教學課程:在 Synapse Studio 中建立 Apache Spark 作業定義
本教學課程示範如何使用 Synapse Studio 建立 Apache Spark 作業定義,然後將它們提交至無伺服器 Apache Spark 集區。
本教學課程涵蓋下列工作:
- 建立 PySpark 的 Apache Spark 作業定義 (Python)
- 建立 Spark 的 Apache Spark 作業定義 (Scala)
- 建立 .NET Spark 的 Apache Spark 作業定義 (C#/F#)
- 匯入 JSON 檔案以建立作業定義
- 將 Apache Spark 作業定義檔案匯出至本機
- 將 Apache Spark 作業定義提交為批次作業
- 將 Apache Spark 作業定義新增至管線
必要條件
開始本教學課程之前,請務必符合下列需求:
- Azure Synapse Analytics 工作區。 如需指示,請參閱 建立 Azure Synapse Analytics 工作區。
- 無伺服器 Apache Spark 集區。
- ADLS Gen2 儲存器帳戶。 您必須是 您想要使用之 ADLS Gen2 檔案系統的記憶體 Blob 資料參與者 。 如果您不是,則必須手動新增許可權。
- 如果您不想使用工作區預設記憶體,請在 Synapse Studio 中連結必要的 ADLS Gen2 記憶體帳戶。
建立 PySpark 的 Apache Spark 作業定義 (Python)
在本節中,您會為 PySpark (Python) 建立 Apache Spark 作業定義。
開啟 Synapse Studio。
您可以移至 建立 Apache Spark 作業定義的 範例檔案,下載 python.zip的範例檔案,然後解壓縮壓縮套件,並 解壓縮 wordcount.py 和 shakespeare.txt 檔案。
選取 [數據 - 連結 ->> Azure Data Lake Storage Gen2],然後將 wordcount.py 和shakespeare.txt上傳至您的 ADLS Gen2 文件系統。
