Teradata 移轉的安全性、存取和作業
本文是七部分系列的第三部分,提供如何從 Teradata 遷移至 Azure Synapse Analytics 的指引。 本文著重於安全性存取作業的最佳做法。
安全性考量
本文討論現有舊版 Teradata 環境的連線方法,以及如何以最低風險和使用者影響移轉至 Azure Synapse Analytics。
本文假設需要依現狀移轉現有的連線和使用者/角色/許可權結構方法。 如果沒有,請使用 Azure 入口網站 來建立和管理新的安全制度。
如需 Azure Synapse 安全性選項的詳細資訊,請參閱安全性白皮書。
連線和驗證
Teradata 授權選項
提示
Teradata 和 Azure Synapse 中的驗證可以「在資料庫中」或透過外部方法進行。
Teradata 支援數種連線和授權機制。 有效的機制值為:
TD1,它會選取 Teradata 1 作為驗證機制。 需要使用者名稱和密碼。
TD2,它會選取 Teradata 2 作為驗證機制。 需要使用者名稱和密碼。
TDNEGO,它會根據原則自動選取其中一個驗證機制,而不需使用者介入。
LDAP,它會選取輕量型目錄存取通訊協定(LDAP)作為驗證機制。 應用程式會提供使用者名稱和密碼。
KRB5,它會在使用 Windows 伺服器的 Windows 用戶端上選取 Kerberos (KRB5)。 若要使用 KRB5 登入,用戶必須提供網域、使用者名稱和密碼。 將使用者名稱設定為
MyUserName@MyDomain來指定網域。NTLM,它會在 Windows 用戶端上選取使用 Windows 伺服器的 NTLM。 應用程式會提供使用者名稱和密碼。
Kerberos (KRB5)、Kerberos 兼容性 (KRB5C)、NT LAN Manager (NTLM) 和 NT LAN Manager 兼容性 (NTLMC) 僅適用於 Windows。
Azure Synapse 授權選項
Azure Synapse 支援兩個連線和授權的基本選項:
SQL 驗證:SQL 驗證是透過資料庫連線,其中包含資料庫標識碼、使用者標識元和密碼,以及其他選擇性參數。 這在功能上相當於 Teradata TD1、TD2 和預設連線。
Microsoft Entra 驗證:使用 Microsoft Entra 驗證,您可以在一個中央位置集中管理資料庫使用者和其他 Microsoft 服務 的身分識別。 集中標識元管理提供單一位置來管理 SQL 數據倉儲使用者,並簡化許可權管理。 Microsoft Entra ID 也可以支援 LDAP 和 Kerberos 服務的連線,例如,如果移轉資料庫之後,Microsoft Entra ID 可用來連線到現有的 LDAP 目錄。
使用者、角色及權限
概觀
提示
高階規劃對於成功的移轉項目至關重要。
Teradata 和 Azure Synapse 都會透過使用者、角色和許可權的組合來實作資料庫訪問控制。 兩者都使用標準 SQL CREATE USER 和 語句來定義使用者和 CREATE ROLE 角色,以及 GRANT 和 REVOKE 語句,將這些使用者和/或角色指派或移除許可權。
提示
建議自動化移轉程式,以減少經過的時間和錯誤範圍。
從概念上講,這兩個資料庫很類似,而且有可能將現有使用者標識碼、角色和許可權的移轉自動化到某種程度。 從 Teradata 系統目錄資料表擷取現有的舊版使用者和角色資訊,併產生在 Azure Synapse 中執行的相符對等 CREATE USER 和 CREATE ROLE 語句,以重新建立相同的使用者/角色階層,以移轉這類數據。
在數據擷取之後,請使用 Teradata 系統目錄數據表來產生對等 GRANT 語句來指派許可權(其中相等的語句存在)。 下圖顯示如何使用現有的元數據來產生必要的 SQL。
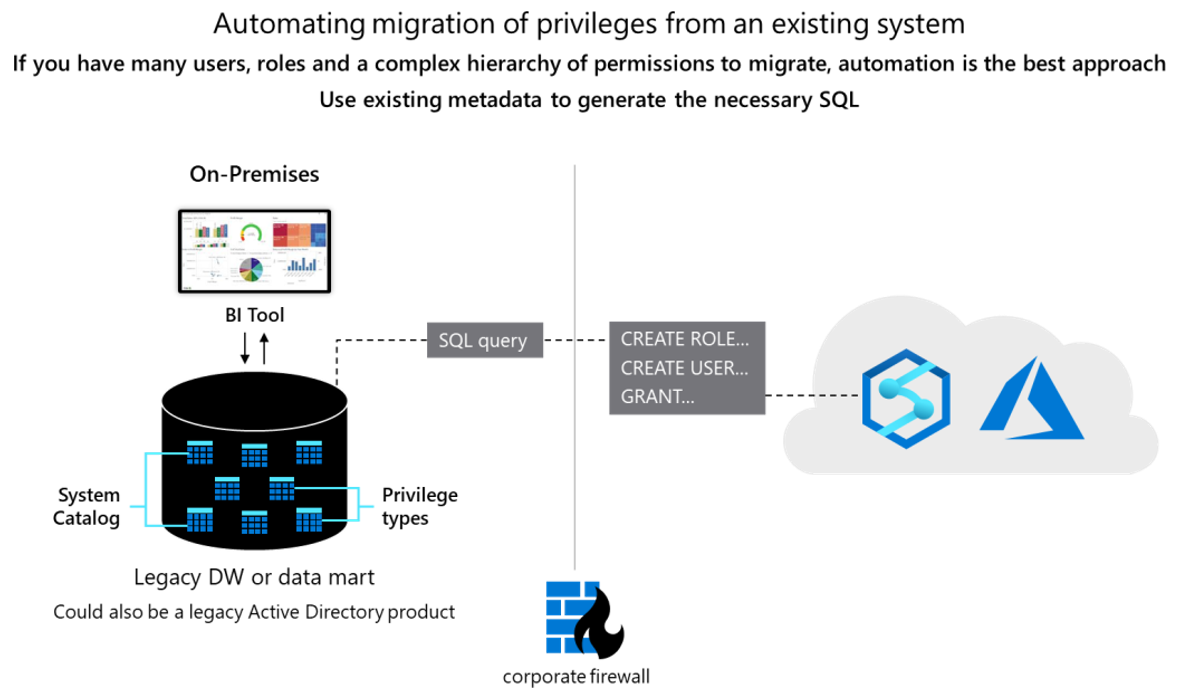
使用者和角色
提示
數據倉儲的移轉不僅需要數據表、檢視表和 SQL 語句。
