對輸入連線進行疑難排解
此文章說明 Azure 串流分析輸入連線的常見問題、如何對輸入問題進行疑難排解,以及如何修正問題。 需要對串流分析作業啟用資源記錄,許多疑難排解步驟才能執行。 如果您未啟用資源記錄,請參閱使用資源記錄對 Azure 串流分析進行疑難排解。
作業未收到輸入事件
測試輸入和輸出連線能力。 針對各個輸入和輸出使用 [測試連線] 按鈕,驗證輸入及輸出的連線能力。
檢查您的輸入資料。
確定您已在輸入預覽中選取時間範圍。 在測試查詢之前,請選擇 [選取時間範圍],然後輸入範例持續時間。
重要
對於非網路插入的 ASA 作業,請不要以任何方式依賴來自 ASA 之連線的來源 IP 位址。 視不時發生的服務基礎結構作業而定,它們可以是公用或私人 IP。
格式不正確的輸入事件導致還原序列化錯誤
當串流分析作業的輸入資料流包含格式不正確的訊息時,就會導致還原序列化問題。 例如,格式錯誤的訊息可能是在 JSON 物件中遺漏括弧或大括弧所導致,或是由時間欄位中不正確的時間戳記格式所導致。
當串流分析作業從輸入收到格式不正確的訊息時,會捨棄訊息並以警告通知您。 您串流分析作業的 [輸入] 圖格上會顯示警告符號。 只要作業處於執行中狀態,下列警告符號就會存在:
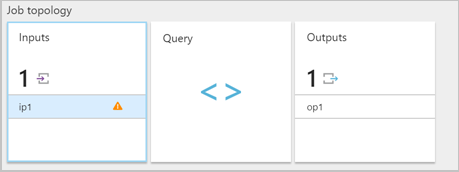
啟用資源記錄以檢視錯誤及導致該錯誤之訊息 (承載) 的詳細資料。 有許多原因會造成還原序列化錯誤。 如需特定還原序列化錯誤的詳細資訊,請參閱輸入資料錯誤。 如果未啟用資源記錄,Azure 入口網站中將會提供簡短通知。
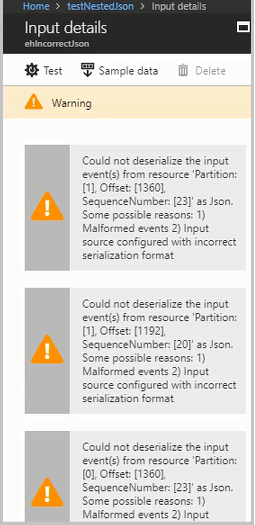
在訊息承載大於 32 KB 或為二進位格式的情況下,請執行 CheckMalformedEvents.cs 程式碼,其於 GitHub 範例存放庫 \(英文\) 中提供。 此程式碼讀取分割區識別碼、位移,並列印位於該位移的資料。
導致輸入還原序列化錯誤的其他常見原因如下:
- 整數資料行的值大於 9223372036854775807。
- 字串,而不是物件陣列或新行分隔物件。 有效的範例:[{'a':1}]。 不正確的範例:"'a' :1"。
- 在作業中使用 Avro 格式的事件中樞擷取 Blob 作為輸入。
- 在單一輸入事件中有兩個資料行,只有大小寫不同。 範例:column1 和 COLUMN1。
分割計數變更
事件中樞的分割計數可以變更。 如果事件中樞的分割計數已變更,就必須停止並重新啟動串流分析作業。
當作業執行時,事件中樞的分割計數變更時,會顯示下列錯誤。 Microsoft.Streaming.Diagnostics.Exceptions.InputPartitioningChangedException
作業超過事件中樞接收器上限
使用事件中樞的最佳做法是使用多個取用者群組,以確保作業可擴縮性。 在特定輸入的串流分析作業中,其讀取器數量會影響單一取用者群組中的讀取器數量。 接收器精確數量會以相應放大拓撲邏輯的內部實作詳細資料為基礎,並且不會對外公開。 讀取器數量會在作業開始時或作業升級期間變更。
當接收器數目超過上限時,會顯示下列錯誤訊息。 錯誤訊息包含對取用者群組底下之事件中樞所進行的現有連線清單。 AzureStreamAnalytics 標籤會指出連線是來自 Azure 串流服務。
The streaming job failed: Stream Analytics job has validation errors: Job will exceed the maximum amount of Event Hubs Receivers.
The following information may be helpful in identifying the connected receivers: Exceeded the maximum number of allowed receivers per partition in a consumer group which is 5. List of connected receivers –
AzureStreamAnalytics_c4b65e4a-f572-4cfc-b4e2-cf237f43c6f0_1,
AzureStreamAnalytics_c4b65e4a-f572-4cfc-b4e2-cf237f43c6f0_1,
AzureStreamAnalytics_c4b65e4a-f572-4cfc-b4e2-cf237f43c6f0_1,
AzureStreamAnalytics_c4b65e4a-f572-4cfc-b4e2-cf237f43c6f0_1,
AzureStreamAnalytics_c4b65e4a-f572-4cfc-b4e2-cf237f43c6f0_1.
