快速入門:使用對應數據流轉換數據
在本快速入門中,您將使用 Azure Synapse Analytics 建立管線,以使用對應數據流,將數據從 Azure Data Lake Storage Gen2 (ADLS Gen2) 來源轉換成 ADLS Gen2 接收。 本快速入門中的設定模式可以在使用對應數據流轉換數據時加以擴充
在本快速入門中,您會執行下列步驟:
- 在 Azure Synapse Analytics 中使用數據流活動建立管線。
- 建置具有四個轉換的對應資料流。
- 對管線執行測試。
- 監視資料流程活動
必要條件
Azure 訂用帳戶:如果您沒有 Azure 訂用帳戶,請在開始前先建立免費 Azure 帳戶。
Azure Synapse 工作區:使用 Azure 入口網站 建立 Synapse 工作區,遵循快速入門:建立 Synapse 工作區中的指示。
Azure 記憶體帳戶:您可以使用 ADLS 記憶體作為 來源 和 接收 資料存放區。 如果您沒有儲存體帳戶,請參閱建立 Azure 儲存體帳戶,按照步驟建立此帳戶。
我們在本教學課程中轉換的檔案是 MoviesDB.csv,可在這裡找到。 若要從 GitHub 擷取檔案,請將內容複寫到您選擇的文字編輯器,以 .csv 檔案的形式儲存在本機。 若要將檔案上傳到儲存體帳戶,請參閱使用 Azure 入口網站上傳 Blob。 這些範例會參考名為 'sample-data' 的容器。
