使用隔離裝置在 SUSE 中進行高可用性設定
在本文中,我們將逐步說明如何使用隔離裝置,在 SUSE 作業系統上的 HANA 大型執行個體中設定高可用性 (HA)。
注意
本指南是在 Microsoft HANA 大型執行個體環境中成功測試設定後所得出。 HANA 大型執行個體的 Microsoft 服務管理小組不支援作業系統的相關問題。 如需作業系統層的疑難排解或釐清,請連絡 SUSE。
Microsoft 服務管理小組會設定並完全支援隔離裝置。 這有助於對隔離裝置問題進行疑難排解。
先決條件
若要使用 SUSE 叢集設定高可用性,您需要:
- 佈建 HANA 大型執行個體。
- 使用最新的修補檔安裝並註冊作業系統。
- 將 HANA 大型執行個體伺服器連線到 SMT 伺服器,以取得修補檔和套件。
- 設定網路時間通訊協定 (NTP 時間伺服器)。
- 閱讀並了解有關 HA 設定的最新 SUSE 文件。
設定詳細資料
本指南使用下列設定:
- 作業系統:適用於 SAP 的 SLES 12 SP1
- HANA 大型執行個體:2xS192 (4 個插槽,2 TB)
- HANA 版本:HANA 2.0 SP1
- 伺服器名稱:sapprdhdb95 (node1) 和 sapprdhdb96 (node2)
- 隔離裝置:iSCSI 型
- 其中一個 HANA 大型執行個體節點上的 NTP
當您使用 HANA 系統複本設定 HANA 大型執行個體時,可以要求 Microsoft 服務管理小組設定隔離裝置。 在佈建時執行此動作。
如果您是已佈建 HANA 大型執行個體的現有客戶,您仍然可以取得隔離裝置的設定支援。 將下列資訊以服務要求表單 (SRF) 的形式提供給 Microsoft 服務管理小組。 您可以透過技術支援專案經理或 Microsoft 連絡人索取 HANA 大型執行個體取得 SRF 表單。
- 伺服器名稱和伺服器 IP 位址 (例如 myhanaserver1 和 10.35.0.1)
- 位置 (例如美國東部)
- 客戶名稱 (例如 Microsoft)
- HANA 系統識別碼 (SID) (例如 H11)
