教學課程:建立電話號碼的自訂分析器
在搜尋解決方案中,具有複雜模式或特殊字元的字串可能會是一項挑戰,因為預設分析器會去除模式有意義的部分或對這些部分錯誤解譯,而導致使用者在找不到預期的資訊時,搜尋體驗不佳。 電話號碼是難以分析字串的傳統範例。 其會以各種格式提供,且包含預設分析器忽略的特殊字元。
本教學課程使用電話號碼做為其主題,仔細查看模式資料的問題,並示範如何使用自訂分析器解決這個問題。 此處所述的方法可現況用於電話號碼,或針對具有相同特性的欄位 (例如 URL、電子郵件、郵遞區號和日期) 進行調整。
在本教學課程中,您會使用 REST 用戶端和 Azure AI 搜尋服務 REST API 來:
- 了解問題
- 開發處理電話號碼的初始自訂分析器
- 測試自訂分析器
- 逐一查看自訂分析器設計,以進一步改善結果
必要條件
本教學課程需要下列服務和工具。
具有 REST 用戶端 (英文) 的 Visual Studio Code (英文)
Azure AI 搜尋服務 (部分機器翻譯) 在您的目前訂用帳戶下建立或尋找現有的 Azure AI 搜尋服務資源。 您可以使用本快速入門的免費服務。
下載檔案
本教學課程的原始程式碼位於 Azure-Samples/azure-search-rest-samples GitHub 存放庫的 custom-analyzer.rest 檔案中。
複製金鑰和 URL
本教學課程中的 REST 呼叫需要搜尋服務端點和系統管理 API 金鑰。 您可以從 Azure 入口網站取得這些值。
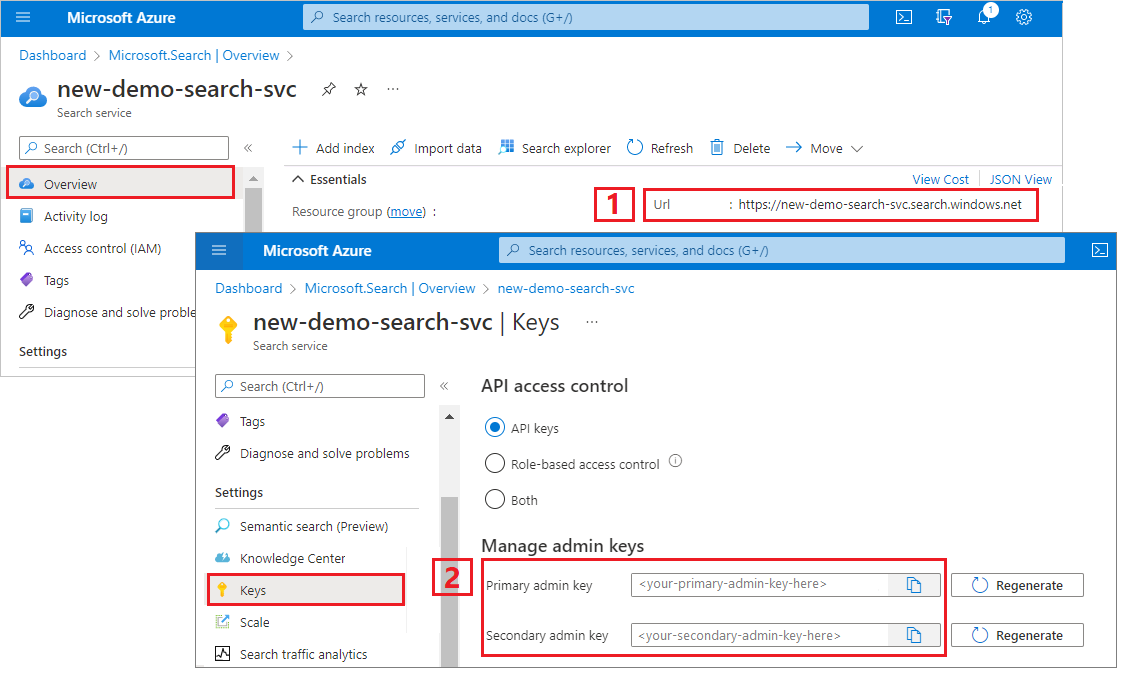
登入 Azure 入口網站,流覽至 [概觀] 頁面,然後複製 URL。 範例端點看起來會像是
https://mydemo.search.windows.net。在 [設定 > 金鑰] 下面,複製系統管理金鑰。 系統管理金鑰可用來新增、修改和刪除物件。 有兩個可交換的系統管理密鑰。 複製任一個。
有效的 API 金鑰能為每個要求在傳送要求之應用程式與處理要求的搜尋服務間建立信任。
建立初始索引
在 Visual Studio Code 中開啟新的文字檔。
將變數設定為您在上一個步驟中收集到的搜尋端點和 API 金鑰。
@baseUrl = PUT-YOUR-SEARCH-SERVICE-URL-HERE @apiKey = PUT-YOUR-ADMIN-API-KEY-HERE使用
.rest檔案副檔名來儲存檔案。貼上下列範例,以建立名為
phone-numbers-index且具有兩個欄位的小型索引:id和phone_number。 我們尚未定義分析器,因此預設會使用standard.lucene分析器。### Create a new index POST {{baseUrl}}/indexes?api-version=2024-07-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "name": "phone-numbers-index", "fields": [ { "name": "id", "type": "Edm.String", "key": true, "searchable": true, "filterable": false, "facetable": false, "sortable": true }, { "name": "phone_number", "type": "Edm.String", "sortable": false, "searchable": true, "filterable": false, "facetable": false } ] }選取 [傳送要求]。 您應該會得到
HTTP/1.1 201 Created回應,且回應本文中應該會包含以 JSON 表示的索引結構描述。使用包含各種電話號碼格式的文件,將資料載入索引中。 這是您的測試資料。
### Load documents POST {{baseUrl}}/indexes/phone-numbers-index/docs/index?api-version=2024-07-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "value": [ { "@search.action": "upload", "id": "1", "phone_number": "425-555-0100" }, { "@search.action": "upload", "id": "2", "phone_number": "(321) 555-0199" }, { "@search.action": "upload", "id": "3", "phone_number": "+1 425-555-0100" }, { "@search.action": "upload", "id": "4", "phone_number": "+1 (321) 555-0199" }, { "@search.action": "upload", "id": "5", "phone_number": "4255550100" }, { "@search.action": "upload", "id": "6", "phone_number": "13215550199" }, { "@search.action": "upload", "id": "7", "phone_number": "425 555 0100" }, { "@search.action": "upload", "id": "8", "phone_number": "321.555.0199" } ] }讓我們嘗試一些類似於使用者可能輸入的查詢。 