在系統目錄數據表 DBC.USERS (或 DBC.DATABASES) 和 DBC.ROLEMEMBERS中找到 Teradata 系統中目前使用者和角色的相關信息。 查詢這些數據表(如果使用者可以 SELECT 存取這些數據表),以取得系統內定義的目前使用者和角色清單。 以下是針對個別使用者執行此動作的查詢範例:
/***SQL to find all users***/
SELECT
DatabaseName AS UserName
FROM DBC.Databases
WHERE dbkind = 'u';
/***SQL to find all roles***/
SELECT A.ROLENAME, A.GRANTEE, A.GRANTOR,
A.DefaultRole,
A.WithAdmin,
B.DATABASENAME,
B.TABLENAME,
B.COLUMNNAME,
B.GRANTORNAME,
B.AccessRight
FROM DBC.ROLEMEMBERS A
JOIN DBC.ALLROLERIGHTS B
ON A.ROLENAME = B.ROLENAME
GROUP BY 1,2,3,4,5,6,7
ORDER BY 2,1,6;
這些範例會修改 SELECT 語句,以產生結果集,這是一系列的 CREATE USER 和 CREATE ROLE 語句,方法是在語句中 SELECT 將適當的文字納入為常值。
無法擷取現有的密碼,因此您必須實作配置在 Azure Synapse 上配置新初始密碼的配置。
權限
提示
基本資料庫作業有對等的 Azure Synapse 許可權,例如 DML 和 DDL。
在 Teradata 系統中,系統數據表 DBC.ALLRIGHTS 並 DBC.ALLROLERIGHTS 保留使用者和角色的訪問許可權。 查詢這些數據表(如果使用者可以 SELECT 存取這些數據表),以取得系統內定義的目前訪問許可權清單。 以下是個別使用者的查詢範例:
/**SQL for AccessRights held by a USER***/
SELECT UserName, DatabaseName,TableName,ColumnName,
CASE WHEN Abbv.AccessRight IS NOT NULL THEN Abbv.Description ELSE
ALRTS.AccessRight
END AS AccessRight, GrantAuthority, GrantorName, AllnessFlag, CreatorName, CreateTimeStamp
FROM DBC.ALLRIGHTS ALRTS LEFT OUTER JOIN AccessRightsAbbv Abbv
ON ALRTS.AccessRight = Abbv.AccessRight
WHERE UserName='UserXYZ'
Order By 2,3,4,5;
/**SQL for AccessRights held by a ROLE***/
SELECT RoleName, DatabaseName,TableName,ColumnName,
CASE WHEN Abbv.AccessRight IS NOT NULL THEN Abbv.Description ELSE
ALRTS.AccessRight
END AS AccessRight, GrantorName, CreateTimeStamp
FROM DBC.ALLROLERIGHTS ALRTS LEFT OUTER JOIN AccessRightsAbbv
Abbv
ON ALRTS.AccessRight = Abbv.AccessRight
WHERE RoleName='BI_DEVELOPER'
Order By 2,3,4,5;
修改這些範例 SELECT 語句,以產生一系列 GRANT 語句的結果集,方法是在語句中 SELECT 將適當的文字納入為常值。
使用數據表 AccessRightsAbbv 來查閱訪問許可權的全文,因為聯結索引鍵是縮寫的 『type』 字段。 如需 Teradata 訪問權限的清單及其在 Azure Synapse 中的對等專案,請參閱下表。
