使用串流分析無程式碼編輯器,篩選及擷取至 Azure Synapse SQL
本文描述如何使用無程式碼編輯器,輕鬆建立串流分析作業。 它會從事件中樞持續讀取、篩選傳入資料,然後將結果持續寫入 Synapse SQL 資料表。
必要條件
- 您的 Azure 事件中樞資源必須可公開存取,且不可位於防火牆後方或在 Azure 虛擬網路中受保護。
- 事件中樞中的資料必須以 JSON、CSV 或 Avro 格式序列化。
開發串流分析作業以篩選和擷取資料
使用下列步驟開發串流分析作業,將即時資料篩選和擷取至 Synapse SQL 資料表。
在 Azure 入口網站中,找出並選取您的 Azure 事件中樞執行個體。
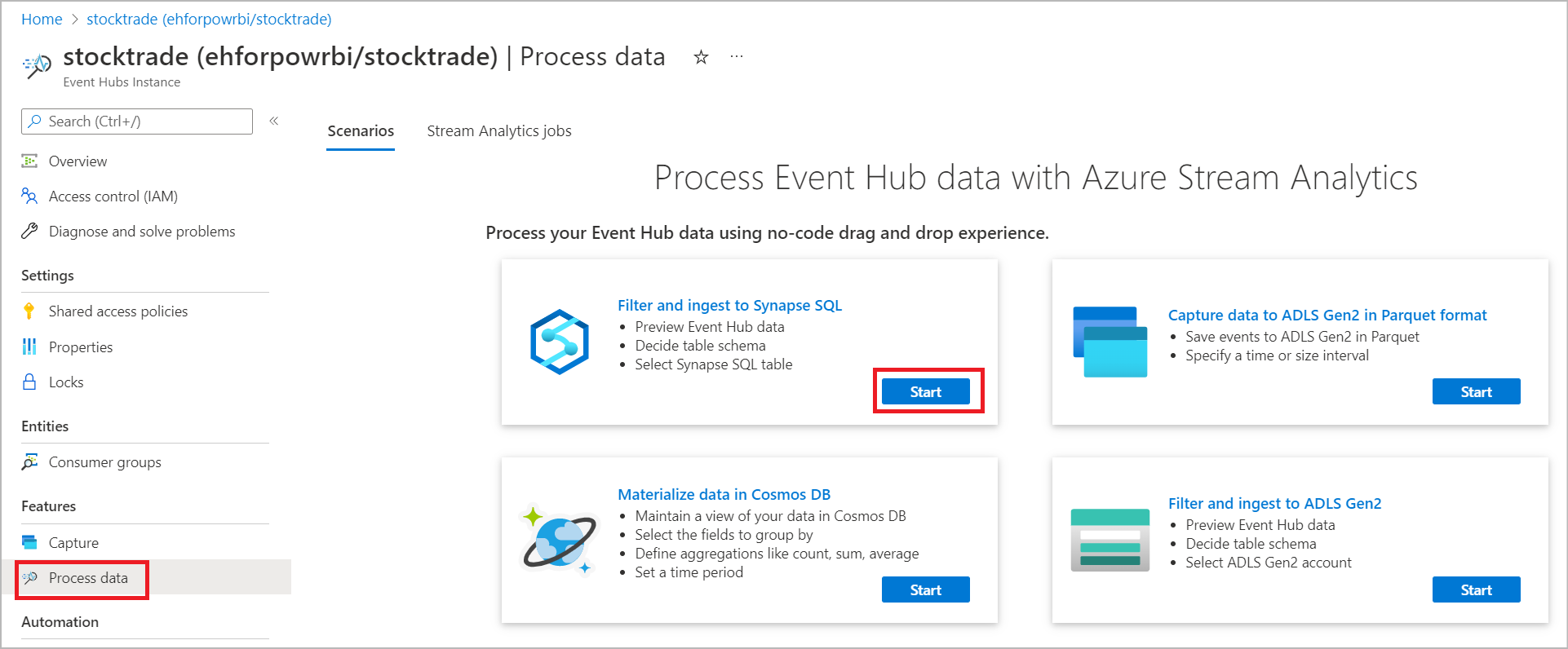
選取[功能]>[處理資料],並於 [篩選及擷取至 Synapse SQL] 卡片上選取 [開始]。
輸入名稱以識別串流分析作業,並選取 [建立]。
![顯示您輸入作業名稱之 [新增串流分析作業] 視窗的螢幕快照。](media/filter-ingest-synapse-sql/create-new-stream-analytics-job.png)
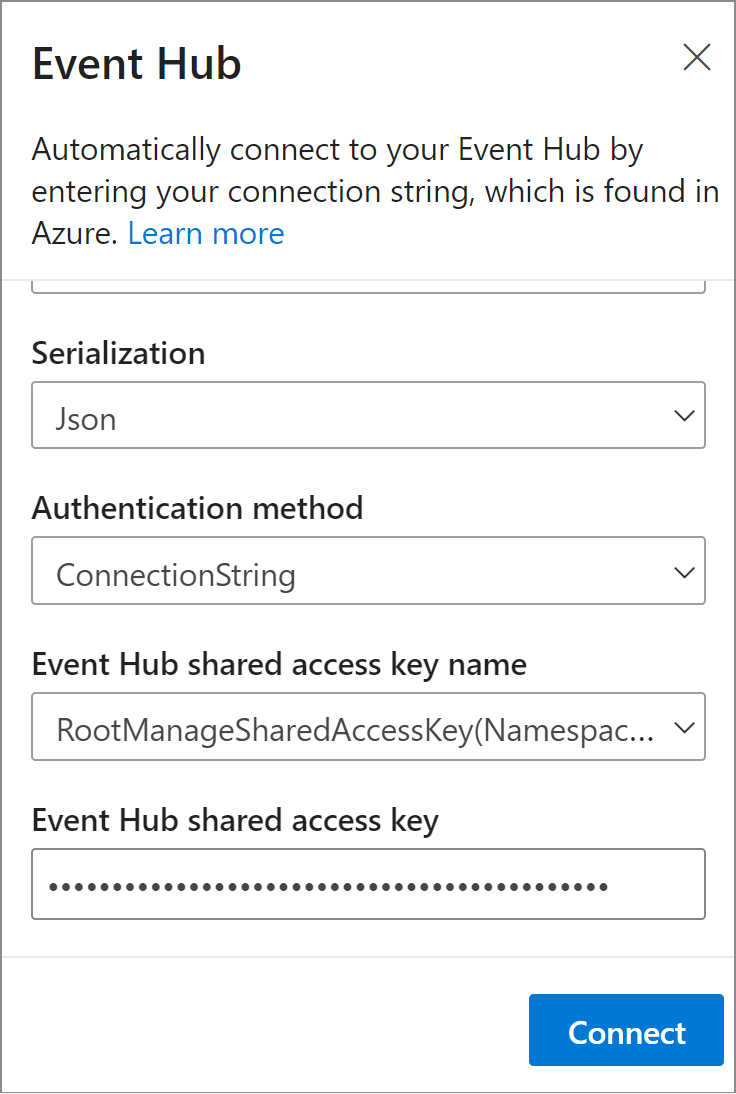
在 [事件中樞] 視窗中指定資料的 [序列化] 類型,以及作業要用於連線至事件中樞的 [驗證方法]。 然後選取 [連線]。
當連線成功,且有資料流量流向事件中樞執行個體,便可立即看到兩個項目:
- 輸入資料中的欄位。 您可選擇 [新增欄位],或選取欄位旁的三個點符號,以移除、重新命名或變更其類型。
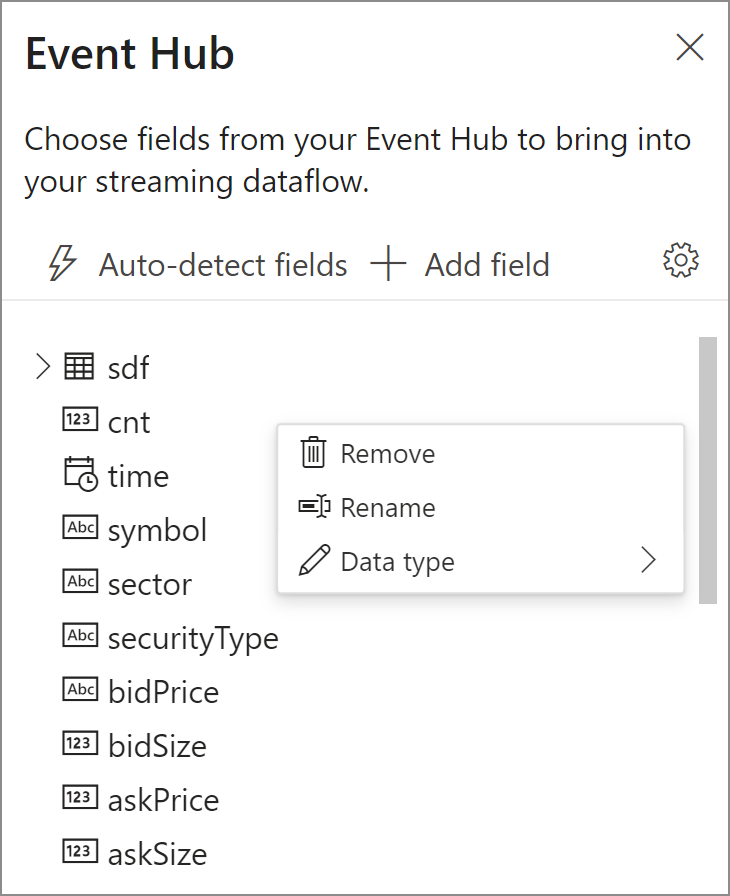
- 傳入資料的即時範例,位於 [資料預覽] 資料表的圖表檢視下。 此項目會定期自動重新整理。 您可選取 [暫停串流預覽],以查看範例輸入資料的靜態檢視。