設定隔離裝置之後,Microsoft 服務管理小組會為您提供 SBD 名稱與 iSCSI 儲存裝置的 IP 位址。 您可以使用此資訊進行隔離設定。
請依照以下幾節中的步驟,使用隔離裝置設定 HA。
識別 SBD 裝置
注意
本節僅適用於現有客戶。 如果您是新客戶,Microsoft 服務管理小組將會提供 SBD 裝置名稱,因此請略過本節。
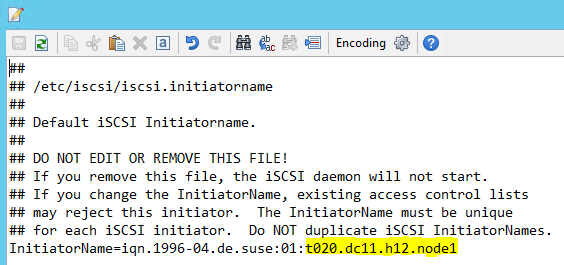
將 /etc/iscsi/initiatorname.isci 修改為:
iqn.1996-04.de.suse:01:<Tenant><Location><SID><NodeNumber>Microsoft 服務管理小組會提供此字串。 修改這「兩個」節點上的檔案。 但是,各節點的號碼皆不同。
設定
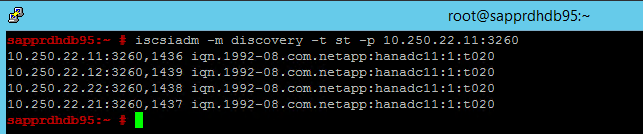
node.session.timeo.replacement_timeout=5和node.startup = automatic來修改 /etc/iscsi/iscsid.conf。 修改這「兩個」節點上的檔案。在這「兩個」節點上執行下列探索命令。
iscsiadm -m discovery -t st -p <IP address provided by Service Management>:3260結果顯示四個工作階段。
在這「兩個」節點上執行下列命令,以登入 iSCSI 裝置。
iscsiadm -m node -l結果顯示四個工作階段。

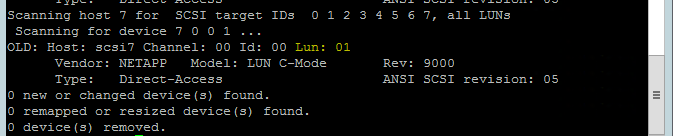
使用下列命令來執行「rescan-scsi-bus.sh」重新掃描指令碼。 此指令碼會顯示為您建立的新磁碟。 在這「兩個」節點上執行。
rescan-scsi-bus.sh結果應顯示大於零的 LUN 數字 (例如:1、2 等等)。
若要取得裝置名稱,請在「兩個」節點上執行下列命令。
fdisk –l在結果中,選擇大小為 178 MiB 的裝置。

初始化 SBD 裝置
使用下列命令來將「兩個」節點上的 SBD 裝置初始化。
sbd -d <SBD Device Name> create
在「兩個」節點上使用下列命令來檢查已寫入裝置的內容。
