使用 Microsoft Fabric 中的 PREDICT 進行機器學習模型評分
Microsoft Fabric 可讓使用者使用可調整的 PREDICT 函式來操作機器學習模型。 此函式支援任何計算引擎中的批次評分。 用戶可以直接從Microsoft網狀架構筆記本或指定 ML 模型的專案頁面產生批次預測。
在本文中,您將瞭解如何自行撰寫程式代碼,或使用可為您處理批次評分的引導式 UI 體驗來套用 PREDICT。
必要條件
取得 Microsoft Fabric 訂用帳戶。 或註冊免費的 Microsoft Fabric 試用版。
登入 Microsoft Fabric。
使用首頁左下方的體驗切換器,切換至 Fabric。
![體驗切換器功能表的螢幕擷取畫面,顯示選取 [資料科學] 的位置。](media/tutorial-data-science-prepare-system/switch-to-data-science.png)
限制
- 目前支援此有限 ML 模型類別集的 PREDICT 函式:
- CatBoost
- Keras
- LightGBM
- ONNX
- Prophet
- PyTorch
- Sklearn
- Spark
- Statsmodels
- TensorFlow
- XGBoost
- PREDICT 會要求您 以 MLflow 格式儲存 ML 模型,並填入其簽章
- PREDICT 不支援 具有多張量輸入或輸出的 ML 模型
從筆記本呼叫 PREDICT
