Azure 工作負載中負責任的 AI
在工作負載設計中負責任 AI 的目標是確保 AI 演算法的使用是 公平、透明且包容性。 架構完善的安全性原則與機密性和完整性的焦點相互關聯。 必須備妥安全性措施,才能維護用戶隱私權、保護數據,以及保護設計的完整性,這不應該因非預期用途而誤用。
在 AI 工作負載中,決策是由通常使用不透明邏輯的模型所做出。 用戶應該信任系統的功能,並有信心負責任地做出決策。 必須避免操縱、內容毒性、IP 侵權和捏造回應等不道德行為。
請考慮媒體娛樂公司想要使用 AI 模型提供建議的使用案例。 無法實作負責任的 AI 和適當的安全性,可能會導致不良動作專案控制模型。 模型可能會建議可能導致有害結果的媒體內容。 對於組織而言,此行為可能會導致品牌損毀、不安全的環境和法律問題。 因此,在整個系統的生命週期中保持道德警惕至關重要且不可談判。
道德決策應將安全性和工作負載管理排定優先順序,並考慮到人為結果。 熟悉Microsoft負責任 AI 架構,並確定原則會反映在您的設計中並測量。 此影像顯示架構的核心概念。
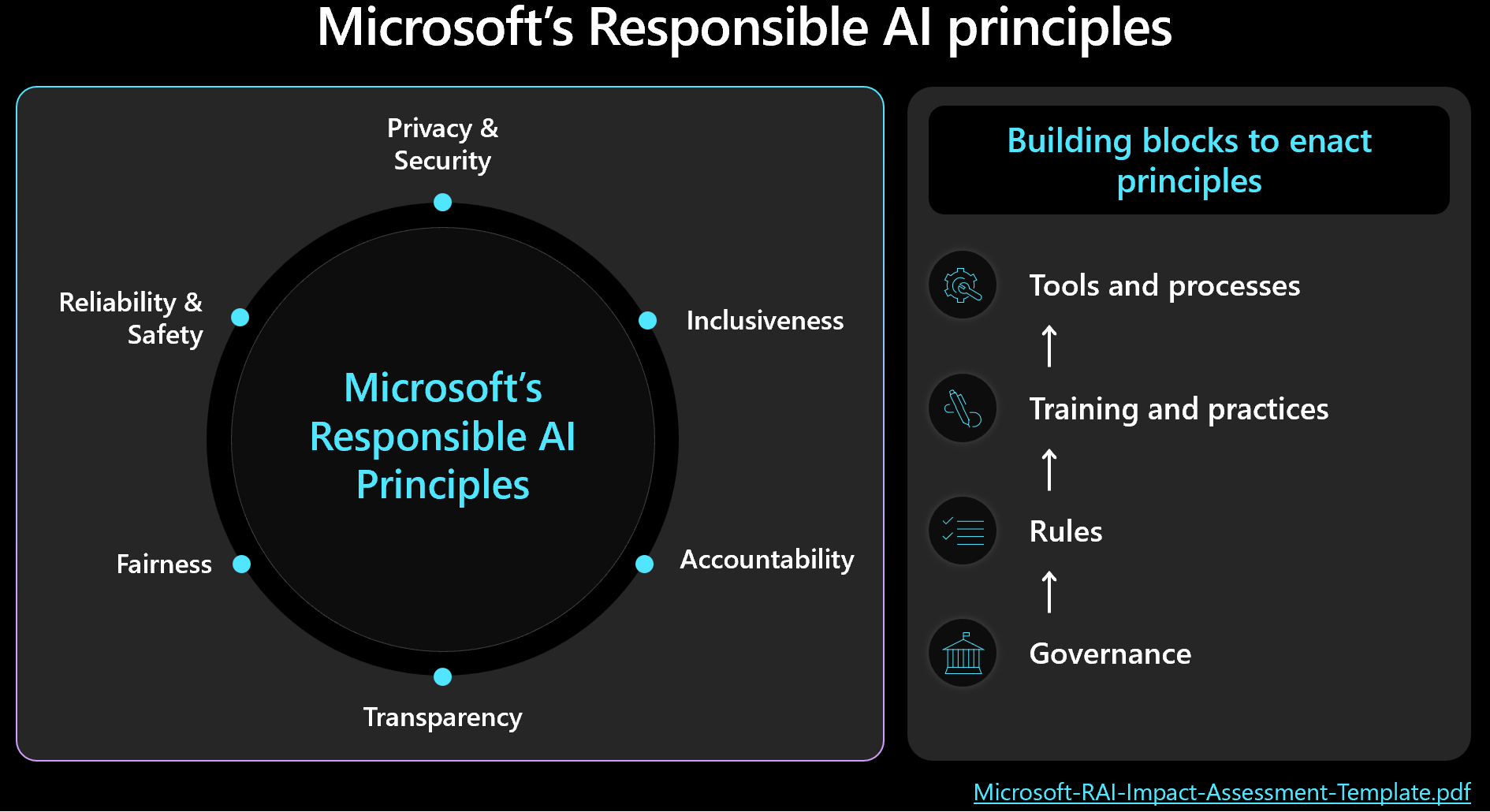
重要
預測精確度和負責任 AI 計量通常相互關聯。 改善模型的精確度可以增強其公平性和與現實的一致性。 不過,雖然道德 AI 經常與精確度一致,但僅精確度並不包含所有道德考慮。 請務必負責任地驗證這些道德原則。
本文提供道德決策、驗證使用者輸入,以及確保安全用戶體驗的建議。 它也提供數據安全性的指引,以確保用戶數據受到保護。
建議
以下是本文所提供的建議摘要。
| 建議 | 描述 |
|---|---|
| 開發原則,以在生命週期的每個階段強制執行道德做法。 | 包含明確陳述道德需求的檢查清單專案,專為工作負載內容量身打造。 範例包括用戶數據透明度、同意設定,以及處理「被遺忘的權利」的程式。 ▪ 開發負責任的 AI 原則 ▪ 在負責任 AI 原則上強制執行治理 |
| 使用最大化隱私權的目標來保護用戶數據。 | 僅收集必要專案,並取得適當的使用者同意。 套用技術控制項來保護使用者配置檔、其數據,以及存取該數據。 ▪ 以道德方式處理用戶數據 ▪ 檢查傳入和傳出數據 |
| 讓 AI 決策保持清楚且可理解。 | 維護建議演算法運作方式的清楚說明,並提供使用者對數據使用方式和演演算法決策的深入解析,以確保他們瞭解並信任此程式。 ▪ 確保用戶體驗安全 |
開發負責任的 AI 原則
記錄您對道德和負責任 AI 使用方式的方法。 明確在生命週期的每個階段套用的狀態原則,讓工作負載小組瞭解其責任。 雖然Microsoft的負責任 AI 標準提供指導方針,但您必須為內容定義這些意義。