| Teradata 許可權名稱 | Teradata 類型 | Azure Synapse 對等專案 |
|---|---|---|
| ABORT 會話 | AS | KILL DATABASE CONNECTION |
| ALTER EXTERNAL PROCEDURE | 阿拉伯聯合大公國 | 4 |
| ALTER FUNCTION | AF | ALTER FUNCTION |
| ALTER PROCEDURE | AP | ALTER PROCEDURE |
| CHECKPOINT | CP | CHECKPOINT |
| CREATE AUTHORIZATION | CA | CREATE LOGIN |
| CREATE DATABASE | CD | CREATE DATABASE |
| CREATE EXTERNAL PROCEDURE | CE | 4 |
| CREATE FUNCTION | CF | CREATE FUNCTION |
| CREATE GLOP | GC | 3 |
| CREATE MACRO | 喀麥隆 | CREATE PROCEDURE 2 |
| 建立擁有者程式 | OP | 建立程序 |
| CREATE PROCEDURE | 電腦 | 建立程序 |
| CREATE PROFILE | CO | CREATE LOGIN 1 |
| CREATE ROLE | CR | CREATE ROLE |
| DROP DATABASE | DD | DROP DATABASE |
| DROP 函式 | DF | DROP FUNCTION |
| DROP GLOP | GD | 3 |
| DROP MACRO | DM | DROP PROCEDURE 2 |
| DROP PROCEDURE | PD | DELETE PROCEDURE |
| DROP PROFILE | D 0 | DROP LOGIN 1 |
| DROP ROLE | 博士 | DELETE ROLE |
| DROP TABLE | DT | DROP TABLE |
| DROP TRIGGER | DG | 3 |
| DROP USER | DU | DROP USER |
| DROP VIEW | DV | DROP VIEW |
| 轉 儲 | DP | 4 |
| EXECUTE | E | 執行 CREATE 陳述式之前,請先執行 |
| EXECUTE FUNCTION | EF | 執行 CREATE 陳述式之前,請先執行 |
| EXECUTE PROCEDURE | PE | 執行 CREATE 陳述式之前,請先執行 |
| GLOP 成員 | GM | 3 |
| INDEX | IX | CREATE INDEX |
| INSERT | I | INSERT |
| MONRESOURCE | MR | 5 |
| MONSESSION | 毫秒 | 5 |
| 覆寫傾印條件約束 | OA | 4 |
| 覆寫 RESTORE 條件約束 | OR | 4 |
| REFERENCES | RF | REFERENCES |
| REPLCONTROL | RO | 5 |
| RESTORE | RS | 4 |
| SELECT | R | SELECT |
| SETRESRATE | SR | 5 |
| SETSESSRATE | SS | 5 |
| 顯示 | SH | 3 |
| UPDATE | U | UPDATE |
AccessRightsAbbv 資料表附註:
Teradata
PROFILE在功能上相當於LOGINAzure Synapse 中的 。下表摘要說明 Teradata 中的巨集和預存程式之間的差異。 在 Azure Synapse 中,程式會提供數據表中所述的功能。