PREDICT 支援 Microsoft Fabric 登錄中的 MLflow 封裝模型。 如果您的工作區中有已定型且已註冊的 ML 模型,您可以跳至步驟 2。 如果沒有,步驟 1 會提供範例程式碼來引導您定型範例羅吉斯迴歸模型。 您可使用此模型在程序結尾產生批次預測。
定型 ML 模型,並將其註冊到 MLflow。 下一個程式代碼範例會使用 MLflow API 來建立機器學習實驗,然後針對 scikit-learn 羅吉斯回歸模型啟動 MLflow 執行。 然後,模型版本會在 Microsoft Fabric 登錄中儲存並註冊。 如需定型模型和追蹤您自己的實驗的詳細資訊,請流覽如何使用scikit-learn資源來定型ML模型。
import mlflow import numpy as np from sklearn.linear_model import LogisticRegression from sklearn.datasets import load_diabetes from mlflow.models.signature import infer_signature mlflow.set_experiment("diabetes-demo") with mlflow.start_run() as run: lr = LogisticRegression() data = load_diabetes(as_frame=True) lr.fit(data.data, data.target) signature = infer_signature(data.data, data.target) mlflow.sklearn.log_model( lr, "diabetes-model", signature=signature, registered_model_name="diabetes-model" )將測試資料載入至 Spark DataFrame。 