流覽至 Synapse Studio
建立 Azure Synapse 工作區之後,有兩種方式可以開啟 Synapse Studio:
- 在 Azure 入口網站中開啟 Synapse 工作區。 在 [開始使用] 底下的 [開啟 Synapse Studio] 卡片上選取 [開啟]。
- 開啟 Azure Synapse Analytics 並登入您的工作區。
在本快速入門中,我們使用名為 「adftest2020」 的工作區作為範例。 它會自動巡覽至 Synapse Studio 首頁。
建立包含資料流程活動的管線
管線包含一組活動的執行邏輯流程。 在本節中,您將建立包含數據流活動的管線。
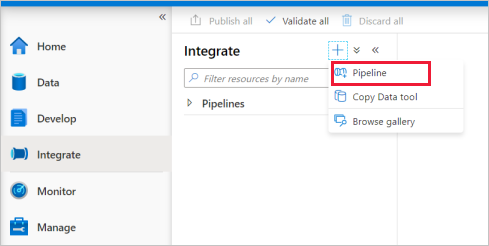
移至 [ 整合] 索引標籤。選取管線標頭旁邊的加號圖示,然後選取 [管線]。
在管線的 [ 屬性 設定] 頁面中,輸入 TransformMovies for Name。
在 [活動] 窗格中的 [移動和轉換] 下,將 [數據流] 拖曳到管線畫布上。