例如,原則應該包含用戶數據透明度和同意設定機制的檢查清單專案,理想情況下允許使用者退出退出數據包含。 數據管線、分析、模型定型和其他階段都必須遵守該選擇。 另一個範例是處理「被遺忘的權利」的程式。請洽詢貴組織的道德部門和法律小組,以做出明智的決策。
建立關於數據使用方式和演演算法決策的透明原則,以確保用戶瞭解並信任此程式。 記錄這些決定,以維護潛在的未來訴訟的明確歷程記錄。
實作道德 AI 涉及三個主要角色:研究小組、原則小組和工程小組。 這些小組之間的共同作業應可運作。 如果您的組織有現有的小組,請利用其工作;否則,請自行建立這些做法。
對職責分離負責:
研究小組會藉由諮詢組織指導方針、業界標準、法律、法規和已知的紅隊策略,進行風險探索 。
原則小組會開發工作負載特有的原則,併入父組織和政府法規的指導方針。
工程小組會將原則 實作至其流程和交付專案,確保其驗證和測試是否遵守。
每個小組都會正式化其指導方針,但 工作負載小組必須負責自己的記載做法。 小組應該清楚記錄任何其他步驟或刻意偏差,確定允許什麼沒有模棱兩可。 此外,請透明瞭解解決方案中任何潛在的缺點或非預期的結果。
在負責任 AI 原則上強制執行治理
設計您的工作負載以 符合組織和法規治理。 例如,如果透明度是組織需求,請判斷其如何套用至您的工作負載。 識別設計、生命週期、程序代碼或其他元件中的區域,其中應引進透明度功能以符合該標準。
瞭解必要的治理、責任、審查委員會和報告授權。 請確定 您的治理委員會已核准並簽署 工作負載設計,以避免重新設計並降低道德或隱私權考慮。 您可能需要經過多層核准。 以下是治理的典型結構。
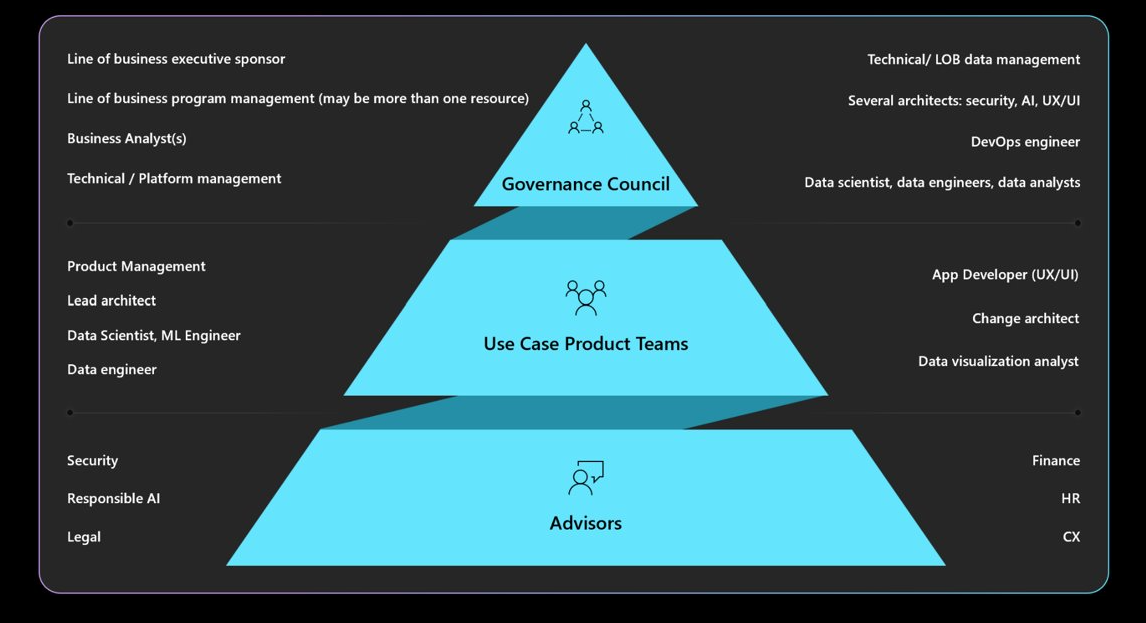
如需組織原則和核准者的相關信息,請參閱 雲端採用架構:定義負責任的 AI 策略。
確保用戶體驗安全
用戶體驗應以產業指導方針為基礎。 利用 Microsoft Human-AI 體驗設計連結庫 ,其中包含原則並提供實作的實作,以及來自Microsoft產品和其他產業來源的範例。
用戶互動的整個生命週期都有工作負載責任,從使用者的意圖開始,在會話期間使用系統,以及因為系統錯誤而中斷。 以下是需要考慮的一些做法:
建置透明度。 讓使用者知道系統如何產生其查詢的回應。
包含模型所參考之數據源的連結,以進行預測,藉由顯示資訊的來源來增強使用者信心。 數據設計應確保元數據中包含這些來源。 當擷取增強型應用程式中的協調器執行搜尋時,它會擷取 20 個檔案區塊,並將屬於三個不同的檔的前 10 個區塊傳送至模型做為內容。 UI 接著可以在顯示模型的回應時參考這三個源檔,以提高透明度和使用者信任。
使用代理程式時,透明度會變得更重要,後者在前端介面和後端系統之間充當媒介。 例如,在票證系統中,協調流程程式代碼會解譯使用者意圖,並呼叫 API 來呼叫代理程式以擷取必要的資訊。 公開這些互動可讓使用者知道系統的動作。
針對涉及多個代理程式的自動化工作流程,請建立記錄每個步驟的記錄檔。 這項功能有助於識別和更正錯誤。 此外,它也可以為使用者提供決策的說明,讓透明度運作。
警告
實作透明度建議時,請避免讓用戶無法取得太多資訊。 使用漸進式方法,從最少干擾性UI方法開始。
例如,顯示具有模型信賴分數的工具提示。 您可以納入使用者可以按兩下連結以取得更多詳細資料,例如源文件的連結。 這個使用者起始的方法會讓UI保持非干擾性,並讓使用者只有在選擇時才尋求其他資訊。
收集意見反應。 實作意見反應機制。
避免在每次響應之後,對大量問卷的使用者造成壓倒性。 請改用簡單、快速的意見反應機制,例如向上/向下豎起大拇指,或針對答案的特定層面,以 1 到 5 來評分系統。 這個方法可讓細微的意見反應不干擾,協助改善系統一段時間。 請留意意見反應的潛在偏差,因為使用者響應背後可能有次要原因。
實作意見反應機制會影響架構,因為需要數據記憶體。 視需要將此視為用戶數據,並套用隱私權控制層級。
除了回應意見反應之外,還收集用戶體驗有效性的意見反應。 您可以透過系統的監視堆疊收集參與計量來完成此動作。
讓內容安全措施運作
使用自定義解決方案程式代碼、適當的工具和有效的安全性做法,將內容安全性整合到 AI 生命週期的每個階段。 以下是一些策略。
數據匿名。 當數據從擷取移至定型或評估時,請進行檢查,以將洩漏個人資訊的風險降到最低,並避免暴露原始用戶數據的風險。
Con 帳篷模式 ration。 使用即時評估要求和回應的內容安全 API,並確保這些 API 可連線。
識別並減輕威脅。 將已知的安全性做法套用至您的 AI 案例。 例如,進行威脅模型化,並記錄威脅及其風險降低。 Red Team 練習等常見安全性做法適用於 AI 工作負載。 紅色小組可以測試模型是否可以操作以產生有害的內容。 這些活動應該整合到 AI 作業中。
如需執行紅色小組測試的相關信息,請參閱 規劃大型語言模型 (LLM) 及其應用程式的紅色小組。
使用正確的計量。 使用適當的計量,以有效測量模型的道德行為。 計量會根據 AI 模型的類型而有所不同。 產生模型測量可能不適用於回歸模型。 請考慮預測預期壽命和結果影響保險費率的模型。 此模型中的偏差可能會導致道德問題,但問題源於核心計量測試中的偏差。 改善精確度可以降低道德問題,因為道德和正確性計量通常相互關聯。
