使用 Azure 機器學習 分析數據
本教學課程使用 Azure 機器學習 設計工具來建置預測性機器學習模型。 此模型是以儲存在 Azure Synapse 中的數據為基礎。 本教學課程的案例是預測客戶是否可能購買自行車,而 Adventure Works,自行車店可以建置目標行銷活動。
必要條件
若要逐步執行本教學課程,您需要:
- 預先載入 AdventureWorksDW 範例數據的 SQL 集區。 若要布建此 SQL 集區,請參閱 建立 SQL 集 區,然後選擇載入範例數據。 如果您已經有數據倉儲,但沒有範例數據,您可以 手動載入範例數據。
- Azure Machine Learning 工作區。 請遵循 本教學課程 來建立新的教學課程。
取得資料
所使用的數據位於 AdventureWorksDW 的 dbo.vTargetMail 檢視中。 若要在本教學課程中使用數據存放區,數據會先匯出至 Azure Data Lake Storage 帳戶,因為 Azure Synapse 目前不支持數據集。 Azure Data Factory 可用來使用 複製活動將數據從數據倉儲匯出至 Azure Data Lake Storage。 使用下列查詢進行匯入:
SELECT [CustomerKey]
,[GeographyKey]
,[CustomerAlternateKey]
,[MaritalStatus]
