如何在複製活動中設定 Azure SQL 受控實例
本文概述如何使用數據管線中的複製活動,將數據從 Azure SQL 受控實例複製和複製到 Azure SQL 受控實例。
支援的組態
如需複製活動下每個索引標籤的設定,請分別移至下列各節。
一般
請參閱 一般 設定 指引,以設定 [一般 設定] 索引標籤。
源
複製活動的 [來源] 索引標籤下,Azure SQL 受控實例支援下列屬性。
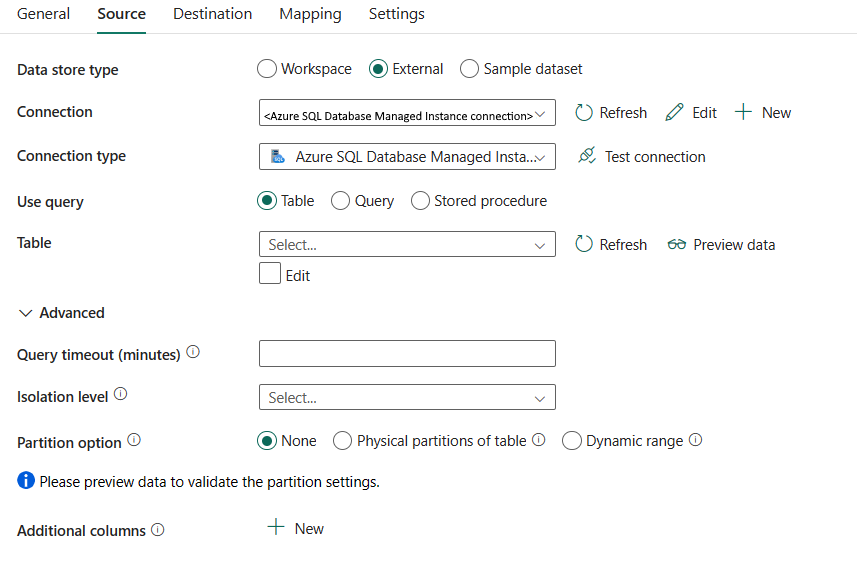
下列屬性 必要的:
資料存放區類型:選取 [外部]。
連線:從連線清單中選取 Azure SQL 受控實例連線。 如果連線不存在,請選取 [新增]來建立新的 Azure SQL 受控實例連線。
連線類型:選取 Azure SQL 受控實例。
使用查詢:指定讀取數據的方式。 您可以選擇 資料表、查詢或 預存程式。 下列清單描述每個設定的組態:
數據表:從指定的數據表讀取數據。 從下拉式清單中選取您的源數據表,或選取 編輯 手動輸入。
查詢:指定要讀取數據的自定義 SQL 查詢。 例如
select * from MyTable。 或選取鉛筆圖示以在程式碼編輯器中編輯。
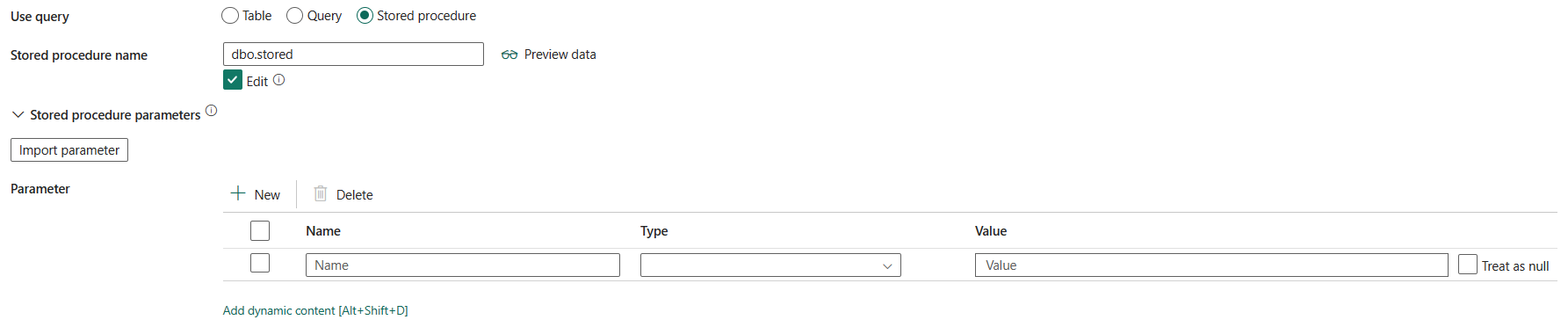
預存程式:使用從源數據表讀取數據的預存程式。 最後一個 SQL 語句必須是預存程式中的 SELECT 語句。
預存程式名稱:選取預存程式,或在選取 [編輯] 以從源數據表讀取數據時,手動指定預存程式名稱。
預存程式參數:指定預存程序參數的值。 允許的值是名稱或值組。 參數的名稱和大小寫必須符合預存程序參數的名稱和大小寫。 您可以選取 [匯入參數] 來取得預存程序參數。
在 [進階底下,您可以指定下列字段:
查詢逾時(分鐘):指定查詢命令執行的逾時,預設值為 120 分鐘。 如果為此屬性設定參數,允許的值會是時間範圍,例如 “02:00:00” (120 分鐘)。
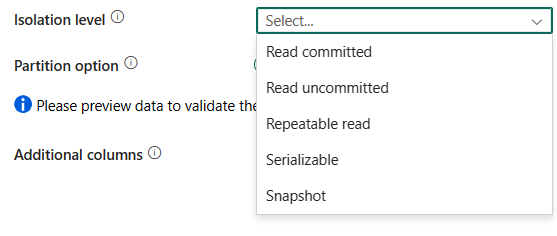
隔離等級:指定 SQL 來源的交易鎖定行為。 允許的值為:讀已提交、讀未提交、可重複讀、可序列化、快照。 如果未指定,則會使用資料庫的預設隔離等級。 如需詳細資訊,請參閱 IsolationLevel Enum。
資料分割選項:指定用來從 Azure SQL 受控實例載入資料的數據分割選項。 允許的值為:None (預設值)、資料表的實體分割區,以及 Dynamic range。 啟用分割區選項時(也就是,不是 None),從 Azure SQL 受控實例同時載入數據的平行度是由複製活動設定頁籤中的 [複製平行度] 控制。
None:選擇此設定來不使用分割區。
資料表的實體分割區:當您使用實體分割區時,分割欄位和機制會根據您的實體資料表定義自動決定。
動態範圍:當您使用已啟用平行的查詢時,需要範圍分割參數(
?DfDynamicRangePartitionCondition)。 範例查詢:SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition。分區欄位名稱:指定用於範圍分區並進行平行複製的源欄位名稱,該欄位類型必須為 整數或日期/日期時間 類型(
