開啟 Synapse Studio,移至左側的 [管理]> [連結服務],然後按一下 [新增] 來建立新的連結服務。
選擇 [適用於 MySQL 的 Azure 資料庫],按兩下 [繼續]。
提供連結服務的名稱。 記錄連結服務的名稱,這項資訊將用來不久設定 Spark。
從 Azure 訂用帳戶清單中選取外部 Hive 中繼存放區 適用於 MySQL 的 Azure 資料庫,或手動輸入資訊。
提供使用者名稱和密碼來設定連線。
測試連線來驗證使用者名稱和密碼。
按一下 [建立]來建立連結服務。
某些網路安全性規則設定可能會封鎖從 Spark 集區存取外部 Hive 中繼存放區 DB。 設定 Spark 集區之前,請在任何 Spark 集區筆記本中執行下列程式代碼,以測試外部 Hive 中繼存放區 DB 的連線。
您也可以從輸出結果取得Hive中繼存放區版本。 Hive 中繼存放區版本將會用於Spark組態中。
警告
請勿使用硬式編碼的密碼在筆記本中發佈測試腳本,因為這可能會對您的Hive中繼存放區造成潛在的安全性風險。
Azure SQL 的連線測試程序代碼
%%spark
import java.sql.DriverManager
/** this JDBC url could be copied from Azure portal > Azure SQL database > Connection strings > JDBC **/
val url = s"jdbc:sqlserver://{your_servername_here}.database.windows.net:1433;database={your_database_here};user={your_username_here};password={your_password_here};encrypt=true;trustServerCertificate=false;hostNameInCertificate=*.database.windows.net;loginTimeout=30;"
try {
val connection = DriverManager.getConnection(url)
val result = connection.createStatement().executeQuery("select t.SCHEMA_VERSION from VERSION t")
result.next();
println(s"Successful to test connection. Hive Metastore version is ${result.getString(1)}")
} catch {
case ex: Throwable => println(s"Failed to establish connection:\n $ex")
}
適用於 MySQL 的 Azure 資料庫的連接測試程序代碼
%%spark
import java.sql.DriverManager
/** this JDBC url could be copied from Azure portal > Azure Database for MySQL > Connection strings > JDBC **/
val url = s"jdbc:mysql://{your_servername_here}.mysql.database.azure.com:3306/{your_database_here}?useSSL=true"
try {
val connection = DriverManager.getConnection(url, "{your_username_here}", "{your_password_here}");
val result = connection.createStatement().executeQuery("select t.SCHEMA_VERSION from VERSION t")
result.next();
println(s"Successful to test connection. Hive Metastore version is ${result.getString(1)}")
} catch {
case ex: Throwable => println(s"Failed to establish connection:\n $ex")
}
成功建立連結服務至外部 Hive 中繼存放區之後,您必須設定一些 Spark 組態以使用外部 Hive 中繼存放區。 您可以設定 Spark 集區層級或 Spark 工作階段層級的設定。
以下是設定和描述:
注意
Synapse 的目標是使用 HDI 的計算順暢運作。 不過,HDI 4.0 中的 HMS 3.1 與 OSS HMS 3.1 不相容。 如需 OSS HMS 3.1,請查看 這裡。
| Spark 設定 |
描述 |
spark.sql.hive.metastore.version |
支援的版本: 確定您使用前 2 個部分,而不使用第 3 個部分 |
spark.sql.hive.metastore.jars |
- 版本 2.3:
/opt/hive-metastore/lib-2.3/*:/usr/hdp/current/hadoop-client/lib/*:/usr/hdp/current/hadoop-client/* - 3.1 版:
/opt/hive-metastore/lib-3.1/*:/usr/hdp/current/hadoop-client/lib/*:/usr/hdp/current/hadoop-client/*
|
spark.hadoop.hive.synapse.externalmetastore.linkedservice.name |
連結服務的名稱 |
spark.sql.hive.metastore.sharedPrefixes |
com.mysql.jdbc,com.microsoft.vegas |
建立 Spark 集區時,請在 [其他設定] 索引標籤下,將以下設定放在文字檔案中,並在 [Apache Spark 設定] 區段中上傳該文字檔案。 您也可以使用現有 Spark 集區的捷徑功能表,選擇 Apache Spark 設定來新增這些設定。
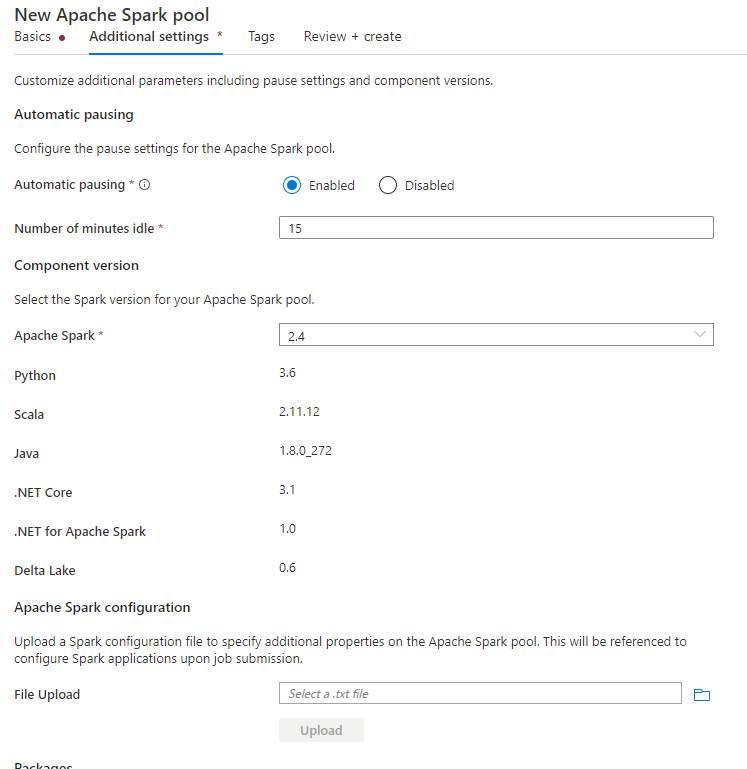
更新中繼存放區版本和連結服務名稱,並將以下設定儲存在 Spark 集區設定的文字檔案中:
spark.sql.hive.metastore.version <your hms version, Make sure you use the first 2 parts without the 3rd part>
spark.hadoop.hive.synapse.externalmetastore.linkedservice.name <your linked service name>