,[Gender]
,cast ([YearlyIncome] as int) as SalaryYear
,[TotalChildren]
,[NumberChildrenAtHome]
,[EnglishEducation]
,[EnglishOccupation]
,[HouseOwnerFlag]
,[NumberCarsOwned]
,[CommuteDistance]
,[Region]
,[Age]
,[BikeBuyer]
FROM [dbo].[vTargetMail]
在 Azure Data Lake Storage 中提供數據之後,Azure 機器學習 中的數據存放區會用來連線到 Azure 記憶體服務。 請遵循下列步驟來建立資料存放區和對應的數據集:
從 Azure 入口網站 啟動 Azure Machine Learning 工作室,或在 Azure Machine Learning 工作室 登入。
按兩下 [管理] 區段中左窗格中的數據存放區,然後按兩下[新增資料存放區]。
提供資料存放區的名稱、選取類型為 『Azure Blob 儲存體』、提供位置和認證。 接著按一下 [ 建立]。
接下來,按兩下 [資產] 區段中左窗格中的 [資料集]。 選取 [從數據存放區] 選項 [建立數據集]。
指定資料集的名稱,然後選取要為 表格式的類型。 然後,按 [下一步] 以繼續前進。
在 [選取或建立數據存放區] 區段中,選取 [先前建立的數據存放區] 選項。 選取稍早建立的數據存放區。 按 [下一步] 並指定路徑和檔案設定。 如果檔案包含數據行標頭,請務必指定數據行標頭。
最後,按兩下 [建立] 以建立資料集。
設定設計工具實驗
接下來,請依照下列步驟進行設計工具設定:
按兩下 [作者] 區段中左窗格的 [設計工具] 索引標籤。
選取 [容易使用的預先建置元件 ] 以建置新的管線。
在右側的 [設定] 窗格中,指定管線的名稱。
此外,在 [設定] 按鈕中,針對先前布建的叢集選取整個實驗的目標計算叢集。 關閉 [設定] 窗格。
匯入資料
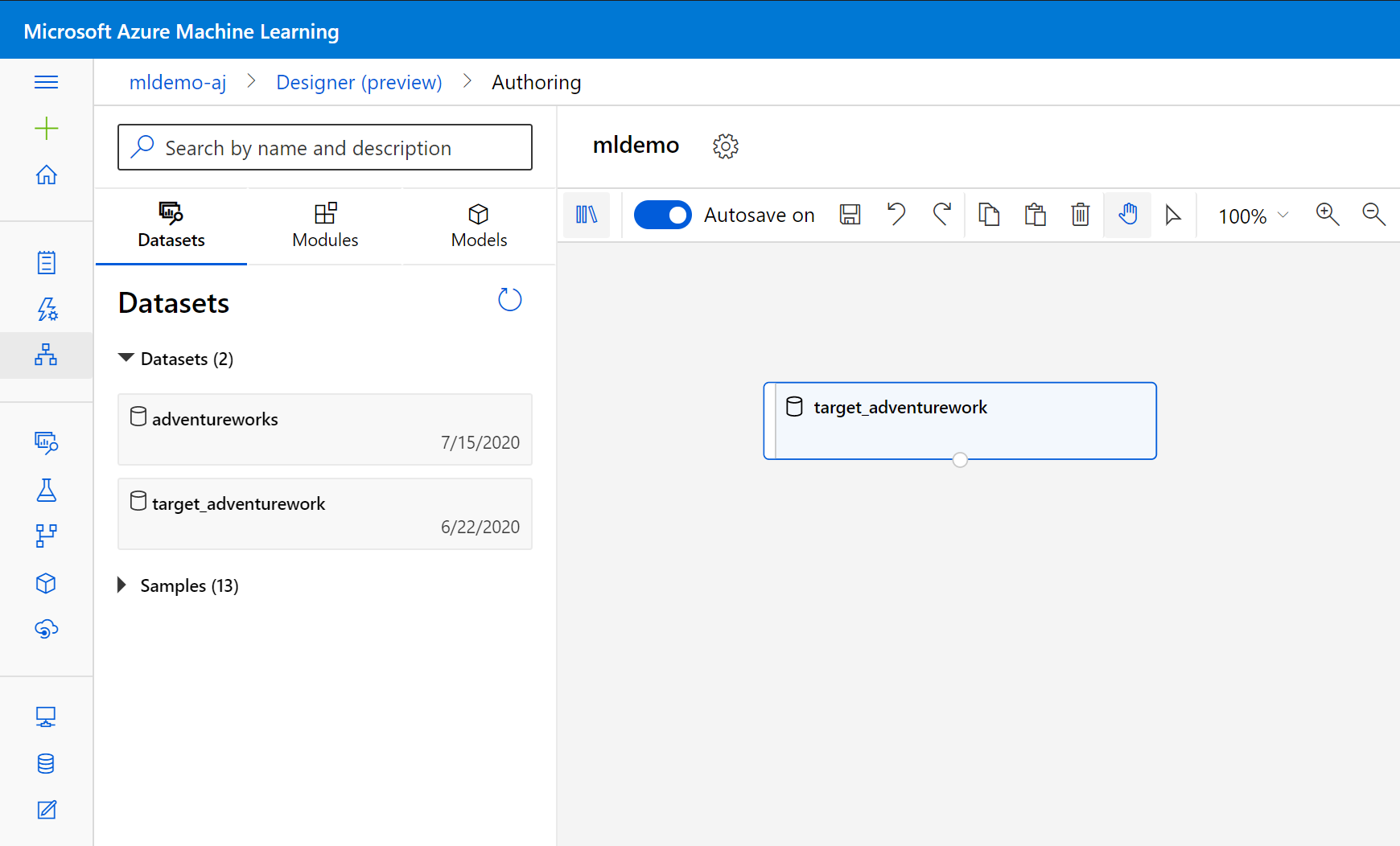
選取 搜尋方塊下方左窗格中的 [數據集 ] 子索引卷標。
將稍早建立的數據集拖曳至畫布。
清理資料
若要清除數據,請卸除與模型無關的數據行。 請執行以下步驟:
選取左窗格中的 [ 元件 ] 子索引卷標。
將 [資料轉換<操作] 底下的 [選取數據集中的數據行] 元件拖曳到畫布中。 將此元件連線至 數據集 元件。
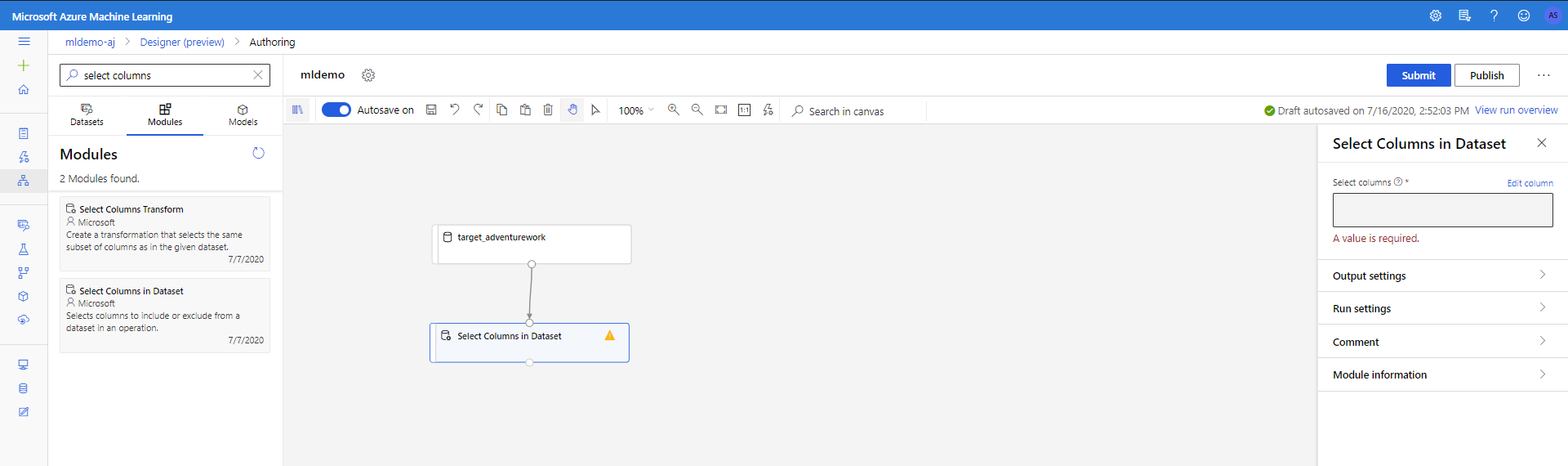
單擊元件以開啟 [屬性] 窗格。 按兩下 [編輯資料行] 以指定要卸除的數據行。
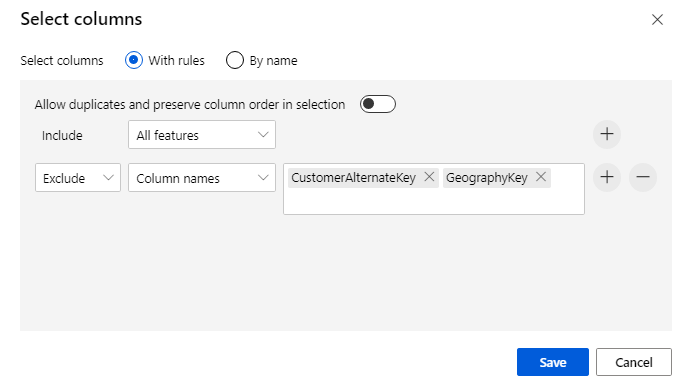
排除兩個數據行:CustomerAlternateKey 和 GeographyKey。 按下 [儲存]