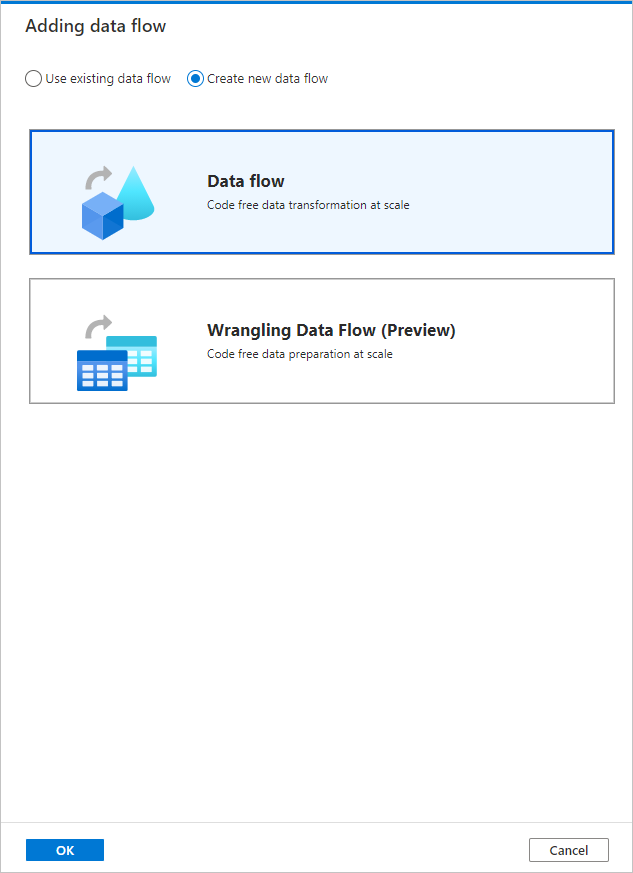
在 [ 新增數據流 ] 頁面彈出視窗中,選取 [建立新的數據流 -> 數據流]。 完成時選取 [ 確定 ]。
在 [屬性] 頁面上為您的數據流命名 TransformMovies。
在資料流程畫布中建置轉換邏輯
建立資料流程之後,會自動傳送到資料流程畫布。 在此步驟中,您將建立數據流,以採用ADLS記憶體中的MoviesDB.csv,並將喜劇的平均評等從1910年匯總到2000年。 然後,您會將此檔案寫回 ADLS 儲存體。
在數據流畫布上方,滑動 [數據流偵錯 ] 滑桿。 偵錯模式可讓您對即時 Spark 叢集進行轉換邏輯的互動式測試。 資料流程叢集需要 5-7 分鐘的準備時間,如果使用者想要進行資料流程開發,建議使用者先開啟偵錯功能。 如需詳細資訊,請參閱偵錯模式。
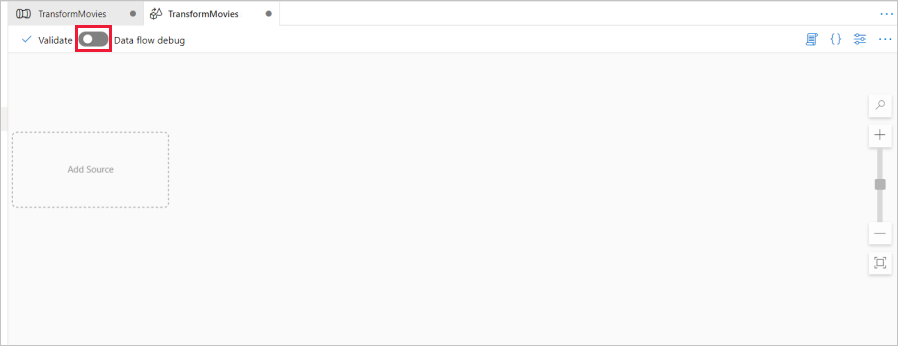
在資料流程畫布中,按一下 [新增來源] 方塊以新增來源。
將來源命名為 MoviesDB。 選取 [新增] 以建立新的來源資料集。
選擇 [Azure Data Lake Storage Gen2]。 選取 [繼續]。

選擇 [DelimitedText]。 選取 [繼續]。
