快速入門:使用 Azure 入口網站 建立新的無伺服器 Apache Spark 集區
Azure Synapse Analytics 提供各種分析引擎,可協助您內嵌、轉換、模型、分析及散發數據。 Apache Spark 集區提供開放原始碼巨量數據計算功能。 在 Synapse 工作區中建立 Apache Spark 集區之後,就可以載入、模型化、處理和散發數據,以更快速地分析深入解析。
在本快速入門中,您將瞭解如何使用 Azure 入口網站 在 Synapse 工作區中建立 Apache Spark 集區。
重要
不論您使用Spark實例,是否按分鐘計費。 使用Spark實例之後,請務必關閉Spark實例,或設定短暫的逾時。 如需詳細資訊,請參閱 本文的清除資源 一節。
如果您沒有 Azure 訂用帳戶,請在開始前建立免費帳戶。
必要條件
- 您將需要 Azure 訂用帳戶。 如有需要, 請建立免費的 Azure 帳戶
- 您將使用 Synapse 工作區。
登入 Azure 入口網站
登入 Azure 入口網站
流覽至 Synapse 工作區
流覽至將建立 Apache Spark 集區的 Synapse 工作區,方法是直接在搜尋列中輸入服務名稱(或資源名稱)。
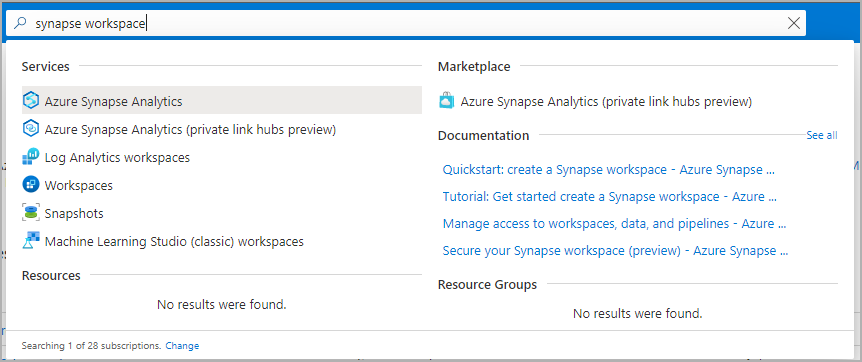
從工作區清單中,輸入要開啟之工作區的名稱(或部分名稱)。 在此範例中,我們使用名為 contosoanalytics 的工作區。


建立新的 Apache Spark 集區
重要
自 2023 年 9 月起,Apache Spark 2.4 的 Azure Synapse Runtime 已被取代,且正式不受支援。 假設 Spark 3.1 和 Spark 3.2 也宣佈終止支持, 我們建議客戶移轉至Spark 3.3。
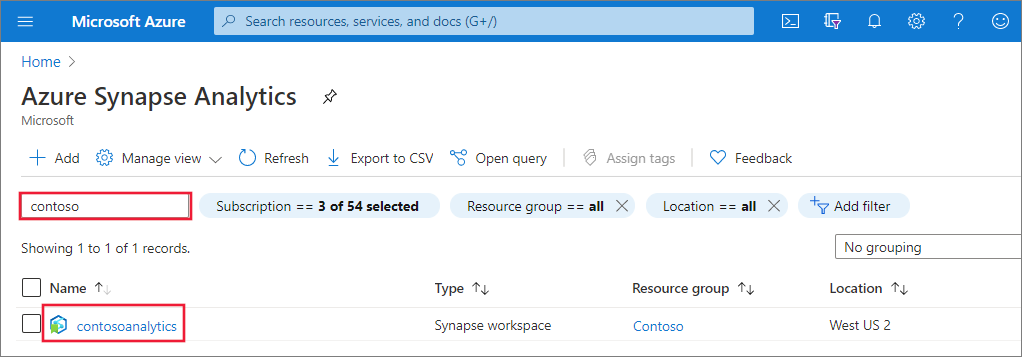
在您要在其中建立 Apache Spark 集區的 Synapse 工作區中,選取 [ 新增 Apache Spark 集區]。
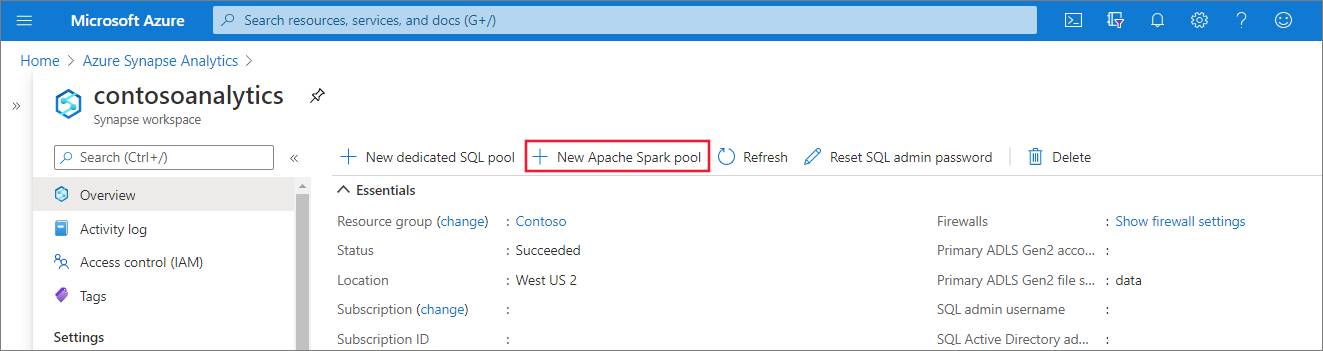
在 [基本] 索引標籤中,輸入下列詳細資料:
設定 建議的值 描述 Apache Spark 集區名稱 有效的集區名稱,例如 contosospark這是 Apache Spark 集區將擁有的名稱。 節點大小 小 (4 個虛擬 CPU/32 GB) 將此設為最小的大小,以降低本快速入門的成本 Autoscale 停用 本快速入門不需要自動調整 節點數目 5 使用小型大小來限制本快速入門的成本 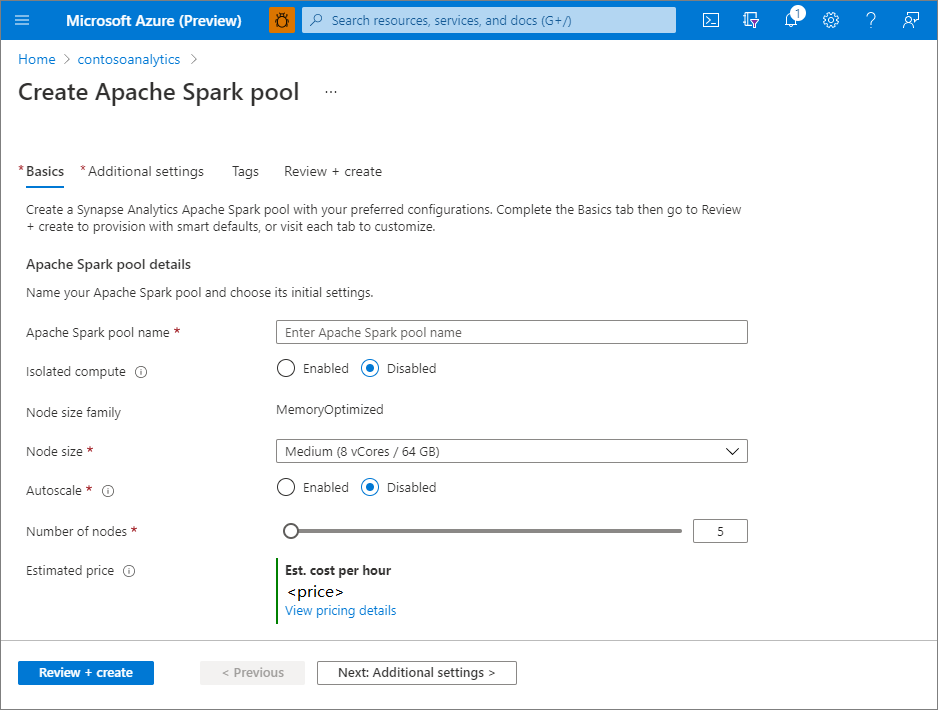
重要
Apache Spark 集區可以使用的名稱有特定限制。 名稱必須只包含字母或數位、必須是15或更少字元、必須以字母開頭、不包含保留字,而且在工作區中是唯一的。
選取 [下一步:其他設定 ],並檢閱預設設定。 請勿修改任何預設設定。

選取 [ 下一步:卷標]。 請考慮使用 Azure 標籤。 例如,用來識別誰建立資源的 「Owner」 或 「CreatedBy」 標記,以及用來識別此資源是否在生產、開發等中的 「Environment」 標記。如需詳細資訊,請參閱 開發 Azure 資源的命名和標記策略。
選取 [檢閱 + 建立]。
請確定詳細數據會根據先前輸入的內容看起來正確,然後選取 [ 建立]。
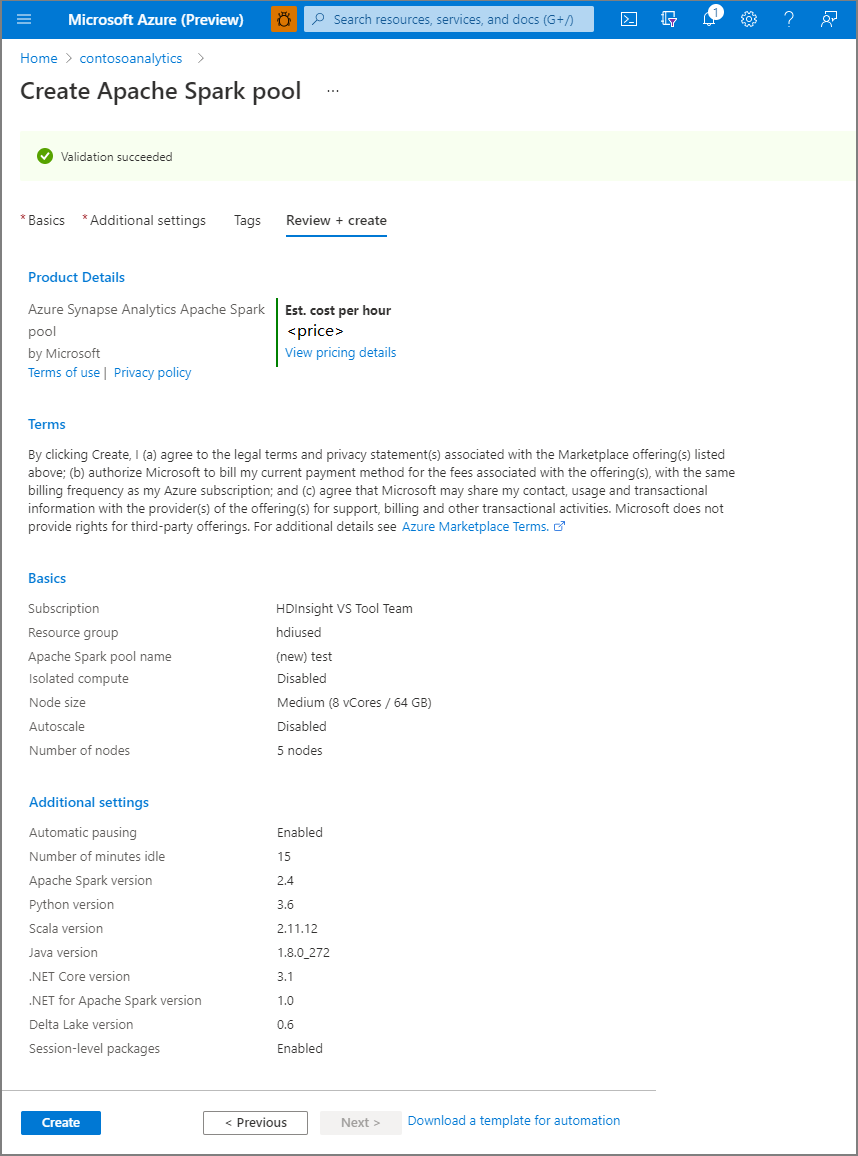
此時,資源布建流程將會啟動,指出一旦完成。
