在 Azure Synapse Analytics 中管理 Apache Spark 集區的程式庫
識別您想要針對 Spark 應用程式使用或更新的 Scala、Java、R(預覽)或 Python 套件之後,您就可以從 Spark 集區安裝或移除它們。 集區層級的程式庫可供集區上執行的所有筆記本和作業使用。
在 Spark 集區安裝程式庫有兩種主要方式:
- 安裝已上傳為工作區套件的工作區連結庫。
- 若要更新 Python 連結庫,請提供 requirements.txt 或 Conda environment.yml環境規格檔案,以從 PyPI 或 Conda-Forge 等存放庫安裝套件。 如需詳細資訊,請參閱 環境規格格式 一節。
儲存變更之後,Spark 作業會執行安裝,並快取產生的環境以供稍後重複使用。 作業完成後,新的 Spark 作業或筆記本會話會使用更新的集區連結庫。
重要
- 如果您要安裝的套件很大,或需要很長的時間才能安裝,Spark 實例啟動時間就會受到影響。
- 不支援變更 PySpark、Python、Scala/Java、.NET、R 或 Spark 版本。
- 在啟用數據外洩保護的工作區內,不支援從 PyPI、Conda-Forge 或預設 Conda 通道等外部存放庫安裝套件。
從 Synapse Studio 或 Azure 入口網站管理套件
您可以從 Synapse Studio 或 Azure 入口網站 管理 Spark 集區連結庫。
在 Azure 入口網站 中,流覽至您的 Azure Synapse Analytics 工作區。