Macro 預存程序 包含 SQL 包含 SQL 可能包含 BTEQ 點命令 包含完整的SPL 可接收傳遞給它的參數值 可接收傳遞給它的參數值 可以擷取一或多個數據列 必須使用數據指標來擷取多個數據列 儲存在 DBC PERM 空間中 儲存在 DATABASE 或 USER PERM 中 將數據列傳回用戶端 可傳回一或多個值給用戶端做為參數 SHOW、GLOP和TRIGGER在 Azure Synapse 中沒有直接對等專案。這些功能由 Azure Synapse 中的系統自動管理。 請參閱 作業考慮。
在 Azure Synapse 中,這些功能是在資料庫外部處理。
如需 Azure Synapse 中訪問許可權的詳細資訊,請參閱 Azure Synapse Analytics 安全性許可權。
操作考量
提示
若資料倉儲要有效運作,便需要作業工作。
本節討論如何在 Azure Synapse 中實作典型的 Teradata 作業工作,並降低對用戶的風險和影響。
與所有數據倉儲產品一樣,生產環境中一旦有持續管理工作,就有必要讓系統有效率地執行,並提供數據以進行監視和稽核。 未來成長的資源使用率和容量規劃也屬於此類別,備份/還原數據也是一樣。
雖然概念上不同數據倉儲的管理和作業工作很類似,但個別的實作可能會有所不同。 一般而言,Azure Synapse 等新式雲端式產品通常會納入更自動化且「系統管理」的方法(而不是 Teradata 等舊版數據倉儲中的更「手動」方法)。
下列各節會比較各種作業工作的 Teradata 和 Azure Synapse 選項。
內務處理工作
提示
管家工作可讓生產倉儲有效率地運作,並優化使用記憶體等資源。
在大部分的舊版數據倉儲環境中,需要執行一般「管家」工作,例如回收可釋放的磁碟空間,方法是移除舊版更新或刪除的數據列,或重新組織數據記錄檔或索引區塊以提高效率。 收集統計數據也是一項可能耗時的工作。 在擷取大量數據之後需要收集統計數據,以提供查詢優化器最新的數據,以基底產生查詢執行計劃。
Teradata 建議收集統計數據,如下所示:
收集未填入數據表的統計數據,以設定內部處理中使用的間隔直方圖。 此初始集合可讓後續的統計數據集合更快。 請務必在新增數據之後重新收集統計數據。
收集新填入數據表的原型階段統計數據。
在數據表或數據分割的重大變更百分比之後收集生產階段統計數據(~10% 的數據列)。 對於大量的非統一值,例如日期或時間戳,最好是以 7% 的回想。
在您建立使用者並將實際查詢載入套用至資料庫之後收集生產階段統計數據(最多三個月查詢)。
在低 CPU 使用率期間升級或移轉後的前幾周收集統計數據。
您可以使用自動化統計數據管理開啟 API,或使用 Teradata 點 Stats Manager Portlet 來手動管理統計數據集合。
提示
在 Azure 中自動化和監視內務處理工作。
Teradata Database 包含數據字典中的許多記錄數據表,可自動或啟用特定功能之後累積數據。 由於記錄資料會隨著時間成長,因此會清除較舊的資訊,以避免使用永久空間。 有選項可將這些記錄的維護自動化。 接下來會討論需要維護的 Teradata 字典數據表。
要維護的字典數據表
使用 DBC.AMPUsage 檢視和軟體提供的巨集重 ClearPeakDisk 設累積器和尖峰值:
DBC.Acctg:依帳戶/用戶的資源使用量DBC.DataBaseSpace:資料庫和數據表空間會計
Teradata 會自動維護這些數據表,但良好的作法可以減少其大小:
DBC.AccessRights:對象的用戶權力DBC.RoleGrants:物件的角色許可權DBC.Roles:已定義的角色DBC.Accounts:依使用者的帳戶代碼
封存這些記錄數據表(如有需要),並清除資訊 60-90 天。 保留取決於客戶需求:
DBC.SW_Event_Log:資料庫主控台記錄DBC.ResUsage:資源監視數據表DBC.EventLog:工作階段登入/註銷歷程記錄DBC.AccLogTbl:記錄的使用者/物件事件DBC.DBQL tables:記錄的使用者/SQL 活動.NETSecPolicyLogTbl:記錄動態安全策略稽核線索.NETSecPolicyLogRuleTbl:控制記錄動態安全策略的時機和方式
當相關聯的卸除式媒體過期並覆寫時,清除這些數據表:
DBC.RCEvent:封存/復原事件DBC.RCConfiguration:封存/復原設定DBC.RCMedia:封存/復原的 VolSerial
Azure Synapse 可以選擇自動建立統計數據,以便視需要使用統計數據。 根據排程或自動,手動執行索引和數據區塊的重組。 利用原生內建 Azure 功能可減少移轉練習中所需的工作。
監視和稽核
提示
經過一段時間,已實作數個不同的工具,以允許監視和記錄 Teradata 系統。
Teradata 提供數個工具來監視作業,包括 Teradata 觀點和生態系統管理員。 針對記錄查詢歷程記錄,資料庫查詢記錄 (DBQL) 是一項 Teradata 資料庫功能,可提供一系列預先定義的數據表,可根據使用者定義規則來儲存查詢及其持續時間、效能和目標活動的歷程記錄。
資料庫管理員可以使用 Teradata 點來判斷系統狀態、趨勢和個別查詢狀態。 藉由觀察系統使用量的趨勢,系統管理員更能夠規劃項目實作、批次作業和維護,以避免使用尖峰期間。 商務使用者可以使用 Teradata 點快速存取報表和查詢的狀態,並向下切入至詳細數據。
提示
Azure 入口網站提供 UI 來管理所有 Azure 資料和程序的監視和稽核工作。
同樣地,Azure Synapse 會在 Azure 入口網站 內提供豐富的監視體驗,以提供數據倉儲工作負載的深入解析。 Azure 入口網站是監視資料倉儲的建議工具,因為其提供可設定的保留期、警示、建議,以及可自訂的計量與記錄圖表及儀表板。
入口網站也可讓您與其他 Azure 監視服務整合,例如 Operations Management Suite (OMS) 和 Azure 監視器 (logs),為數據倉儲提供整體的監視體驗,以及整合式監視體驗的整個 Azure 分析平臺。
提示
低階和全系統計量會自動記錄在 Azure Synapse 中。
Azure Synapse 的資源使用率統計數據會自動記錄在系統中。 每個查詢的計量包括 CPU、記憶體、快取、I/O 和暫存工作區的使用統計數據,以及連線嘗試失敗等連線資訊。
Azure Synapse 提供一組 動態管理檢視 (DMV)。 若要對您的工作負載進行主動式疑難排解和識別效能瓶頸時,這些檢視十分實用。
如需詳細資訊,請參閱 Azure Synapse 作業和管理選項。
高可用性 (HA) 和災害復原 (DR)
Teradata 會實作 、封存還原複製 (ARC) 公用程式及數據流架構 (DSA) 等 FALLBACK功能,透過復寫和封存數據來提供資料遺失和高可用性的保護。 災害復原 (DR) 選項包括雙重作用中解決方案、DR 即服務,或根據復原時間需求來取代系統。
提示
Azure Synapse 會自動建立快照集,以確保快速復原時間。
Azure Synapse 會使用資料庫快照集來提供倉儲的高可用性。 數據倉儲快照集會建立還原點,可用來復原或將數據倉儲複製到先前的狀態。 由於 Azure Synapse 是分散式系統,因此數據倉儲快照集是由 Azure 儲存體 中的許多檔案所組成。 快照集會從儲存在數據倉儲中的數據擷取累加變更。
Azure Synapse 會在一天中自動擷取快照集,以建立 7 天可用的還原點。 無法變更此保留期間。 Azure Synapse 支援八小時的復原點目標 (RPO)。 數據倉儲可以從過去七天內擷取的任何一個快照集,在主要區域中還原。
提示
使用使用者定義的快照集,在密鑰更新之前定義恢復點。
也支援使用者定義的還原點,允許手動觸發快照集,以在大型修改前後建立數據倉儲的還原點。 這項功能可確保還原點在邏輯上保持一致,以在所需的 RPO 少於 8 小時的任何工作負載中斷或使用者錯誤時,提供額外的數據保護。
提示
Microsoft Azure 提供自動備份至不同地理位置的功能,以便進行災害復原。
除了先前所述的快照集,Azure Synapse 也會以標準 方式每天對配對數據中心進行一次異地備份。 異地還原的 RPO 為 24 小時。 您可以將異地備份還原至支援 Azure Synapse 的任何其他區域中的伺服器。 異地備份可確保數據倉儲可以還原,以防主要區域中的還原點無法使用。
工作負載管理
提示
在生產數據倉儲中,通常會有不同資源使用量特性同時執行的混合工作負載。
工作負載是一種具有常見特性的資料庫要求類別,其數據庫存取權可以使用一組規則來管理。 工作負載適用於:
為不同類型的要求設定不同的存取優先順序。
監視資源使用量模式、效能微調和容量規劃。
限制可以同時執行的要求或會話數目。
在 Teradata 系統中,工作負載管理是藉由監視系統活動和達到預先定義限制時採取行動來管理工作負載效能的行為。 工作負載管理會使用規則,而且每個規則僅適用於某些資料庫要求。 不過,所有規則的集合會套用至平臺上的所有作用中工作。 Teradata Active System Management (TASM) 會在 Teradata 資料庫中執行完整的工作負載管理。
Azure Synapse 中,資源類別是預先決定的資源限制,其掌管查詢執行時的計算資源與並行存取。 資源類別可協助您管理工作負載,方法是設定並行執行的查詢數目限制,以及在指派給每個查詢的計算資源上設定限制。 記憶體和並行存取之間各有取捨。
Azure Synapse 會自動記錄資源使用率的統計資料。 計量包括每個查詢的 CPU、記憶體、快取、I/O 和暫存工作區的使用量統計資料。 Azure Synapse 也會記錄連線資訊,例如失敗的連線嘗試。
提示
低階計量和全系統計量都會自動記錄至 Azure 中。
Azure Synapse 支援下列的基本工作負載管理概念:
工作負載分類:您可以將要求指派給工作負載群組,以設定重要性層級。
工作負載重要性:您可以影響要求取得資源存取權的順序。 根據預設,當資源可供使用時,系統會以先進先出的方式從佇列中釋放查詢。 工作負載的重要性可讓較高優先順序的查詢立即接收資源,而非以佇列為準。
工作負載隔離:您可以保留工作負載群組的資源、指派不同資源的使用量上限和最使用量下限、限制要求群組可取用的資源,以及設定逾時值以自動終止失控查詢。
執行混合工作負載可能會造成忙碌系統上的資源挑戰。 成功的工作負載管理配置可有效地管理資源、確保高效率的資源使用率,以及最大化的投資報酬率 (ROI)。 工作負載分類、工作負載重要性和工作負載隔離可更充分地控制工作負載如何利用系統資源。
工作負載管理指南將說明分析工作負載、管理和監視工作負載重要性的技術](../../sql-data-warehouse/sql-data-warehouse-how-to-manage-and-monitor-workload-importance.md),以及說明將資源類別轉換成工作負載群組的步驟。 使用 Azure 入口網站和 DMV 上的 T-SQL 查詢來監視工作負載,以確保有效率地利用適用資源。 Azure Synapse 提供一組動態管理檢視 (DMV),可監視工作負載管理的所有層面。 若要在工作負載中進行主動式疑難排解和識別效能瓶頸時,這些檢視十分實用。
此資訊也可用於容量規劃,判斷其他使用者或應用程式工作負載所需的資源。 這也適用於規劃相應增加/相應減少計算資源,以支援符合成本效益的「尖峰」工作負載。
如需 Azure Synapse 中工作負載管理的詳細資訊,請參閱使用資源類別進行工作負載管理。
調整計算資源
提示
Azure 的主要優點是能夠依需求獨立增加和減少相應計算資源,符合成本效益的方式處理尖峰工作負載。
Azure Synapse 的架構會分隔記憶體和計算,讓每個記憶體和計算都能獨立調整。 如此便可調整計算資源,以符合無關資料儲存體的效能需求。 您也可以暫停和繼續計算資源。 此架構的自然優點是計算和記憶體的計費是分開的。 若資料倉儲未使用,則可暫停計算以節省計算成本。
您可以調整數據倉儲的數據倉儲單位設定,以相應增加或相應減少計算資源。 當您新增更多數據倉儲單位時,載入和查詢效能會以線性方式增加。
新增更多計算節點可增加計算能力,以及運用更多平行處理的能力。 隨著計算節點數目的增加,每個計算節點的散發數目會減少,為查詢提供更多的計算能力和平行處理。 同樣地,減少數據倉儲單位會減少計算節點的數目,進而減少查詢的計算資源。
下一步
若要深入瞭解視覺效果和報告,請參閱本系列中的下一篇文章: Teradata 移轉的視覺效果和報告。