將資料集命名為 MoviesDB。 在連結服務下拉式清單中,選擇 [新增]。
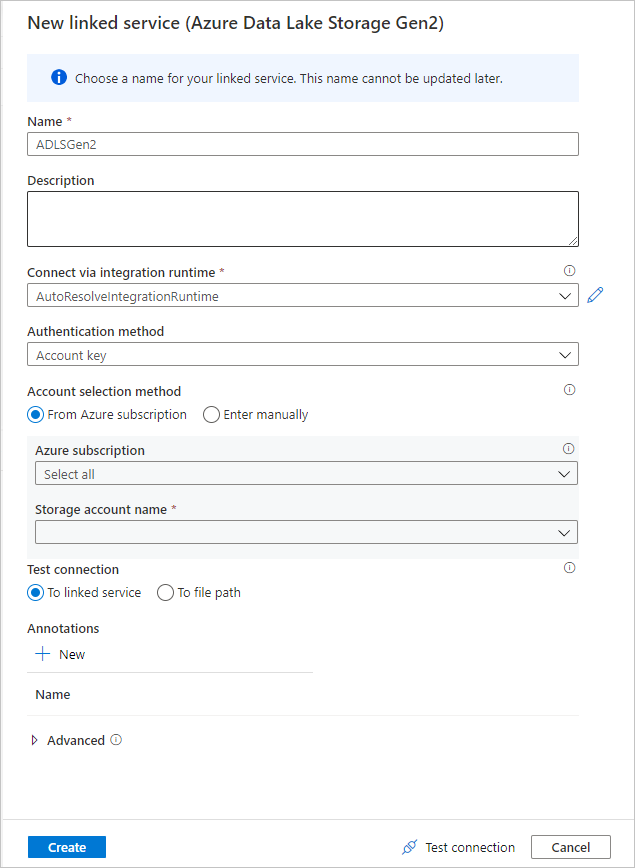
在連結服務建立畫面中,將您的ADLS Gen2連結服務 命名為ADLSGen2 ,並指定您的驗證方法。 然後輸入您的連線認證。 在本快速入門中,我們會使用帳戶密鑰來連線到記憶體帳戶。 您可以選取 [ 測試連線 ],確認已正確輸入認證。 完成後,請選取 [建立]。
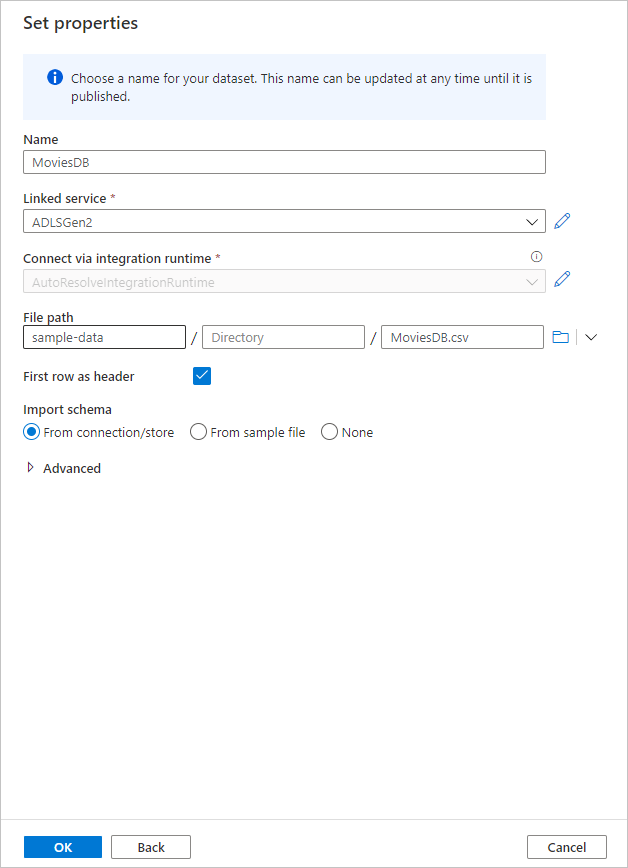
回到數據集建立畫面之後,請在 [檔案路徑] 欄位底下輸入檔案所在的位置。 在本快速入門中,“MoviesDB.csv” 檔案位於容器 “sample-data”。 當檔案有標頭時,請核取 [第一個資料列為標頭]。 選取 [從連線/存放區],以直接從儲存體中的檔案匯入標頭結構描述。 完成時選取 [ 確定 ]。
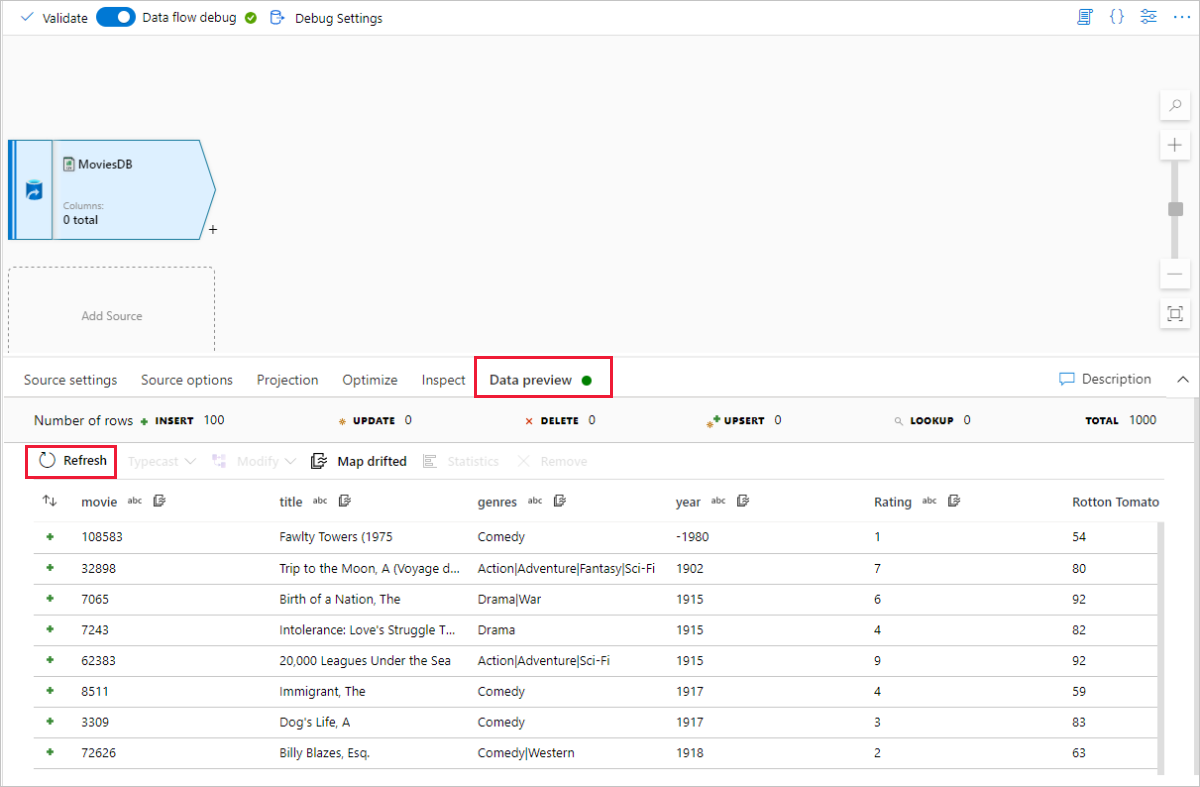
如果您的偵錯叢集已啟動,請前往來源轉換的 [資料預覽] 索引標籤,然後選取 [重新整理] 以取得資料的快照集。 您可以使用資料預覽來確認是否已正確設定轉換。
在資料流程畫布的來源節點旁,選取加號圖示以新增轉換。 您要新增的第一個轉換是篩選。