sbd -d <SBD Device Name> dump
設定 SUSE HA 叢集
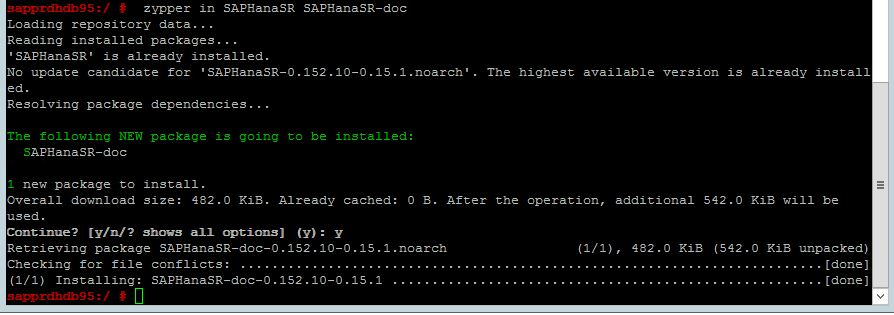
使用下列命令來檢查「兩個」節點上是否皆已安裝 ha_sles 和 SAPHanaSR-doc 模式。 如果尚未安裝,請安裝這兩個模式。
zypper in -t pattern ha_sles zypper in SAPHanaSR SAPHanaSR-doc
使用
ha-cluster-init命令或 yast2 精靈來設定叢集。 在此範例中,我們使用的是 yast2 精靈。 您只能在「主要節點」上執行此步驟。移至 [yast2]>[高可用性]>[叢集]。
![顯示 YaST 控制中心的螢幕擷取畫面,其中已選取 [高可用性] 和 [叢集]。](media/howtohli/hasetupwithfencing/yast-control-center.png)
在出現的有關 Hawk 封裝安裝的對話中,選取 [取消],因為已安裝 halk2 套件。
![此螢幕擷取畫面顯示具有 [安裝] 和 [取消] 選項的對話方塊。](media/howtohli/hasetupwithfencing/yast-hawk-install.png)
在出現關於繼續的對話中,選取 [繼續]。
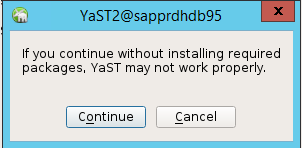
預期值為已部署的節點數目 (在此案例中為 2)。 選取 [下一步] 。
新增節點名稱,然後選取 [新增建議的檔案]。
![此螢幕擷取畫面顯示含有 [同步主機] 和 [同步檔案] 清單的 [叢集設定] 視窗。](media/howtohli/hasetupwithfencing/yast-cluster-configure-csync2.png)
選取 [開啟 csync2]。
選取 [產生預先共用金鑰]。
在出現的快顯訊息中,選取 [確定]。
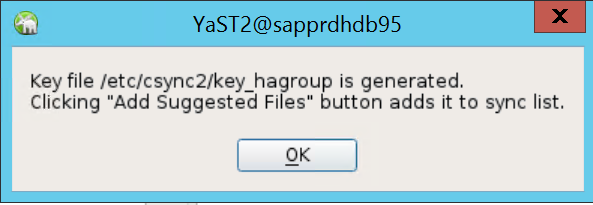
系統會使用 IP 位址和 Csync2 中的預先共用金鑰來執行驗證。 金鑰檔案會以