spark.sql.hive.metastore.jars /opt/hive-metastore/lib-<your hms version, 2 parts>/*:/usr/hdp/current/hadoop-client/lib/*
spark.sql.hive.metastore.sharedPrefixes com.mysql.jdbc,com.microsoft.vegas
以下是中繼存放區 2.3 版的範例,其中包含名為 HiveCatalog21 的鏈接服務:
spark.sql.hive.metastore.version 2.3
spark.hadoop.hive.synapse.externalmetastore.linkedservice.name HiveCatalog21
spark.sql.hive.metastore.jars /opt/hive-metastore/lib-2.3/*:/usr/hdp/current/hadoop-client/lib/*
spark.sql.hive.metastore.sharedPrefixes com.mysql.jdbc,com.microsoft.vegas
針對筆記本會話,您也可以使用 %%configure magic 命令在筆記本中設定 Spark 工作階段。 此程式碼如下。
%%configure -f
{
"conf":{
"spark.sql.hive.metastore.version":"<your hms version, 2 parts>",
"spark.hadoop.hive.synapse.externalmetastore.linkedservice.name":"<your linked service name>",
"spark.sql.hive.metastore.jars":"/opt/hive-metastore/lib-<your hms version, 2 parts>/*:/usr/hdp/current/hadoop-client/lib/*",
"spark.sql.hive.metastore.sharedPrefixes":"com.mysql.jdbc,com.microsoft.vegas"
}
}
針對批次作業,也可以透過 SparkConf套用相同的組態。
執行查詢來驗證連線
在所有這些設定之後,請嘗試在 Spark 筆記本中執行以下查詢來列出目錄物件,以檢查外部 Hive 中繼存放區的連線能力。
spark.sql("show databases").show()
設定儲存體連線
Hive 中繼存放區資料庫的連結服務只會提供Hive目錄元數據的存取權。 若要查詢現有的資料表,您必須設定儲存體帳戶的連線,此儲存體帳戶也會儲存 Hive 資料表的基礎資料。
設定 Azure Data Lake Storage Gen 2 的連線
工作區主要儲存體帳戶
如果Hive數據表的基礎資料儲存在工作區主要記憶體帳戶中,則不需要執行額外的設定。 只要您在建立工作區期間遵循記憶體設定指示即可運作。
其他 ADLS Gen 2 帳戶
如果 Hive 目錄的基礎資料儲存在另一個 ADLS Gen 2 帳戶中,您必須確定執行 Spark 查詢的使用者在 ADLS Gen2 儲存體帳戶上擁有儲存體 Blob 資料參與者角色。
設定到 Blob 儲存體的連接
如果 Hive 資料表的基礎資料儲存在 Azure Blob 儲存體帳戶中,請遵循下列步驟設定連線:
開啟 Synapse Studio,移至 [資料] > [連結] 索引標籤 > [新增] 按鈕 > [連線至外部資料表]。
![[連線到記憶體帳戶] 的螢幕快照。](media/use-external-metastore/connect-to-storage-account.png)
選擇 [Azure Blob 儲存體],然後選取 [繼續]。
提供連結服務的名稱。 記錄連結服務的名稱,這項資訊將會在Spark組態中不久使用。
選取 Azure Blob 儲存體帳戶。 確定驗證方法是 [帳戶金鑰]。 目前 Spark 集區只能透過帳戶金鑰存取 Blob 儲存體帳戶。
測試連線 ,然後選取 [ 建立]。
在建立 Blob 儲存體帳戶的連結服務之後,當您執行 Spark 查詢時,請務必在筆記本中執行下列 Spark 程式碼,為 Spark 工作階段取得 Blob 儲存體帳戶的存取權。 在這裡深入了解您為何需要這麼做。
%%pyspark
blob_account_name = "<your blob storage account name>"
blob_container_name = "<your container name>"
from pyspark.sql import SparkSession
sc = SparkSession.builder.getOrCreate()
token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary
blob_sas_token = token_library.getConnectionString("<blob storage linked service name>")
spark.conf.set('fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name), blob_sas_token)
在設定儲存體連線之後,您可以查詢 Hive 中繼存放區中的現有資料表。
已知的限制
- Synapse Studio 物件總管將繼續在 Managed Synapse 中繼存放區中顯示物件,而不是外部 HMS。
-
SQL <-> 使用外部 HMS 時,Spark 同步 處理無法運作。
- 只有 Azure SQL 資料庫 和 適用於 MySQL 的 Azure 資料庫 支援作為外部 Hive 中繼存放區資料庫。 僅支援 SQL 授權。
- 目前 Spark 僅適用於外部 Hive 數據表和非交易式/非 ACID 受控 Hive 數據表。 其不支援 Hive ACID/交易式資料表。
- 不支援 Apache Ranger 整合。
疑難排解
使用 Blob 儲存體中儲存的資料查詢 Hive 資料表時,請參閱下列錯誤
No credentials found for account xxxxx.blob.core.windows.net in the configuration, and its container xxxxx is not accessible using anonymous credentials. Please check if the container exists first. If it is not publicly available, you have to provide account credentials.
透過連結服務對記憶體帳戶使用密鑰驗證時,您必須採取額外步驟來取得 Spark 會話的令牌。 在執行查詢之前,請執行以下程式碼來設定您的 Spark 工作階段。 在這裡深入了解您為何需要這麼做。
%%pyspark
blob_account_name = "<your blob storage account name>"
blob_container_name = "<your container name>"
from pyspark.sql import SparkSession
sc = SparkSession.builder.getOrCreate()
token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary
blob_sas_token = token_library.getConnectionString("<blob storage linked service name>")
spark.conf.set('fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name), blob_sas_token)
查詢 ADLS Gen2 帳戶中儲存的資料表時,請參閱以下錯誤
Operation failed: "This request is not authorized to perform this operation using this permission.", 403, HEAD
發生這種情況的原因是執行 Spark 查詢的使用者沒有足夠的權限來存取基礎儲存體帳戶。 請確定執行 Spark 查詢的使用者在 ADLS Gen2 儲存器帳戶上具有 記憶體 Blob 資料參與者 角色。 建立連結服務之後,即可完成此步驟。
若要避免變更 HMS 後端架構/版本,系統預設會設定下列 Hive 組態:
spark.hadoop.hive.metastore.schema.verification true
spark.hadoop.hive.metastore.schema.verification.record.version false
spark.hadoop.datanucleus.fixedDatastore true
spark.hadoop.datanucleus.schema.autoCreateAll false
如果您的 HMS 版本為 1.2.1 或 1.2.2,則 Hive 中只有 1.2.0 當您轉向 spark.hadoop.hive.metastore.schema.verificationtrue時才需要的問題。 我們的建議是您可以將 HMS 版本修改為 1.2.0,或覆寫下列兩個設定來解決此問題:
spark.hadoop.hive.metastore.schema.verification false
spark.hadoop.hive.synapse.externalmetastore.schema.usedefault false
如果您需要移轉 HMS 版本,建議使用 Hive 結構描述工具。 然後,如果 HDInsight 叢集已使用 HMS,我們建議使用 HDI 提供的版本。
OSS HMS 3.1 的 HMS 架構變更
Synapse 的目標是使用 HDI 的計算順暢運作。 不過,HDI 4.0 中的 HMS 3.1 與 OSS HMS 3.1 不相容。 如果 HDI 未佈建 HMS 3.1,請手動套用下列內容。
-- HIVE-19416
ALTER TABLE TBLS ADD WRITE_ID bigint NOT NULL DEFAULT(0);
ALTER TABLE PARTITIONS ADD WRITE_ID bigint NOT NULL DEFAULT(0);
如果您想要與 HDInsight 4.0 中的 Spark 叢集共用 Hive 目錄,請確定您在 Synapse Spark 中的屬性 spark.hadoop.metastore.catalog.default 與 HDInsight Spark 中的值一致。 HDI Spark 的預設值為 spark,而 Synapse Spark 的預設值為 hive。
如限制中所述,Synapse Spark 集區僅支援外部 Hive 數據表和非交易式/ACID 受控數據表,目前不支援 Hive ACID/交易數據表。 在 HDInsight 4.0 Hive 叢集中,所有受控數據表預設都會建立為 ACID/交易式數據表,這就是為什麼您在查詢這些數據表時取得空的結果。
java.lang.ClassNotFoundException: Class com.microsoft.vegas.vfs.SecureVegasFileSystem not found
您可以藉由附加 /usr/hdp/current/hadoop-client/* 至 , spark.sql.hive.metastore.jars輕鬆地修正此問題。
Eg:
spark.sql.hive.metastore.jars":"/opt/hive-metastore/lib-2.3/*:/usr/hdp/current/hadoop-client/lib/*:/usr/hdp/current/hadoop-client/*