int、smallint、bigint、date、smalldatetime、datetime、datetime2或datetimeoffset)。 如果未指定,則會自動偵測數據表的索引或主鍵,並當做分區欄位使用。如果您使用查詢來擷取源數據,請在 WHERE 子句中連結
?DfDynamicRangePartitionCondition。 如需範例,請參閱 Azure SQL 受控實例的 平行複製 一節。分割區上限:指定分割欄位範圍拆分的最大值。 這個值用來決定數據分割的步幅,而不是用於篩選數據表中的數據列。 數據表或查詢結果中的所有數據列都會進行分割和複製。 如果未指定,複製活動會自動偵測值。 如需範例,請參閱從 Azure SQL 受控實例 一節 平行複製。
分割區下限:指定用於分割範圍的分割區列的最小值。 這個值用來決定數據分割的步幅,而不是用於篩選數據表中的數據列。 數據表或查詢結果中的所有數據列都會進行分割和複製。 如果未指定,複製活動會自動偵測值。 如需範例,請參閱從 Azure SQL 受控實例 一節 平行複製。
其他數據行:新增其他數據行來儲存來源檔案的相對路徑或靜態值。 後者支援使用表達式。
請注意下列幾點:
- 如果為來源指定 查詢,複製活動會針對 Azure SQL 受控實例來源執行此查詢,以取得數據。 若預存程序需要參數,您可以透過指定 預存程序名稱,及 預存程序參數 來指定預存程序。
- 在來源中使用預存程式來擷取數據時,請注意,如果預存程式的設計為在傳入不同的參數值時傳回不同的架構,您可能會在從 UI 匯入架構時,或從 UI 匯入架構或將數據複製到具有自動數據表建立的 SQL 資料庫時發生失敗或看到非預期的結果。
目的地
複製活動的 [目的地] 索引標籤下,Azure SQL 受控實例支援下列屬性。
![顯示 [目的地] 索引標籤的螢幕快照。](media/connector-azure-sql-managed-instance/destination.png)
下列屬性 是必需的:
資料存放區類型:選取 [外部]。
連線:從連線清單中選取 Azure SQL 受控實例連線。 如果連線不存在,請透過選取 新增來建立新的 Azure SQL 受控實例連線。
連線類型:選取 Azure SQL 受控實例。
[數據表] 選項:您可以選擇 [使用現有的],以使用指定的數據表。 或者選擇 [自動建立數據表],以在來源架構中不存在的情況下自動建立目的地數據表,並請注意,當預存程式作為寫入行為時,此選項不被支援。
如果您選擇 [使用現有的:
- 數據表:從下拉式清單中選取目的地資料庫中的數據表。 或檢查 編輯,然後手動輸入您的表格名稱。
如果您選取:自動建立資料表:
- 資料表:指定自動建立目的地資料表的名稱。
在 [進階底下,您可以指定下列字段:
寫入行為:當來源是檔案型數據存放區中的檔案時,定義寫入行為。 您可以選擇 插入、**Upsert 或 預存程式。
插入:選擇此選項會使用插入寫入行為將數據載入 Azure SQL 受控實例。