建立模型
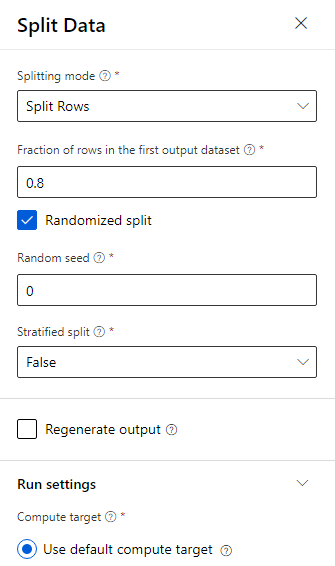
數據分割為 80-20:80% 來定型機器學習模型,20% 用來測試模型。 此二元分類問題會使用「雙類別」演算法。
將分割 數據 元件拖曳至畫布。
在 [屬性] 窗格中,針對 第一個輸出數據集中的數據列分數輸入 0.8。
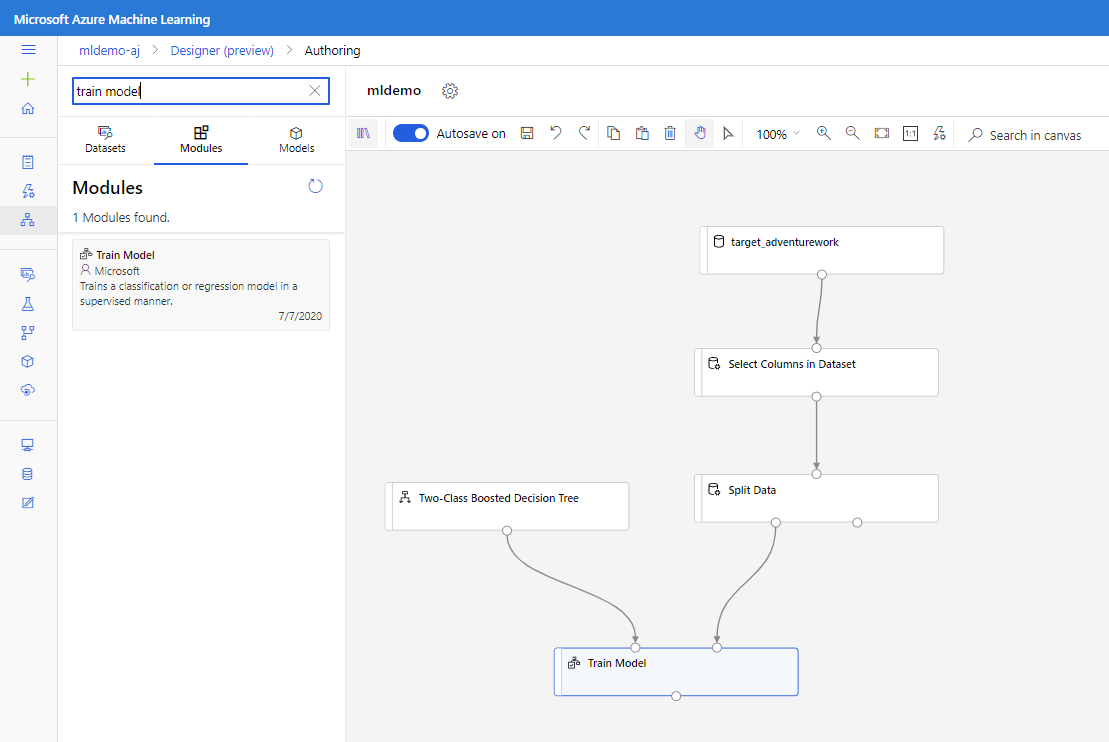
將 雙類別提升判定樹 元件拖曳到畫布中。
將 [ 定型模型] 元件拖曳至畫布。 將輸入 連接到雙類別提升判定樹 (ML 演算法)和 分割數據(用來 定型演算法的數據)元件來指定輸入。
針對 [定型模型模型],在 [屬性] 窗格中的 [卷標] 數據行 選項中,選取 [編輯數據行]。 選取 BikeBuyer 資料行作為要預測的數據行,然後選取 [ 儲存]。
![顯示已選取 [BikeBuyer] 標籤數據行的螢幕快照。](media/sql-data-warehouse-get-started-analyze-with-azure-machine-learning/label-column.png)
評分模型
現在,測試模型在測試數據上的執行方式。 將比較兩個不同的演算法,看看哪一個執行得更好。 請執行以下步驟:
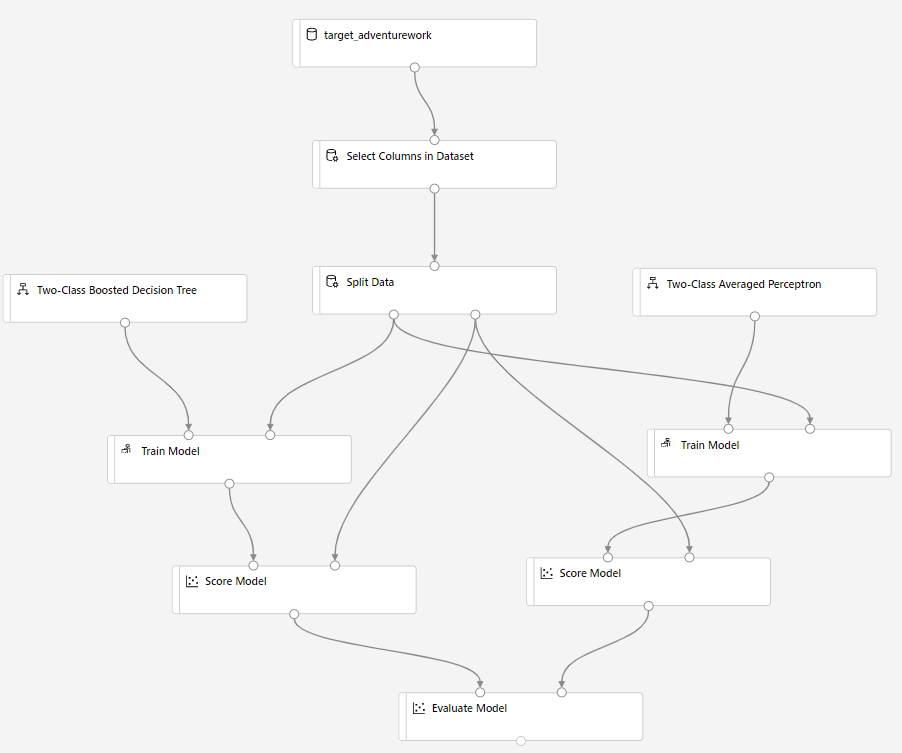