![顯示 [數據預覽] 底下範例數據的螢幕快照。](media/filter-ingest-synapse-sql/no-code-sample-input.png)
- 輸入資料中的欄位。 您可選擇 [新增欄位],或選取欄位旁的三個點符號,以移除、重新命名或變更其類型。
在 [篩選] 區域中,選取欄位以篩選具有條件的傳入資料。
![此螢幕快照顯示 [篩選] 區域,您可以在其中篩選具有條件的傳入數據。](media/filter-ingest-synapse-sql/no-code-filter-data.png)
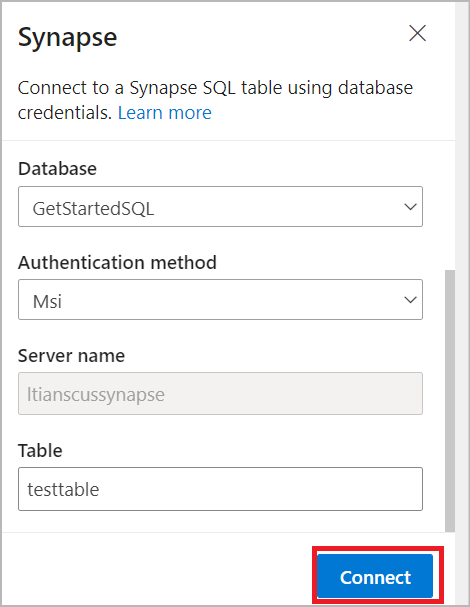
選取 Synapse SQL 資料表,以傳送篩選的資料:
- 從下拉式功能表選取 [訂用帳戶]、[資料庫 (專用 SQL 集區名稱)] 和 [驗證方法]。
- 輸入要擷取篩選資料的資料表名稱。 選取 Connect。
注意
該資料表結構描述應完全符合資料預覽所產生的欄位數目及其類型。
您也可選取 [取得靜態預覽/重新整理靜態預覽],查看所選 Synapse SQL 資料表中待擷取資料的預覽。
![顯示 [取得靜態預覽/重新整理靜態預覽] 選項的螢幕快照。](media/filter-ingest-synapse-sql/no-code-synapse-static-preview.png)
選取 [儲存],並選取 [啟動] 串流分析作業。
![顯示 [儲存] 和 [開始] 選項的螢幕快照。](media/filter-ingest-synapse-sql/no-code-save-start.png)
若要啟動作業,請指定:
- 作業執行時的串流單位 (SU) 數目。 SU 代表配置給作業的計算和記憶體數量。 建議先使用三個,再視需要調整。