將篩選轉換命名為 FilterYears。 選取 [篩選對象] 旁的運算式方塊,以開啟運算式產生器。 您將在這裡指定篩選條件。
資料流程運算式產生器可讓您以互動方式建立要在各種轉換中使用的運算式。 運算式可以包含內建函式、輸入結構描述中的資料行,以及使用者定義的參數。 如需如何建立運算式的詳細資訊,請參閱資料流程運算式產生器。
在本快速入門中,您想要篩選 1910 年至 2000 年間流派喜劇的電影。 當年份目前為字串時,您必須使用
toInteger()函式將其轉換成整數。 使用大於或等於 (>=) 且小於或等於 (<=) 運算符,與常值年份值 1910 和 200-比較。 將這些表達式與&&(and) 運算子結合在一起。 產生的運算式如下所示:toInteger(year) >= 1910 && toInteger(year) <= 2000若要找出哪些電影是喜歌劇,您可以使用
rlike()函式來尋找資料行內容類型中的「喜歌劇」模式。 將rlike運算式與比較年份聯集以取得:toInteger(year) >= 1910 && toInteger(year) <= 2000 && rlike(genres, 'Comedy')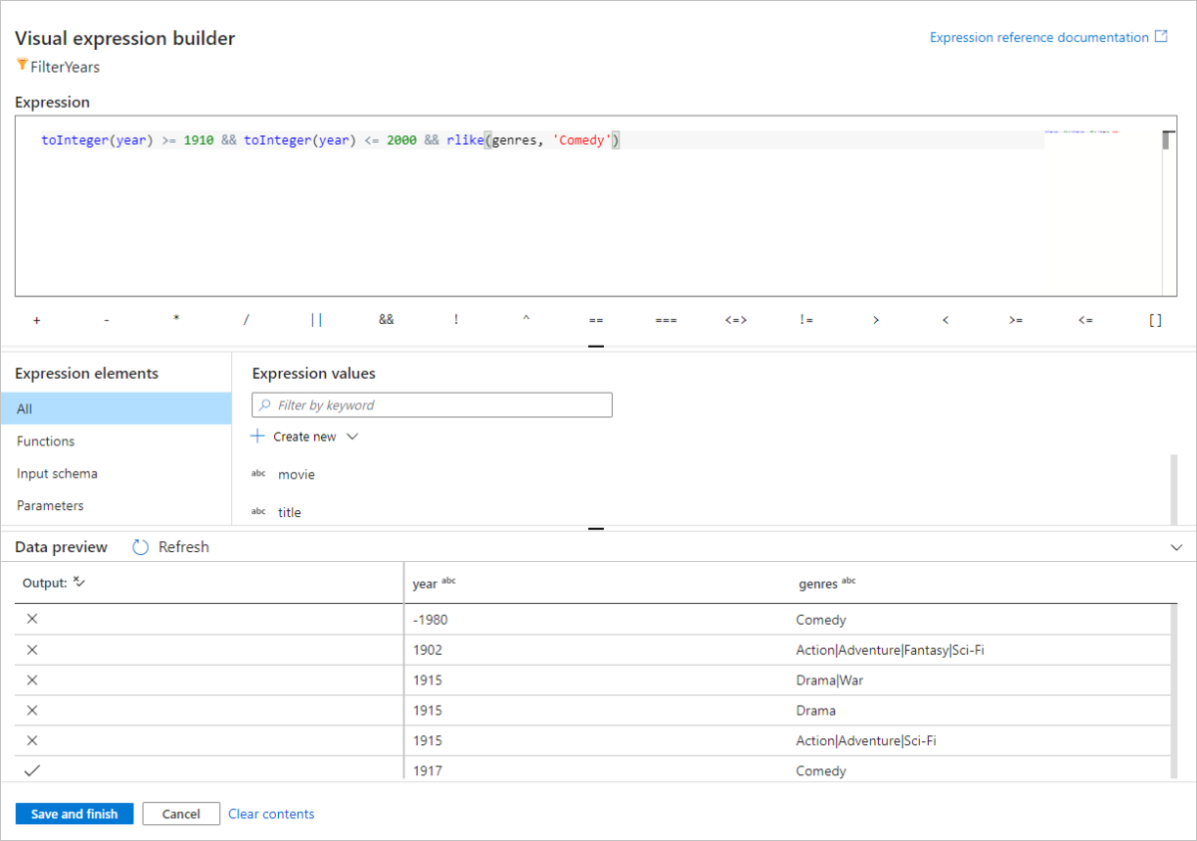
