教學課程:使用矩陣分解搭配 ML.NET 建置電影推薦工具
本教學課程會示範如何在 .NET Core 主控台應用程式中使用 ML.NET 建置電影推薦工具。 這些步驟會使用 C# 和 Visual Studio 2019。
在本教學課程中,您會了解如何:
- 選取機器學習演算法
- 準備及載入您的資料
- 建置及定型模型
- 評估模型
- 部署及取用模型
您可以在 dotnet/samples 存放庫中找到本教學課程的原始程式碼。
機器學習工作流程
您將使用下列步驟來完成您的工作以及任何其他 ML.NET 工作:
必要條件
選取適當的機器學習工作
有數種方式可以解決推薦問題,例如推薦電影清單或推薦相關產品清單;但在此情況下,您將預測使用者會給予該電影的評等 (1-5),如果特定電影的預測評等高於所定義閾值,即推薦該電影 (評等愈高,使用者喜歡特定電影的可能性愈高)。
建立主控台應用程式
建立專案
建立名為 "MovieRecommender" 的 C# 主控台應用程式。 按 [下一步] 按鈕。
選擇 .NET 6 作為要使用的架構。 按一下 [ 建立 ] 按鈕。
在您的專案中建立一個名為 Data 的目錄以儲存資料集:
在 [方案總管] 中,以滑鼠右鍵按一下專案,然後選取 [新增]>[新增資料夾]。 輸入 "Data",然後按 Enter。
安裝 Microsoft.ML 和 Microsoft.ML.Recommender NuGet 套件:
注意
除非另有說明,否則此樣本會使用所提及 NuGet 套件的最新穩定版本。
在 [方案總管] 中,以滑鼠右鍵按一下專案,然後選取 [管理 NuGet 套件]。 選擇 "nuget.org" 作為 [套件來源]、選取 [瀏覽] 索引標籤、搜尋 Microsoft.ML、從清單中選取該套件,然後選取 [安裝] 按鈕。 在 [預覽變更] 對話方塊上,選取 [確定] 按鈕,然後在 [授權接受] 對話方塊上,如果您同意所列套件的授權條款,請選取 [我接受]。 為 Microsoft.ML.Recommender 重複這些步驟。
在您的 Program.cs 檔案最上方新增下列
using陳述式:using Microsoft.ML; using Microsoft.ML.Trainers; using MovieRecommendation;
下載您的資料
下載兩個資料集,並儲存至您先前建立的 Data 資料夾:
以滑鼠右鍵按一下 recommendation-ratings-train.csv,然後選取 [另存連結 (或目標)...]
以滑鼠右鍵按一下 recommendation-ratings-test.csv,然後選取 [另存連結 (或目標)...]
請務必將 *.csv 檔案儲存至 Data 資料夾,或儲存在其他位置之後將 *.csv 檔案移至 Data 資料夾。
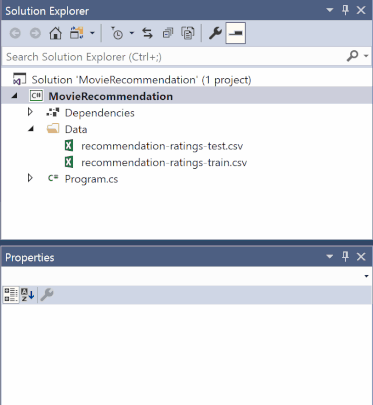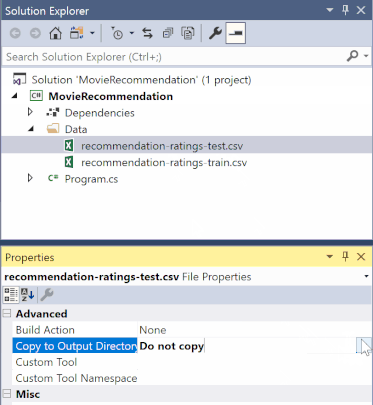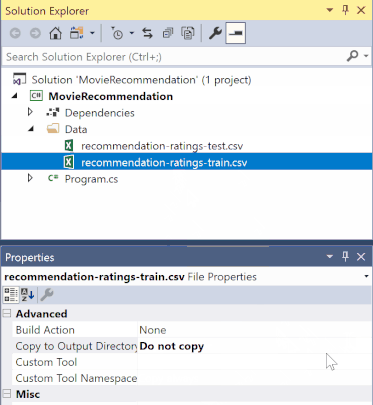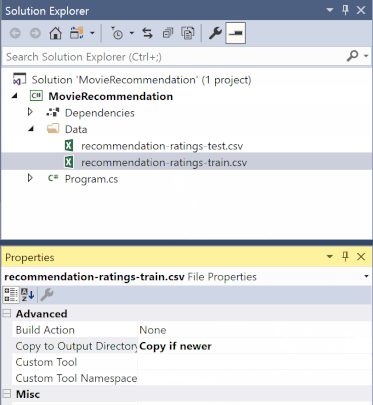
在 [方案總管] 中,以滑鼠右鍵按一下每個 *.csv 檔案,然後選取 [屬性]。 在 [進階] 底下,將 [複製到輸出目錄] 的值變更為 [有更新時才複製]。
載入您的資料
ML.NET 程序的第一個步驟是準備並載入模型定型和測試資料。
推薦評等資料會分成 Train 和 Test 資料集。 Train 資料用來調整您的模型。 Test 資料用來以您的已定型模型進行預測並評估模型效能。 Train 和 Test 資料通常會分割為 80/20 比例。
以下是您 *.csv 檔案的資料預覽:
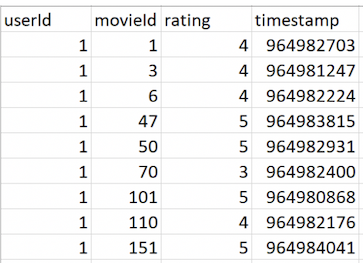
在 *.csv 檔案中有四個資料行:
userIdmovieIdratingtimestamp
在機器學習服務中,用來進行預測的資料行稱為特徵,而傳回預測的資料行稱為標籤。
您希望預測電影評等,因此評等資料行是 Label。 其他三個資料行 userId、movieId 和 timestamp 都是 Features,用來預測 Label。
| 功能 | 標籤 |
|---|---|
userId |
rating |
movieId |
|
timestamp |
由您決定使用哪些 Features 來預測 Label。 您也可以使用類似排列特徵重要性的方法,來協助您選取最合適的 Features。
在此情況下,您應該排除 timestamp 資料行為 Feature,因為時間戳記並不會實際影響使用者對特定影片的評分方式,因此無法提供更精確的預測:
| 功能 | 標籤 |
|---|---|
userId |
rating |
movieId |
接下來,您必須定義輸入類別的資料結構。
將新類別新增至專案:
在 [方案總管] 中,以滑鼠右鍵按一下專案,然後選取 [新增] > [新項目]。
在 [新增項目] 對話方塊中,選取 [類別],然後將 [名稱] 欄位變更為 MovieRatingData.cs。 接著,選取 [新增] 按鈕。
MovieRatingData.cs 檔案隨即在程式碼編輯器中開啟。 將下列 using 陳述式新增至 MovieRatingData.cs 的最上方:
using Microsoft.ML.Data;
移除現有類別定義,並在 MovieRatingData.cs 中新增下列程式碼,來建立稱為 MovieRating 的類別:
public class MovieRating
{
[LoadColumn(0)]
public float userId;
[LoadColumn(1)]
public float movieId;
[LoadColumn(2)]
public float Label;
}
MovieRating 會指定輸入資料類別。 LoadColumn 屬性會指定應該載入資料集內的哪些資料行 (依資料行索引)。 userId 和 movieId 資料行是您的 Features (您將給予模型來預測 Label 的輸入),而評等資料行是您將預測的 Label (模型的輸出)。
建立另一個類別 MovieRatingPrediction,藉由在 MovieRatingData.cs 中的 MovieRating 類別之後新增下列程式碼,以代表預測的結果:
public class MovieRatingPrediction
{
public float Label;
public float Score;
}
在 Program.cs 中,以下列程式碼取代 Console.WriteLine("Hello World!"):
MLContext mlContext = new MLContext();
MLContext 類別是所有 ML.NET 作業的起點,且初始化 mlContext 會建立新的 ML.NET 環境,其可在模型建立工作流程物件之間共用。 就概念而言,類似於 Entity Framework 中的 DBContext。
在檔案底部,建立名為 LoadData() 的方法:
(IDataView training, IDataView test) LoadData(MLContext mlContext)
{
}
注意
此方法將給出錯誤,直到您在下列步驟中新增 return 陳述式。
初始化您的資料路徑變數、從 *.csv 檔案載入資料,並將下列程式碼新增為 LoadData() 中的下一行程式碼來傳回 Train 和 Test 資料作為 IDataView 物件:
var trainingDataPath = Path.Combine(Environment.CurrentDirectory, "Data", "recommendation-ratings-train.csv");
var testDataPath = Path.Combine(Environment.CurrentDirectory, "Data", "recommendation-ratings-test.csv");
IDataView trainingDataView = mlContext.Data.LoadFromTextFile<MovieRating>(trainingDataPath, hasHeader: true, separatorChar: ',');
IDataView testDataView = mlContext.Data.LoadFromTextFile<MovieRating>(testDataPath, hasHeader: true, separatorChar: ',');
return (trainingDataView, testDataView);
ML.NET 中的資料會以 IDataView 介面表示。 IDataView 是彈性且有效率的表格式資料描述方式 (數值和文字)。 資料可以從文字或即時 (例如 SQL 資料庫或記錄檔) 載入至 IDataView 物件。
LoadFromTextFile() 會定義資料結構描述並讀入檔案中。 會接受資料路徑變數然後傳回 IDataView。 在此情況下,您提供 Test 和 Train 檔案的路徑,並指示文字檔案標頭 (以便其正確使用資料行名稱) 和逗號字元資料分隔符號 (預設的分隔符號是索引標籤)。
新增下列程式碼以呼叫 LoadData() 方法並傳回 Train 和 Test 資料:
(IDataView trainingDataView, IDataView testDataView) = LoadData(mlContext);
建置及定型您的模型
請使用下列程式碼,在緊接著 LoadData() 方法之後,建立 BuildAndTrainModel() 方法:
ITransformer BuildAndTrainModel(MLContext mlContext, IDataView trainingDataView)
{
}
注意