- 輸出資料錯誤處理 – 可讓您指定資料發生錯誤後作業輸出至目的地失敗時的期望行為。 依預設,您的作業會重試,直到寫入作業成功為止。 您也可選擇捨棄這類輸出事件。
![顯示 [開始串流分析] 作業選項的螢幕快照,您可以在其中變更輸出時間、設定串流單位數目,然後選取 [輸出數據錯誤處理選項]。](media/filter-ingest-synapse-sql/no-code-start-job.png)
選取 [啟動] 之後,作業會在兩分鐘內開始執行,且計量會在下方的索引標籤區段中開啟。
您也可以在 [串流分析作業] 索引標籤的 [處理資料] 區段下看到作業。選取 [開啟計量] 以進行監視,或視需要停止並重新啟動。
![[串流分析作業] 索引標籤的螢幕快照,您可以在其中檢視執行中的作業狀態。](media/filter-ingest-synapse-sql/no-code-list-jobs.png)

![顯示您輸入作業名稱之 [新增串流分析作業] 視窗的螢幕快照。](media/filter-ingest-synapse-sql/create-new-stream-analytics-job.png#lightbox)


![顯示 [數據預覽] 底下範例數據的螢幕快照。](media/filter-ingest-synapse-sql/no-code-sample-input.png#lightbox)
![此螢幕快照顯示 [篩選] 區域,您可以在其中篩選具有條件的傳入數據。](media/filter-ingest-synapse-sql/no-code-filter-data.png#lightbox)

![顯示 [取得靜態預覽/重新整理靜態預覽] 選項的螢幕快照。](media/filter-ingest-synapse-sql/no-code-synapse-static-preview.png#lightbox)