如果您有使用中的偵錯叢集,您可以按下 [ 重新 整理] 來確認邏輯,以查看與所使用的輸入相較之下的表達式輸出。 如何使用資料流程運算式語言來完成這項邏輯的正確解答不只一個。
完成表達式之後,請選取 [儲存] 和 [完成 ]。
擷取 [資料預覽] 以確認篩選是否正常運作。
下一個要新增的轉換是 [Schema modifier] \(結構描述修飾詞\) 下的彙總轉換。
將彙總轉換命名為 AggregateComedyRatings。 在 [分組方式] 索引標籤中,從下拉式清單中選取 [year],以依電影上映年份分組彙總。
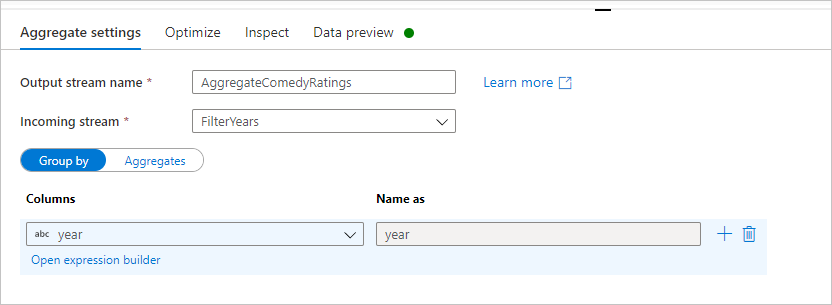
移至 [彙總] 索引標籤。在左側文字輸入框中,將彙總資料行命名為 AverageComedyRating。 選取右側運算式方塊,透過運算式產生器輸入彙總運算式。
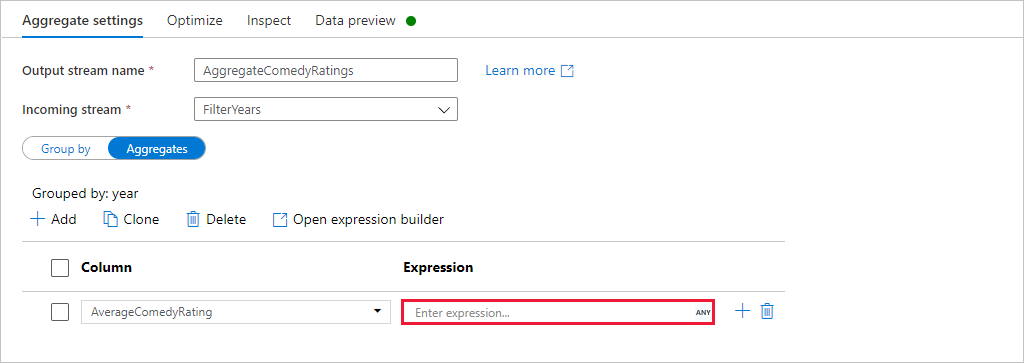
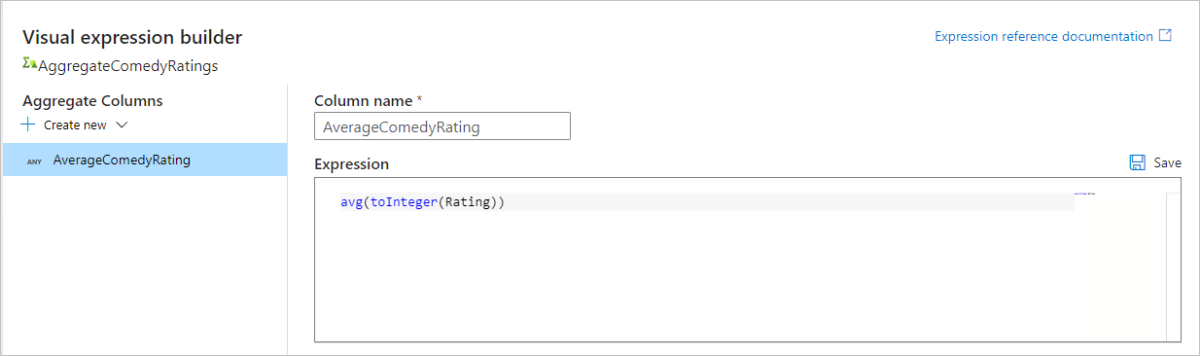
若要取得資料行 Rating 的平均值,請使用