注意
如果在作業升級期間變更讀取器數量,暫時性警告會寫入稽核記錄中。 串流分析作業會從這些暫時性問題中自動復原。
在事件中樞新增取用者群組
若要在事件中樞執行個體中新增新的取用者群組,請遵循下列步驟:
登入 Azure 入口網站。
找到您的事件中樞。
選取 [實體] 標題下方的 [事件中樞]。
依名稱選取事件中樞。
在 [事件中樞執行個體] 頁面上,[實體] 標題下方,選取 [取用者群組]。 隨即列出名為 $Default 的取用者群組。
選取 [+ 取用者群組] 以新增取用者群組。
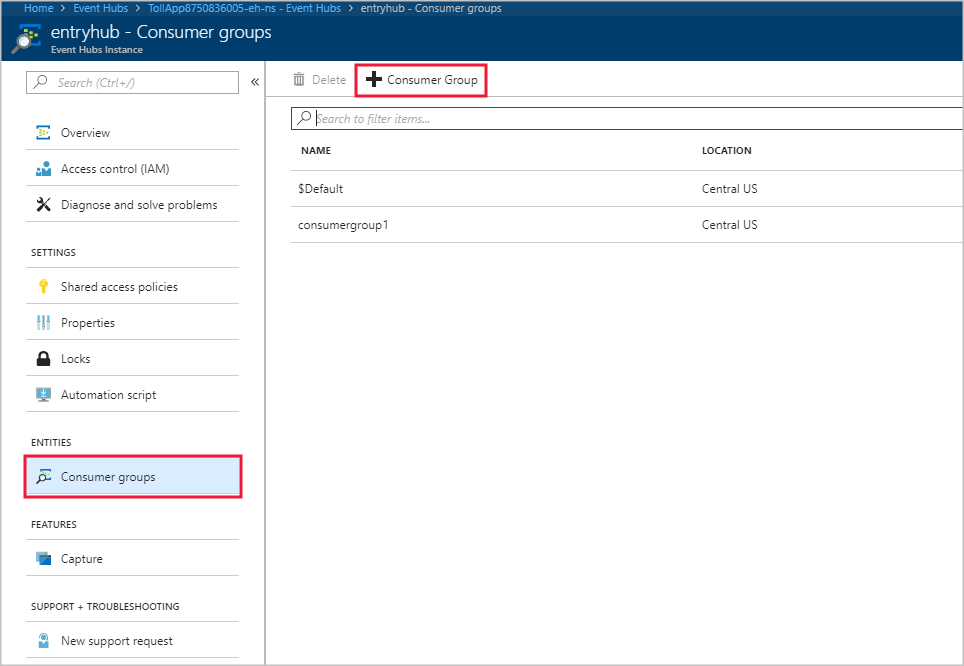
當您在串流分析作業中建立輸入以指向事件中樞時,您已指定取用者群組。 $Default 用於未指定任何項目時。 一旦您建立新的取用者群組後,請在串流分析作業中編輯事件中樞輸入,並指定新取用者群組的名稱。
每個分割區的讀取器超過事件中樞上限
如果串流查詢語法參考相同的輸入事件中樞資源多次,則作業引擎可以為相同取用者群組中的每個查詢使用多個讀取器。 當對同一個取用者群組有過多參考時,作業會超過五個的限制,並且擲回錯誤。 在這些狀況下,您可以使用下節中所述的解決方案,在多個取用者群組之間使用多個輸入,藉此進一步地分割。
讀取器數量 (每個分割區) 超過事件中樞上限 (5 個) 的情況如下:
多個 SELECT 陳述式︰ 如果您使用多個 SELECT 陳述式參照相同的事件中樞輸入,則每個 SELECT 陳述式皆會造成新的接收器建立。
UNION︰當您使用 UNION 時,就有可能會有多個輸入參照相同的事件中樞和取用者群組。
SELF JOIN︰當您使用 SELF JOIN 作業時,就可能發生參照相同事件中樞多次的情形。
以下最佳做法可減少讀取器數量 (每個分割區) 超過事件中樞上限 (5 個) 的情況。
使用 WITH 子句將查詢分割成多個步驟
WITH 子句會指定名為結果集的暫存,並且可由查詢中的 FROM 子句加以參照。 您可以定義單一 SELECT 陳述式執行範圍的 WITH 子句。
例如,不要使用此查詢︰
SELECT foo
INTO output1
FROM inputEventHub
SELECT bar
INTO output2
FROM inputEventHub
…
改為使用此查詢:
WITH data AS (
SELECT * FROM inputEventHub
)
SELECT foo
INTO output1
FROM data
SELECT bar
INTO output2
FROM data
…
請確定這些輸入會繫結至不同的取用者群組
如果查詢中有三個以上的輸入與同一個事件中樞取用者群組連線,請建立個別的取用者群組。 這需要建立其他串流分析輸入。
使用不同的取用者群組建立不同的輸入
您可以為相同的事件中樞建立具有不同取用者群組的個別輸入。 以下為 UNION 查詢範例,其中 InputOne 和 InputTwo 參考相同的事件中樞來源。 任何查詢都可以使用具有不同取用者群組的個別輸入。 UNION 查詢只是一個範例。
WITH
DataOne AS
(
SELECT * FROM InputOne
),
DataTwo AS
(
SELECT * FROM InputTwo
),
SELECT foo FROM DataOne
UNION
SELECT foo FROM DataTwo
每個分割區的讀取器數目超過 IoT 中樞限制
串流分析作業使用 IoT 中樞的內建事件中樞相容端點,從 IoT 中樞連線和讀取事件。 如果您的每個分割區讀取數超過 IoT 中樞的限制,您可以使用事件中樞的解決方案來解決此問題。 您可以透過 IoT 中樞入口網站端點工作階段或 IoT 中樞 SDK,為內建端點建立取用者群組。
取得協助
如需進一步的協助,請嘗試 Azure 串流分析的 Microsoft 問與答頁面。