若要使用上一個步驟中定型的 ML 模型產生批次預測,您需要以 Spark DataFrame 的形式測試數據。 在下列程式代碼中,以您自己的數據取代
test變數值。# You can substitute "test" below with your own data test = spark.createDataFrame(data.frame.drop(['target'], axis=1))建立
MLFlowTransformer物件,載入 ML 模型以進行推斷。 若要建立MLFlowTransformer物件來產生批次預測,您必須執行下列動作:-
test指定您需要作為模型輸入的 DataFrame 資料列(在此案例中,全部都是) - 選擇新輸出資料列的名稱(在此案例中為
predictions) - 提供正確的模型名稱和模型版本來產生這些預測。
如果您使用自己的 ML 模型,請以輸入資料行、輸出資料行名稱、模型名稱和模型版本取代值。
from synapse.ml.predict import MLFlowTransformer # You can substitute values below for your own input columns, # output column name, model name, and model version model = MLFlowTransformer( inputCols=test.columns, outputCol='predictions', modelName='diabetes-model', modelVersion=1 )-
使用 PREDICT 函式產生預測。 若要叫用 PREDICT 函式,請使用轉換器 API、Spark SQL API 或 PySpark 使用者定義函式 (UDF)。 下列各節說明如何使用不同的方法來叫用 PREDICT 函式,利用先前步驟中定義的測試數據和 ML 模型來產生批次預測。
具有轉換器 API 的 PREDICT
此程式代碼會使用轉換器 API 叫用 PREDICT 函式。 如果您使用自己的 ML 模型,請取代模型和測試資料的值。
# You can substitute "model" and "test" below with values
# for your own model and test data
model.transform(test).show()
具有 Spark SQL API 的 PREDICT
此程式代碼會使用 Spark SQL API 叫用 PREDICT 函式。 如果您使用自己的 ML 模型,請將、 model_name和 model_version 的值取代為您的features模型名稱、模型版本和功能數據行。
注意
使用 Spark SQL API 進行預測產生仍然需要建立 MLFlowTransformer 物件(如步驟 3 所示)。
from pyspark.ml.feature import SQLTransformer
