教學課程:將 ML.NET 分類模型定型以分類影像
了解如何使用預先定型的 TensorFlow 模型進行影像處理,將分類模型定型以分類影像。
會定型 TensorFlow 模型,以將影像分類成千個類別。 因為 TensorFlow 模型知道如何辨識影像中的模式,所以 ML.NET 模型可以使用其管線中的一部分,將原始影像轉換成特徵或輸入來定型分類模型。
在本教學課程中,您會了解如何:
- 了解問題
- 將預先定型的 TensorFlow 模型併入 ML.NET 管線
- 定型和評估 ML.NET 模型
- 分類測試影像
您可以在 dotnet/samples 存放庫中找到本教學課程的原始程式碼。 根據預設,本教學課程的 .NET 專案組態會以 .NET Core 2.2 為目標。
必要條件
選取正確的機器學習工作
深入學習
深度學習是機器學習的子集,其正為電腦視覺及語音辨識等領域帶來革命性的影響。
深度學習模型是使用包含多個學習層級的大量已標籤資料 \(英文\) 及神經網路來定型的。 深度學習:
- 能在某些工作上產生較好的效能,例如電腦視覺。
- 需要大量的定型資料。
影像分類是特定分類工作,可讓我們將影像自動分類為多個類別,例如:
- 是否能在影像中偵測到人類面孔。
- 偵測貓與狗。
或是以下列影像為例,判斷該影像是否為食物、玩具或設備:



注意
上述影像為 Wikimedia Commons 所有,並具有下列屬性:
- "220px-Pepperoni_pizza.jpg" 公眾領域,https://commons.wikimedia.org/w/index.php?curid=79505 \(英文\),
- "119px-Nalle_-_a_small_brown_teddy_bear.jpg" 攝影者:Jonik \(英文\) - 自行拍攝,CC BY-SA 2.0,https://commons.wikimedia.org/w/index.php?curid=48166 \(英文\)。
- "193px-Broodrooster.jpg" 攝影者:M.Minderhoud \(英文\) - 自行創作,CC BY-SA 3.0,https://commons.wikimedia.org/w/index.php?curid=27403 \(英文\)
若要從頭對影像分類模型進行定型,將會需要設定數以百萬計的參數、眾多已標籤的定型資料,以及大量的計算資源 (數以百計的 GPU 小時)。 預先定型模型雖然不如從頭對自訂模型進行定型來得有效,但是能讓您透過僅需處理數以千計的影像 (而非數以百萬計的已標籤影像) 來縮短此程序,並以較為快速的方式建置自訂模型 (在不具備 GPU 的電腦上於一小時內便能完成)。 本教學課程僅使用十個左右的訓練影像,進一步縮減程序。
Inception model 已針對將影像分類至一千個類別進行定型,但是針對本教學課程,您只需要將影像分類至較小的類別集合,且僅分類至那些集合。 您可以使用 Inception model 的能力,辨識及分類影像到您自訂影像分類器新的受限類別之中。
- Food
- Toy (玩具)
- 設備
本教學課程使用 TensorFlow 起始深度學習模型,這是在 ImageNet 資料集上定型的熱門影像辨識模型。 TensorFlow 模型會將整個影像分類成一千個類別,例如 “Umbrella”、“Jersey” 和 “Dishwasher”。
由於 Inception model 已經搭配數以千計的不同影像預先進行定型,其在內部包含影像識別所需的影像特徵。 我們可以使用模型中的這些內部影像特徵來定型具有較少類別的新模型。
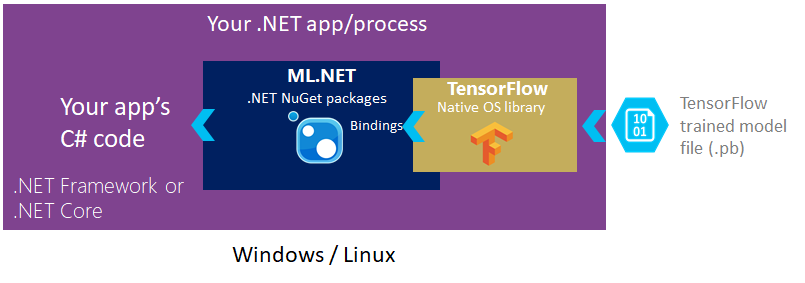
如下圖所示,您會在 .NET Core 或 .NET Framework 應用程式中新增對 ML.NET NuGet 套件的參考。 實際上,ML.NET 包含和參考原生 TensorFlow 程式庫,可讓您撰寫載入現有定型模型檔案的程式 TensorFlow 代碼。
多元分類
使用 TensorFlow 開始模型來擷取適合作為傳統機器學習演算法輸入的功能之後,我們會新增 ML.NET 多類別分類器。
在此案例中使用的特定定型器是多維度羅吉斯迴歸演算法。
此定型器所實作的演算法對於具有大量特徵的問題執行良好,這是對影像資料運作的深度學習模型的情況。
如需詳細資訊,請參閱深度學習與機器學習。
資料
有兩個資料來源:.tsv 檔案,以及影像檔案。 tags.tsv 檔案包含兩個資料行:第一個會被定義為 ImagePath,而第二個則是對應至影像的 Label。 下列範例檔案沒有標頭資料列,且看起來像這樣:
broccoli.jpg food
pizza.jpg food
pizza2.jpg food
teddy2.jpg toy
teddy3.jpg toy
teddy4.jpg toy
toaster.jpg appliance
toaster2.png appliance
