Azure AI 搜尋服務中的語意排名
在 Azure AI 搜尋服務中,語意排名工具是一項功能,可量化地改善搜尋相關性,方法是使用 Microsoft 的語言理解模型來對搜尋結果重新排名。 本文是一個高階簡介,可協助您瞭解語意排名工具的行為和優點。
語意排名工具是依使用量收費的進階功能。 建議您以本文為背景概念,但如果您想要開始使用,請依照下列步驟操作。
注意
語意排名工具不會使用生成式 AI 或向量。 如果您要尋找向量和相似度搜尋,請參閱 Azure AI 搜尋 中的向量搜尋以取得詳細數據。
什麼是語意排名?
語意排名工具是查詢端功能的集合,可改善文字型查詢、向量查詢和混合式查詢的初始 BM25 排名或 RRF 排名搜尋結果的品質。 當您在搜尋服務上啟用此功能時,語意排名會以兩種方式延伸查詢執行管線:
首先,它會在使用 BM25 或倒數排名融合 (RRF) 評分的初始結果集上新增次要排名。 此次要排名使用改寫自 Microsoft Bing 的多語種深度學習模型,以提升語意上最相關的結果。
其次,會擷取並傳回回應中的標題和答案,您可以在搜尋頁面上轉譯這些內容,以改善使用者的搜尋體驗。
以下是語意重新排名工具的功能。
| 功能 | 描述 |
|---|---|
| L2 排名 | 使用查詢的情境內容或語意意義,計算預先排名結果的新相關性分數。 |
| 語意標題和醒目提示 | 從最能摘要內容的欄位中擷取逐字句子和片語,並醒目提示重要段落以便輕鬆瀏覽。 當個別內容欄位對搜尋結果頁面而言太密集時,摘要結果的標題很有用。 醒目提示的文字可提升最相關的字詞和片語,讓使用者可以快速判斷為何將相符項目視為相關。 |
| 語意答案 | 從語意查詢傳回的選擇性和額外子結構。 為看起來像是問題的查詢提供直接答案。 需要含有具答案特性文字的文件。 |
語意排名工具的運作方式
語意排名工具會將查詢和結果饋送至 Microsoft 裝載的語言理解模型,並掃描以取得更好的相符項目。
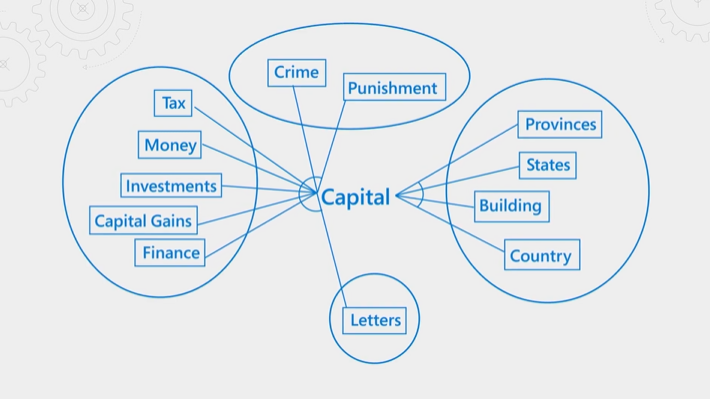
下圖說明相關概念。 請考慮「資本」一詞。 根據內容是否與金融、法律、地理或文法相關,這個詞會有不同的意義。 透過語言理解,語意排名工具可以偵測內容,並提升符合查詢意圖的結果。
語意排名同時很耗費資源和時間。 為了在查詢作業的預期延遲內完成處理,我們合併和減少語意排名工具的輸入,以儘快完成重新排名步驟。
語意排名有三個步驟:
- 收集並摘要輸入
- 使用語意排名工具來評分結果
- 輸出重新評分的結果、標題和答案
如何收集及摘要輸入
在語意排名中,查詢子系統會將搜尋結果作為輸入傳遞至摘要和排名模型。 由於排名模型具有輸入大小限制,且需要大量處理,因此必須對搜尋結果進行大小調整和結構化 (摘要) 以便有效率地處理。
語意排名工具從文字查詢的 BM25 排名結果或向量或混合式查詢的 RRF 排名結果開始。 重新排名練習中只會使用文字欄位,而且只有前 50 個結果會進入語意排名,即使包含超過 50 個結果也不例外。 一般而言,語意排名中使用的是資訊欄位和描述性欄位。
對於搜尋結果中的每個文件,摘要模型最多接受 2,000 個語彙基元,其中一個語彙基元大約是 10 個字元。 輸入由語意設定中列出的 "title"、"keyword" 和 "content" 欄位組合而成。
任何過長字串都會遭修剪,以確保整體長度符合摘要步驟的輸入需求。 正是因為這樣的修剪作業,所以需要依優先順序將欄位新增至語意設定。 如果文件很大,而且欄位有很多文字,則會忽略超出上限的任何內容。
語意欄位 語彙基元限制 "title" 128 個語彙基元 "keywords 128 個語彙基元 "content" 剩餘語彙基元 摘要輸出是每份文件的摘要字串,由每個欄位中最相關的資訊所組成。 摘要字串會傳送至排名工具進行評分,並傳送至機器閱讀理解模型以獲取標題和答案。