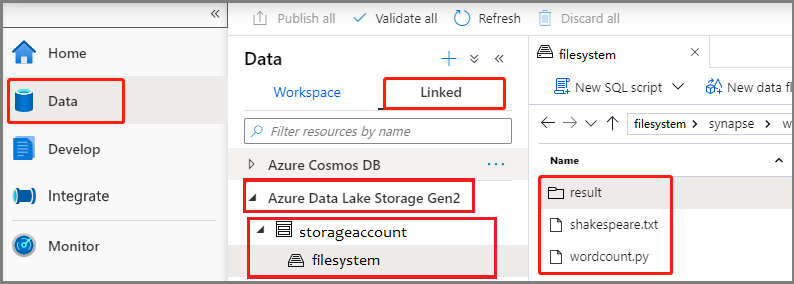
選取 [開發 中樞],選取 [+] 圖示,然後選取 [Spark 作業定義 ] 以建立新的 Spark 作業定義。
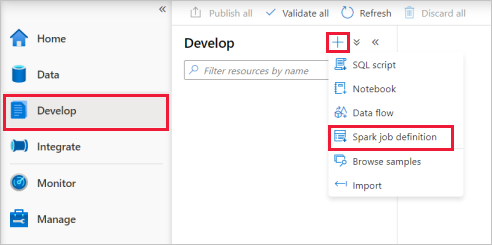
從 Apache Spark 作業定義主視窗中的 [語言] 下拉式列表中選取 PySpark (Python)。
填寫 Apache Spark 作業定義的資訊。
屬性 說明 工作定義名稱 輸入 Apache Spark 作業定義的名稱。 此名稱可以隨時更新,直到發佈為止。
範例:job definition sample主要定義檔 用於作業的主要檔案。 從您的記憶體中選取 PY 檔案。 您可以選取 [上傳檔案],以將檔案上傳至儲存體帳戶。
範例:abfss://…/path/to/wordcount.py命令列引數 作業的選擇性自變數。
樣本:abfss://…/path/to/shakespeare.txtabfss://…/path/to/result
注意:範例作業定義的兩個自變數會以空格分隔。參考檔案 主要定義檔中用來作為參考的其他檔案。 您可以選取 [上傳檔案],以將檔案上傳至儲存體帳戶。 Spark 集區 作業將會提交至選取的 Apache Spark 集區。 Spark 版本 Apache Spark 集區正在執行的 Apache Spark 版本。 執行程式 要提供給作業之指定 Apache Spark 集區中的執行程式數目。 執行程式大小 要用於作業指定 Apache Spark 集區中指定執行程式的核心和記憶體數目。 驅動程式大小 在指定 Apache Spark 集區中提供給作業使用的驅動程式所能使用的核心和記憶體數目。 Apache Spark 設定 藉由在下方新增屬性來自定義組態。 如果您未新增屬性,Azure Synapse 將會在適用時使用預設值。 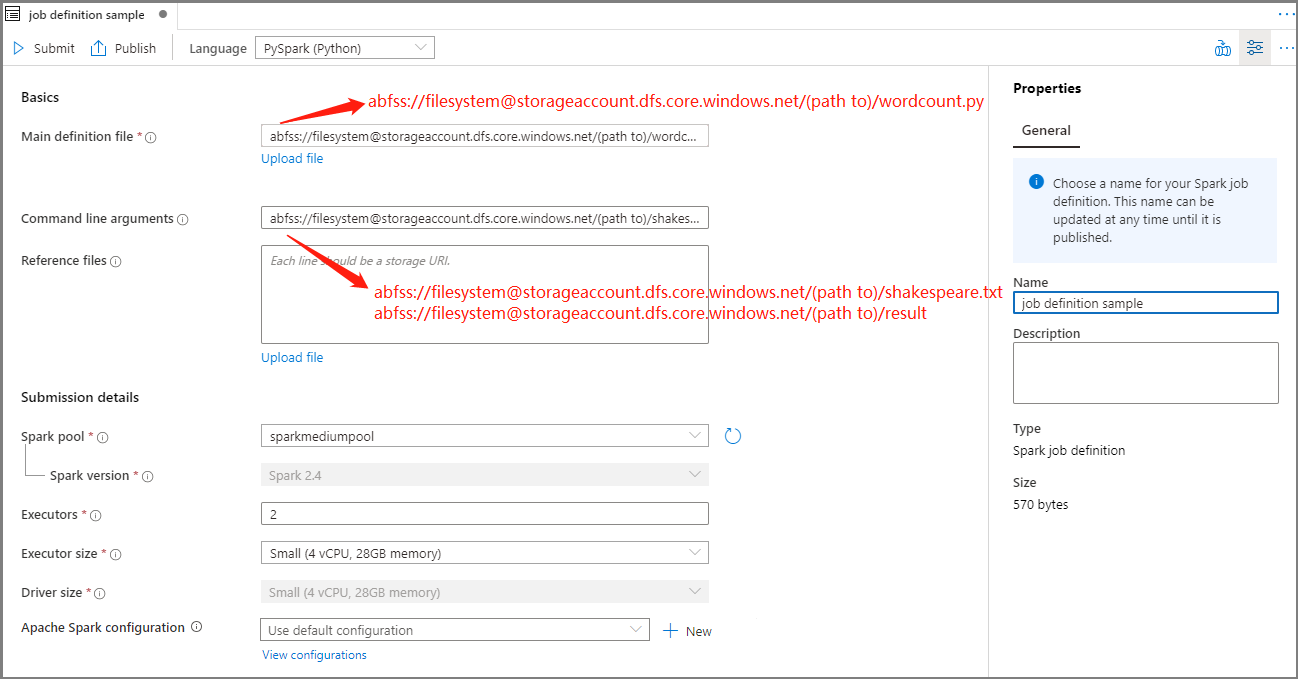
選取 [發佈 ] 以儲存 Apache Spark 作業定義。

建立 Apache Spark 的 Apache Spark 作業定義(Scala)
在本節中,您會為 Apache Spark(Scala) 建立 Apache Spark 作業定義。
您可以移至 建立 Apache Spark 作業定義的 範例檔案,下載 scala.zip的範例檔案,然後解壓縮壓縮套件,並解壓縮 wordcount.jar 和 shakespeare.txt 檔案。
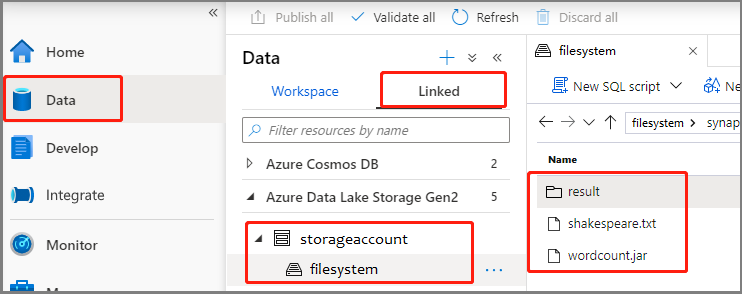
選取 [數據 - 連結 ->> Azure Data Lake Storage Gen2],然後將wordcount.jar和shakespeare.txt上傳至您的 ADLS Gen2 文件系統。
選取 [開發 中樞],選取 [+] 圖示,然後選取 [Spark 作業定義 ] 以建立新的 Spark 作業定義。 (範例影像與步驟 4 相同建立適用於 PySpark 的 Apache Spark 作業定義 (Python)。
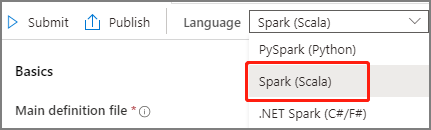
從 Apache Spark 作業定義主視窗中的 [語言] 下拉式清單中選取 Spark(Scala)。
填寫 Apache Spark 作業定義的資訊。 您可以複製範例資訊。
屬性 說明 工作定義名稱 輸入 Apache Spark 作業定義的名稱。 此名稱可以隨時更新,直到發佈為止。
範例:scala主要定義檔 用於作業的主要檔案。 從記憶體選取 JAR 檔案。 您可以選取 [上傳檔案],以將檔案上傳至儲存體帳戶。
範例:abfss://…/path/to/wordcount.jarMain class name (主要類別名稱) 主要定義檔中的完整識別碼或主要類別。
範例:WordCount命令列引數 作業的選擇性自變數。
樣本:abfss://…/path/to/shakespeare.txtabfss://…/path/to/result
注意:範例作業定義的兩個自變數會以空格分隔。參考檔案 主要定義檔中用來作為參考的其他檔案。 您可以選取 [上傳檔案],以將檔案上傳至儲存體帳戶。 Spark 集區 作業將會提交至選取的 Apache Spark 集區。 Spark 版本 Apache Spark 集區正在執行的 Apache Spark 版本。 執行程式 要提供給作業之指定 Apache Spark 集區中的執行程式數目。 執行程式大小 要用於作業指定 Apache Spark 集區中指定執行程式的核心和記憶體數目。 驅動程式大小 在指定 Apache Spark 集區中提供給作業使用的驅動程式所能使用的核心和記憶體數目。 Apache Spark 設定 藉由在下方新增屬性來自定義組態。 如果您未新增屬性,Azure Synapse 將會在適用時使用預設值。 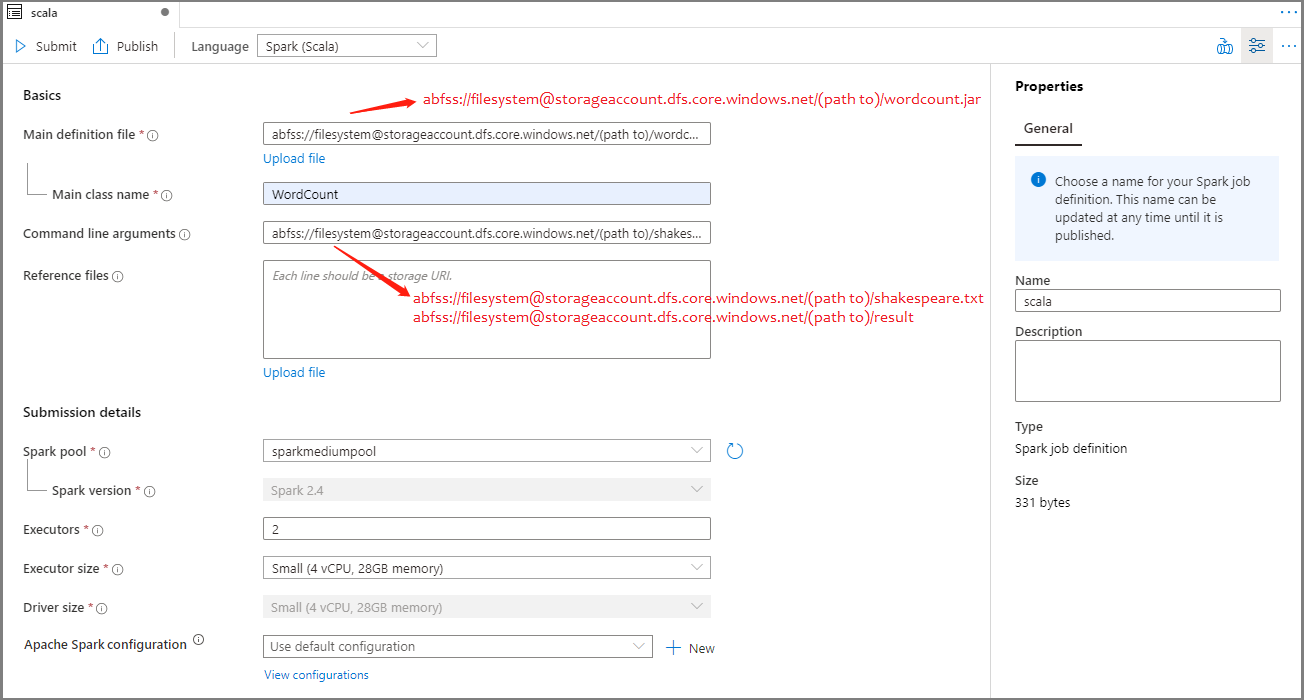
選取 [發佈 ] 以儲存 Apache Spark 作業定義。

建立 .NET Spark 的 Apache Spark 作業定義(C#/F#)
在本節中,您會為 .NET Spark(C#/F#) 建立 Apache Spark 作業定義。
您可以移至 建立 Apache Spark 作業定義的 範例檔案,下載 dotnet.zip的範例檔案,然後解壓縮壓縮套件,並 解壓縮wordcount.zip 和 shakespeare.txt 檔案。
選取 [數據 - 連結 ->> Azure Data Lake Storage Gen2],然後將wordcount.zip和shakespeare.txt上傳至您的 ADLS Gen2 文件系統。
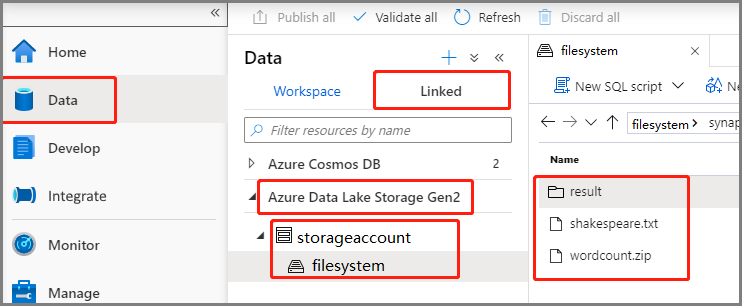
選取 [開發 中樞],選取 [+] 圖示,然後選取 [Spark 作業定義 ] 以建立新的 Spark 作業定義。 (範例影像與步驟 4 相同建立適用於 PySpark 的 Apache Spark 作業定義 (Python)。
從 Apache Spark 作業定義主視窗中的 [語言] 下拉式清單中選取 .NET Spark(C#/F# )。
填寫 Apache Spark 作業定義的資訊。 您可以複製範例資訊。
屬性 說明 工作定義名稱 輸入 Apache Spark 作業定義的名稱。 此名稱可以隨時更新,直到發佈為止。
範例:dotnet主要定義檔 用於作業的主要檔案。 從記憶體選取包含適用於 Apache Spark 應用程式的 .NET 的 ZIP 檔案(也就是主要可執行檔、包含使用者定義函式的 DLL 和其他必要檔案)。 您可以選取 [上傳檔案],以將檔案上傳至儲存體帳戶。
範例:abfss://…/path/to/wordcount.zip主要可執行檔 主要定義 ZIP 檔案中的主要可執行檔。
範例:WordCount命令列引數 作業的選擇性自變數。
樣本:abfss://…/path/to/shakespeare.txtabfss://…/path/to/result
注意:範例作業定義的兩個自變數會以空格分隔。參考檔案 背景工作節點執行未包含在主要定義 ZIP 檔案中的 .NET for Apache Spark 應用程式所需的其他檔案(也就是相依 jar、其他使用者定義函式 DLL 和其他組態檔)。 您可以選取 [上傳檔案],以將檔案上傳至儲存體帳戶。 Spark 集區 作業將會提交至選取的 Apache Spark 集區。 Spark 版本 Apache Spark 集區正在執行的 Apache Spark 版本。 執行程式 要提供給作業之指定 Apache Spark 集區中的執行程式數目。 執行程式大小 要用於作業指定 Apache Spark 集區中指定執行程式的核心和記憶體數目。 驅動程式大小 在指定 Apache Spark 集區中提供給作業使用的驅動程式所能使用的核心和記憶體數目。 Apache Spark 設定 藉由在下方新增屬性來自定義組態。 如果您未新增屬性,Azure Synapse 將會在適用時使用預設值。 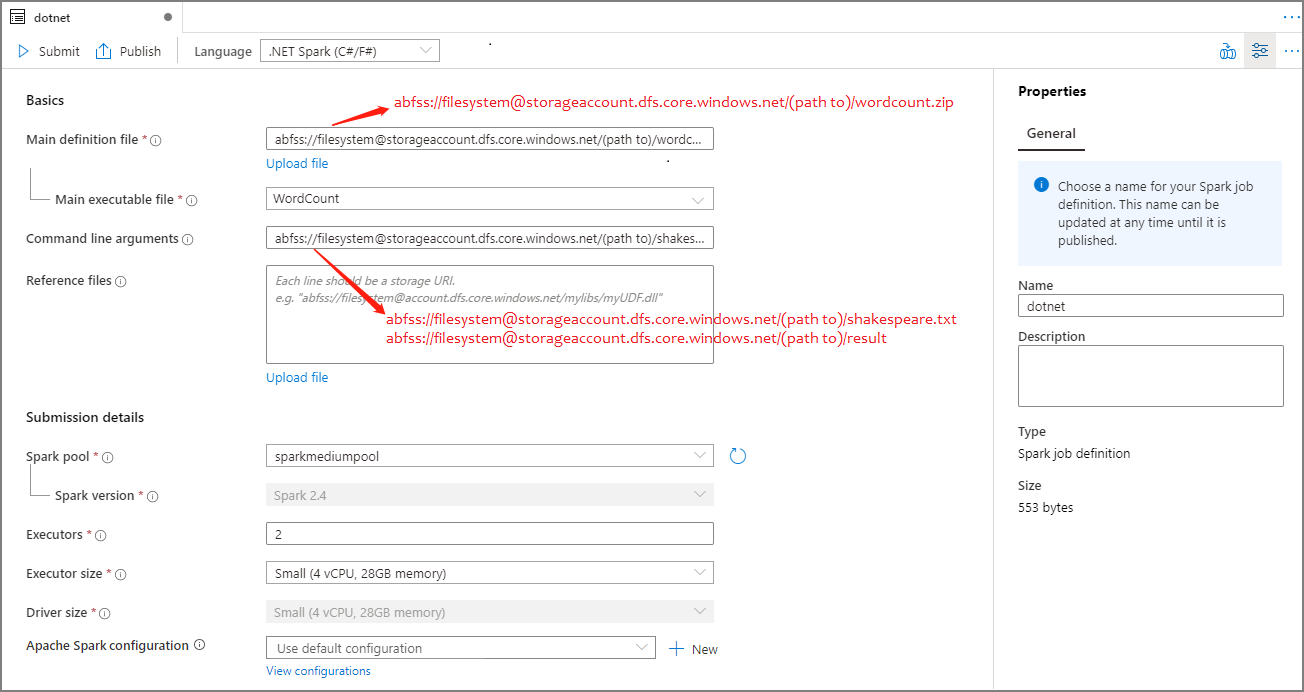
選取 [發佈 ] 以儲存 Apache Spark 作業定義。

注意
針對 Apache Spark 組態,如果 Apache Spark 設定 Apache Spark 作業定義未執行任何特殊動作,則執行作業時會使用預設組態。
匯入 JSON 檔案以建立 Apache Spark 作業定義
您可以從 Apache Spark 作業定義總管的 [動作] 功能表,將現有的本機 JSON 檔案匯入 Azure Synapse 工作區,以建立新的 Apache Spark 作業定義。
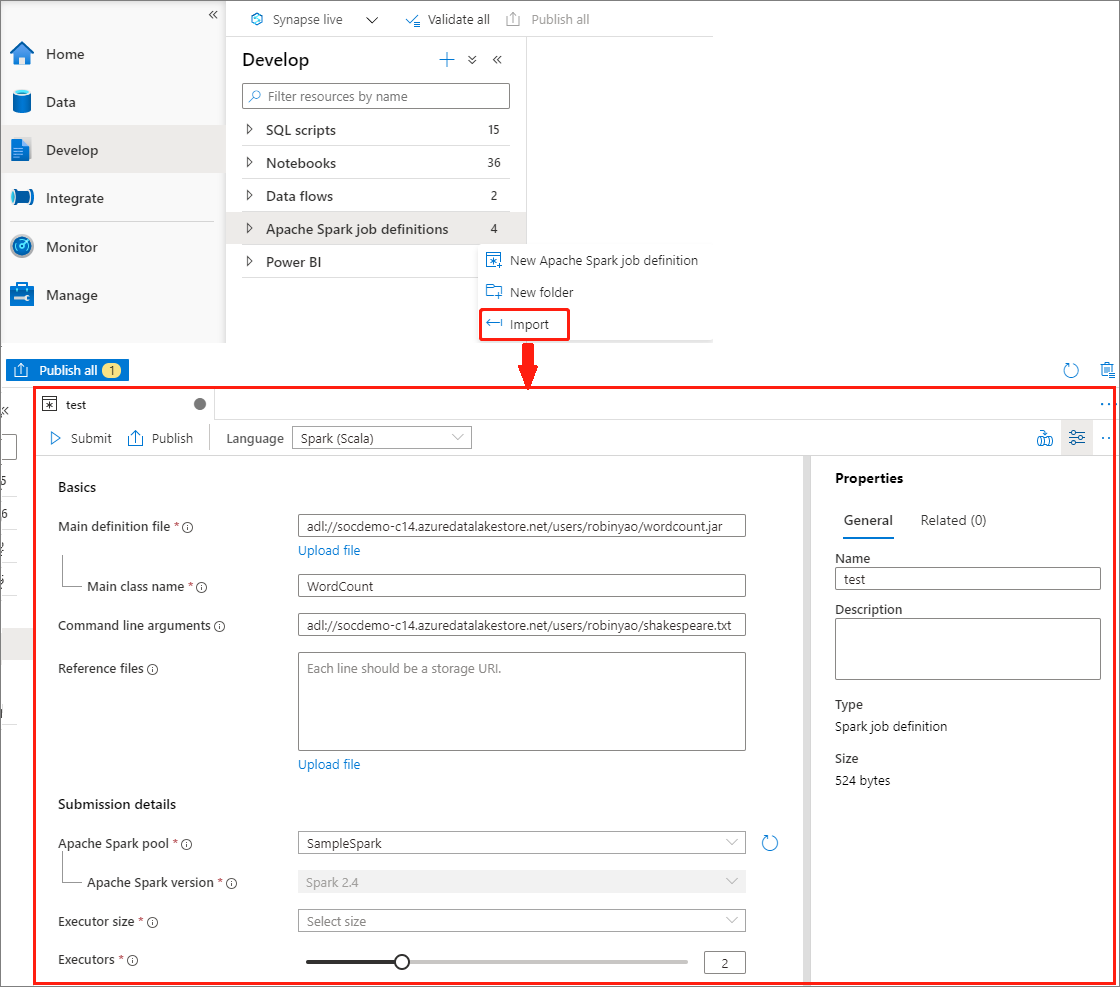
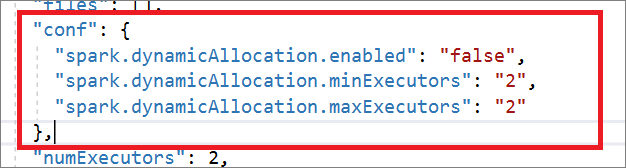
Spark 作業定義與 Livy API 完全相容。 您可以在本機 JSON 檔案中新增其他 Livy 屬性的其他參數 (Livy Docs - REST API (apache.org)。 您也可以在 config 屬性中指定 Spark 組態相關參數,如下所示。 然後,您可以將 JSON 檔案匯回,為您的批次作業建立新的 Apache Spark 作業定義。 Spark 定義匯入的範例 JSON:
{
"targetBigDataPool": {
"referenceName": "socdemolarge",
"type": "BigDataPoolReference"
},
"requiredSparkVersion": "2.3",
"language": "scala",
"jobProperties": {
"name": "robinSparkDefinitiontest",
"file": "adl://socdemo-c14.azuredatalakestore.net/users/robinyao/wordcount.jar",
"className": "WordCount",
"args": [
"adl://socdemo-c14.azuredatalakestore.net/users/robinyao/shakespeare.txt"
],
"jars": [],
"files": [],
"conf": {
"spark.dynamicAllocation.enabled": "false",
"spark.dynamicAllocation.minExecutors": "2",
"spark.dynamicAllocation.maxExecutors": "2"
},
"numExecutors": 2,
"executorCores": 8,
"executorMemory": "24g",
"driverCores": 8,
"driverMemory": "24g"
}
}
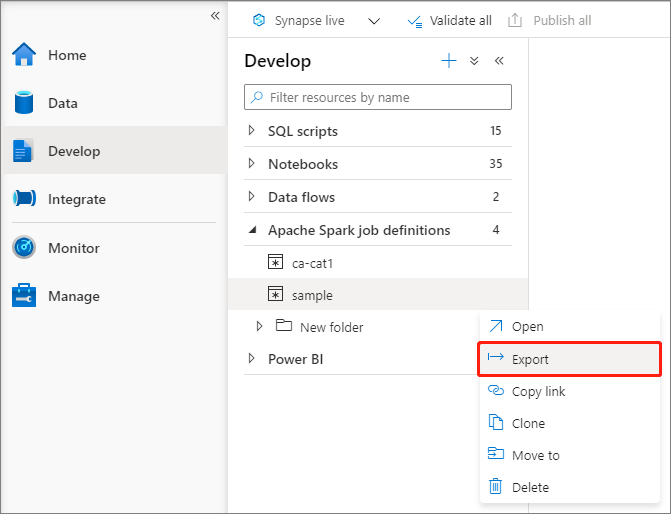
導出現有的 Apache Spark 作業定義檔
您可以從 檔案總管 的 [動作] 功能表,將現有的 Apache Spark 作業定義檔案匯出至本機。 您可以進一步更新 JSON 檔案以取得其他 Livy 屬性,並視需要將其匯回以建立新的作業定義。
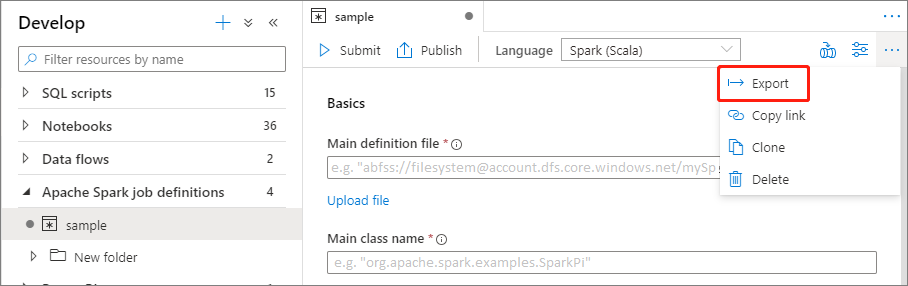
將 Apache Spark 作業定義提交為批次作業
建立 Apache Spark 作業定義之後,您可以將它提交至 Apache Spark 集區。 請確定您是 您想要使用之 ADLS Gen2 檔案系統的記憶體 Blob 資料參與者 。 如果您不是,則必須手動新增許可權。
案例 1:提交 Apache Spark 作業定義
選取 Apache spark 作業定義視窗,以開啟它。
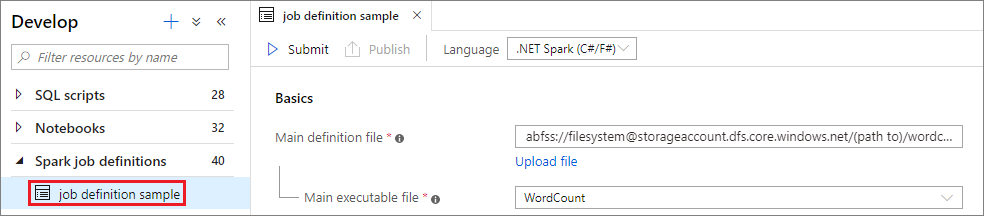
選取 [提交 ] 按鈕,將您的專案提交至選取的 Apache Spark 集區。 您可以選取 [Spark 監視 URL] 索引標籤,以查看 Apache Spark 應用程式的 LogQuery。
![選取 [提交] 按鈕以提交 Spark 作業定義](media/apache-spark-job-definitions/submit-spark-definition.png)
![[Spark 提交] 對話框](media/apache-spark-job-definitions/submit-definition-result.png)
案例 2:檢視 Apache Spark 作業執行進度
選取 [ 監視],然後選取 [Apache Spark 應用程式 ] 選項。 您可以找到提交的 Apache Spark 應用程式。
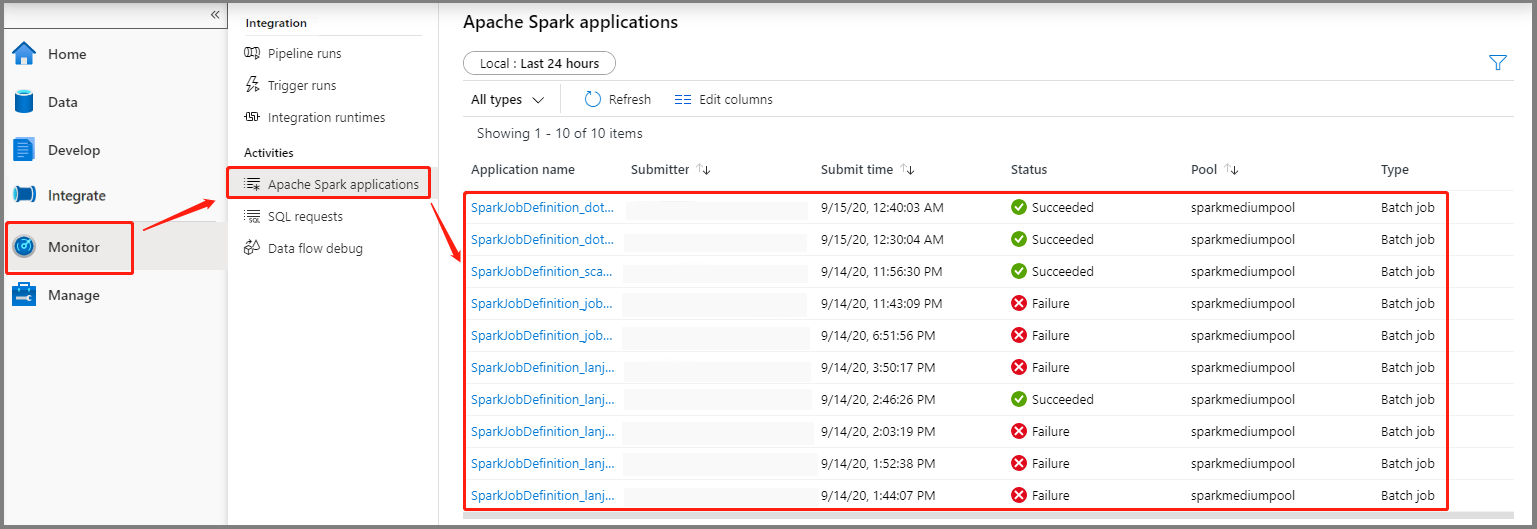
然後選取 Apache Spark 應用程式, SparkJobDefinition 作業視窗隨即顯示。 您可以從這裏檢視作業執行進度。
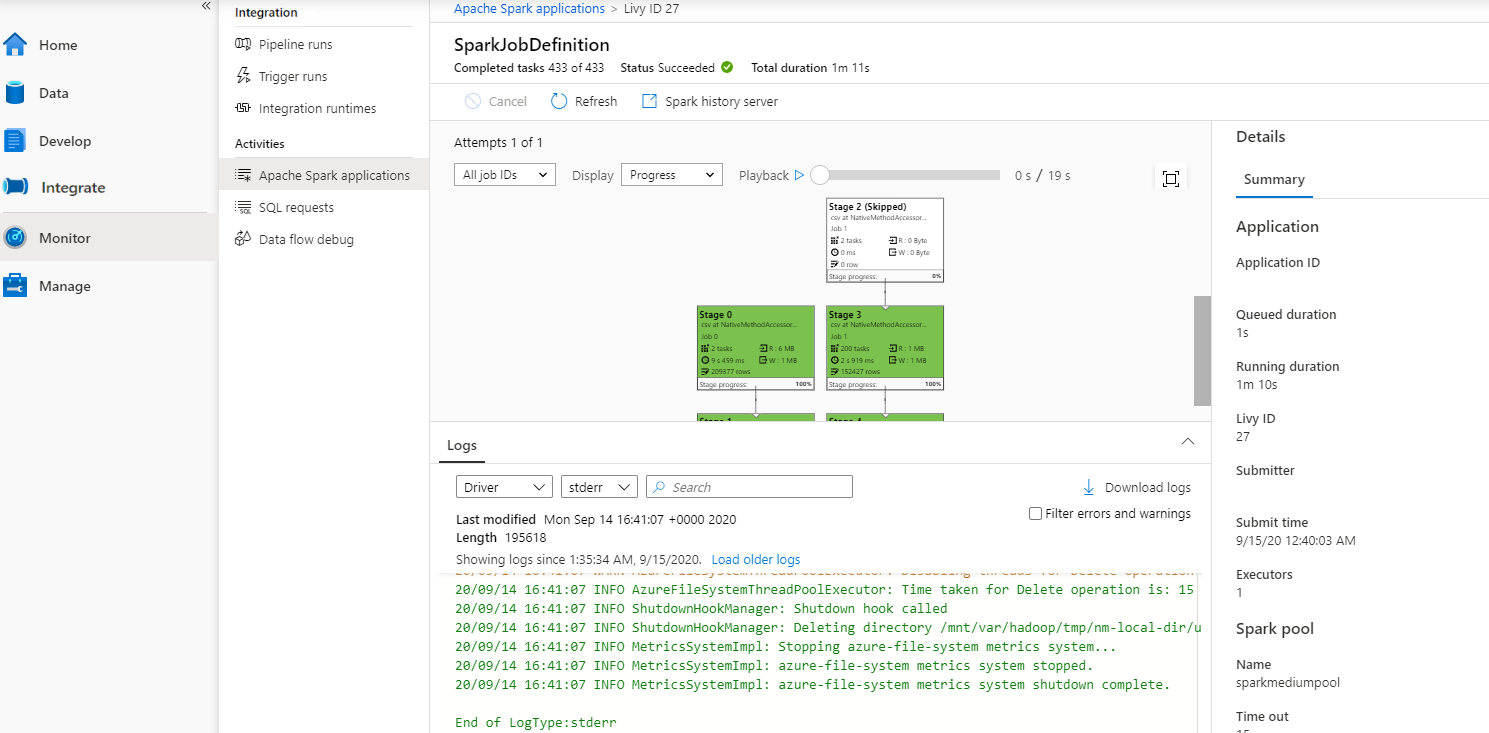
案例 3:檢查輸出檔案
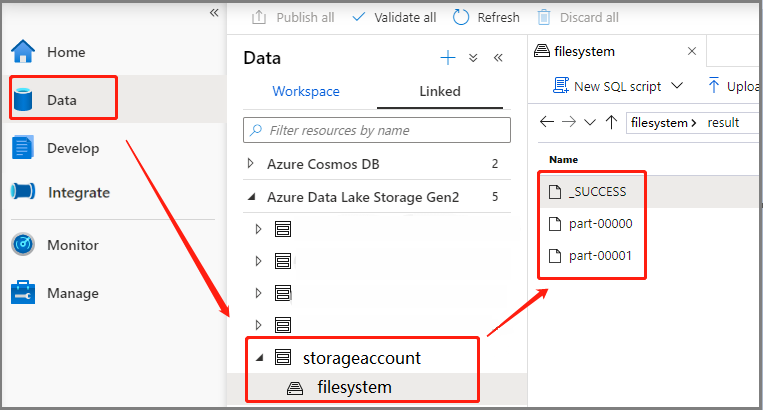
選取 [數據 - 連結 ->> Azure Data Lake Storage Gen2](hozhaobdbj),開啟稍早建立的結果資料夾,您可以移至結果資料夾,並檢查是否產生輸出。
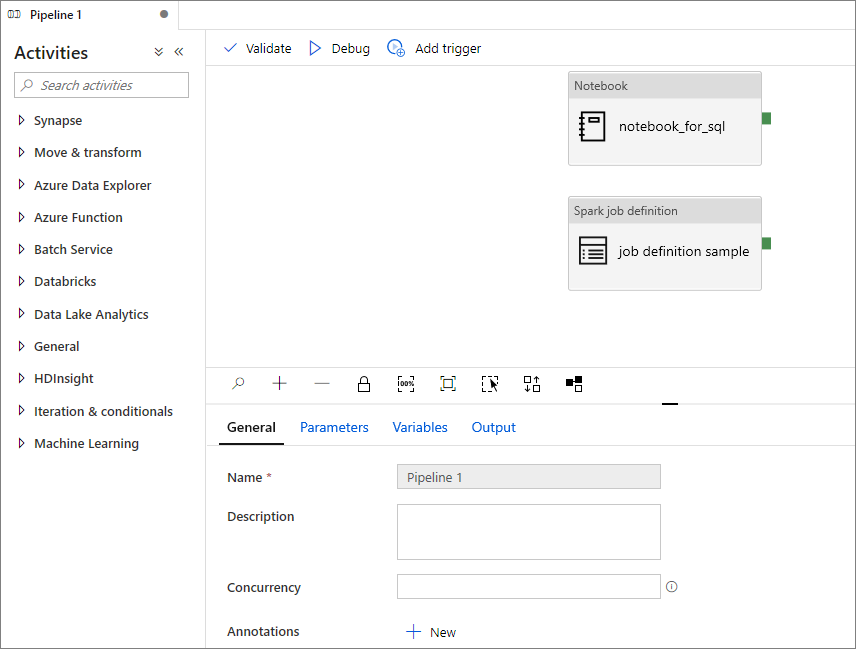
將 Apache Spark 作業定義新增至管線
在本節中,您會將 Apache Spark 作業定義新增至管線。
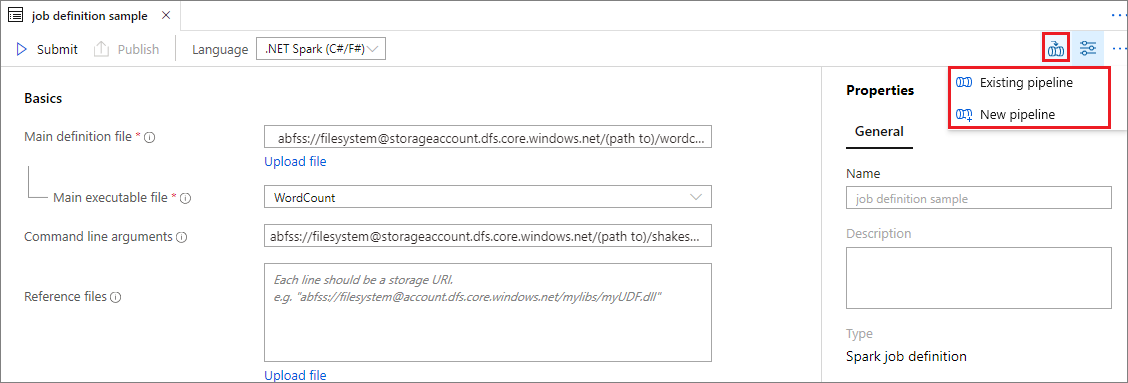
開啟現有的 Apache Spark 作業定義。
選取 Apache Spark 作業定義右上方的圖示,選擇 [現有管線] 或 [新增管線]。 如需詳細資訊,請參閱管線頁面。
下一步
接下來,您可以使用 Azure Synapse Studio 來建立 Power BI 數據集及管理 Power BI 數據。 前往將 Power BI工作區連結至 Synapse 工作區 一文,以深入瞭解。