Upsert:選擇此選項會使用 upsert 寫入行為將數據載入 Azure SQL 受控實例。
使用 TempDB:指定是否要使用全域臨時表或實體數據表作為 upsert 的臨時表。 根據預設,服務會使用全域臨時表做為臨時表,並選取此屬性。
![顯示選取 [使用 TempDB] 的螢幕快照。](media/connector-azure-sql-managed-instance/use-tempdb.png)
選取使用者資料庫架構:如果未選取 使用 TempDB,請在使用實體數據表時指定建立過渡數據表的過渡架構。
注意
您必須擁有建立和刪除資料表的許可權。 根據預設,過渡數據表會共用與目的地數據表相同的架構。
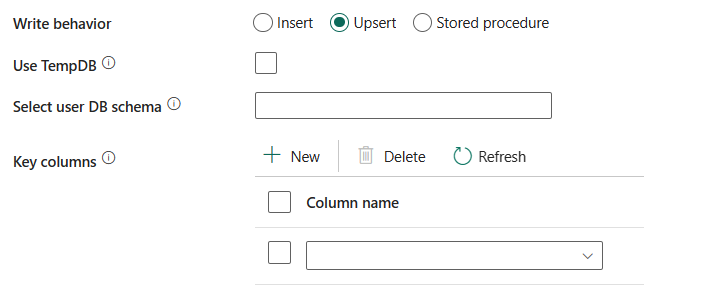
主鍵列:指定列名稱以唯一識別行。 您可以使用單一按鍵或一系列按鍵。 如果未指定,則會使用主鍵。
預存程式:使用預存程式,定義如何將源數據套用至目標數據表。 每個批次 調用此預存程式。 針對只執行一次且與源數據無關的作業,例如刪除或截斷,請使用 預先複製腳本 屬性。
預存程序名稱:選取預存程序,或在檢查從來源資料表讀取數據的 [編輯] 時手動指定預存程序名稱。
預存程式參數:
- 資料表類型:指定要用於預存程式中的數據表類型名稱。 複製活動會讓要移動的數據在具有該表類型的臨時表中可用。 接著,預存程序代碼可以將正在複製的數據與現有數據合併。
- 資料表類型參數名稱:指定預存程式中指定之數據表類型的參數名稱。
- 參數:指定預存程序參數的值。 允許的值是名稱或值組。 參數的名稱和大小寫必須符合預存程序參數的名稱和大小寫。 您可以選取 [匯入參數] 來取得預存程序參數。
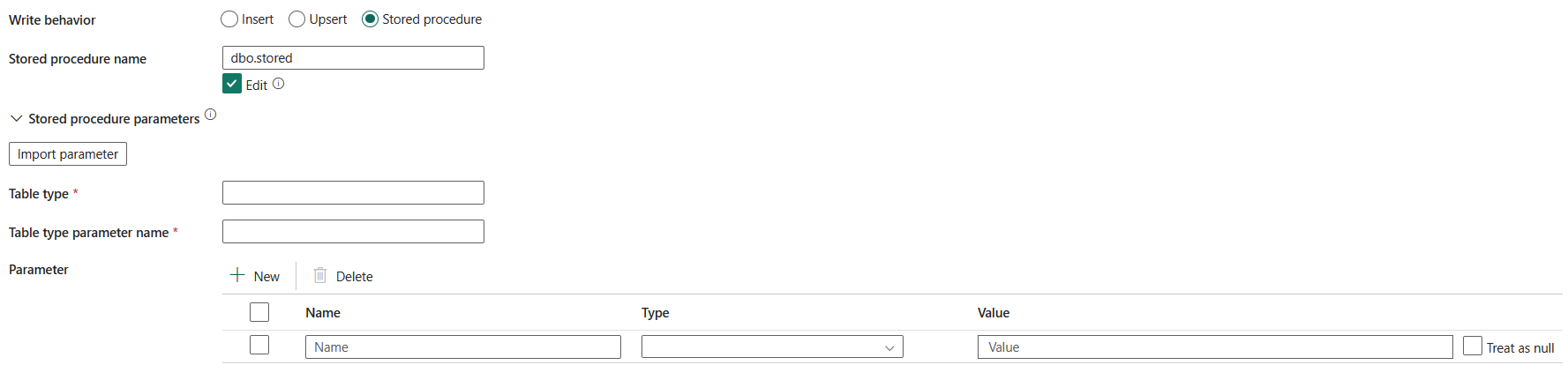
大量插入資料表鎖定:選擇 是 或 否(預設)。 使用此設定可改善在無索引的資料表上,從多個用戶端進行大量插入操作時的複製效能。 當您選取 插入 或 Upsert 作為寫入行為時,您可以指定此屬性。 如需詳細資訊,請參閱 BULK INSERT (Transact-SQL)
預複製腳本:在每次執行中指定一個腳本,讓複製活動在將數據寫入目的地表之前執行。 您可以使用這個屬性來清除預先載入的數據。
寫入批次逾時:指定批次插入作業在超過時間限制之前完成的等候時間。允許的值是時間長度。 如果未指定任何值,則逾時預設為 “02:00:00”。
寫入批次大小:指定每個批次要插入 SQL 資料表的數據列數目。 允許的值是整數(數據列數目)。 根據預設,服務會根據數據列大小動態決定適當的批次大小。
最大並行連線:活動執行期間,與數據存放區建立的並行連線上限。 只有在您想要限制並行連線時,才指定值。
映射
針對 對應 索引標籤,如果您未將 Azure SQL 受控實例自動建立資料表套用為目的地,請移至 [對應]。
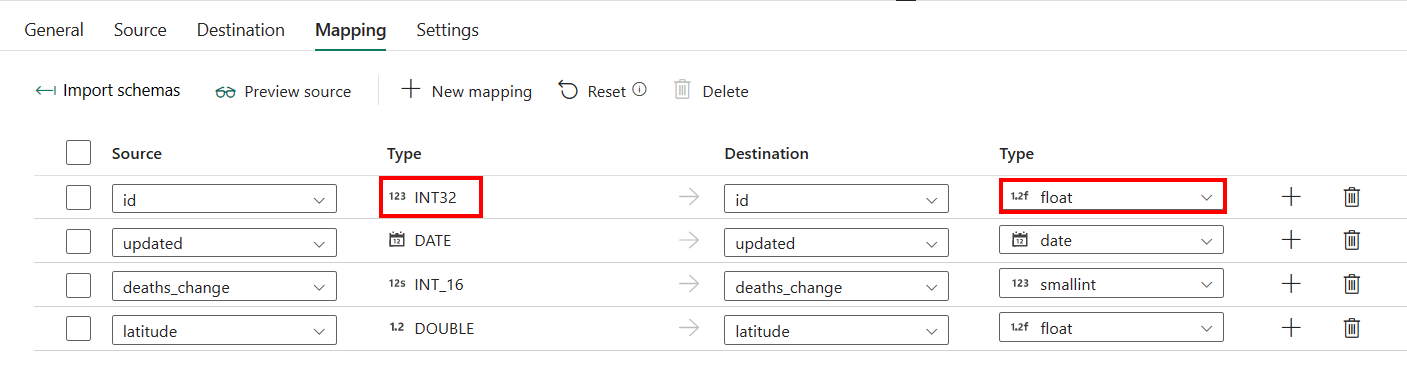
如果您將 Azure SQL 受控實例應用為目的地,並啟用自動建立資料表功能,那麼除了 對應中的配置之外,您還可以編輯目的地欄位的類型。 選取 匯入架構之後,您可以在目的地中指定資料行類型。
例如,來源中 標識碼 數據行的類型為 int,而且當對應至目的地數據行時,您可以將它變更為 float 類型。
設定
如需設定 [設定] 索引標籤的組態,請移至 [設定] 索引標籤下設定其他的設定。
從 Azure SQL 受控實例平行複製
複製活動中的 Azure SQL 受控實例連接器提供內建的數據分割,以平行方式複製數據。 您可以在複製活動的 [來源] 索引標籤上找到資料分割選項。
當您啟用數據分割複製時,複製活動會針對 Azure SQL 受控實例來源執行平行查詢,以依數據分割載入數據。 平行度是由複製活動設定索引標籤中複製平行處理原則 度所控制。例如,如果您將複製平行 處理原則的 度設定為 4,服務會根據指定的數據分割選項和設定,同時產生並執行四個查詢,而每個查詢都會從 Azure SQL 受控實例擷取部分數據。
建議您啟用與數據分割的平行複製,特別是當您從 Azure SQL 受控實例載入大量數據時。 以下是針對不同案例的建議組態。 將數據複製到檔案型數據存放區時,建議以多個檔案的形式寫入資料夾(僅指定資料夾名稱),在此情況下效能會優於寫入單一檔案。
| 場景 | 建議的設定 |
|---|---|
| 從大型數據表中進行完整載入,並使用物理分區。 |
分區選項:表格的實體分區。 在執行期間,服務會自動偵測實體分割區,並依分割區複製數據。 若要檢查資料表是否有實體分割區,您可以參考 此查詢。 |
| 從大型數據表全量加載,沒有實體分區,但有用於數據分區的整數或日期時間列。 |
分區選項:動態範圍分區。 資料分割資料行(選擇性):指定用來分割數據的數據行。 如果未指定,則會使用索引列或主鍵列。 分割區上限 和 分割區下限(選擇性):指定是否要判斷分割區步幅。 這不適用於篩選數據表中的數據列,數據表中的所有數據列都會進行分割和複製。 如果未指定,複製活動會自動偵測值。 例如,如果您的分割區數據行 「ID」 的值範圍從 1 到 100,而您將下限設定為 20,並將上限設定為 80,且平行複製為 4,則服務會依 4 個分割區擷取數據 - 範圍中的標識符 <=20、[21、50]、[51、80]和 >=81。 |
| 使用自定義查詢載入大量數據,不使用實體分區,但使用整數或日期/日期時間欄進行數據分割。 |
分區選項:動態範圍分割。 查詢: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>。分割欄位:指定用於分割資料的欄位。 分割區上限 和 分割區下限(選擇性):指定是否要判斷分割區步幅。 這不適用於篩選數據表中的數據列,查詢結果中的所有數據列都會進行分割和複製。 如果未指定,複製活動會自動偵測值。 例如,如果您的分割區欄位「ID」的值範圍是從 1 到 100,您將下界設為 20,上界設為 80,並且設定平行處理為 4,則服務會分別以 4 個分割區來擷取數據,範圍分別為:<= 20、[21, 50]、[51, 80] 以及 >= 81。 以下是不同案例的更多範例查詢: • 查詢整個資料表: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition• 從具有數據行選取範圍和其他 where 子句篩選的數據表查詢: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• 使用子查詢查詢: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• 在子查詢中使用分割區進行查詢: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
使用資料分割選項載入資料的最佳做法:
- 選擇具有唯一性的欄位作為分區欄位(例如主鍵或唯一鍵),以避免資料偏斜。
- 如果數據表具有內建分割區,請使用數據分割選項 數據表 的實體分割區,以取得更好的效能。
檢查實體分割區的範例查詢
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, pf.name AS PartitionFunctionName, c.name AS ColumnName, iif(pf.name is null, 'no', 'yes') AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON pf.function_id = ps.function_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
如果數據表有實體分割區,您會看到 「HasPartition」 為 「yes」,如下所示。

數據表摘要
如需 Azure SQL 受控實例複製活動的摘要和詳細資訊,請參閱下表。
來源資訊
| 名字 | 描述 | 價值 | 必填 | JSON 腳本屬性 |
|---|---|---|---|---|
| 資料存放區類型 | 您的資料存放區類型。 | 外部 | 是的 | / |
| 連線 | 您與源資料存放區的連線。 | < 您的連線 > | 是的 | 連接 |
| 連線類型 | 您的連線類型。 選取 Azure SQL 受控實例。 | Azure SQL 受控實例 | 是的 | / |
| 使用查詢 | 要讀取數據的自定義 SQL 查詢。 | • 表格 •查詢 • 預存程式 |
是的 | / |
| 表格 | 您的源數據表。 | < 您的表格名稱> | 不 | 圖式 桌子 |
| 查詢 | 要讀取數據的自定義 SQL 查詢。 | < 查詢 > | 不 | sqlReaderQuery |
| 預存程式名稱 | 這個屬性是從源數據表讀取數據的預存程式名稱。 最後一個 SQL 語句必須是預存程式中的 SELECT 語句。 | < 預存程式名稱 > | 不 | sqlReaderStoredProcedureName |
| 預存程序參數 | 這些參數適用於預存程式。 允許的值是名稱或值組。 參數的名稱和大小寫必須符合預存程序參數的名稱和大小寫。 | < 名稱或值組 > | 不 | 儲存程序參數 |
| 查詢逾時 | 查詢命令執行的逾時。 | 時間跨度 (預設值為 120 分鐘) |
不 | queryTimeout |