csync2 -k /etc/csync2/key_hagroup產生。檔案「key_hagroup」應在建立之後手動複製到叢集的所有成員。 務必將檔案從 node1 複製到 node2。 然後選取 [下一步]。
![顯示 [叢集設定] 對話方塊的螢幕擷取畫面,其中包含將金鑰複製給所有叢集成員所需的選項。](media/howtohli/hasetupwithfencing/yast-cluster-conntrackd.png)
在預設選項中,[開機中] 為 [關閉]。 將其變更為 [開啟],讓 Pacemaker 服務在開機時即啟動。 您可以根據自己的設定需求來選擇。
![顯示 [叢集服務] 視窗的螢幕擷取畫面,其中已開啟 [開機]。](media/howtohli/hasetupwithfencing/yast-cluster-service.png)
選取 [下一步]後,叢集設定就完成了。
設定 Softdog 監視程式
在「兩個」節點上將下行加入至 /etc/init.d/boot.local。
modprobe softdog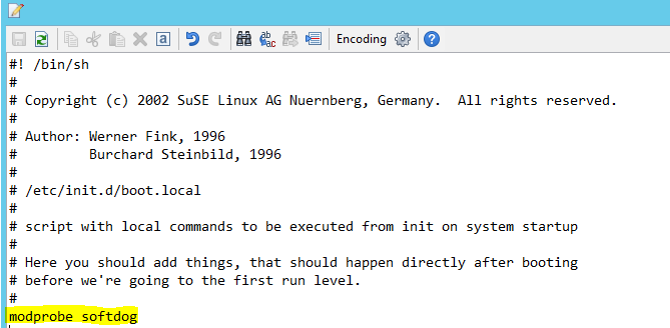
使用下列命令來更新「兩個」節點上的 /etc/sysconfig/sbd 檔案。
SBD_DEVICE="<SBD Device Name>"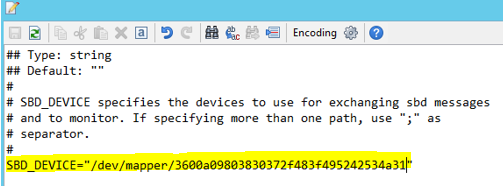
執行下列命令以在「兩個」節點上載入核心模組。
modprobe softdog
使用下列命令,以確保 softdog 正在「兩個」節點上執行。
lsmod | grep dog
使用下列命令來啟動「兩個」節點上的 SBD 裝置。
/usr/share/sbd/sbd.sh start
使用下列命令在「兩個」節點上測試 SBD 精靈。
sbd -d <SBD Device Name> list結果會顯示在兩個節點上設定之後的兩個項目。

將以下測試訊息傳送至其中「一個」節點。
sbd -d <SBD Device Name> message <node2> <message>在「第二個」節點 (node2) 上使用下列命令來檢查訊息狀態。
sbd -d <SBD Device Name> list