自 2024 年 11 月起,傳遞至語意排名器之每個產生的摘要字串長度上限為 2,048 個標記。 先前是256個令牌。
排名的評分方式
評分會透過標題完成,以及填入 2,048 標記長度之摘要字串的任何其他內容。
相對於提供的查詢,評估標題的概念和語意相關性。
根據指定查詢的文件語義相關性,將 @search.rerankerScore 指派給每個文件。 分數的範圍從 4 到 0 (高到低),分數越高表示相關性越高。
分數 意義 4.0 文件高度相關並完全回答問題,但段落可能包含與問題無關的額外文字。 3.0 文件相關,但缺乏可讓它便完整的詳細資料。 2.0 文件有些相關;它會部分回答問題,或只解決問題的某些層面。 1.0 文件與問題相關,並回答其中一小部分。 0.0 文件無關緊要。 相符項目會依分數遞減順序列出,並包含在查詢回應承載中。 承載包含答案、純文字和醒目提示的標題,以及您標示為可擷取或在 select 子句中指定的任何欄位。
注意
針對任何指定的查詢,@search.rerankerScore 的分佈可能會因為基礎結構層級的條件而呈現輕微的變化。 已知排名模型更新會影響散發。 基於這些原因,如果您要撰寫最低閾值的自訂程式碼,或為向量和混合式查詢設定閾值屬性,請不要讓限制變得太細微。
語意排名工具的輸出
機器閱讀理解模型會從每個摘要字串中找到最具代表性的段落。
輸出為:
文件的語意標題。 每個標題都有純文字版和醒目提示版,就每個文件而言通常少於 200 個字。
選擇性的語意答案,假設您指定
answers參數,查詢以問題形式提出,且在長字串中找到可能解答問題的段落。
標題和答案一律是來自索引的逐字文字。 此工作流程中沒有任何建立或撰寫新內容的生成式 AI 模型。
語意功能和限制
語意排名工具是較新的技術,因此請務必對其可以和無法辦到的事情設立期望值。 該工具可提供下列功能:
提升語意更接近原始查詢意圖的相符項目。
尋找用作標題和答案的字串。 標題和答案會在回應中傳回,並且能呈現在搜尋結果頁面上。
語意排名工具無法執行的動作是對整個主體重新執行查詢以尋找語意相關的結果。 語意排名會將現有的結果集重新排名,由預設排名演算法評分的前 50 個結果組成。 此外,語意排名工具無法建立新的資訊或字串。 系統會逐字從內容擷取標題和答案,因此如果結果不包含類似答案的文字,語言模型並不會自行產生。
雖然語意排名並非在所有案例中都有用,但某些內容可以顯著受益於其功能。 語意排名工具中的語言模型最適合用於資訊豐富且結構化為 PROSE 的可搜尋內容。 知識庫、線上文件或包含描述性內容的文件可從語意排名工具功能取得最大效益。
基礎技術由 Bing 和 Microsoft Research 提供,並以附加功能形式整合至 Azure AI 搜尋服務基礎結構。 如需支援語意排名工具的研究與 AI 投資的詳細資訊,請參閱 Bing 的 AI 如何支援Azure AI 搜尋服務 (Microsoft Research 部落格)。
下列影片提供功能的概觀。
可用性和價格
語意排名工具可在基本和更高層級的搜尋服務中使用,但受限於區域可用性。
當您啟用語意排名工具時,請選擇該功能的定價方案:
- 在較低的查詢量(每月低於1,000個),語意排名是免費的。
- 當查詢量較高時,請選擇標準定價方案。
Azure AI 搜尋服務定價頁面會顯示不同貨幣和區間的計費費率。
當查詢要求包含 queryType=semantic 且搜尋字串不為空白 (例如,search=pet friendly hotels in New York) 時,則會收取語意排名工具費用。 如果您的搜尋字串為空白 (search=*),即使 queryType 設定為 semantic,系統也不會向您收費。
如何開始使用語意排名工具
登入 Azure 入口網站,確認您的搜尋服務為基本或更新版本。