從 [ 分析集區 ] 區段,選取 [Apache Spark 集 區] 索引卷標,然後從列表中選取 Spark 集區。
從 Spark 集區的 [設定] 區段中選取 [套件]。
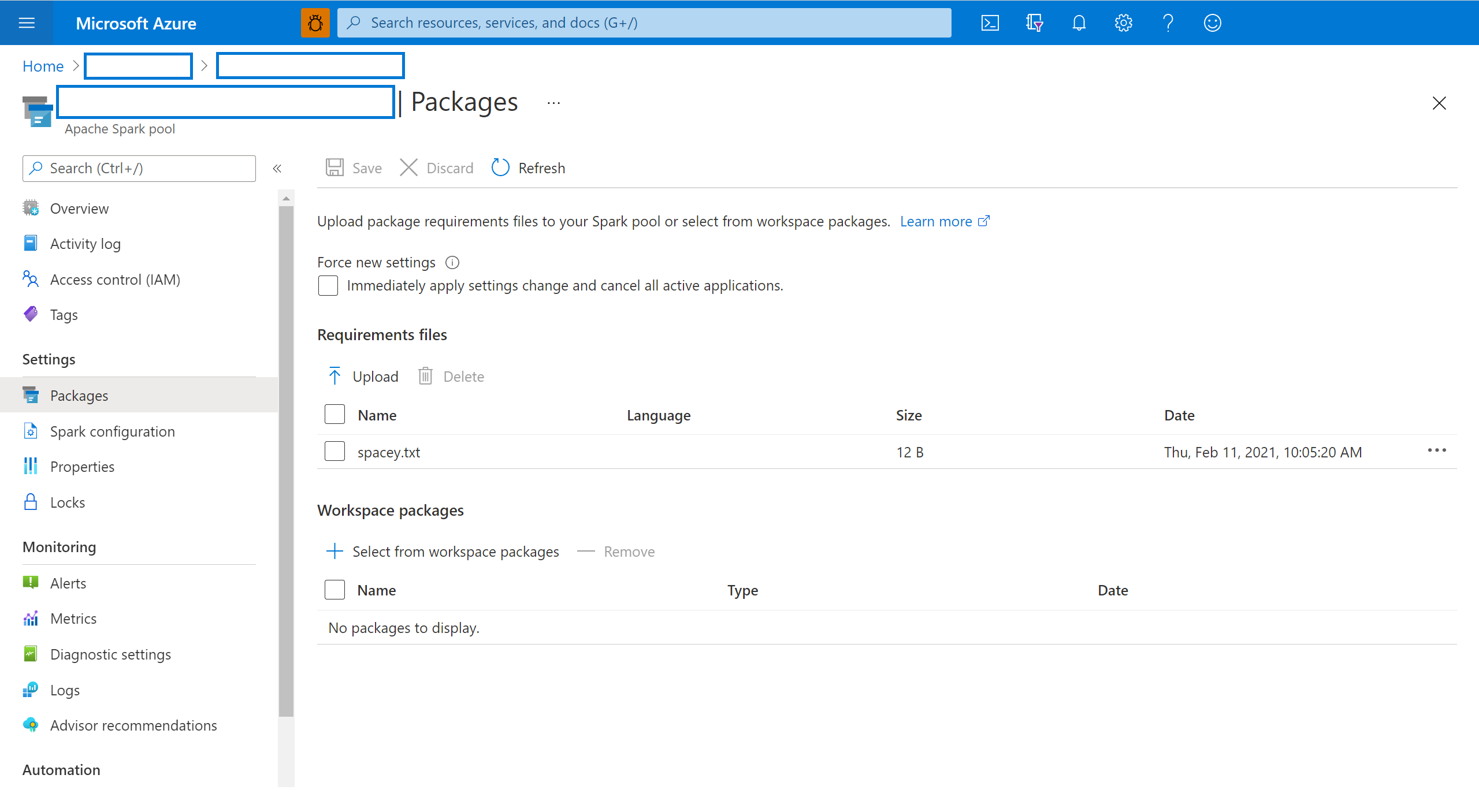
針對 Python 摘要程式庫,請在頁面的 [套件] 區段中,使用檔案選取器上傳環境設定檔。
您也可以選取其他工作區套件,將 Jar、Wheel 或 Tar.gz 檔案新增至集區中。
您也可以從 [工作區套件 ] 區段移除已取代的套件,然後您的集區就不會再附加這些套件。
儲存變更之後,系統會觸發系統作業來安裝及快取指定的連結庫。 此流程有助於縮短整體工作階段啟動時間。
作業成功完成之後,所有新的會話都會挑選更新的集區連結庫。


重要
選取 [ 強制新設定] 選項,即可結束所選 Spark 集區的所有目前會話。 會話結束後,您必須等候集區重新啟動。
如果未核取此設定,則您必須等候目前的Spark工作階段結束或手動停止。 會話結束後,您必須讓集區重新啟動。
追蹤安裝進度
每當集區更新為一組新的程式庫時,就會起始系統保留的 Spark 作業。 此 Spark 作業有助於監視程式庫安裝的狀態。 如果安裝因連結庫衝突或其他問題而失敗,Spark 集區會還原為先前或默認狀態。
此外,使用者可以檢查安裝記錄,以識別相依性衝突,或查看集區更新期間已安裝哪些連結庫。
若要檢視這些記錄:
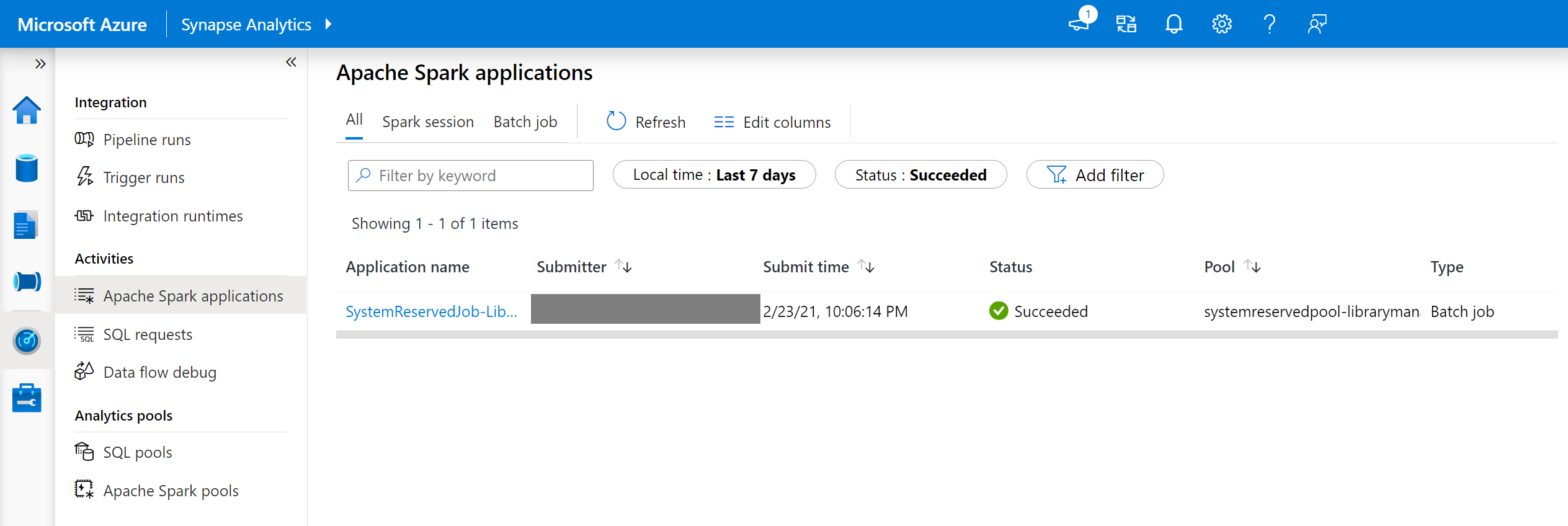
在 Synapse Studio 中,流覽至 [監視] 索引標籤中的 [Spark 應用程式] 列表。