新增道德檢測。 AI 模型結果必須可解釋。 您需要證明和追蹤推斷的製作方式,包括用於定型的數據、計算的特徵和地面數據。 在歧視 AI 中,您可以逐步證明決策的合理性。 不過,對於產生模型,說明結果可能會相當複雜。 記錄決策程式 ,以解決潛在的法律影響並提供透明度。
整個 AI 生命週期都應該實作此可解釋性層面。 數據清理、譜系、選取準則和處理是應追蹤決策的關鍵階段。
工具
應整合內容安全性和數據可追蹤性的工具,例如 Microsoft Purview。 您可以從測試呼叫 Azure AI 內容安全性 API,以利進行內容安全性測試。
Azure AI Studio 提供評估模型行為的計量。 如需詳細資訊,請參閱 產生式 AI 的評估和監視計量。
針對定型模型,建議您檢閱 Azure 機器學習 所提供的計量。
檢查傳入和傳出數據
提示插入式攻擊,例如越獄,是 AI 工作負載的共同考慮。 在此情況下,某些使用者可能會嘗試針對非預期用途誤用模型。 為了確保安全, 請檢查數據以防止攻擊並篩選掉不適當的內容。 此分析應同時套用至使用者的輸入和系統的回應,以確保傳入和傳出流程中有徹底的缺點 帳篷模式。
在進行多個模型調用的案例中,例如透過 Azure OpenAI 提供單一用戶端要求,將內容安全檢查套用至每個叫用的成本和不必要的案例中。 請考慮 將工作集中在架構中,同時將安全性保持為伺服器端責任。 假設架構在模型推斷端點前面有閘道,以卸除特定後端功能。 該閘道的設計目的是要處理後端可能原生不支援的要求和回應的內容安全性檢查。 雖然閘道是常見的解決方案,但協調流程層可以在更簡單的架構中有效地處理這些工作。 在這兩種情況下,您可以視需要選擇性地套用這些檢查,將效能和成本優化。
檢查應該是多模式,涵蓋各種格式。 使用多模式輸入,例如影像時,請務必分析它們是否有可能有害或暴力的隱藏訊息。 這些訊息可能不會立即顯示,類似於不可見的筆跡,而且需要仔細檢查。 基於此目的,請使用內容安全性 API 之類的工具。
若要強制執行隱私權和數據安全策略,請檢查用戶數據和地面數據,以符合隱私權法規。 請確定數據在流經系統時經過清理或篩選。 例如,來自先前客戶支援交談的數據可作為基礎數據。 應該在重複使用之前加以清理。
以道德方式處理用戶數據
道德做法涉及仔細處理用戶數據管理。 這包括知道何時使用數據,以及何時避免依賴用戶數據。
不共用用戶數據的推斷。 若要安全地與其他組織共用用戶數據以取得深入解析, 請使用清除機制模型。 在此案例中,組織會將數據提供給信任的第三方,以使用匯總的數據來定型模型。 然後,所有機構都可以使用此模型,讓共用的深入解析不公開個別數據集。 目標是使用模型的推斷功能,而不需共用詳細的定型數據。