| 隔離等級 | 指定 SQL 來源的交易鎖定行為。 | • 已認可讀取 • 讀取未認可 • 可重複讀取 •序列化 •快照 |
不 | 隔離層級 (isolationLevel): • 已提交讀取 • ReadUncommitted(未提交讀取) • 可重複讀取 可序列化 •快照 |
| 分割區選項 | 用來從 Azure SQL 受控實例載入數據的數據分割選項。 | • 無 (預設值) • 資料表的實體分區 •動態範圍 |
不 | partitionOption: • 無 (預設值) • 資料表的實體分區 • DynamicRange |
| 分割欄名稱 | 在 整數或日期/日期時間 類型的源數據欄位名稱(int、smallint、bigint、date、smalldatetime、datetime、datetime2或 datetimeoffset)中,該名稱用於範圍分割以進行平行複製。 如果未指定,則會自動偵測資料表的索引或主鍵,並用作分區欄位。 如果您使用查詢來擷取原始數據,請在 WHERE 子句中掛勾 ?DfDynamicRangePartitionCondition。 |
< 分割區欄名稱 > | 不 | 分區欄位名稱 |
| 分割區上限 | 分區範圍分割的分區列最大值。 這個值用來決定數據分割的步幅,而不是用於篩選數據表中的數據列。 數據表或查詢結果中的所有數據列都會進行分割和複製。 如果未指定,複製活動會自動偵測值。 | < 分割區上限 > | 不 | partitionUpperBound |
| 分割區下限 | 用於分割範圍的分割列的最小值。 這個值用來決定數據分割的步幅,而不是用於篩選數據表中的數據列。 數據表或查詢結果中的所有數據列都會進行分割和複製。 如果未指定,複製活動會自動偵測值。 | < 分割區下限 > | 不 | partitionLowerBound |
| 額外欄位 | 新增其他數據行以儲存來源檔案的相對路徑或靜態值。 支持後者的表達式。 | •名字 •價值 |
不 | additionalColumns: •名字 •價值 |
目的地資訊
| 名字 | 描述 | 價值 | 必填 | JSON 腳本屬性 |
|---|---|---|---|---|
| 資料存放區類型 | 您的資料存放區類型。 | 外部 | 是的 | / |
| 連線 | 您與目的地資料存放區的連線。 | < 您的連線 > | 是的 | 連接 |
| 連線類型 | 您的連線類型。 選取 Azure SQL 受控實例。 | Azure SQL 受控實例 | 是的 | / |
| 資料表選項 | 指定是否在來源架構不存在時自動建立目的地數據表。 | • 使用現有的 • 自動建立數據表 |
是的 | tableOption: • 自動創建 |
| 表格 | 您的目的地數據表。 | 您的表 <的名稱> | 是的 | 圖式 桌子 |
| 寫入行為 | 複製活動將數據載入 Azure SQL 受控實例資料庫時的寫入行為。 | •插入 • Upsert • 預存程式 |