avg()彙總函式。 由於 Rating 為字串且avg()接受數字輸入,因此我們必須透過toInteger()函式將值轉換成數字。 此運算式看起來如下所示:avg(toInteger(Rating))完成時選取 [儲存] 和 [ 完成 ]。
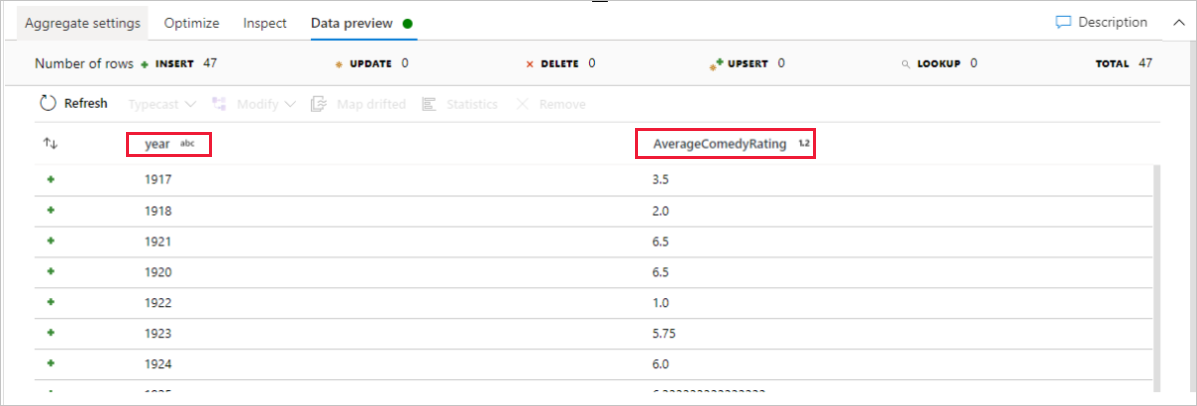
前往 [資料預覽] 索引標籤以檢視轉換輸出。 請注意,其中只有兩個資料行:[year] 和 [AverageComedyRating]。
接下來,您想要在 [目的地] 下新增接收器轉換。
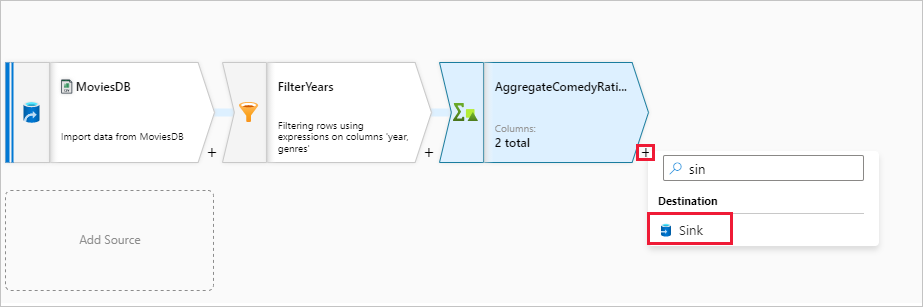
將您的接收器命名為 Sink。 選取 [新增] 以建立您的接收器資料集。
選擇 [Azure Data Lake Storage Gen2]。 選取 [繼續]。
選擇 [DelimitedText]。 選取 [繼續]。
將接收器資料集命名為 MoviesSink。 針對連結服務,請選擇您在步驟 7 中建立的 ADLS Gen2 鏈接服務。 輸入要寫入資料的輸出資料夾。 在本快速入門中,我們會在容器 『sample-data』 中寫入資料夾 『output』。 此資料夾不需要事先存在,而且可以動態建立。 將 [第一個資料列為標頭] 設定為 True,並針對 [匯入結構描述] 選取 [無]。 完成時選取 [ 確定 ]。