選取對應至集區更新的系統 Spark 應用程式作業。 這些系統作業在 SystemReservedJob-LibraryManagement 標題下執行。
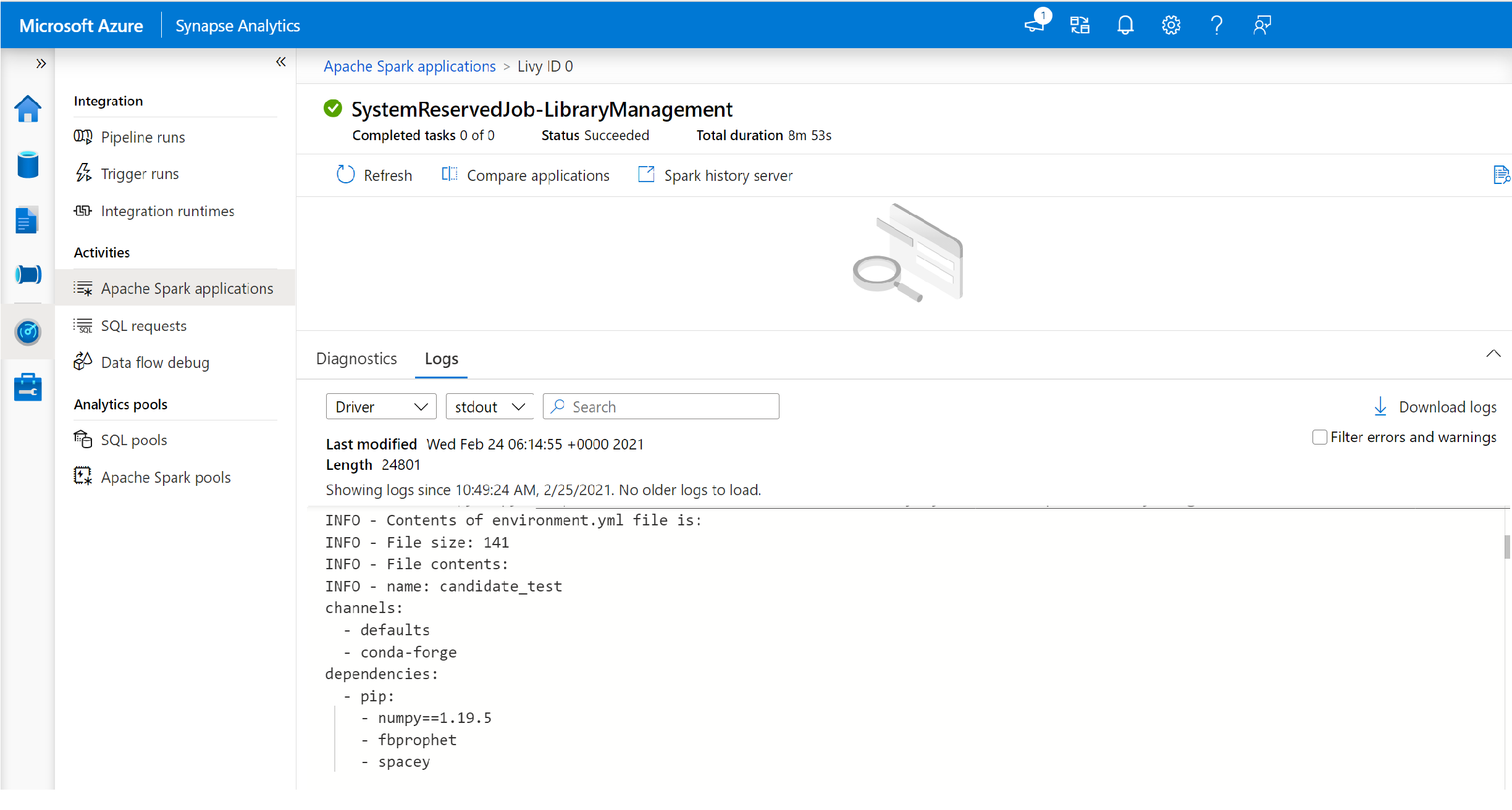
切換以檢視 [驅動程式] 和 [stdout] 記錄。
結果包含與安裝相依性相關的記錄。


環境規格格式
PIP requirements.txt
requirements.txt 檔案 (pip freeze 命令的輸出) 可用來升級環境。 更新集區時會從 PyPI 下載此檔案所列的封裝。 然後會快取並儲存完整的相依性,以供稍後重複使用集區。
下列程式碼片段顯示需求檔案的格式。 PyPI 封裝名稱連同確切版本一起列出。 此檔案遵循 pip freeze 參考文件所述的格式。
此範例鎖定特定版本。
absl-py==0.7.0
adal==1.2.1
alabaster==0.7.10
YML 格式
此外,您可以提供 environment.yml 檔案來更新集區環境。 此檔案所列的封裝是從預設的 Conda 通道、Conda-Forge 和 PyPI 下載。 您可以使用設定選項來指定其他通道或移除預設通道。
此範例指定通道和 Conda/PyPI 相依性。
name: stats2
channels:
- defaults
dependencies:
- bokeh
- numpy
- pip:
- matplotlib
- koalas==1.7.0
如需從這個 environment.yml 檔案建立環境的詳細資訊,請參閱 啟用環境。