將評分模型元件拖曳至畫布,並將其聯機到定型模型和分割數據元件。
將 雙類別貝氏平均 Perceptron 拖曳到實驗畫布中。 您將比較此演算法與雙類別提升判定樹的效能。
在畫布中複製並貼上元件 定型模型 和 評分模型 。
將評估 模型 元件拖曳到畫布中,以比較這兩種演算法。
按兩下 [提交 ] 以設定管線執行。
執行完成後,以滑鼠右鍵按兩下 評估模型 元件,然後按兩下 [ 可視化評估結果]。
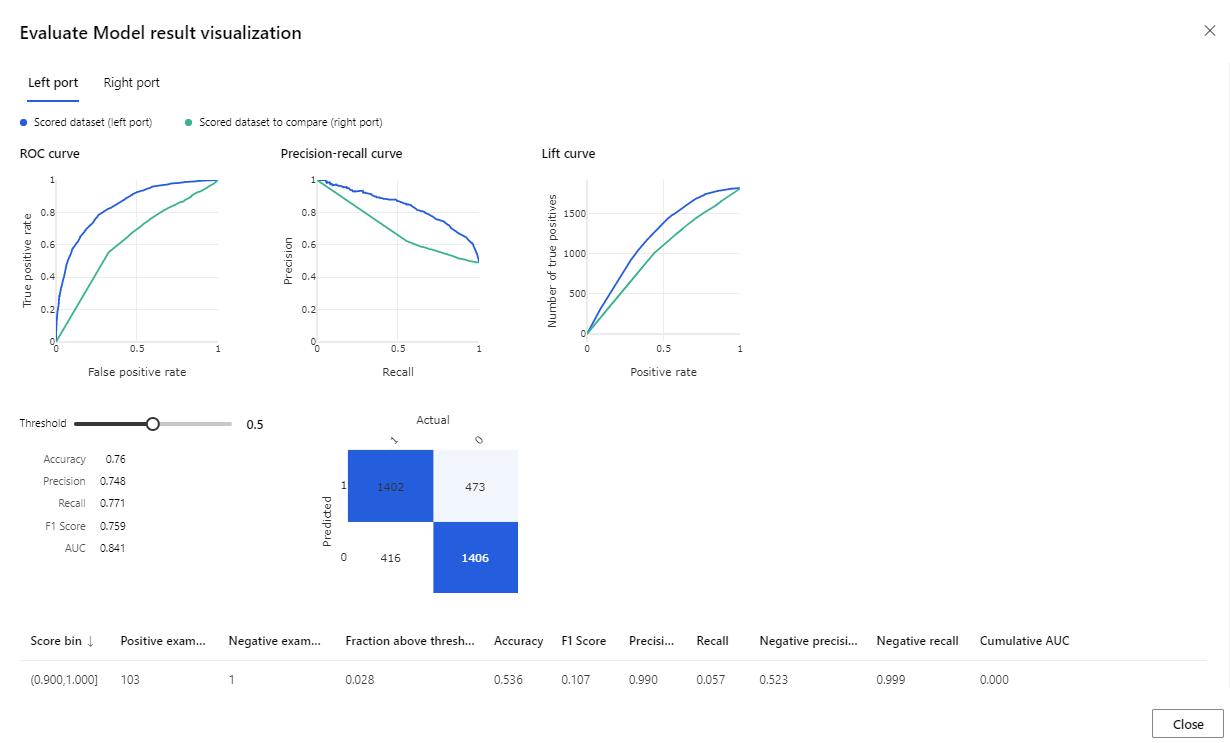

提供的計量是 ROC 曲線、精確度召回圖表和增益曲線。 查看這些計量,以查看第一個模型的執行效能優於第二個模型。 若要查看第一個模型預測的內容,請以滑鼠右鍵按兩下評分模型元件,然後按兩下 [可視化評分數據集] 以查看預測的結果。
您會看到另外兩個新增至測試數據集的數據行。
- 評分機率:客戶是自行車購買者的可能性。
- 評分標籤:模型完成的分類 – 自行車購買者 (1) 或不是 (0)。 卷標的這個機率臨界值設定為50%,而且可以調整。
比較 BikeBuyer 資料行 (actual) 與計分標籤 (預測),以查看模型的執行程度。 接下來,您可以使用此模型為新客戶進行預測。 您可以將 此模型發佈為 Web 服務 ,或將結果寫回 Azure Synapse。
下一步
若要深入瞭解 Azure 機器學習,請參閱 Azure 上的 機器學習 簡介。