使用者可以使用任何格式來搜尋
(425) 555-0100,而仍應該會傳回結果。 一開始先搜尋(425) 555-0100:### Search for a phone number GET {{baseUrl}}/indexes/phone-numbers-index/docs/search?api-version=2024-07-01&search=(425) 555-0100 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}}查詢傳回了四個預期結果中的三個,但也傳回了兩個非預期的結果:
{ "value": [ { "@search.score": 0.05634898, "phone_number": "+1 425-555-0100" }, { "@search.score": 0.05634898, "phone_number": "425 555 0100" }, { "@search.score": 0.05634898, "phone_number": "425-555-0100" }, { "@search.score": 0.020766128, "phone_number": "(321) 555-0199" }, { "@search.score": 0.020766128, "phone_number": "+1 (321) 555-0199" } ] }讓我們不使用任何格式設定再試一次:
4255550100。### Search for a phone number GET {{baseUrl}}/indexes/phone-numbers-index/docs/search?api-version=2024-07-01&search=4255550100 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}}此查詢的表現更差,僅傳回四個正確相符項目的其中一個。
{ "value": [ { "@search.score": 0.6015292, "phone_number": "4255550100" } ] }
如果您發現這些結果令人困惑,那麼您並不孤單。 在下一節中,我們將深入探討為何會獲得這些結果。
檢閱分析器的運作方式
若要了解這些搜尋結果,我們必須了解分析器正在執行的動作。 從這裡,我們可以使用分析 API 來測試預設分析器,並提供符合我們需求的分析器。
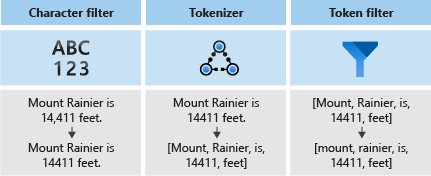
「分析器」是全文搜尋引擎的元件,負責查詢字串和已編製索引文件中的文字處理。 視案例而定,不同的分析器會以不同的方式處理文字。 在此案例中,我們需要建置專門用於電話號碼的分析器。
分析器由三個元件組成︰
在下圖中,您可以看到這三個元件如何合作將句子化為權杖:
然後,這些權杖會儲存在反向索引中,以實現快速的全文檢索搜尋。 反向索引會將在語彙分析期間擷取的所有唯一詞彙對應到其發生所在的文件,以實現全文檢索搜尋。 您可以在下一個圖表中看到範例:

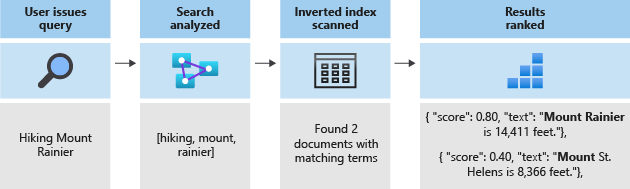
所有搜尋都會往下一路搜尋儲存在反向索引中的詞彙。 當使用者發出查詢時:
- 系統會剖析查詢並分析查詢詞彙。
- 接著,會掃描反向索引,以尋找具有相符詞彙的文件。
- 最後,所擷取的文件會依照評分演算法排序。
如果查詢詞彙不符合反向索引中的詞彙,則不會傳回結果。 若要深入了解查詢的運作方式,請參閱關於全文檢索搜尋的這篇文章。
注意
部分詞彙查詢是此規則的重要例外狀況。 與一般詞彙查詢不同,這些查詢 (前置詞查詢、萬用字元查詢、RegEx 查詢) 會略過語彙分析程序。 在與索引中的詞彙進行比對之前,部分詞彙只會是小寫狀態。 如果分析器未設定為支援這些類型的查詢,您往往會收到非預期的結果,因為索引中不存在相符的詞彙。
使用分析 API 測試分析器
Azure AI 搜尋服務提供分析 API,可讓您測試分析器以了解其如何處理文字。
您可以使用下列要求來呼叫分析 API:
POST {{baseUrl}}/indexes/phone-numbers-index/analyze?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"text": "(425) 555-0100",