此方法將給出錯誤,直到您在下列步驟中新增 return 陳述式。
將下列程式碼新增至 BuildAndTrainModel() 以定義資料轉換:
IEstimator<ITransformer> estimator = mlContext.Transforms.Conversion.MapValueToKey(outputColumnName: "userIdEncoded", inputColumnName: "userId")
.Append(mlContext.Transforms.Conversion.MapValueToKey(outputColumnName: "movieIdEncoded", inputColumnName: "movieId"));
由於 userId 和 movieId 代表使用者與電影標題,而非真正的值,所以您會使用 MapValueToKey() 方法來將每個 userId 和每個 movieId 轉換成數值索引鍵類型 Feature 資料行 (推薦演算法所接受的格式),並將其新增為新的資料集資料行:
| userId | movieId | 標籤 | userIdEncoded | movieIdEncoded |
|---|---|---|---|---|
| 1 | 1 | 4 | userKey1 | movieKey1 |
| 1 | 3 | 4 | userKey1 | movieKey2 |
| 1 | 6 | 4 | userKey1 | movieKey3 |
將下列程式碼新增為 BuildAndTrainModel() 中的下一行程式碼,以選擇機器學習演算法,並將其附加至資料轉換定義中:
var options = new MatrixFactorizationTrainer.Options
{
MatrixColumnIndexColumnName = "userIdEncoded",
MatrixRowIndexColumnName = "movieIdEncoded",
LabelColumnName = "Label",
NumberOfIterations = 20,
ApproximationRank = 100
};
var trainerEstimator = estimator.Append(mlContext.Recommendation().Trainers.MatrixFactorization(options));
MatrixFactorizationTrainer 是您的推薦定型演算法。 當您擁有使用者過去如何評等產品的資料時,矩陣分解是推薦的常見方法,此亦為本教學課程資料集的情況。 當您有不同的可用資料時,也有其他推薦演算法 (請參閱其他推薦演算法一節以深入了解)。
在此案例中,Matrix Factorization 演算法使用的方法稱為「共同篩選」,此方法假設如果使用者 1 與使用者 2 對特定問題具有相同的意見,則使用者 1 對其他問題的想法較可能與使用者 2 相同。
比方說,如果使用者 1 對電影的評分與使用者 2 類似,則使用者 2 較可能享受使用者 1 已觀看並給予高度評分的電影:
Incredibles 2 (2018) |
The Avengers (2012) |
Guardians of the Galaxy (2014) |
|
|---|---|---|---|
| 使用者 1 | 已觀看及已按讚的電影 | 已觀看及已按讚的電影 | 已觀看及已按讚的電影 |
| 使用者 2 | 已觀看及已按讚的電影 | 已觀看及已按讚的電影 | 尚未觀看 -- 推薦電影 |
Matrix Factorization 定型器具有數個選項,您可以在以下演算法超參數一節中深入了解。
將下列內容新增為 BuildAndTrainModel() 方法中的下一行程式碼,調整模型為合適於 Train 資料並傳回已定型模型:
Console.WriteLine("=============== Training the model ===============");
ITransformer model = trainerEstimator.Fit(trainingDataView);
return model;
Fit() 方法會以所提供的定型資料集來定型模型。 技術上來說,其會轉換資料並套用定型來執行 Estimator 定義,並傳回已定型模型,也就是 Transformer。
如需 ML.NET 中模型定型工作流程的詳細資訊,請參閱 什麼是 ML.NET 及其運作方式?。
將下列內容新增為對 LoadData() 方法呼叫下方的下一行程式碼,以呼叫 BuildAndTrainModel() 方法並傳回定型模型:
ITransformer model = BuildAndTrainModel(mlContext, trainingDataView);
評估您的模型
一旦您將模型定型後,即可將測試資料用於評估模型的執行情況。
請使用下列程式碼,在緊接著 BuildAndTrainModel() 方法之後,建立 EvaluateModel() 方法:
void EvaluateModel(MLContext mlContext, IDataView testDataView, ITransformer model)
{
}
將下列程式碼新增至 EvaluateModel() 以轉換 Test 資料:
Console.WriteLine("=============== Evaluating the model ===============");
var prediction = model.Transform(testDataView);
Transform() 方法會對測試資料集之多個提供的輸入資料列進行預測。
將下列內容新增為 EvaluateModel() 方法中的下一行程式碼來評估模型:
var metrics = mlContext.Regression.Evaluate(prediction, labelColumnName: "Label", scoreColumnName: "Score");
在您設定好預測後,Evaluate() 方法會評估模型,將預測值與測試資料集中的實際 Labels 進行比較,並傳回模型的執行情況。
將下列內容新增為 EvaluateModel() 方法中的下一行程式碼,將您的評估計量列印到主控台:
Console.WriteLine("Root Mean Squared Error : " + metrics.RootMeanSquaredError.ToString());
Console.WriteLine("RSquared: " + metrics.RSquared.ToString());
將下列內容新增為對 BuildAndTrainModel() 方法呼叫下方的下一行程式碼,以呼叫 EvaluateModel() 方法:
EvaluateModel(mlContext, testDataView, model);
到目前為止,輸出看起來應類似下列文字:
=============== Training the model ===============
iter tr_rmse obj
0 1.5403 3.1262e+05
1 0.9221 1.6030e+05
2 0.8687 1.5046e+05
3 0.8416 1.4584e+05
4 0.8142 1.4209e+05
5 0.7849 1.3907e+05
6 0.7544 1.3594e+05
7 0.7266 1.3361e+05
8 0.6987 1.3110e+05
9 0.6751 1.2948e+05
10 0.6530 1.2766e+05
11 0.6350 1.2644e+05
12 0.6197 1.2541e+05
13 0.6067 1.2470e+05
14 0.5953 1.2382e+05
15 0.5871 1.2342e+05
16 0.5781 1.2279e+05
17 0.5713 1.2240e+05
18 0.5660 1.2230e+05
19 0.5592 1.2179e+05
=============== Evaluating the model ===============
Rms: 0.994051469730769
RSquared: 0.412556298844873
在此輸出中,有 20 個反覆項目。 在每個反覆項目中,錯誤的量值會減少並逐漸接近 0。
root of mean squared error (RMS 或 RMSE) 被用來測量模型預測值與測試資料集觀察值之間的差異。 技術上來說,其為誤差平方之平均值的平方根。 此計量值越低,模型就越好。
R Squared 表示資料符合模型的程度。 範圍為 0 到 1。 值為 0 時,表示資料是隨機的,也就是與模型不相符。 值為 1 時,表示模型與資料完全相符。 R Squared 分數愈接近 1 愈好。
建立成功的模型是一個需要反覆嘗試的程序。 此模型一開始的品質較低,因為此教學課程是使用小型的資料集來提供快速的模型定型。 如果您對於模型的品質感到不滿意,可以嘗試為它提供較大的定型資料集,或選擇不同的定型演算法,並針對每個演算法搭配不同的超參數來改善它。 如需詳細資訊,請參閱下面的改善您的模型一節。
使用您的模型
現在您可以使用您的已定型模型對新資料進行預測。
請使用下列程式碼,在緊接著 EvaluateModel() 方法之後,建立 UseModelForSinglePrediction() 方法:
void UseModelForSinglePrediction(MLContext mlContext, ITransformer model)
{
}
將下列程式碼新增至 UseModelForSinglePrediction(),使用 PredictionEngine 來預測評等:
Console.WriteLine("=============== Making a prediction ===============");
var predictionEngine = mlContext.Model.CreatePredictionEngine<MovieRating, MovieRatingPrediction>(model);
PredictionEngine 是一種便利的 API,可讓您在單一資料執行個體上接著執行預測。 PredictionEngine 不是安全執行緒。 可接受在單一執行緒或原型環境中使用。 為了提升效能和執行緒安全性,請使用 PredictionEnginePool 服務,以建立 PredictionEngine 物件的 ObjectPool 供整個應用程式使用。 請參閱本指南,以瞭解如何在ASP.NET Core Web API 中使用 PredictionEnginePool。
注意
PredictionEnginePool 服務延伸模組目前處於預覽狀態。
建立稱為 testInput 的 MovieRating 執行個體,並將下列內容新增為 UseModelForSinglePrediction() 方法中的後續程式碼來將其傳遞至預測引擎:
var testInput = new MovieRating { userId = 6, movieId = 10 };
var movieRatingPrediction = predictionEngine.Predict(testInput);
Predict() 函式會在資料的單一資料行進行預測。
您可以接著使用 Score 或預測的評等,來判斷您是否想要將電影 movieId 10 推薦給使用者 6。 Score 愈高,使用者喜好特定電影的可能性愈高。 在此案例中,假設您推薦預測評等 > 3.5 的電影。
若要列印結果,請將下列內容新增為 UseModelForSinglePrediction() 方法中的後續程式碼:
if (Math.Round(movieRatingPrediction.Score, 1) > 3.5)
{
Console.WriteLine("Movie " + testInput.movieId + " is recommended for user " + testInput.userId);
}
else
{
Console.WriteLine("Movie " + testInput.movieId + " is not recommended for user " + testInput.userId);
}
將下列內容新增為對 EvaluateModel() 方法呼叫後面的下一行程式碼,以呼叫 UseModelForSinglePrediction() 方法:
UseModelForSinglePrediction(mlContext, model);
此方法的輸出看起來應類似下列文字:
=============== Making a prediction ===============
Movie 10 is recommended for user 6
儲存模型
若要使用您的模型在終端使用者應用程式中進行預測,您必須先儲存模型。
請使用下列程式碼,在緊接著 UseModelForSinglePrediction() 方法之後,建立 SaveModel() 方法:
void SaveModel(MLContext mlContext, DataViewSchema trainingDataViewSchema, ITransformer model)
{
}
在 SaveModel() 方法中新增下列程式碼來儲存您的已定型模型:
var modelPath = Path.Combine(Environment.CurrentDirectory, "Data", "MovieRecommenderModel.zip");
Console.WriteLine("=============== Saving the model to a file ===============");
mlContext.Model.Save(model, trainingDataViewSchema, modelPath);
此方法會將已定型模型儲存至 .zip 檔案 (在 "Data" 資料夾中),其之後可用於其他 .NET 應用程式中來進行預測。
將下列內容新增為對 UseModelForSinglePrediction() 方法呼叫後面的下一行程式碼,以呼叫 SaveModel() 方法:
SaveModel(mlContext, trainingDataView.Schema, model);
使用您已儲存的模型
儲存定型模型之後,您就可以在不同的環境中取用模型。 請參閱儲存和載入定型模型,以了解如何在應用程式中運作定型機器學習模型。
結果
完成上述步驟後,請執行主控台應用程式 (Ctrl + F5)。 上述單一預測的結果應該如下所示。 您可能會看到警告或處理中訊息,但為了讓結果變得清楚,這些訊息已從下列結果中移除。
=============== Training the model ===============