若要採用 SBD 設定,請更新「兩個」節點上的檔案 etc/sysconfig/sbd,如下所示。
SBD_DEVICE=" <SBD Device Name>" SBD_WATCHDOG="yes" SBD_PACEMAKER="yes" SBD_STARTMODE="clean" SBD_OPTS=""使用下列命令,在「主要節點」(node1) 上啟動 Pacemaker 服務。
systemctl start pacemaker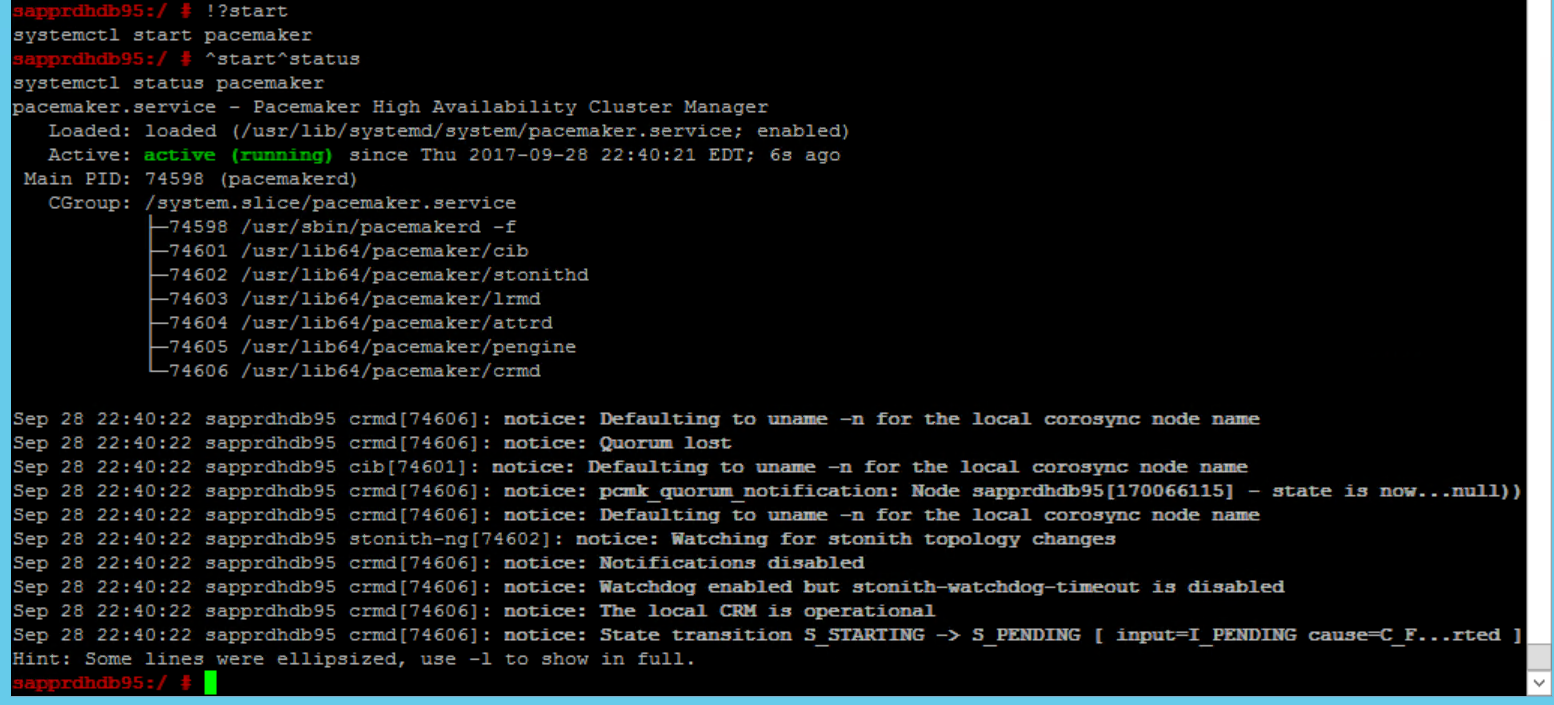
如果 Pacemaker 服務失敗,請參閱本文稍後的案例 5:Pacemaker 服務失敗 (部分機器翻譯) 一節。
將節點加入叢集
在「node2」上執行下列命令,讓 node2 加入叢集。
ha-cluster-join
如果您在加入叢集期間收到錯誤,請參閱本文稍後的案例 6:Node2 無法加入叢集 (部分機器翻譯) 一節。
驗證叢集
使用下列命令檢查,並可選擇在「兩個」節點上首次啟動叢集。
systemctl status pacemaker systemctl start pacemaker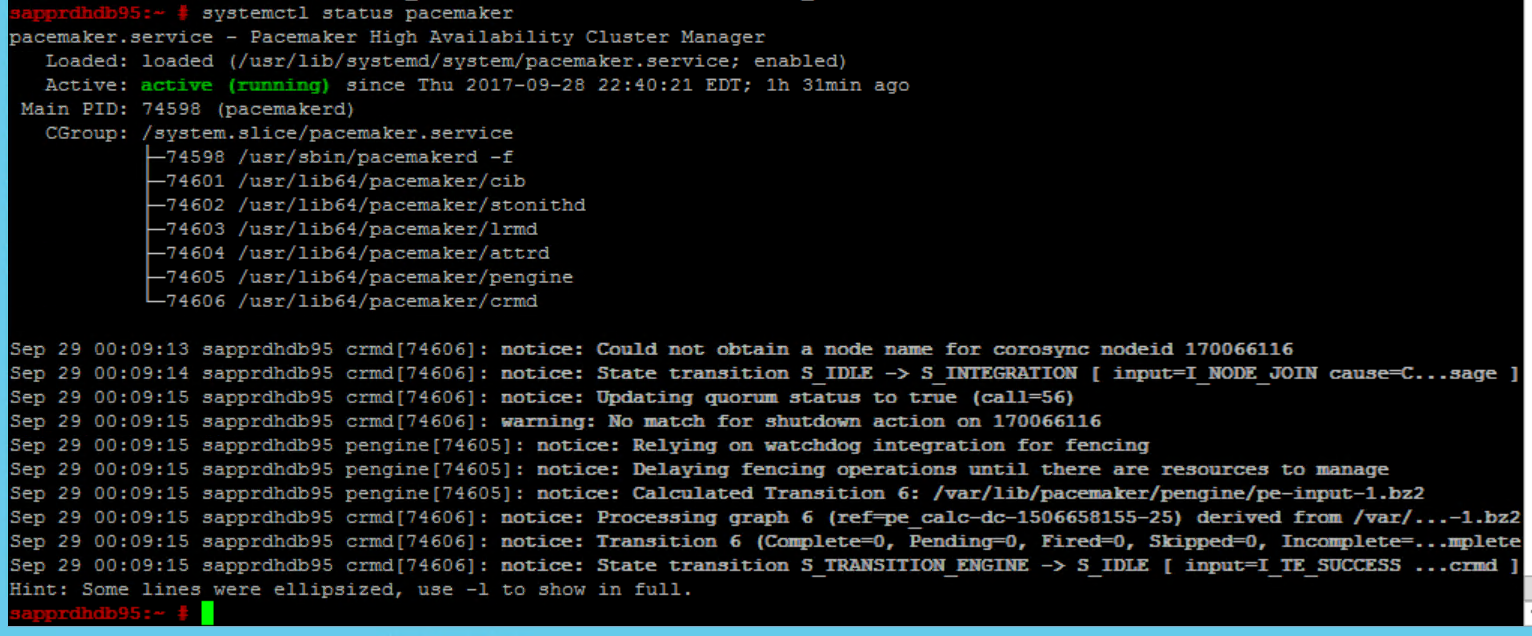
執行下列命令,以確保這「兩個」節點都已連線。 您可以在叢集的「任一節點」上執行它。
crm_mon
您也可以登入 hawk 來檢查叢集狀態:
https://\<node IP>:7630。 預設使用者為 hacluster,而密碼為 linux。 如有需要,您可以使用passwd命令來變更密碼。
設定叢集屬性及資源
本節說明設定叢集資源的步驟。 在此範例中,您會設定下列資源。 您可以參考 SUSE HA 指南,視需要設定其餘的項目。
- 叢集啟動程序
- 隔離裝置
- 虛擬 IP 位址
只在「主要節點」上執行設定。
建立叢集啟動程序檔案,並藉由新增下列文字進行設定。