"analyzer": "standard.lucene"
}
API 會使用您指定的分析器,傳回從文字擷取的權杖。 標準的 Lucene 分析器會將電話號碼分割成三個不同權杖:
{
"tokens": [
{
"token": "425",
"startOffset": 1,
"endOffset": 4,
"position": 0
},
{
"token": "555",
"startOffset": 6,
"endOffset": 9,
"position": 1
},
{
"token": "0100",
"startOffset": 10,
"endOffset": 14,
"position": 2
}
]
}
相反地,格式化為沒有任何標點符號的電話號碼 4255550100 則會權杖化為單一權杖。
{
"text": "4255550100",
"analyzer": "standard.lucene"
}
回應:
{
"tokens": [
{
"token": "4255550100",
"startOffset": 0,
"endOffset": 10,
"position": 0
}
]
}
請記住,系統會同時對查詢詞彙和已編制索引的文件進行分析。 回想一下上一個步驟中的搜尋結果,我們可以開始查看為何系統會傳回這些結果。
在第一個查詢中,傳回非預期的電話號碼,因為其中一個權杖 555 符合我們所搜尋的其中一個詞彙。 在第二個查詢中,系統只傳回一個數字,因為這個數字是唯一有權杖符合 4255550100 的記錄。
建置自訂分析器
我們已經了解所看到的結果,接下來讓我們建置自訂分析器來改善權杖化邏輯。
我們的目標是要針對電話號碼提供直覺式的搜尋,而不論查詢或索引字串的格式為何。 為了達成這個結果,我們將指定字元篩選器、權杖化工具和權杖篩選器。
字元篩選
可先使用字元篩選器處理文字,然後再將文字送到權杖化工具。 字元篩選器的常見用法包括篩選出 HTML 元素或取代特殊字元。
對於電話號碼,我們想要移除空白字元和特殊字元,因為並非所有的電話號碼格式都包含同樣的特殊字元和空格。
"charFilters": [
{
"@odata.type": "#Microsoft.Azure.Search.MappingCharFilter",
"name": "phone_char_mapping",
"mappings": [
"-=>",
"(=>",
")=>",
"+=>",
".=>",
"\\u0020=>"
]
}
]
篩選器會從輸入中移除 -()+. 和空格。
| 輸入 | 輸出 |
|---|---|
(321) 555-0199 |
3215550199 |
321.555.0199 |
3215550199 |
權杖化工具
權杖化工具會在過程中將文字分割成多個權杖,並捨棄一些字元,例如標點符號。 在許多情況下,權杖化的目標是要將句子分割成個別單字。
針對此案例,我們會使用關鍵字權杖化工具 keyword_v2,因為我們想要將電話號碼擷取為單一詞彙。 請注意,這不是解決此問題的唯一方法。 請參閱下面的替代方法一節。
在獲得相同文字時,關鍵字權杖化工具一律會將其輸出為單一詞彙。
| 輸入 | 輸出 |
|---|---|
The dog swims. |
[The dog swims.] |
3215550199 |
[3215550199] |
權杖篩選
權杖篩選器會篩選出或修改權杖化工具所產生的權杖。 權杖篩選器的其中一個常見用法是使用小寫權杖篩選器將所有字元設為小寫。 另一個常見用法是篩除 the、and 或 is 等停用字詞。
雖然我們不需要在此案例中使用任一篩選器,但我們會使用 nGram 權杖篩選器來實現電話號碼的部分搜尋。
"tokenFilters": [
{
"@odata.type": "#Microsoft.Azure.Search.NGramTokenFilterV2",
"name": "custom_ngram_filter",
"minGram": 3,
"maxGram": 20
}
]
NGramTokenFilterV2
nGram_v2 權杖篩選器會根據 minGram 和 maxGram 參數,將權杖分割成指定大小的 n 元。
就電話分析器而言,我們會將 minGram 設定為 3,因為這是我們希望使用者搜尋的最短子字串。
maxGram 會設定為 20 以確保所有電話號碼 (即使有分機) 都能夠放入單一 n 元。
n 元的副作用是會傳回一些誤判為真。 我們會在後續步驟中修正此問題,方法是為不包含 n 元權杖篩選器的搜尋建置不同的分析器。
| 輸入 | 輸出 |
|---|---|
[12345] |
[123, 1234, 12345, 234, 2345, 345] |
[3215550199] |
[321, 3215, 32155, 321555, 3215550, 32155501, 321555019, 3215550199, 215, 2155, 21555, 215550, ... ] |