定型及測試影像都位於您將以 zip 檔案下載的資產資料夾中。 這些影像皆由 Wikimedia Commons 所有。
Wikimedia Commons \(英文\), the free media repository。 於 2018 年 10 月 17 日 10:48 擷取自:https://commons.wikimedia.org/wiki/Pizzahttps://commons.wikimedia.org/wiki/Toasterhttps://commons.wikimedia.org/wiki/Teddy_bear
設定
建立專案
建立稱為 "TransferLearningTF" 的 C# 主控台應用程式。 按 [下一步] 按鈕。
選擇 .NET 6 作為要使用的架構。 按一下 [ 建立 ] 按鈕。
安裝「Microsoft.ML NuGet 套件」:
注意
除非另有說明,否則此樣本會使用所提及 NuGet 封裝的最新穩定版本。
- 在 [方案總管] 中,於您的專案上按一下滑鼠右鍵,然後選取 [管理 NuGet 套件]。
- 選擇 [nuget.org] 作為 [套件來源],選取 [瀏覽] 索引標籤,搜尋 Microsoft.ML。
- 選取 [安裝] 按鈕。
- 選取 [預覽變更] 對話方塊上的 [確定] 按鈕。
- 如果您同意所列套件的授權條款,請在 [授權接受] 對話方塊上選取 [我接受] 按鈕。
- 針對 Microsoft.ML.ImageAnalytics、SciSharp.TensorFlow.Redist 和 Microsoft.ML.TensorFlow 重複這些步驟。
下載資產
下載專案資產目錄 zip 檔案,然後將它解壓縮。
將
assets目錄複製到您的 TransferLearningTF 專案目錄中。 此目錄及其子目錄包含本教學課程所需的資料和支援檔案 (Inception model 除外,您將會在下個步驟中下載並新增它)。下載 Inception model,然後將它解壓縮。
將剛才解壓縮的
inception5h目錄的內容複製到您 TransferLearningTF 專案的assets/inception目錄中。 此目錄包含本教學課程所需的模型和其他支援檔案,如下圖所示: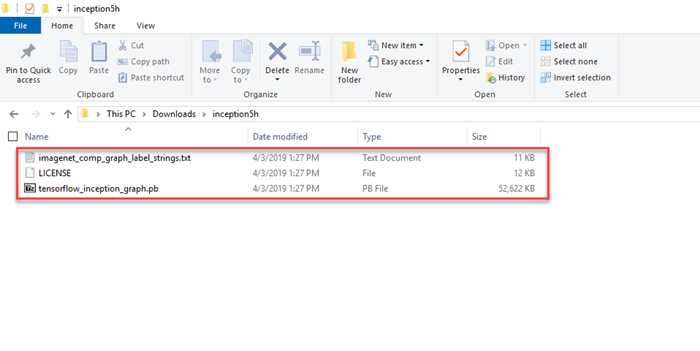
在 [方案總管] 中,以滑鼠右鍵按一下資產目錄及子目錄中的每個檔案,然後選取 [內容]。 在 [進階] 底下,將 [複製到輸出目錄] 的值變更為 [有更新時才複製]。
建立類別及定義路徑
在 Program.cs 檔案頂端新增下列額外的
using陳述式:using Microsoft.ML; using Microsoft.ML.Data;將下列程式碼新增至緊接在使用陳述式下方的一行,以指定資產路徑:
string _assetsPath = Path.Combine(Environment.CurrentDirectory, "assets"); string _imagesFolder = Path.Combine(_assetsPath, "images"); string _trainTagsTsv = Path.Combine(_imagesFolder, "tags.tsv"); string _testTagsTsv = Path.Combine(_imagesFolder, "test-tags.tsv"); string _predictSingleImage = Path.Combine(_imagesFolder, "toaster3.jpg"); string _inceptionTensorFlowModel = Path.Combine(_assetsPath, "inception", "tensorflow_inception_graph.pb");為輸入資料和預測建立類別。
public class ImageData { [LoadColumn(0)] public string? ImagePath; [LoadColumn(1)] public string? Label; }ImageData是輸入資料集類別,並具有下列 String 欄位:ImagePath包含影像檔案名稱。Label包含影像標籤的值。
將新類別新增至
ImagePrediction的專案:public class ImagePrediction : ImageData { public float[]? Score; public string? PredictedLabelValue; }ImagePrediction是影像預測類別,並具有下列欄位:Score包含指定影像分類的信賴百分比。PredictedLabelValue包含已預測影像分類標籤的值。
ImagePrediction是在模型定型後,用來進行預測的類別。 它具有影像路徑的string(ImagePath)。Label會被用來進行模型的重複使用和定型。PredictedLabelValue的使用時機是在進行預測和評估的期間。 就評估而言,會使用含有定型資料、預設值及模型的輸入。
將變數初始化
搭配
MLContext的新執行個體來初始化mlContext變數。 使用下列程式碼取代Console.WriteLine("Hello World!")行:MLContext mlContext = new MLContext();類別 MLContext 是所有 ML.NET 作業的起點,初始化
mlContext會建立可跨模型建立工作流程物件共用的新 ML.NET 環境。 就概念而言,類似於 Entity Framework 中的DBContext。
建立起始模型參數的結構
起始模型具有數個您需要傳遞的參數。 在初始化
mlContext變數之後,使用下列程式碼來建立結構,以將參數值對應至易記名稱:struct InceptionSettings { public const int ImageHeight = 224; public const int ImageWidth = 224; public const float Mean = 117; public const float Scale = 1; public const bool ChannelsLast = true; }
建立顯示公用程式方法
因為您將會不只一次顯示影像資料和相關預測,所以請建立顯示公用程式方法來處理顯示影像和預測結果。
使用下列程式碼,在緊接著
InceptionSettings結構之後,建立DisplayResults()方法:void DisplayResults(IEnumerable<ImagePrediction> imagePredictionData) { }填入
DisplayResults方法的主體:foreach (ImagePrediction prediction in imagePredictionData) { Console.WriteLine($"Image: {Path.GetFileName(prediction.ImagePath)} predicted as: {prediction.PredictedLabelValue} with score: {prediction.Score?.Max()} "); }
建立方法來進行預測
請使用下列程式碼,緊接在
DisplayResults()方法之前,建立ClassifySingleImage()方法:void ClassifySingleImage(MLContext mlContext, ITransformer model) { }建立包含單一
ImagePath之完整路徑和影像檔案名稱的ImageData物件。 將下列程式碼新增為ClassifySingleImage()方法中的下一行:var imageData = new ImageData() { ImagePath = _predictSingleImage };將下列程式碼新增為
ClassifySingleImage方法中的下一行,以建立單一預測:// Make prediction function (input = ImageData, output = ImagePrediction) var predictor = mlContext.Model.CreatePredictionEngine<ImageData, ImagePrediction>(model); var prediction = predictor.Predict(imageData);若要取得預測,請使用 Predict() 方法。 PredictionEngine 是一種便利的 API,可讓您在單一資料執行個體上接著執行預測。
PredictionEngine不是安全執行緒。 可接受在單一執行緒或原型環境中使用。 為了提升效能和執行緒安全性,請使用PredictionEnginePool服務,以建立PredictionEngine物件的ObjectPool供整個應用程式使用。 請參閱本指南,以瞭解如何在ASP.NET Core Web API 中使用PredictionEnginePool。注意
PredictionEnginePool服務延伸模組目前處於預覽狀態。將預測結果顯示為
ClassifySingleImage()方法中的下一行程式碼:Console.WriteLine($"Image: {Path.GetFileName(imageData.ImagePath)} predicted as: {prediction.PredictedLabelValue} with score: {prediction.Score?.Max()} ");
建構 ML.NET 模型管線
ML.NET 模型管線是估算器的鏈結。 管線建構期間不會執行。 估算器物件會建立,但不會執行。
新增方法以產生模型
此方法是教學課程的核心。 它會建立模型的管線,並定型管線以產生 ML.NET 模型。 也會針對一些先前未看到的測試資料來評估模型。
使用下列程式碼,緊接在
InceptionSettings結構之後及DisplayResults()方法之前,建立GenerateModel()方法:ITransformer GenerateModel(MLContext mlContext) { }新增估算器以載入、調整大小,並從影像資料擷取像素:
IEstimator<ITransformer> pipeline = mlContext.Transforms.LoadImages(outputColumnName: "input", imageFolder: _imagesFolder, inputColumnName: nameof(ImageData.ImagePath)) // The image transforms transform the images into the model's expected format. .Append(mlContext.Transforms.ResizeImages(outputColumnName: "input", imageWidth: InceptionSettings.ImageWidth, imageHeight: InceptionSettings.ImageHeight, inputColumnName: "input")) .Append(mlContext.Transforms.ExtractPixels(outputColumnName: "input", interleavePixelColors: InceptionSettings.ChannelsLast, offsetImage: InceptionSettings.Mean))影像資料必須處理成 TensorFlow 模型預期的格式。 在此情況下,影像會載入記憶體中、調整大小為一致大小,並將像素擷取至數值向量。
新增估算器以載入 TensorFlow 模型,並為其評分:
.Append(mlContext.Model.LoadTensorFlowModel(_inceptionTensorFlowModel). ScoreTensorFlowModel(outputColumnNames: new[] { "softmax2_pre_activation" }, inputColumnNames: new[] { "input" }, addBatchDimensionInput: true))管線中的這個階段會將 TensorFlow 模型載入記憶體中,然後透過 TensorFlow 模型網路處理像素值的向量。 將輸入套用至深度學習模型,並使用模型產生輸出,稱為評分。 完全使用模型時,評分會進行推斷或預測。
在此情況下,您會使用最後一層以外的所有 TensorFlow 模型,這是進行推斷的層級。 倒數第二個層級的輸出標示為
softmax_2_preactivation。 此層級的輸出實際上是原始輸入影像特性特徵的向量。TensorFlow 模型所產生的這項特徵向量將用來作為 ML.NET 定型演算法的輸入。
新增估算器,將定型資料中的字串標籤對應至整數索引鍵值:
.Append(mlContext.Transforms.Conversion.MapValueToKey(outputColumnName: "LabelKey", inputColumnName: "Label"))接下來附加的 ML.NET 定型器需要其標籤
key的格式,而不是任一字元串。 索引鍵是一個數字,具有與字串值的一對一對應。新增 ML.NET 定型演算法:
.Append(mlContext.MulticlassClassification.Trainers.LbfgsMaximumEntropy(labelColumnName: "LabelKey", featureColumnName: "softmax2_pre_activation"))新增估算器,將預測的索引鍵值對應回字串:
.Append(mlContext.Transforms.Conversion.MapKeyToValue("PredictedLabelValue", "PredictedLabel")) .AppendCacheCheckpoint(mlContext);
將模型定型
使用 LoadFromTextFile 包裝函式載入定型資料。 將下列程式碼加入為
GenerateModel()方法中的下一行:IDataView trainingData = mlContext.Data.LoadFromTextFile<ImageData>(path: _trainTagsTsv, hasHeader: false);ML.NET 中的資料會以 IDataView 介面表示。
IDataView是彈性且有效率的表格式資料描述方式 (數值和文字)。 資料可以從文字或即時 (例如 SQL 資料庫或記錄檔) 載入至IDataView物件。使用上方載入的資料來定型模型:
ITransformer model = pipeline.Fit(trainingData);Fit()方法會將定型資料集套用至管線,以定型模型。
評估模型的正確性
將下列程式碼新增至
GenerateModel方法的下一行,以載入和轉換測試資料:IDataView testData = mlContext.Data.LoadFromTextFile<ImageData>(path: _testTagsTsv, hasHeader: false); IDataView predictions = model.Transform(testData); // Create an IEnumerable for the predictions for displaying results IEnumerable<ImagePrediction> imagePredictionData = mlContext.Data.CreateEnumerable<ImagePrediction>(predictions, true); DisplayResults(imagePredictionData);您可以使用一些範例影像來評估模型。 就像定型資料一樣,這些影像必須載入至
IDataView,以便由模型轉換。將下列程式碼新增至
GenerateModel()方法以評估模型:MulticlassClassificationMetrics metrics = mlContext.MulticlassClassification.Evaluate(predictions, labelColumnName: "LabelKey", predictedLabelColumnName: "PredictedLabel");當您具有預測之後,請設定 Evaluate() 方法:
- 評估模型 (將預測的值與測試資料集
labels比較)。 - 傳回模型效能計量。
- 評估模型 (將預測的值與測試資料集
顯示模型正確性計量
使用下列程式碼來顯示計量、共用結果,然後依結果採取動作:
Console.WriteLine($"LogLoss is: {metrics.LogLoss}"); Console.WriteLine($"PerClassLogLoss is: {String.Join(" , ", metrics.PerClassLogLoss.Select(c => c.ToString()))}");下列計量會針對影像分類進行評估:
Log-loss:請參閱記錄檔遺失。 建議讓記錄檔遺失盡量接近零。Per class Log-loss. 建議讓每個類別的記錄檔遺失盡量接近零。
新增下列程式碼來將定型後的模型作為下一行傳回:
return model;
執行應用程式!
在建立 MLContext 類別之後新增對
GenerateModel的呼叫:ITransformer model = GenerateModel(mlContext);在對
GenerateModel()方法的呼叫後面新增對ClassifySingleImage()方法的呼叫:ClassifySingleImage(mlContext, model);執行主控台應用程式 (Ctrl + F5)。 您的結果應該與下列輸出類似。 (您可能會看到警告或處理中訊息,但為了讓結果變得清楚,這些訊息已從下列結果中移除。)
=============== Training classification model =============== Image: broccoli2.jpg predicted as: food with score: 0.8955513 Image: pizza3.jpg predicted as: food with score: 0.9667718 Image: teddy6.jpg predicted as: toy with score: 0.9797683 =============== Classification metrics =============== LogLoss is: 0.0653774699265059 PerClassLogLoss is: 0.110315812569315 , 0.0204391272836966 , 0 =============== Making single image classification =============== Image: toaster3.jpg predicted as: appliance with score: 0.9646884
恭喜! 您現在已成功在 ML.NET 中建置分類模型,以使用預先定型的 TensorFlow 進行影像處理來分類影像。
您可以在 dotnet/samples 存放庫中找到本教學課程的原始程式碼。
在本教學課程中,您已了解如何:
- 了解問題
- 將預先定型的 TensorFlow 模型併入 ML.NET 管線
- 定型和評估 ML.NET 模型
- 分類測試影像
請查看機器學習範例 GitHub 存放庫,以探索更複雜的影像分類範例。