sapprdhdb95:~ # vi crm-bs.txt # enter the following to crm-bs.txt property $id="cib-bootstrap-options" \ no-quorum-policy="ignore" \ stonith-enabled="true" \ stonith-action="reboot" \ stonith-timeout="150s" rsc_defaults $id="rsc-options" \ resource-stickiness="1000" \ migration-threshold="5000" op_defaults $id="op-options" \ timeout="600"使用下列命令,將設定新增至叢集。
crm configure load update crm-bs.txt
新增資源、建立檔案以及新增文字,以設定隔離裝置,如下所示。
# vi crm-sbd.txt # enter the following to crm-sbd.txt primitive stonith-sbd stonith:external/sbd \ params pcmk_delay_max="15"使用下列命令,將設定新增至叢集。
crm configure load update crm-sbd.txt建立檔案並新增下列文字,以新增資源的虛擬 IP 位址。
# vi crm-vip.txt primitive rsc_ip_HA1_HDB10 ocf:heartbeat:IPaddr2 \ operations $id="rsc_ip_HA1_HDB10-operations" \ op monitor interval="10s" timeout="20s" \ params ip="10.35.0.197"使用下列命令,將設定新增至叢集。
crm configure load update crm-vip.txt使用
crm_mon命令來驗證資源。結果顯示兩個資源。

您也可以檢查位於 https://<節點 IP 位址>:7630/cib/live/state 的狀態。
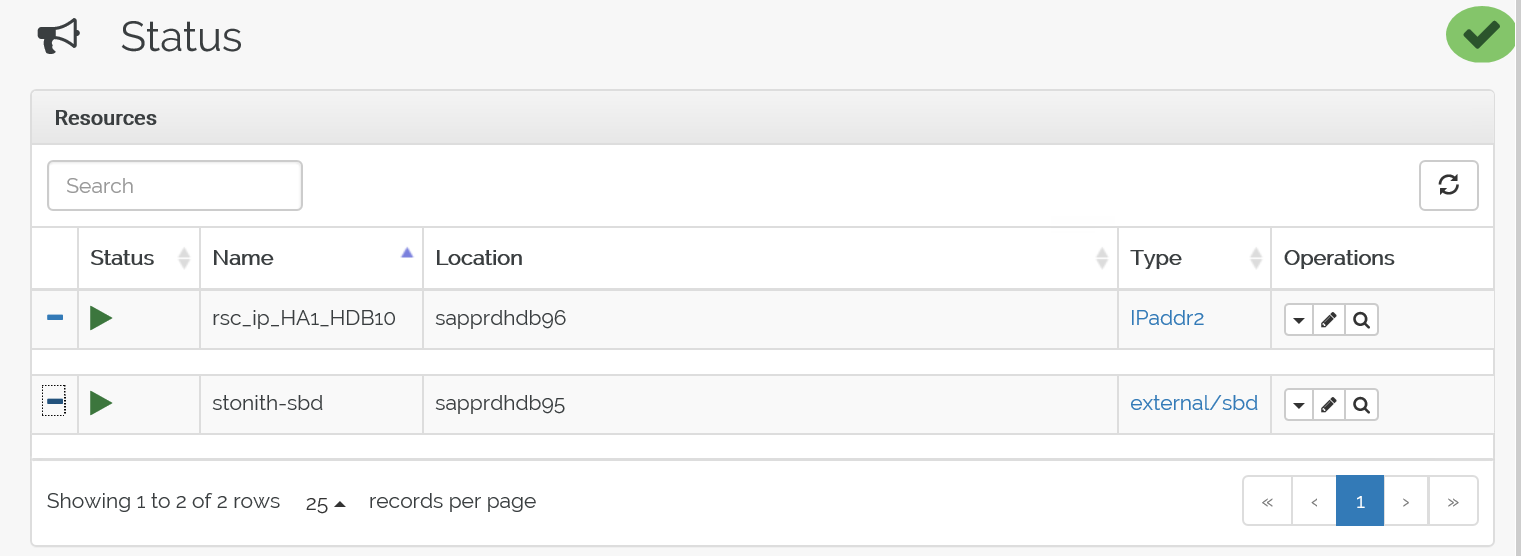
測試容錯移轉程序
若要測試容錯移轉流程,請使用下列命令來停止 node1 上的 Pacemaker 服務。