分析器
準備好字元篩選器、權杖化工具和權杖篩選器之後,我們就可以定義分析器了。
"analyzers": [
{
"@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer",
"name": "phone_analyzer",
"tokenizer": "keyword_v2",
"tokenFilters": [
"custom_ngram_filter"
],
"charFilters": [
"phone_char_mapping"
]
}
]
在分析 API 中,假設有下列輸入,自訂分析器的輸出如下表中所示。
| 輸入 | 輸出 |
|---|---|
12345 |
[123, 1234, 12345, 234, 2345, 345] |
(321) 555-0199 |
[321, 3215, 32155, 321555, 3215550, 32155501, 321555019, 3215550199, 215, 2155, 21555, 215550, ... ] |
輸出資料行中的所有權杖都存在於索引中。 如果我們的查詢包含這些詞彙的任何一項,則會傳回電話號碼。
使用新的分析器重建
刪除目前的索引:
### Delete the index DELETE {{baseUrl}}/indexes/phone-numbers-index?api-version=2024-07-01 HTTP/1.1 api-key: {{apiKey}}使用新的分析器重新建立索引。 此索引結構描述會新增自訂分析器定義,以及電話號碼欄位上的自訂分析器指派。
### Create a new index POST {{baseUrl}}/indexes?api-version=2024-07-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "name": "phone-numbers-index-2", "fields": [ { "name": "id", "type": "Edm.String", "key": true, "searchable": true, "filterable": false, "facetable": false, "sortable": true }, { "name": "phone_number", "type": "Edm.String", "sortable": false, "searchable": true, "filterable": false, "facetable": false, "analyzer": "phone_analyzer" } ], "analyzers": [ { "@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer", "name": "phone_analyzer", "tokenizer": "keyword_v2", "tokenFilters": [ "custom_ngram_filter" ], "charFilters": [ "phone_char_mapping" ] } ], "charFilters": [ { "@odata.type": "#Microsoft.Azure.Search.MappingCharFilter", "name": "phone_char_mapping", "mappings": [ "-=>", "(=>", ")=>", "+=>", ".=>", "\\u0020=>" ] } ], "tokenFilters": [ { "@odata.type": "#Microsoft.Azure.Search.NGramTokenFilterV2", "name": "custom_ngram_filter", "minGram": 3, "maxGram": 20 } ] }
測試自訂分析器
在重新建立索引後,您現在可以使用下列要求來測試分析器:
POST {{baseUrl}}/indexes/tutorial-first-analyzer/analyze?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"text": "+1 (321) 555-0199",
"analyzer": "phone_analyzer"
}
您現在應該會看到電話號碼產生的權杖集合:
{
"tokens": [
{
"token": "132",
"startOffset": 1,
"endOffset": 17,
"position": 0
},
{
"token": "1321",
"startOffset": 1,
"endOffset": 17,
"position": 0
},
{
"token": "13215",
"startOffset": 1,
"endOffset": 17,
"position": 0
},
...
...
...
]
}
修改自訂分析器以處理誤判
使用自訂分析器對索引進行一些範例查詢之後,您會發現重新叫用已改善,而且現在會傳回所有相符的電話號碼。 不過,n 元權杖篩選器也會導致傳回一些誤判為真。 這是 n 元權杖篩選器的常見副作用。
為了避免誤判為真,我們會建立不同的查詢分析器。 此分析器與上一個分析器相同,不同之處在於其會省略custom_ngram_filter。
{
"@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer",
"name": "phone_analyzer_search",
"tokenizer": "custom_tokenizer_phone",
"tokenFilters": [],
"charFilters": [
"phone_char_mapping"
]
}
在索引定義中,我們接著會同時指定 indexAnalyzer 和 searchAnalyzer。
{
"name": "phone_number",
"type": "Edm.String",
"sortable": false,
"searchable": true,
"filterable": false,
"facetable": false,
"indexAnalyzer": "phone_analyzer",
"searchAnalyzer": "phone_analyzer_search"
}
完成此變更後,您就已準備就緒。 以下是後續步驟:
刪除索引。
在新增自訂分析器 (
phone_analyzer-search) 並將該分析器指派給phone-number欄位的searchAnalyzer屬性之後,重新建立索引。重新載入資料。
重新測試查詢,以確認搜尋如預期般運作。 如果您使用範例檔案,此步驟會建立名為
phone-number-index-3的第三個索引。
替代方法
上一節中所述的分析器設計旨在將搜尋的彈性最大化。 不過,這樣做的代價是,索引中會儲存許多可能不重要的詞彙。
下列範例顯示替代分析器,在 Token 化方面更有效率,但仍有缺點。
假設輸入 14255550100,分析器無法以邏輯方式將電話號碼區塊化。 例如,其無法將國碼 (地區碼) (1) 與區碼 (425) 進行區隔。 如果使用者未在其搜尋中包含國碼 (地區碼),這項差異會導致系統未傳回電話號碼。
"analyzers": [
{
"@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer",
"name": "phone_analyzer_shingles",
"tokenizer": "custom_tokenizer_phone",
"tokenFilters": [
"custom_shingle_filter"
]
}
],
"tokenizers": [
{
"@odata.type": "#Microsoft.Azure.Search.StandardTokenizerV2",
"name": "custom_tokenizer_phone",
"maxTokenLength": 4
}
],
"tokenFilters": [
{
"@odata.type": "#Microsoft.Azure.Search.ShingleTokenFilter",
"name": "custom_shingle_filter",
"minShingleSize": 2,
"maxShingleSize": 6,
"tokenSeparator": ""
}
]
您在下列範例中可以看到,電話號碼會分割成您一般會希望使用者搜尋的區塊。
| 輸入 | 輸出 |
|---|---|
(321) 555-0199 |
[321, 555, 0199, 321555, 5550199, 3215550199] |
根據您的需求,這可能是更有效率的問題解決方法。
重要心得
本教學課程示範了用來建置和測試自訂分析器的程序。 您已建立索引、為資料編制索引,然後針對索引進行查詢,以查看傳回的搜尋結果。 您從該處使用了分析 API 來查看語彙分析程序的實際運作過程。
雖然本教學課程中定義的分析器提供了簡單的解決方案來針對電話號碼進行搜尋,但您也可以使用同樣的程序來為共用類似特性的任何案例建立自訂分析器。
清除資源
如果您使用自己的訂用帳戶,當專案結束時,建議您移除不再需要的資源。 資源若繼續執行,將需付費。 您可以個別刪除資源,或刪除資源群組以刪除整組資源。
您可以使用左側瀏覽窗格中的 [所有資源] 或 [資源群組] 連結,在 Azure 入口網站 中找到和管理資源。
下一步
您已經熟悉如何建立自訂分析器,接下來讓我們看看可供您建置豐富搜尋體驗的各種不同篩選器、權杖化工具和分析器。