布建完成之後,流覽回工作區會顯示新建立Apache Spark集區的新專案。
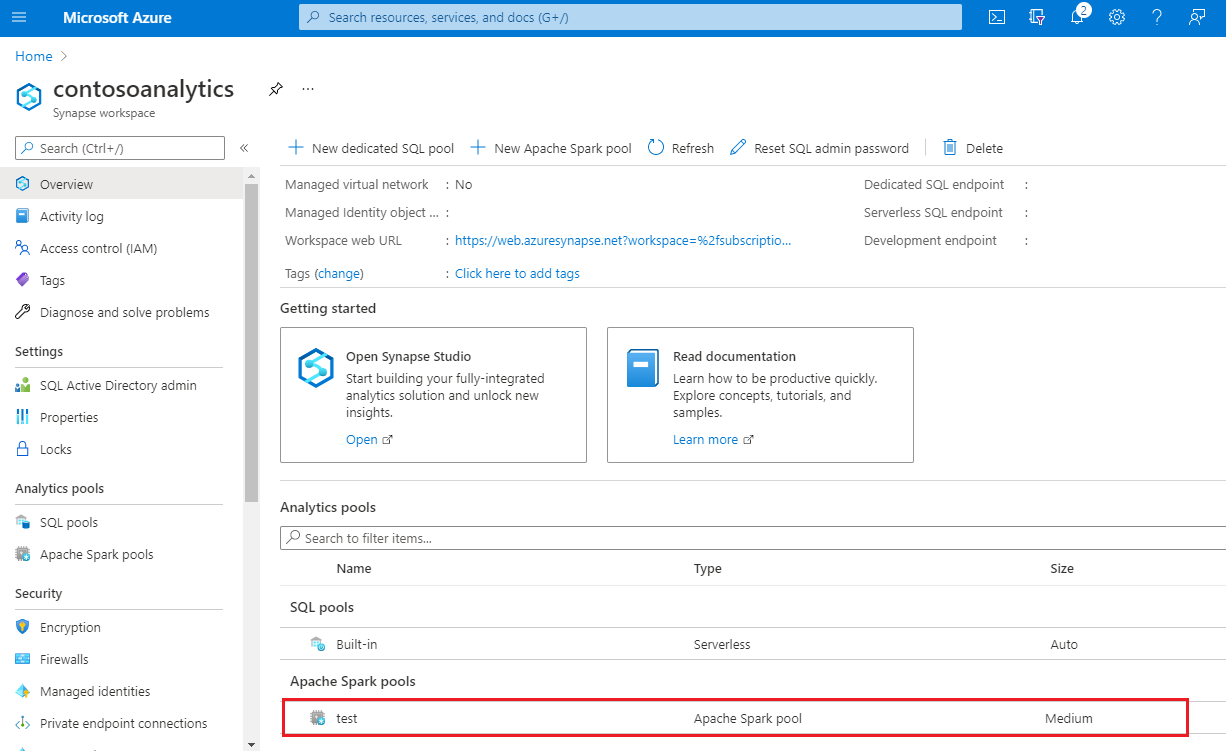
此時,沒有任何資源正在執行,也沒有Spark的費用,您已建立您想要建立之Spark實例的相關元數據。







清除資源
下列步驟會從工作區中刪除Apache Spark集區。
警告
刪除 Apache Spark 集區將會從工作區中移除分析引擎。 將無法再連線到集區,而且使用此 Apache Spark 集區的所有查詢、管線和筆記本將無法再運作。
如果您要刪除 Apache Spark 集區,請執行下列步驟:
- 流覽至工作區中的 [Apache Spark 集區] 窗格。
- 選取要刪除的 Apache Spark 集區(在此案例中為 contosospark)。
- 選取 [刪除]。
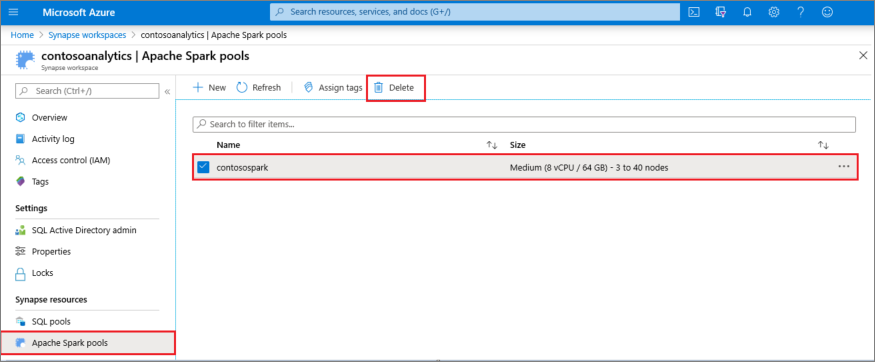
- 確認刪除,然後選取 [ 刪除] 按鈕。
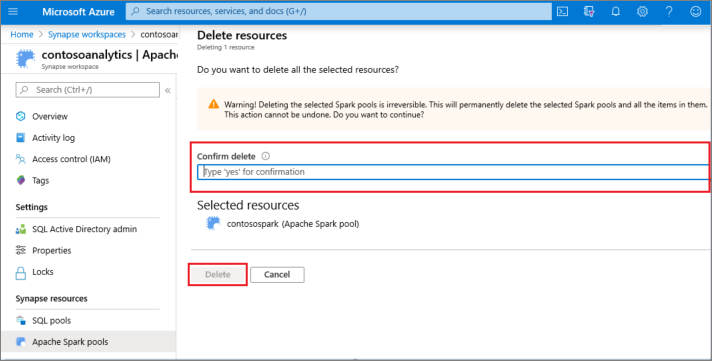
- 當流程成功完成之後,Apache Spark 集區將不再列於工作區資源中。
