(0, 2)
pdq = list(itertools.product(p, d, q))
seasonal_pdq = [(x[0], x[1], x[2], 12) for x in list(itertools.product(p, d, q))]
print('Examples of parameter combinations for Seasonal ARIMA...')
print('SARIMAX: {} x {}'.format(pdq[1], seasonal_pdq[1]))
print('SARIMAX: {} x {}'.format(pdq[1], seasonal_pdq[2]))
print('SARIMAX: {} x {}'.format(pdq[2], seasonal_pdq[3]))
print('SARIMAX: {} x {}'.format(pdq[2], seasonal_pdq[4]))
SARIMAX 還有其他參數:
enforce_stationarity:在調整 SARIMAX 模型之前,模型是否應該對時間序列資料強制執行固定性。如果
enforce_stationarity設定為True(預設值),則表示 SARIMAX 模型應該對時間序列資料強制執行固定性。 然後,SARIMAX 模型會自動將差異套用至資料,使其固定,如d和D順序所指定,然後再調整模型。 這是常見的做法,因為許多時間序列模型,包括 SARIMAX,假設資料是固定的。對於非固定時間序列 (例如,它呈現趨勢或季節性),最好將
enforce_stationarity設定為True,並讓 SARIMAX 模型處理差異,以達到固定性。 針對固定時間序列 (例如,沒有趨勢或季節性的序列),設定enforce_stationarity為False,以避免不必要的差異。enforce_invertibility:控制模型是否應該在最佳化程序期間,對估計的參數強制執行可逆性。如果
enforce_invertibility設定為True(預設值),則表示 SARIMAX 模型應該在估計的參數上強制執行可逆性。 可逆性可確保模型已妥善定義,且預估的 AR 和 MA 係數落在固定性範圍內。強制執行可逆性有助於確保 SARIMAX 模型符合穩定時間序列模型的理論需求。 它也有助於防止模型估計與穩定性的問題。
預設為 AR(1) 模型。 這是指 (1, 0, 0)。 不過,慣常的做法是嘗試順序參數和季節性順序參數的不同組合,並評估資料集的模型效能。 適當的值會因時間序列而異。
判定最佳值通常牽涉到分析時間序列資料的自動更正函數 (ACF) 和部分自動更正函數。 它通常也涉及使用模型選取準則 - 例如,Akaike 資訊準則 (AIC) 或 Bayesian 資訊準則 (BIC)。
微調超參數:
# Tune the hyperparameters to determine the best model
for param in pdq:
for param_seasonal in seasonal_pdq:
try:
mod = sm.tsa.statespace.SARIMAX(y,
order=param,
seasonal_order=param_seasonal,
enforce_stationarity=False,
enforce_invertibility=False)
results = mod.fit(disp=False)
print('ARIMA{}x{}12 - AIC:{}'.format(param, param_seasonal, results.aic))
except:
continue
評估上述結果之後,您可以判定順序參數和季節性順序參數的值。 選擇是 order=(0, 1, 1) 和 seasonal_order=(0, 1, 1, 12),提供了最低的 AIC (例如 279.58)。 使用這些值來訓練模型。
訓練模型
# Model training
mod = sm.tsa.statespace.SARIMAX(y,
order=(0, 1, 1),
seasonal_order=(0, 1, 1, 12),
enforce_stationarity=False,
enforce_invertibility=False)
results = mod.fit(disp=False)
print(results.summary().tables[1])
此程式碼會將傢俱銷售資料的時間序列預測視覺化。 繪製的結果會顯示觀察到的資料和提前一個步驟的預測,以及信賴區間的陰影區域。
# Plot the forecasting results
pred = results.get_prediction(start=maximim_date, end=maximim_date+pd.DateOffset(months=6), dynamic=False) # Forecast for the next 6 months (months=6)
pred_ci = pred.conf_int() # Extract the confidence intervals for the predictions
ax = y['2019':].plot(label='observed')
pred.predicted_mean.plot(ax=ax, label='One-step ahead forecast', alpha=.7, figsize=(12, 7))
ax.fill_between(pred_ci.index,
pred_ci.iloc[:, 0],
pred_ci.iloc[:, 1], color='k', alpha=.2)
ax.set_xlabel('Date')
ax.set_ylabel('Furniture Sales')
plt.legend()
plt.show()
# Validate the forecasted result
predictions = results.get_prediction(start=maximim_date-pd.DateOffset(months=6-1), dynamic=False)
# Forecast on the unseen future data
predictions_future = results.get_prediction(start=maximim_date+ pd.DateOffset(months=1),end=maximim_date+ pd.DateOffset(months=6),dynamic=False)
使用 predictions 來評定模型的效能,方法是將模型與實際值進行對比。
predictions_future 值表示未來的預測。
# Log the model and parameters
model_name = f"{EXPERIMENT_NAME}-Sarimax"
with mlflow.start_run(run_name="Sarimax") as run:
mlflow.statsmodels.log_model(results,model_name,registered_model_name=model_name)
mlflow.log_params({"order":(0,1,1),"seasonal_order":(0, 1, 1, 12),'enforce_stationarity':False,'enforce_invertibility':False})
model_uri = f"runs:/{run.info.run_id}/{model_name}"
print("Model saved in run %s" % run.info.run_id)
print(f"Model URI: {model_uri}")
mlflow.end_run()
# Load the saved model
loaded_model = mlflow.statsmodels.load_model(model_uri)
步驟 4:給模型評分並儲存預測
整合實際值與預測值,以建立 Power BI 報表。 將這些結果儲存在 Lakehouse 內的資料表中。
# Data preparation for Power BI visualization
Future = pd.DataFrame(predictions_future.predicted_mean).reset_index()
Future.columns = ['Date','Forecasted_Sales']
Future['Actual_Sales'] = np.NAN
Actual = pd.DataFrame(predictions.predicted_mean).reset_index()
Actual.columns = ['Date','Forecasted_Sales']
y_truth = y['2023-02-01':]
Actual['Actual_Sales'] = y_truth.values
final_data = pd.concat([Actual,Future])
# Calculate the mean absolute percentage error (MAPE) between 'Actual_Sales' and 'Forecasted_Sales'
final_data['MAPE'] = mean_absolute_percentage_error(Actual['Actual_Sales'], Actual['Forecasted_Sales']) * 100
final_data['Category'] = "Furniture"
final_data[final_data['Actual_Sales'].isnull()]
input_df = y.reset_index()
input_df.rename(columns = {'Order Date':'Date','Sales':'Actual_Sales'}, inplace=True)
input_df['Category'] = 'Furniture'
input_df['MAPE'] = np.NAN
input_df['Forecasted_Sales'] = np.NAN
# Write back the results into the lakehouse
final_data_2 = pd.concat([input_df,final_data[final_data['Actual_Sales'].isnull()]])
table_name = "Demand_Forecast_New_1"
spark.createDataFrame(final_data_2).write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
步驟 5:Power BI 中的視覺化
Power BI 報表顯示平均絕對百分比誤差 (MAPE) 為 16.58。 MAPE 計量定義預測方法的精確度。 相較於實際數量,它代表了預測數量的正確性。
MAPE 是直接的計量。 不論偏差是正數還是負值,10% MAPE 代表預測值與實際值之間的平均偏差是 10%。 理想的 MAPE 值標準會因產業而異。
此圖表中的淺藍色線條代表了實際的銷售值。 深藍色線條代表了預測的銷售值。 實際和預測銷售的比較顯示,該模型有效地預測了 2023 年前 6 個月 Furniture 類別的銷售額。
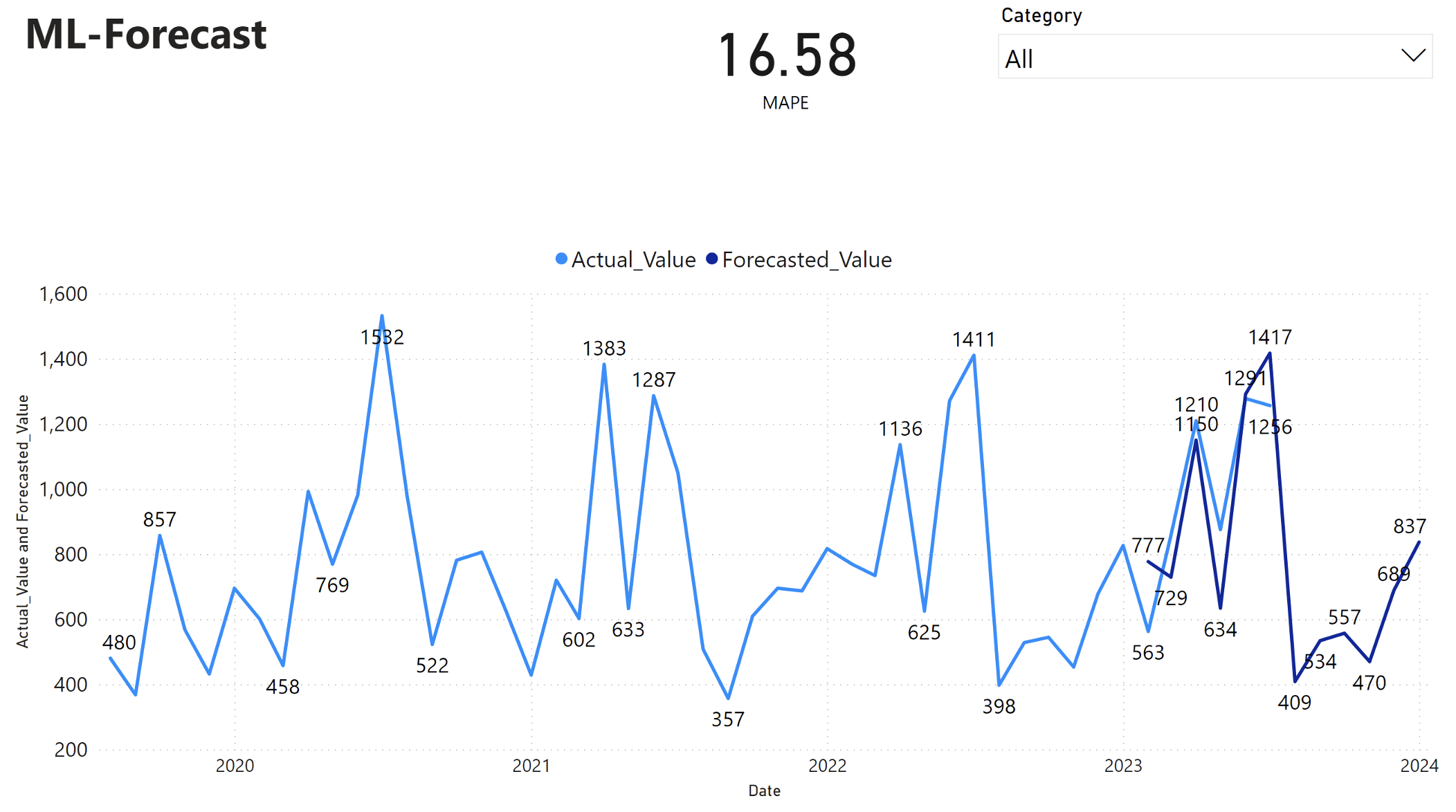
根據此觀察結果,我們可以對模型就 2023 年後 6 個月的整體銷售額,甚至延伸至 2024 年的預測充滿信心。 這種信心可以為詳細目錄管理、原材料採購和其他商務相關考慮的戰略決策提供資訊。