Service pacemaker stop資源會容錯移轉至 node2。
停止 node2 上的 Pacemaker 服務,資源容錯移轉至 node1。
這是容錯移轉前的狀態:
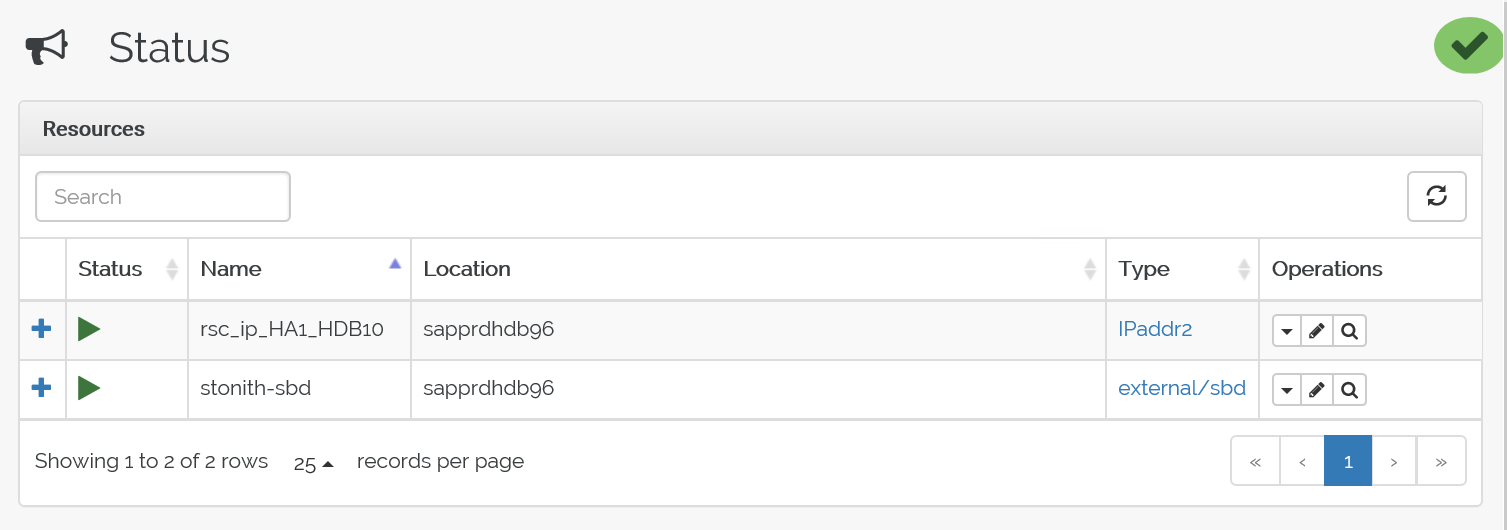
這是容錯移轉後的狀態:
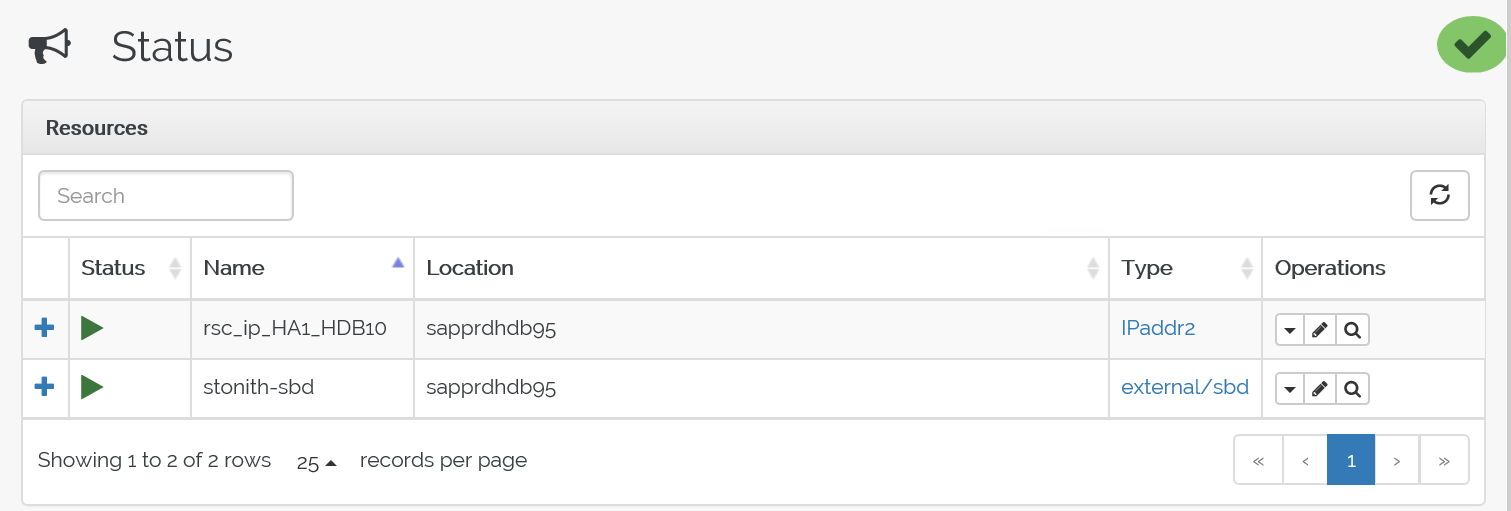

疑難排解
本節說明您在設定期間可能會遇到的失敗案例。
案例 1:叢集節點未連線
如果任一節點未在叢集管理員中顯示為連線,您可以嘗試執行此程序使其連線。
使用下列命令啟動 iSCSI 服務。
service iscsid start使用下列命令登入該 iSCSI 節點。
iscsiadm -m node -l預期的輸出看起來是:
sapprdhdb45:~ # iscsiadm -m node -l Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.11,3260] (multiple) Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.12,3260] (multiple) Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.22,3260] (multiple) Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.21,3260] (multiple) Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.11,3260] successful. Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.12,3260] successful. Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.22,3260] successful. Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.21,3260] successful.