![顯示 [儲存] 和 [開始] 選項的螢幕快照。](media/filter-ingest-synapse-sql/no-code-save-start.png#lightbox)
![顯示 [開始串流分析] 作業選項的螢幕快照,您可以在其中變更輸出時間、設定串流單位數目,然後選取 [輸出數據錯誤處理選項]。](media/filter-ingest-synapse-sql/no-code-start-job.png#lightbox)
![[串流分析作業] 索引標籤的螢幕快照,您可以在其中檢視執行中的作業狀態。](media/filter-ingest-synapse-sql/no-code-list-jobs.png#lightbox)
使用事件中樞異地復寫功能的考慮
Azure 事件中樞 最近啟動公開預覽版中的異地復寫功能。 這項功能與 Azure 事件中樞的異地災害復原功能不同。
當故障轉移類型為強制且復寫一致性為異步時,串流分析作業不保證輸出至 Azure 事件中樞 輸出。
Azure 串流分析,作為 具有事件中樞輸出的產生者 ,可能會在故障轉移期間和事件中樞節流期間觀察到作業的浮水印延遲,以防主要和次要之間的複寫延遲達到設定的延遲上限。
Azure 串流分析,作為 事件中樞作為輸入的取用者 ,可能會在故障轉移期間觀察作業的浮浮水印延遲,而且可能會在故障轉移完成後略過數據或尋找重複的數據。
由於這些注意事項,建議您在事件中樞故障轉移完成之後,立即以適當的開始時間重新啟動串流分析作業。 此外,由於事件中樞異地復寫功能處於公開預覽狀態,因此目前不建議將此模式用於生產串流分析作業。 在事件中樞異地復寫功能正式推出之前,目前的串流分析行為將會改善,並可用於串流分析生產作業。
下一步
深入了解 Azure 串流分析,以及如何監視所建立的作業。