不 | writeBehavior: •插入 更新插入 sqlWriterStoredProcedureName, sqlWriterTableType, storedProcedureTableTypeParameterName, storedProcedureParameters |
| 使用TempDB | 是否要使用全域臨時表或實體數據表作為 upsert 的臨時表。 | 已選擇(預設)或未選擇 | 不 | useTempDB: true (預設值) 或 false |
| 選取使用者資料庫架構 | 為使用實體數據表時建立臨時數據表而設的臨時結構。 注意:用戶必須具有建立和刪除數據表的許可權。 根據預設,過渡數據表會共用與目的地數據表相同的架構。 當您未選擇 使用 TempDB時,進行套用。 | 已選取(預設)或未選取 | 不 | interimSchemaName |
| 重要欄位 | 唯一行識別的欄位名稱。 您可以使用單一索引鍵或一系列索引鍵。 如果未指定,則會使用主鍵。 | < 您的關鍵欄位> | 不 | 鑰匙 |
| 預存程式名稱 | 定義如何將源數據套用至目標數據表的預存程式名稱。 每個批次 叫用此預存程式。 針對只執行一次且與源數據無關的作業,例如刪除或截斷,請使用 預先複製腳本 屬性。 | < 預存程式名稱 > | 不 | sqlWriterStoredProcedureName |
| 數據表類型 | 要用於預存程式中的數據表類型名稱。 複製活動會將移動中的數據放在具有此類型的臨時表中以供使用。 存儲過程代碼然後可以將複製的數據與現有數據合併。 | < 資料表類型名稱 > | 不 | sqlWriterTableType |
| 數據表類型參數名稱 | 預存程式中指定之資料表類型的參數名稱。 | < 數據表類型的參數名稱 > | 不 | storedProcedureTableTypeParameterName |
| 參數 | 預存程序的參數。 允許的值是名稱和值組。 參數的名稱和大小寫必須符合預存程序參數的名稱和大小寫。 | < 名稱和值對 > | 不 | 儲存程序參數 |
| 大量插入數據表鎖定 | 在進行來自多個用戶端的數據表無索引之大量插入作業時,使用此設定可提升複製效能。 | 是或否 (預設值) | 不 | sqlWriterUseTableLock: true 或 false (預設值) |
| 預先複製腳本 | 在每次執行中,寫入資料到目的資料表之前,將執行一個複製活動腳本。 您可以使用這個屬性來清除預先載入的數據。 |
< 預先複製腳本 > (字串) |
不 | preCopyScript |
| 寫入批次逾時 | 批次插入作業在逾時之前完成的等候時間。 | 時間跨度 (預設值為 “02:00:00”) |
不 | writeBatchTimeout |
| 寫入批次大小 | 每個批次要插入 SQL 資料表的數據列數目。 根據預設,服務會根據數據列大小動態決定適當的批次大小。 |
< 數據列數目 > (整數) |
不 | writeBatchSize |
| 最大並行連線 | 在活動運行期間,與資料存放區建立的並行連線的上限值。 只有在您想要限制並行連線時,才指定值。 | 並行連線的最大值 <> (整數) |
不 | 最大併發連接數量 |