# You can substitute "model_name," "model_version," and "features"
# with values for your own model name, model version, and feature columns
model_name = 'diabetes-model'
model_version = 1
features = test.columns
sqlt = SQLTransformer().setStatement(
f"SELECT PREDICT('{model_name}/{model_version}', {','.join(features)}) as predictions FROM __THIS__")
# You can substitute "test" below with your own test data
sqlt.transform(test).show()
具有使用者定義函數 的 PREDICT
此程式代碼會使用 PySpark UDF 叫用 PREDICT 函式。 如果您使用自己的 ML 模型,請取代模型和功能的值。
from pyspark.sql.functions import col, pandas_udf, udf, lit
# You can substitute "model" and "features" below with your own values
my_udf = model.to_udf()
features = test.columns
test.withColumn("PREDICT", my_udf(*[col(f) for f in features])).show()
從 ML 模型的項目頁面產生 PREDICT 程式碼
從任何 ML 模型的項目頁面中,您可以使用 PREDICT 函式,選擇下列其中一個選項來啟動特定模型版本的批次預測產生:
- 將程式代碼範本複製到筆記本,並自行自定義參數
- 使用引導式 UI 體驗來產生 PREDICT 程式碼
使用引導式 UI 體驗
引導式 UI 體驗會逐步引導您完成下列步驟:
- 選取源數據以進行評分
- 將數據正確對應至 ML 模型輸入
- 指定模型輸出的目的地
- 建立使用 PREDICT 來產生並儲存預測結果的筆記本
要使用引導式體驗,
流覽至指定 ML 模型版本的項目頁面。
從 [ 套用此版本] 下拉式清單中,選取 [ 在精靈中套用此模型]。
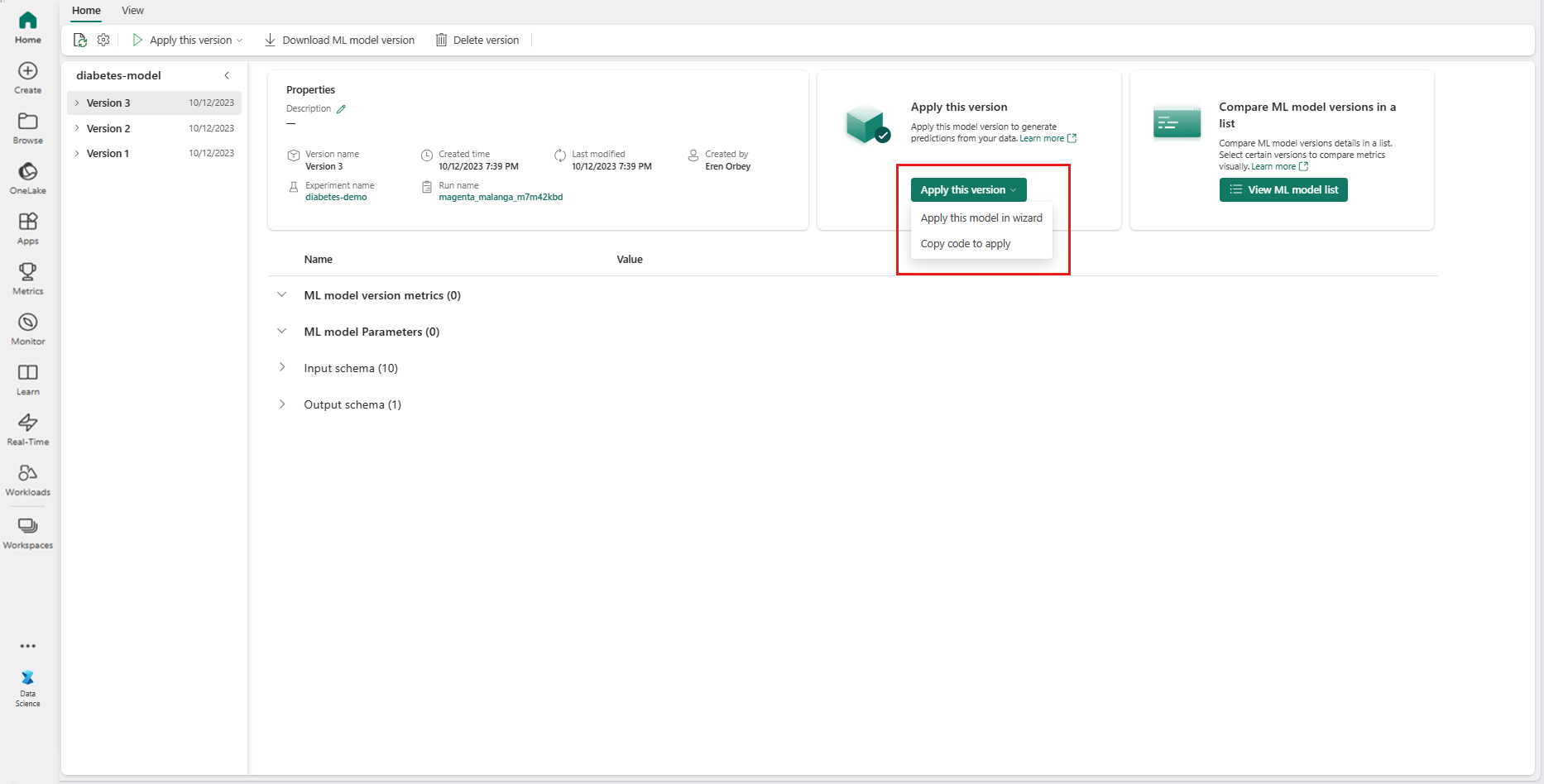
在 [選取輸入數據表] 步驟中,[套用 ML 模型預測] 視窗隨即開啟。
從您目前工作區中的 Lakehouse 選取輸入數據表。
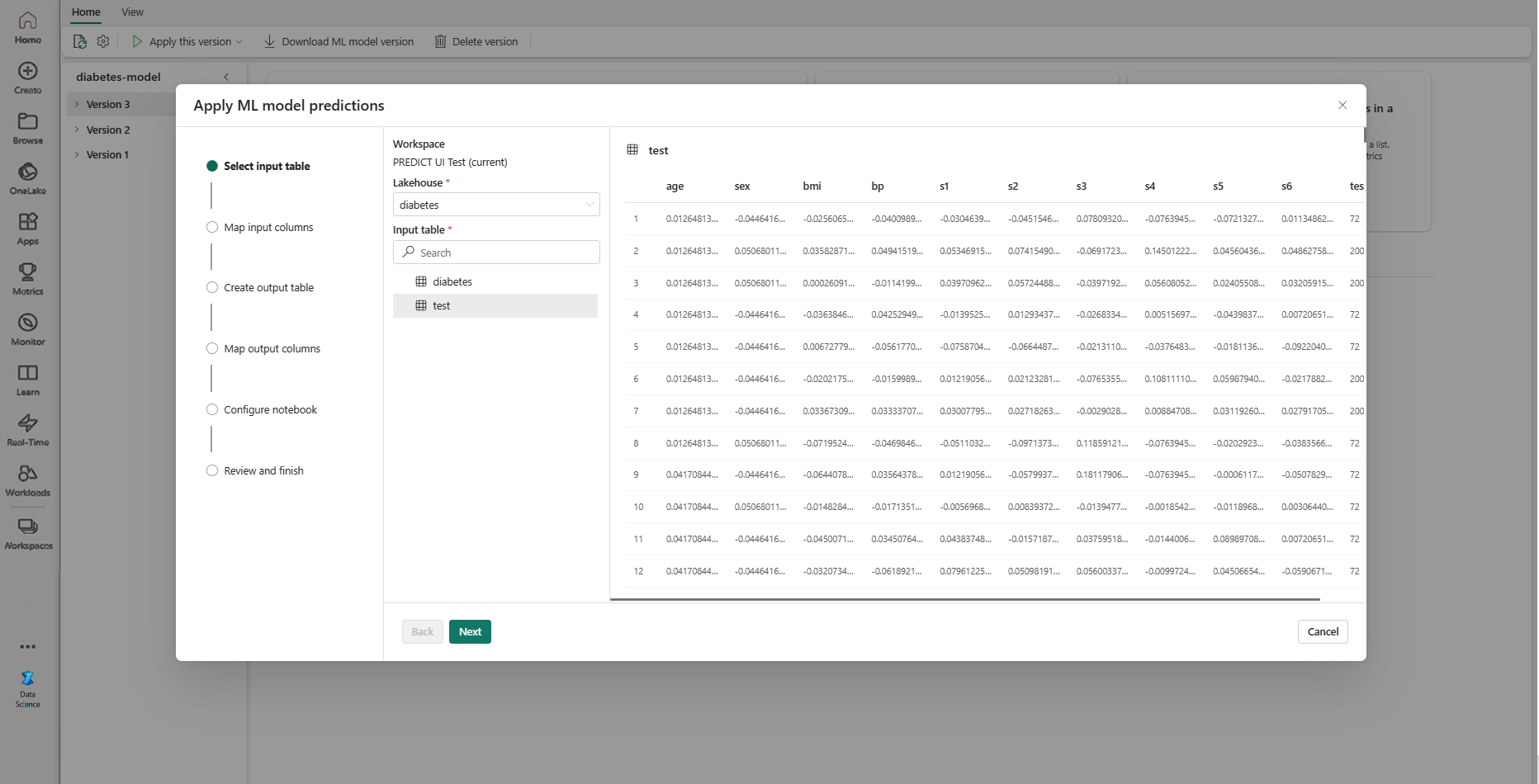
選取 [下一步] 以移至 [對應輸入資料行] 步驟。
將源數據表的數據行名稱對應至 ML 模型的輸入欄位,這些欄位是從模型的簽章提取而來。 您必須為模型的所有必要欄位提供輸入資料列。 此外,源數據行數據類型必須符合模型的預期數據類型。
提示
如果輸入數據表數據行的名稱符合 ML 模型簽章中記錄的數據行名稱,精靈會預先填入此對應。
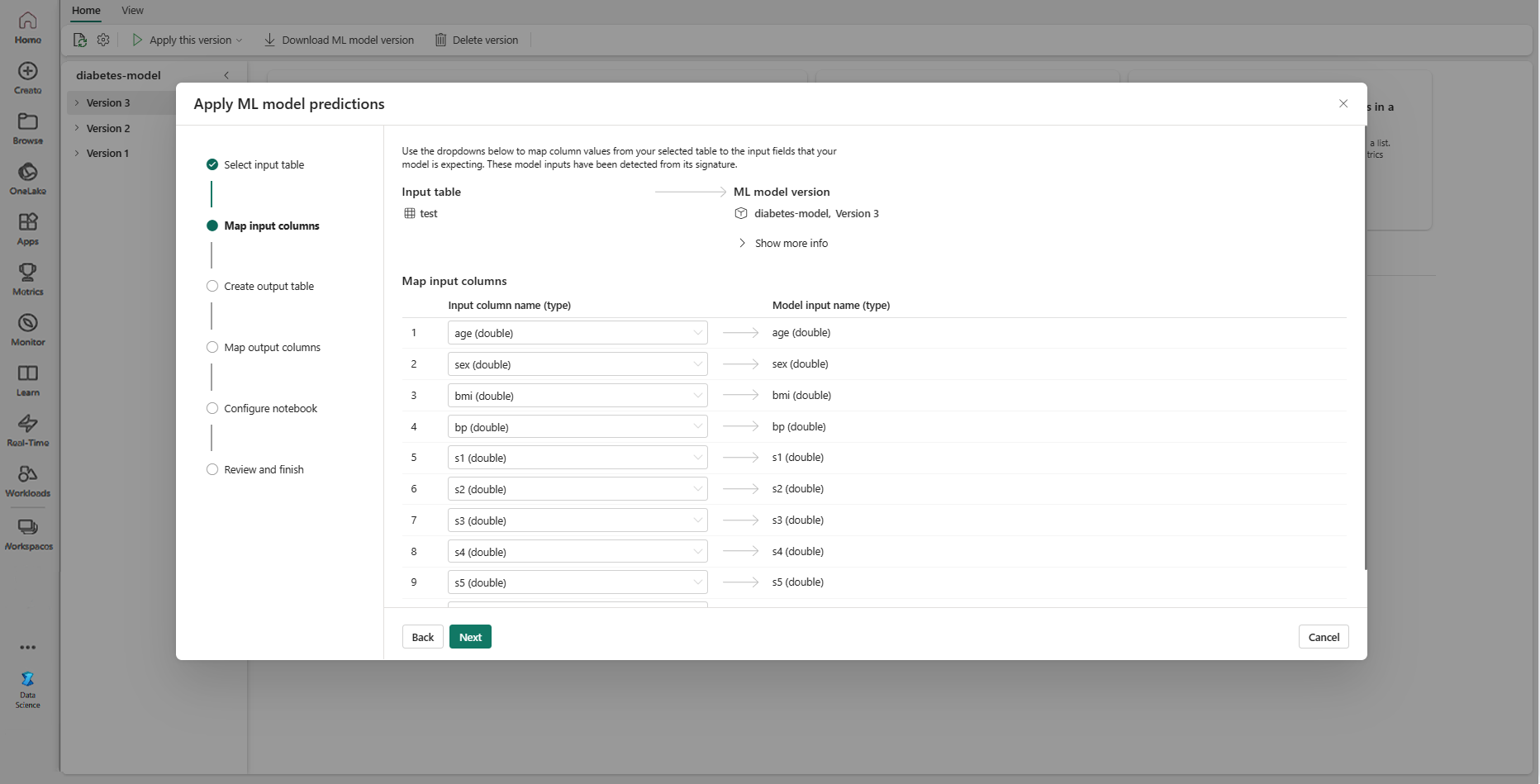
選取 [下一步] 以移至 [建立輸出資料表] 步驟。