促進多樣性和包容性。 需要用戶數據時,請使用各種不同的數據範圍,包括未代表的類型和建立者,以將偏差降到最低。 實作可鼓勵使用者探索新內容和不同內容的功能。 持續監視使用量並調整建議,以避免過度表示任何單一內容類型。
尊重“被遺忘的權利”。 盡可能避免使用用戶數據。 請確定已備妥必要措施,以確保用戶數據會刻意刪除,以確保符合「被遺忘的權利」。
為了確保合規性,可能會要求從系統移除用戶數據。 對於較小的模型,您可以透過重新定型排除個人信息的數據來達成此目的。 對於較大型的模型,其可包含數個較小的獨立定型模型,此程序比較複雜,而且成本與精力相當重要。 請尋求處理這些情況的法律和道德指引,並確定這包含在您的負責任 AI 原則中,如開發負責任 AI 原則中所述。
保留負責任。 如果無法刪除數據, 請取得明確的使用者同意數據收集 ,並提供明確的隱私策略。 只有在絕對必要時,才收集並保留數據。 有作業可在需要時積極移除數據。 例如,儘快清除聊天記錄,並在保留前匿名敏感數據。 請確定已針對待用數據使用進階加密方法。
支援可解釋性。 追蹤系統中的決策,以支援可解釋性需求。 開發建議演算法運作方式的清楚說明,讓使用者深入了解建議特定內容的原因。 目標是確保 AI 工作負載及其結果透明且合理,詳細說明決策的制定方式、使用的數據,以及模型定型方式。
加密用戶數據。 輸入數據必須在數據處理管線的每個階段加密,從使用者輸入數據的那一刻起。 這包括數據,因為它從一個點移動到另一個點,其中儲存,並在推斷期間,如有必要。 平衡安全性和功能,但目標是 在整個生命週期中保持數據私用。
如需加密技術的相關信息,請參閱 應用程式設計。
提供健全的訪問控制。 數種類型的身分識別可能會存取用戶數據。 針對控制平面和數據平面實作角色型 存取控制 (RBAC),涵蓋使用者和系統對系統通訊。
同時維護適當的使用者分割,以保護隱私權。 例如,適用於 Microsoft 365 的 Copilot 可以根據使用者的特定文件和電子郵件來搜尋並提供答案,確保只存取與該使用者相關的內容。
如需強制執行訪問控制的相關信息,請參閱 應用程式設計。
減少介面區。 架構完善的架構安全性支柱的基本策略是將受攻擊面和強化資源降到最低。 此策略應套用至標準端點安全性做法,方法是嚴格控制 API 端點、只公開基本數據,以及避免回應中多餘的資訊。 設計選擇應該在彈性與控制之間取得平衡。
請確定沒有任何匿名端點。 一般而言,請避免給予用戶端比必要更多的控制權。 在大部分情況下,用戶端不需要調整超參數,但在實驗環境中除外。 對於一般使用案例,例如與虛擬代理程式互動,客戶端應該只控制基本層面,藉由限制不必要的控制來確保安全性。
如需詳細資訊,請參閱 應用程式設計。