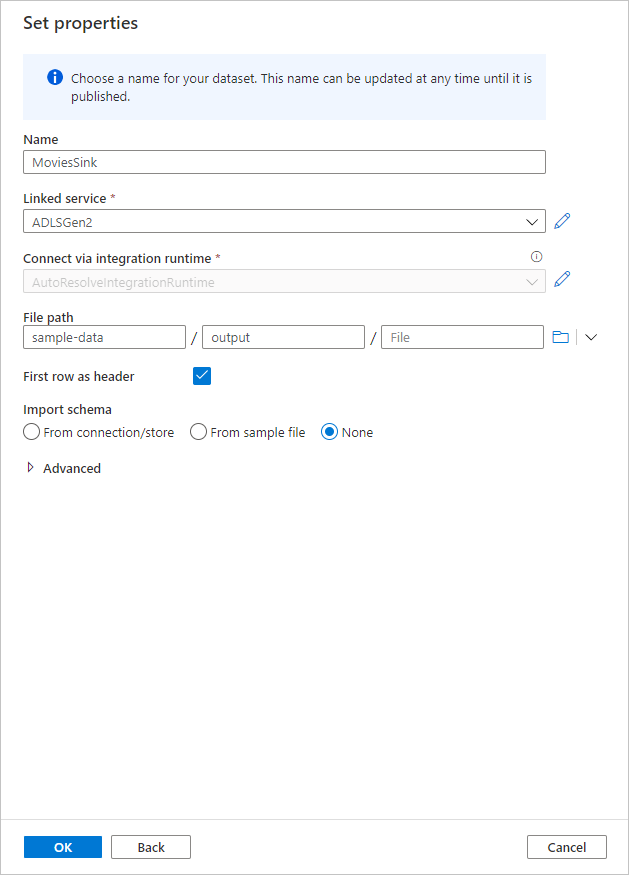
現在您已完成建立資料流程, 可以立即在管線中執行。
執行和監視資料流程
您可以在發佈管線之前先進行偵錯。 在此步驟中,您將觸發資料流程管線的偵錯執行。 雖然數據預覽不會寫入數據,但偵錯執行會將數據寫入至接收目的地。
前往管線畫布。 選取 [偵錯] 以觸發偵錯執行。
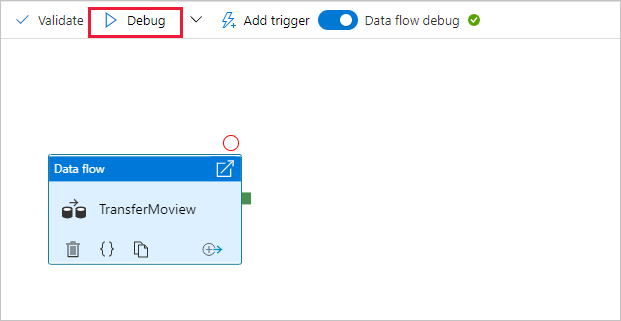
資料流程活動的管線偵錯會使用使用中偵錯叢集,但仍需要至少一分鐘的時間來初始化。 您可以透過 [ 輸出 ] 索引標籤來追蹤進度。執行成功之後,選取眼鏡圖示以開啟監視窗格。

在監視窗格中,您可以看到每個轉換步驟中的資料列數目及所花費的時間。
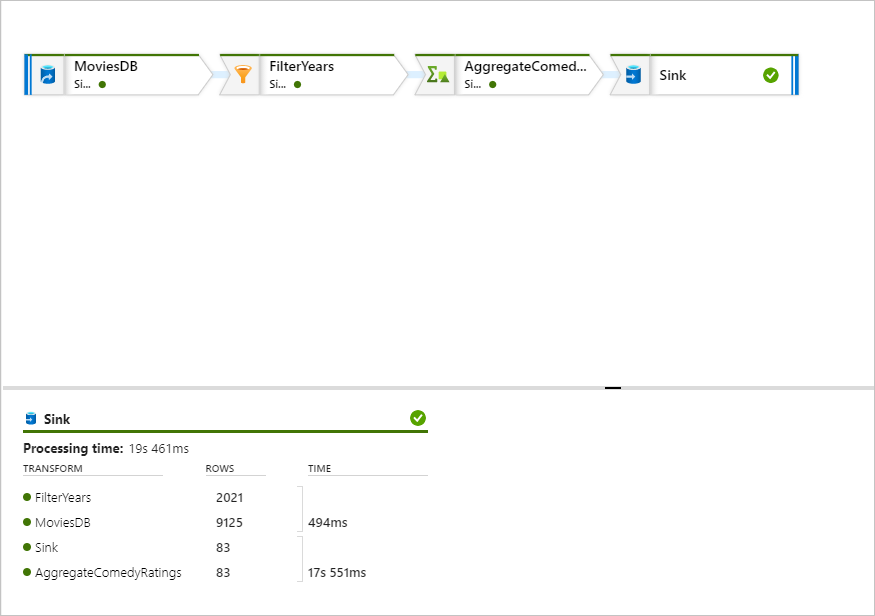
選取轉換以取得資料行和資料分割的詳細資訊。
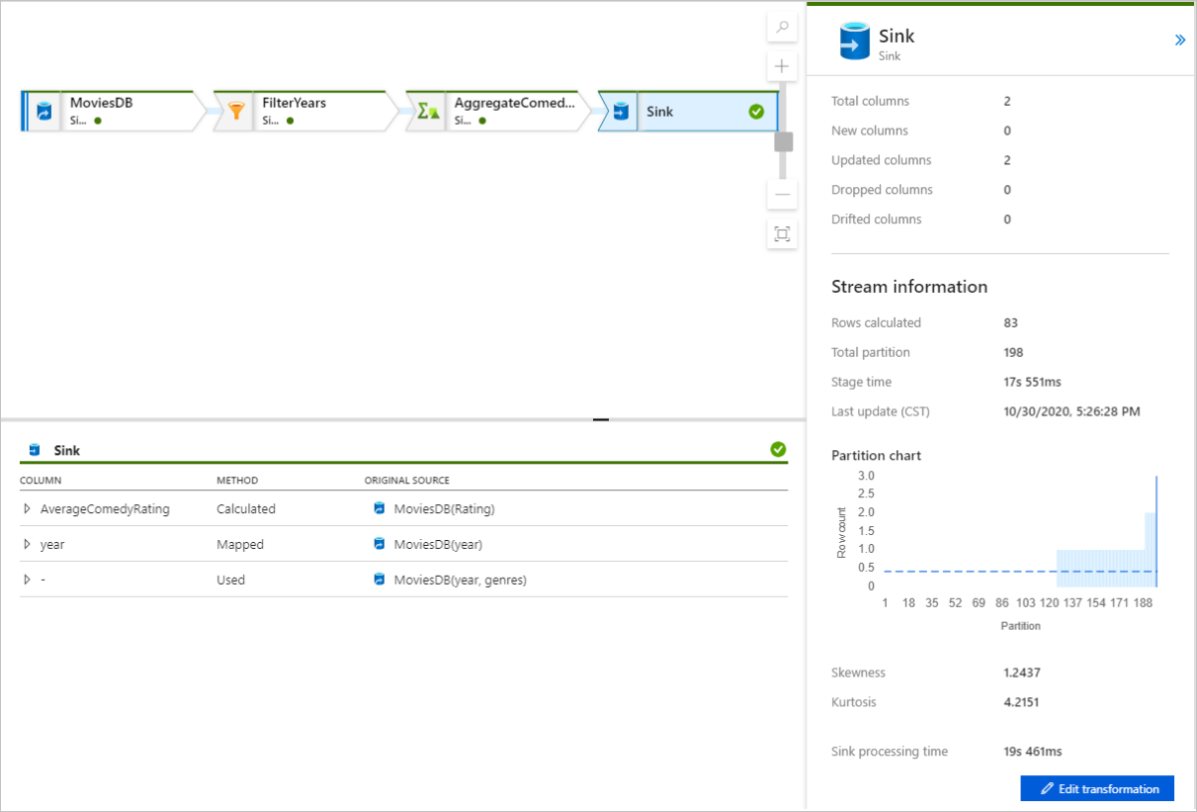
如果您已正確遵循本快速入門,您應該已將 83 個數據列和 2 個資料行寫入接收資料夾。 您可以檢查 Blob 記憶體來驗證資料。
下一步
請前往下列文章,以瞭解 Azure Synapse Analytics 支援: