Azure 監視器

沒有任何一家雲端提供者有提供和 Azure 一樣成熟的雲端應用程式監視解決方案。 Azure 監視器是為了讓您了解系統狀態所設計的諸多工具的統稱。 其可協助您了解雲端原生服務的執行狀況,並主動識別會影響服務的問題。 圖 7-12 呈現的是 Azure 監視器的概略視圖。
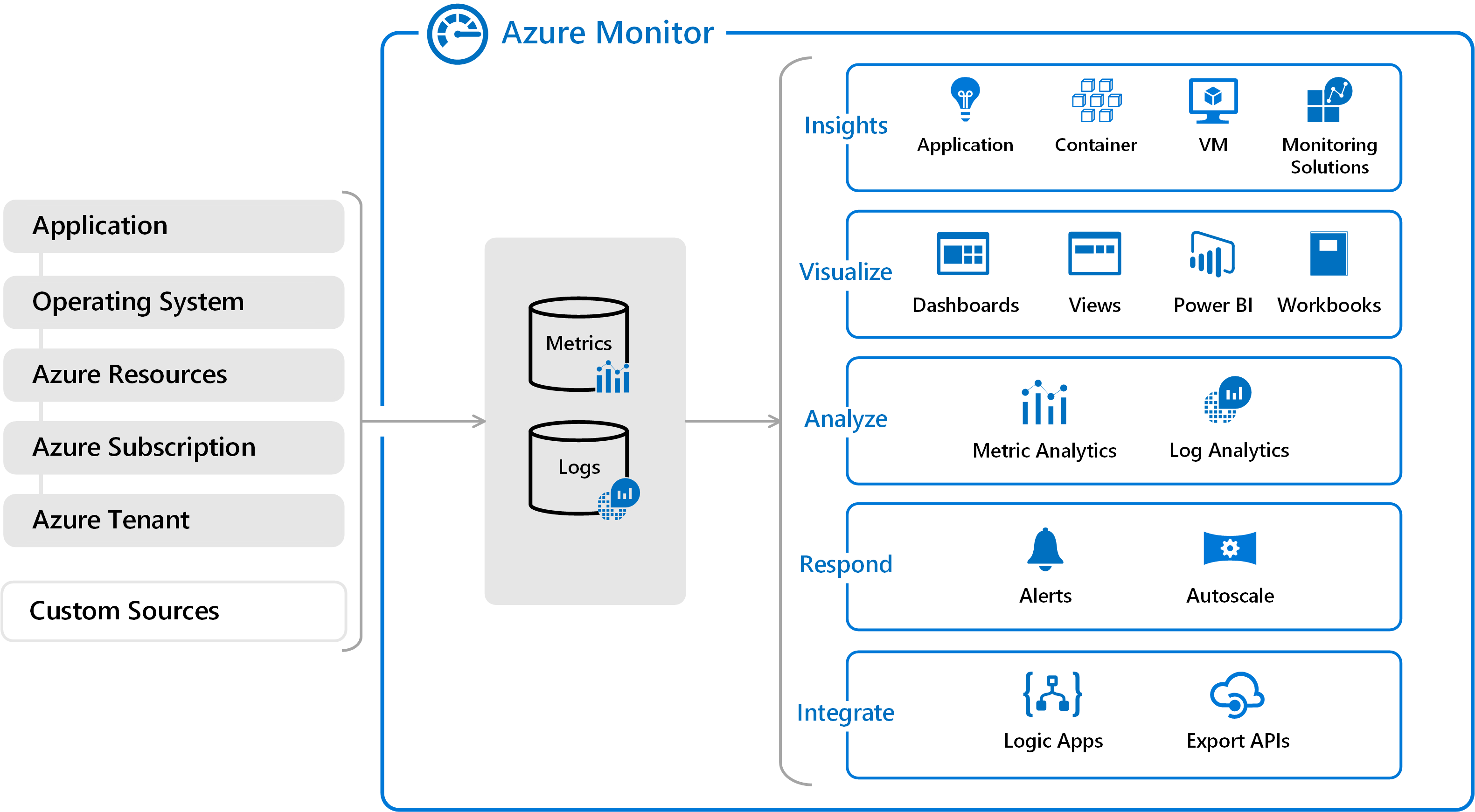 圖 7-12。 Azure 監視器的概略視圖。
圖 7-12。 Azure 監視器的概略視圖。
收集記錄和計量
任何監視解決方案的第一步都是盡量收集資料。 所收集的資料越多,便能提供更加深入的解析。 一直以來,檢測系統都不是件容易的事。 簡易網路管理通訊協定 (SNMP) 是用於收集機器層級資訊的通訊協定典範,但需要大量知識與設定才能進行。 幸運的是,Azure 監視器會自動收集最常見的計量,因此已免去大部分的困難工作。
但其無法自動檢測應用程式層級的計量和事件,因為這些是所部署應用程式特有的資料。 為了收集這些計量,有SDK 和 API 可供您直接報告這類資訊,例如在客戶註冊或完成訂單時。 透過 Application Insights 也可以擷取例外狀況並回報給 Azure 監視器。 SDK 支援可於雲端原生應用程式中發現的大部分語言,包括 Go、Python、JavaScript 和 .NET 語言。
收集應用程式狀態相關資訊的最終目的,是確保終端使用者會獲得良好體驗。 相較於進行徹底的 Web 測試,還有什麼更好的方法能判斷使用者是否遇到問題呢? 這些測試可以像從世界各地的位置 Ping 您的網站一樣簡單,也可以像讓代理程式登入網站並模擬使用者動作一樣複雜。
報告資料
收集到資料後,就可以操作資料、加以彙總並繪製成圖表,讓使用者立即看到所發生的問題。 這些圖表可以收集到儀表板或活頁簿 (活頁簿是多頁式報表,設計目的是要描述系統的某些方面)。
新式應用程式如果沒有一些人工智慧或機器學習功能,就不能說是完整的應用程式。 為此,資料可以傳遞至 Azure 中的各種機器學習工具,讓您擷取資料中可能會隱藏起來的趨勢和資訊。
Application Insights 提供稱為 Kusto (類似 SQL) 的強大查詢語言,可以查詢記錄、彙總記錄,甚至是繪製圖表。 例如,下列查詢會找出 2007 年 11 月的所有記錄、依狀態分組記錄,並將前 10 大記錄繪製為圓形圖。
StormEvents
| where StartTime >= datetime(2007-11-01) and StartTime < datetime(2007-12-01)
| summarize count() by State
| top 10 by count_
| render piechart
圖 7-13 顯示此 Application Insights 查詢的結果。
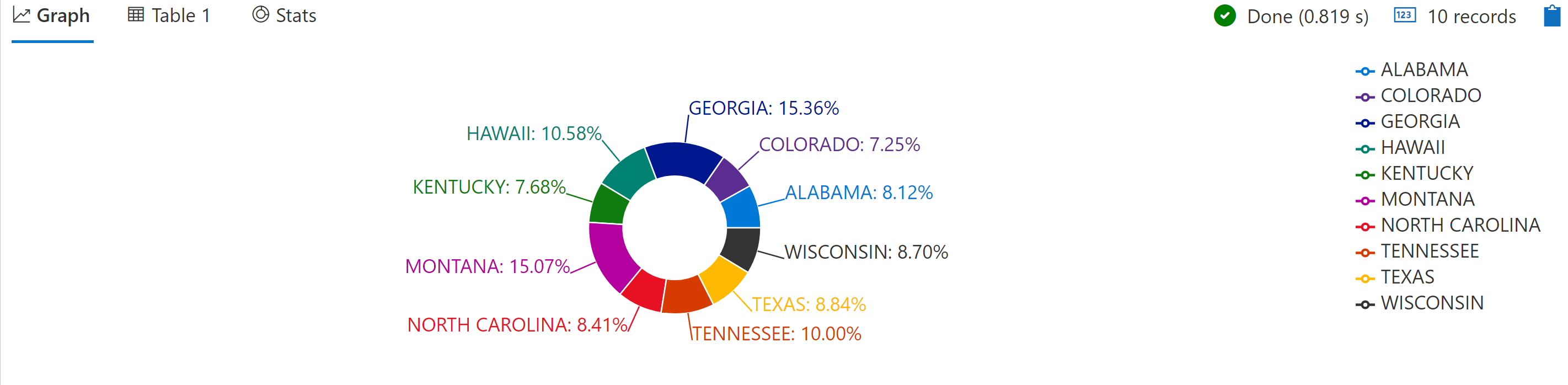 圖 7-13。 Application Insights 查詢結果。
圖 7-13。 Application Insights 查詢結果。
有一個用於實驗 Kusto 查詢的遊樂場。 閱讀查詢範例也會讓您有所啟發。
儀表板
有數種不同的儀表板技術可用來呈現 Azure 監視器的資訊。 最簡單的方式或許是在 Application Insights 中執行查詢,並將資料繪製成圖表。
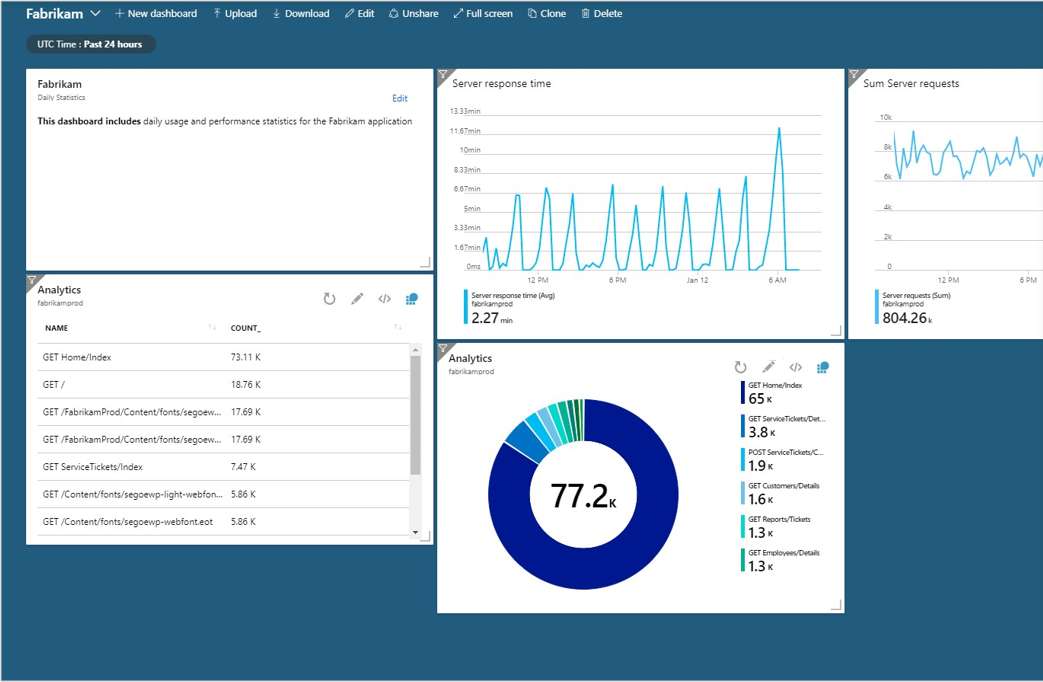 圖 7-14。 內嵌在主要 Azure 儀表板中的 Application Insights 圖表範例。
圖 7-14。 內嵌在主要 Azure 儀表板中的 Application Insights 圖表範例。
接著,可以透過使用儀表板功能將這些圖表適當地內嵌到 Azure 入口網站。 使用者若有更確切的需求 (例如,需要能夠向下切入數層資料),也可以將 Azure 監視器資料提供給 Power BI。 Power BI 是領先業界的企業級商業智慧工具,可彙總許多不同資料來源的資料。
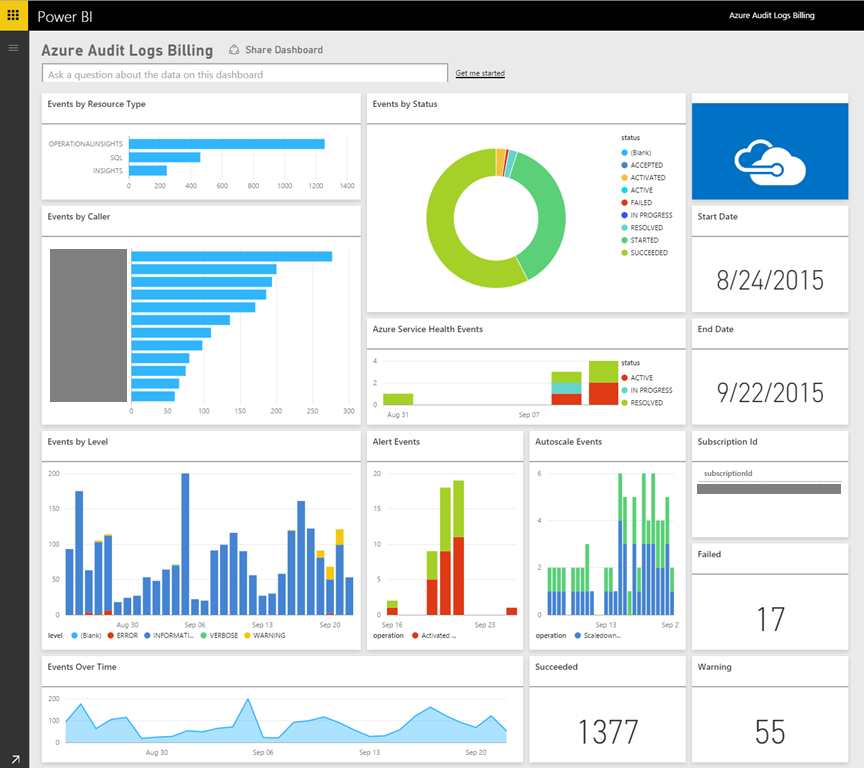
圖 7-15。 Power BI 儀表板範例。
警示
有時候,有了資料儀表板還不夠。 如果沒有人監看儀表板,可能還是要等好幾個小時才能解決問題,甚至是偵測到問題。 為此,Azure 監視器也提供了最優秀的警示解決方案。 警示可由各種條件觸發,包括:
- 計量值
- 記錄搜尋查詢
- 活動記錄事件
- 底層 Azure 平台健康情況
- 針對網站可用性的測試
警示一經觸發,便可以執行各式各樣的工作。 簡單一點的,警示可能只會傳送電子郵件通知給郵寄清單,或傳簡訊給個人。 複雜一點的,警示可以在 PagerDuty 之類的工具中觸發工作流程,其會知道特定應用程式的待命者。 警示可以在 Microsoft Flow 中觸發動作,而讓工作流程有近乎無限的可能性。
在識別警示的常見原因時,便可以使用警示常見原因的詳細資料以及用來解決警示的步驟來增強警示。 高度成熟的雲端原生應用程式部署可以選擇開始自我修復工作以執行各種動作,例如從擴展集移除失敗的節點,或觸發自動調整活動。 最終情況可能是,系統不必再於凌晨 2 點喚醒待命人員來解決即時網站問題,因為系統將能夠自行調整以做出補償,或至少拖到隔天一早有人上班為止。
Azure 監視器會自動利用機器學習來了解所部署應用程式的正常運作參數。 此方法可讓其偵測到未在正常參數範圍內運作的服務。 例如,在一般工作日,網站上的流量可能是每分鐘 10,000 個要求。 然後,在某一週,要求數目突然飆高到不尋常的每分鐘 20,000 個要求。 智慧偵測會注意到這個異常情況,並觸發警示。 同時,趨勢分析也足夠聰明,而能夠避免在流量負載符合預期時引發誤判。