iter tr_rmse obj
0 1.5382 3.1213e+05
1 0.9223 1.6051e+05
2 0.8691 1.5050e+05
3 0.8413 1.4576e+05
4 0.8145 1.4208e+05
5 0.7848 1.3895e+05
6 0.7552 1.3613e+05
7 0.7259 1.3357e+05
8 0.6987 1.3121e+05
9 0.6747 1.2949e+05
10 0.6533 1.2766e+05
11 0.6353 1.2636e+05
12 0.6209 1.2561e+05
13 0.6072 1.2462e+05
14 0.5965 1.2394e+05
15 0.5868 1.2352e+05
16 0.5782 1.2279e+05
17 0.5713 1.2227e+05
18 0.5637 1.2190e+05
19 0.5604 1.2178e+05
=============== Evaluating the model ===============
Rms: 0.977175077487166
RSquared: 0.43233349213192
=============== Making a prediction ===============
Movie 10 is recommended for user 6
=============== Saving the model to a file ===============
恭喜! 您現在已成功建置推薦電影的機器學習服務模型。 您可以在 dotnet/samples 存放庫中找到本教學課程的原始程式碼。
改善模型
有幾種方式可讓您改善模型的效能,以便您進行更精確的預測。
資料
為每位使用者和影片識別碼新增更多具有足夠樣本的已定型資料,有助於改善推薦模型的品質。
交叉驗證是一種評估模型技術,會將資料隨機分割成子集 (而不是像本教學課程從資料集擷取出測試資料),並採用部分群組作為定型資料,以及部分群組作為測試資料。 此方法在模型品質方面的表現優於定型/測試分割。
功能
在本教學課程中,您只會使用資料集所提供的三個 Features (user id、movie id 和 rating)。
雖然這是不錯的起點,但在實際操作時,建議您新增其他屬性或 Features (例如年齡、性別、地理位置等),如果這些也包含在資料集內。 新增更多相關 Features 有助於改善推薦模型的效能。
如果您不確定哪 Features 一個可能最與機器學習工作有關,您也可以使用「特徵貢獻計算」 ( () 和 排列特徵重要性,ML.NET 提供來探索最具影響力 Features 的 。
演算法超參數
雖然 ML.NET 提供最佳的預設定型演算法,但您也可以變更演算法的超參數來進一步微調效能。
針對 Matrix Factorization,您可以使用 NumberOfIterations 和 ApproximationRank 等超參數,查看其是否可提供您更好的結果。
例如,本教學課程中的演算法選項如下:
var options = new MatrixFactorizationTrainer.Options
{
MatrixColumnIndexColumnName = "userIdEncoded",
MatrixRowIndexColumnName = "movieIdEncoded",
LabelColumnName = "Label",
NumberOfIterations = 20,
ApproximationRank = 100
};
其他建議演算法
具備共同篩選的矩陣分解演算法,僅為執行電影推薦的其中一種方法。 在許多情況下,您可能會沒有可用的評等資料,並只有使用者的電影觀看記錄。 而在其他情況下,您擁有的資料可能不只是使用者評等資料。
| 演算法 | 狀況 | 範例 |
|---|---|---|
| 單一類別矩陣分解 | 當您只需要 userId 和 movieId 時,請使用此選項。 此推薦類型乃根據共同採購案例或經常同時購買的產品,也就是會根據客戶自己的採購訂單記錄向客戶推薦一組產品。 | >試試看 |
| 欄位感知分解機器 | 當您所擁有的功能多於 userId、productId 和評等 (如產品描述或產品價格) 時,請使用此選項來進行推薦。 此方法也會使用共同作業篩選方法。 | >試試看 |
新使用者案例
共同篩選的一個常見問題是冷啟動問題,也就是當您有一個不具有先前資料的新使用者,以至於無法進行推斷時。 此問題的解決方法通常是要求新使用者建立設定檔,並對他們先前看過的電影評分 (舉例來說)。 雖然此方法會對使用者造成一些負擔,但可以為沒有評等記錄的新使用者提供一些起始資料。
資源
本教學課程中使用的資料衍生自 MovieLens 資料集。
後續步驟
在本教學課程中,您已了解如何:
- 選取機器學習演算法
- 準備及載入您的資料
- 建置及定型模型
- 評估模型
- 部署及取用模型
前進到下一個教學課程來深入了解