提供目前工作區所選 Lakehouse 內新資料表的名稱。 此輸出數據表會儲存 ML 模型的輸入值,並將預測值附加至該數據表。 根據預設,輸出數據表會建立在與輸入數據表相同的 Lakehouse 中。 您可以變更目的地湖屋。
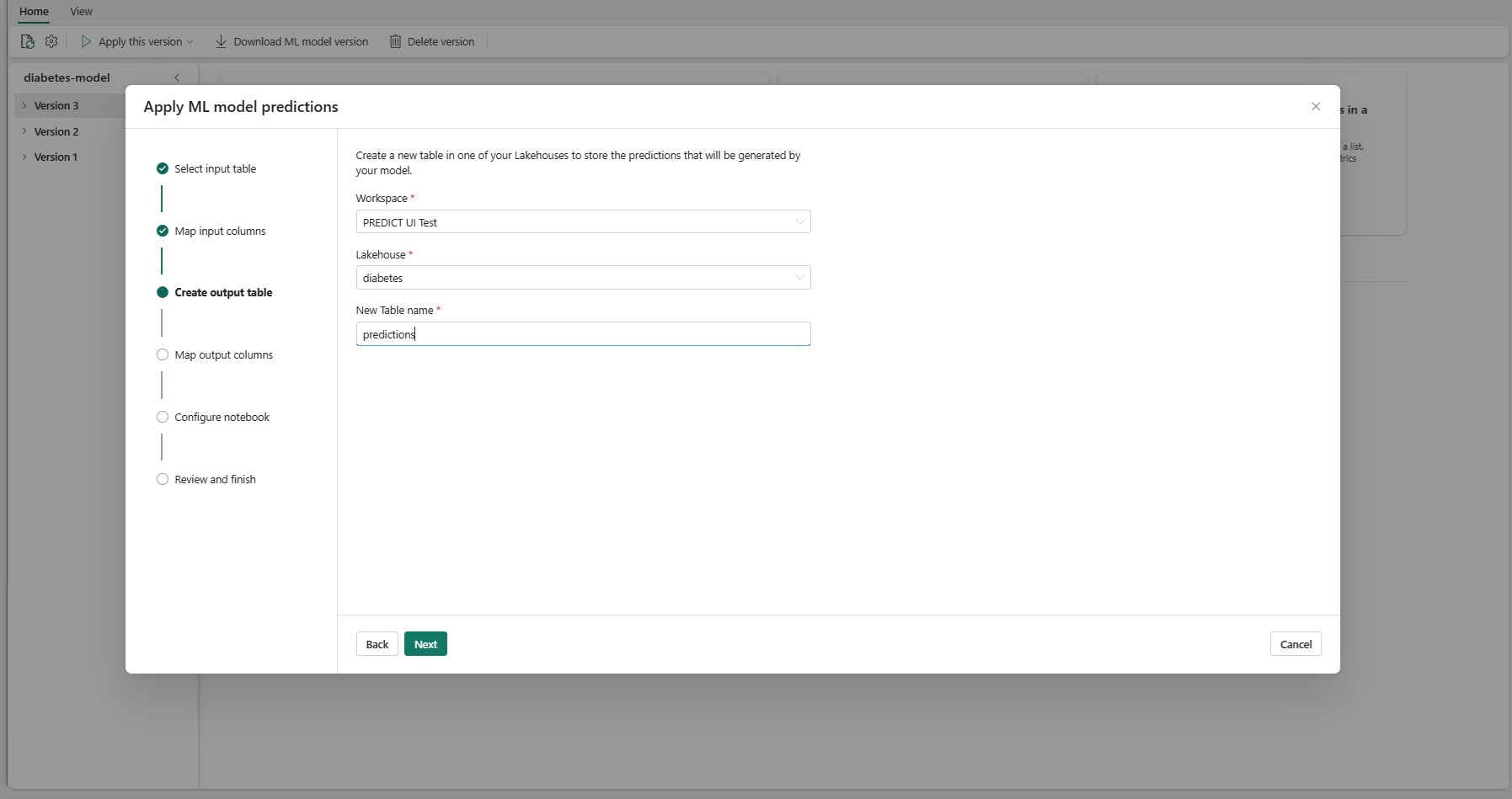
選取 [下一步] 以移至 [對應輸出資料行] 步驟。
使用提供的文字欄位,為儲存 ML 模型預測的輸出資料表資料行命名。
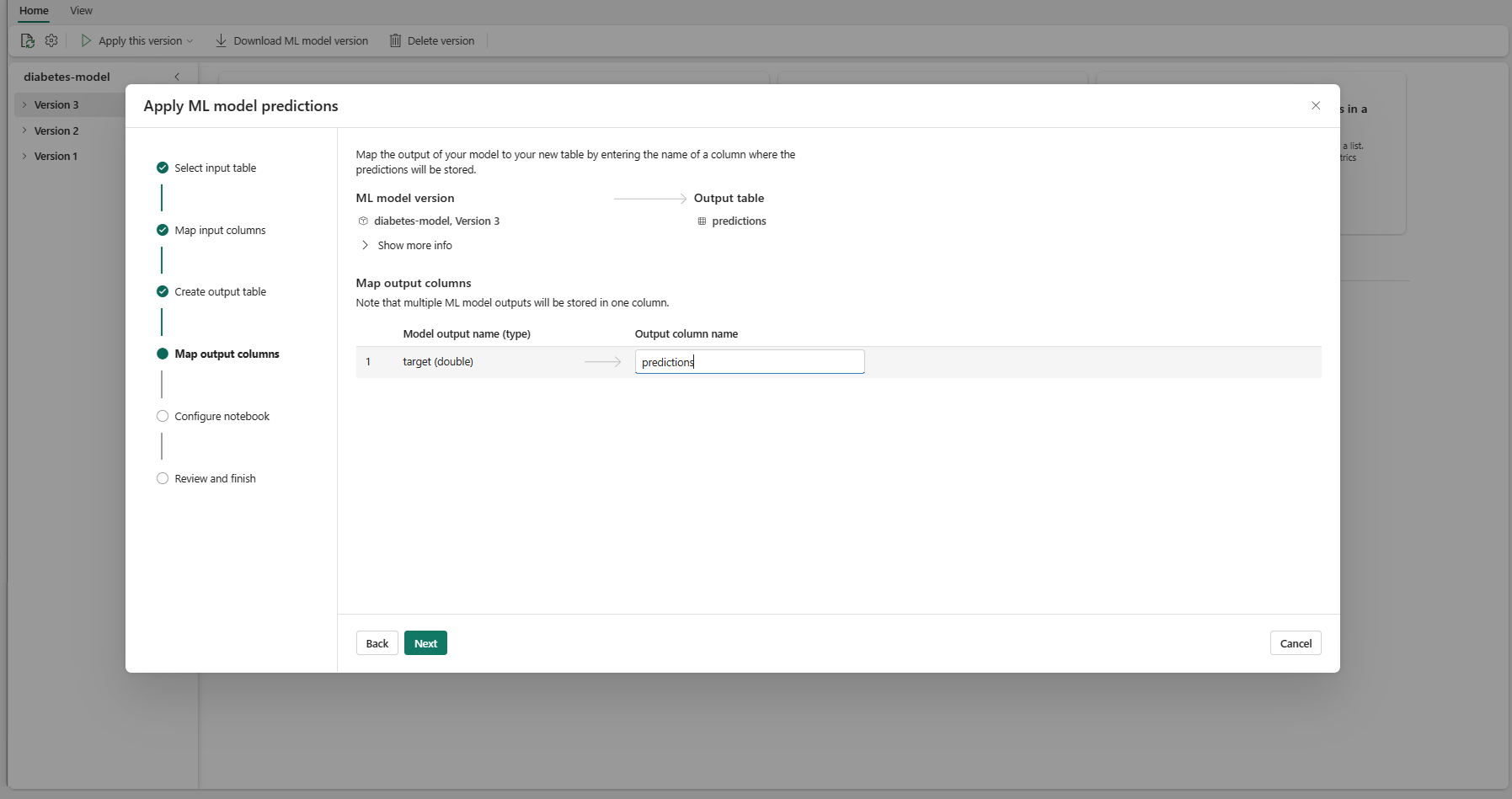
選取 [下一步] 以移至 [設定筆記本] 步驟。
提供執行所產生 PREDICT 程式代碼之新筆記本的名稱。 精靈會在此步驟中顯示所產生的程式碼的預覽。 如有需要,您可以將程式代碼複製到剪貼簿,並將它貼到現有的筆記本中。
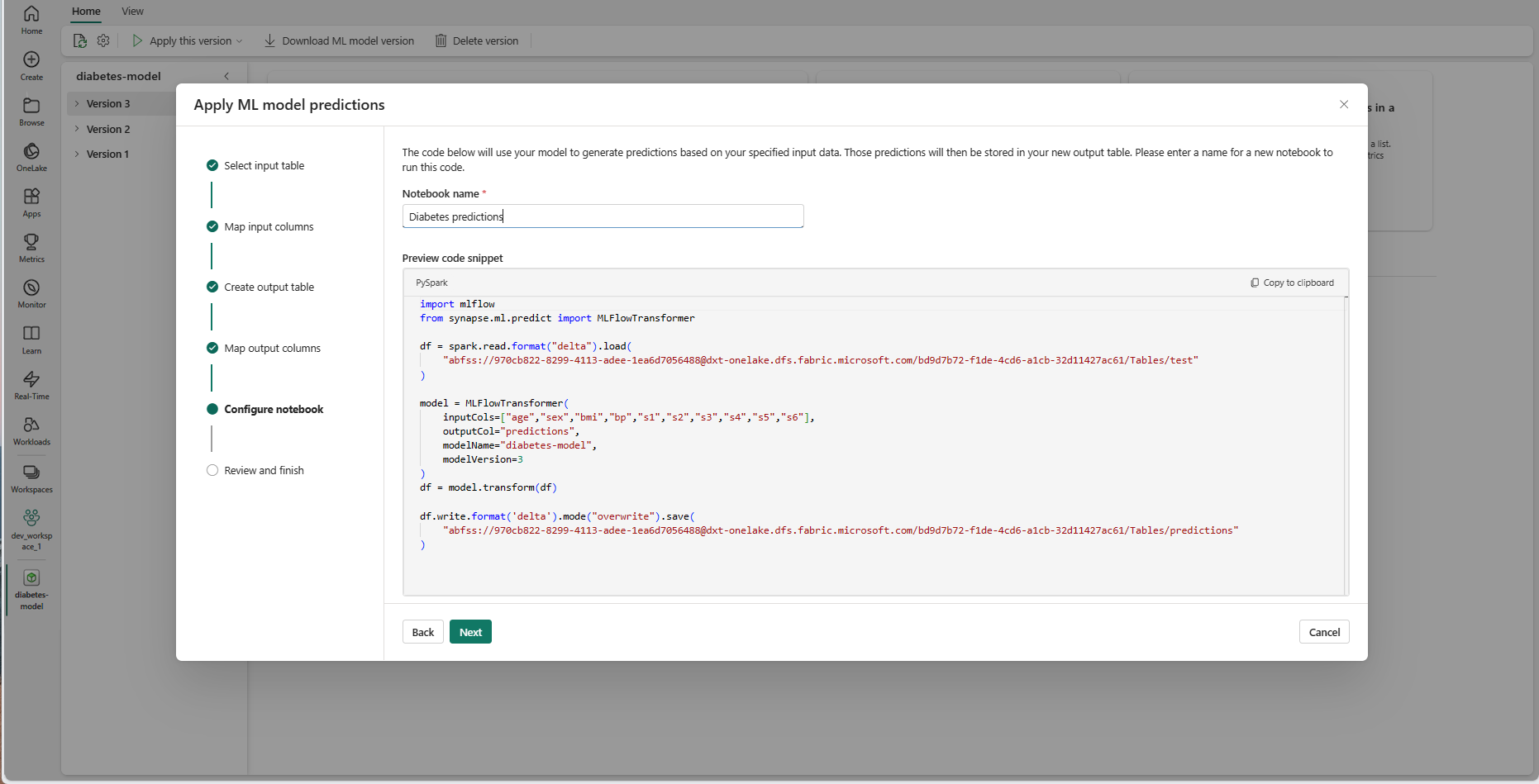
選取 [下一步] 以移至 [檢閱並完成] 步驟。
檢閱摘要頁面上的詳細數據,然後選取 [建立筆記本],將新筆記本 及其產生的程式代碼新增至您的工作區。 系統會直接前往該筆記本,您可以在其中執行程式碼來產生和儲存預測。
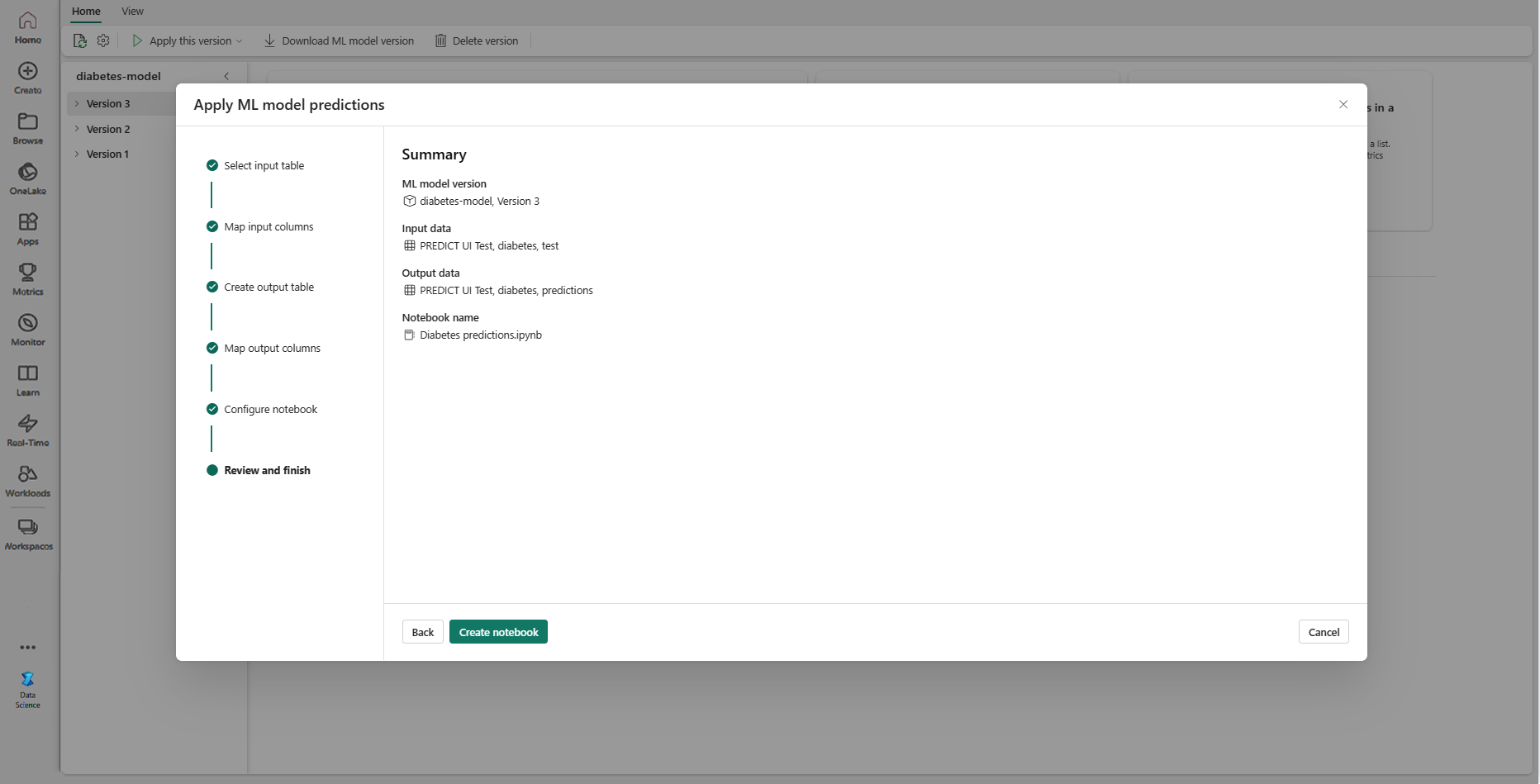







使用可自訂的程式碼範本
若要使用程式碼範本來產生批次預測:
- 移至指定 ML 模型版本的項目頁面。
- 從 [套用此版本] 下拉式清單中選取 [複製要套用的程式碼]。 該選取可讓您複製可自訂的程式碼範本。
您可以將此程式碼範本貼到筆記本中,使用 ML 模型產生批次預測。 若要成功執行程式碼範本,您必須手動取代下列值:
-
<INPUT_TABLE>:提供 ML 模型輸入之資料表的檔案路徑 -
<INPUT_COLS>:輸入資料表中要饋送至 ML 模型的資料行名稱陣列 -
<OUTPUT_COLS>:輸出資料表中儲存預測之新資料行的名稱 -
<MODEL_NAME>:用於產生預測的 ML 模型的名稱 -
<MODEL_VERSION>:用於產生預測的 ML 模型的版本 -
<OUTPUT_TABLE>:儲存預測之資料表的檔案路徑

import mlflow
from synapse.ml.predict import MLFlowTransformer
df = spark.read.format("delta").load(
<INPUT_TABLE> # Your input table filepath here
)
model = MLFlowTransformer(
inputCols=<INPUT_COLS>, # Your input columns here
outputCol=<OUTPUT_COLS>, # Your new column name here
modelName=<MODEL_NAME>, # Your ML model name here
modelVersion=<MODEL_VERSION> # Your ML model version here
)
df = model.transform(df)
df.write.format('delta').mode("overwrite").save(
<OUTPUT_TABLE> # Your output table filepath here
)