案例 2:Yast2 未顯示圖形檢視
此文章使用 yast2 圖形化畫面來設定高可用性叢集。 如果 yast2 未以圖形化視窗開啟,並擲回 Qt 錯誤,請採取下列步驟來安裝必要的套件。 如果它以圖形視窗開啟,您可以略過步驟。
Qt 錯誤的範例如下:

預期輸出的範例如下:
請確定您以使用者 “root” 的身分登入,並讓 SMT 安裝程式下載和安裝套件。
移至 [yast]>[軟體]>[軟體管理]>[相依項目],然後選取 [安裝建議的套件]。
注意
在這「兩個」節點上執行所述步驟,便能從這兩個節點存取 yast2 圖形檢視。
下列螢幕擷取畫面顯示預期的畫面。
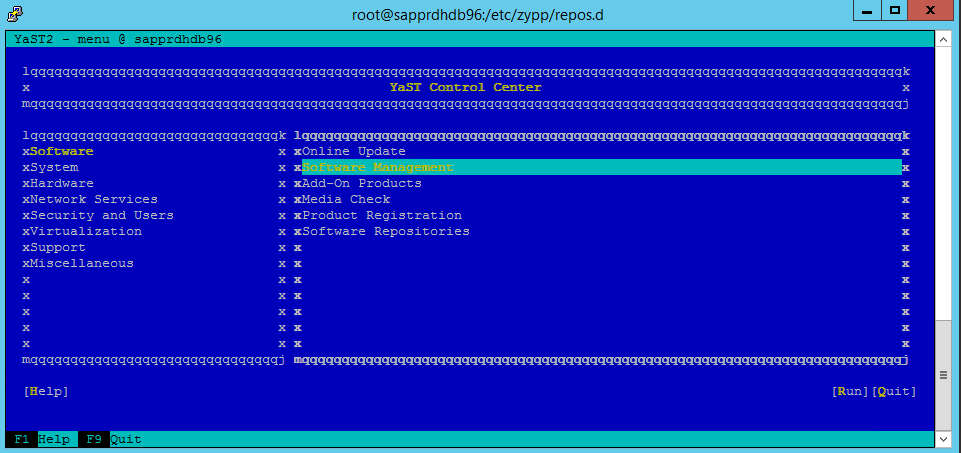
在 [相依性] 下,選取 [安裝建議的套件]。
![顯示主控台視窗的螢幕擷取畫面,其中已選取 [安裝建議的套件]。](media/howtohli/hasetupwithfencing/yast-dependencies.png)
檢閱所做的變更,然後按 [確定]。
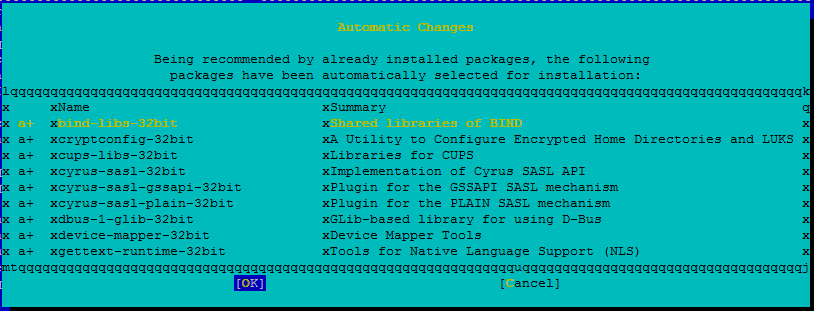
繼續執行封裝安裝。
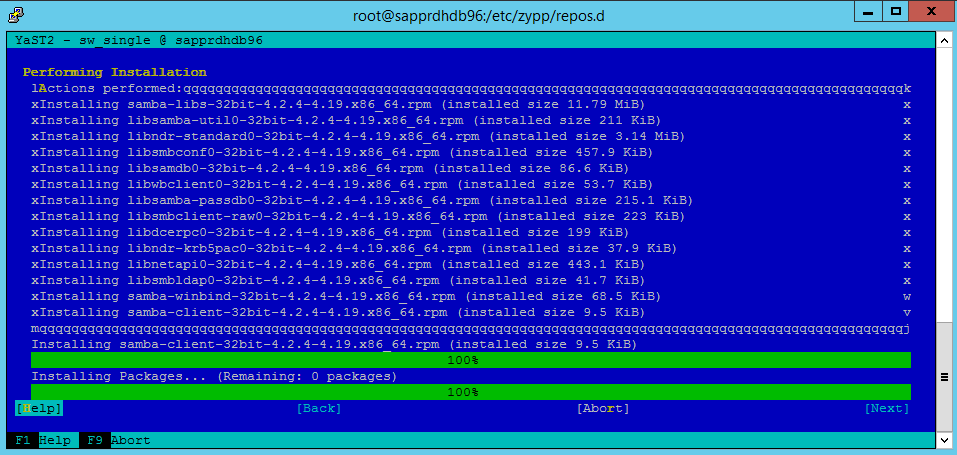
選取 [下一步] 。
當 [安裝成功完成] 畫面出現時,選取 [完成]。
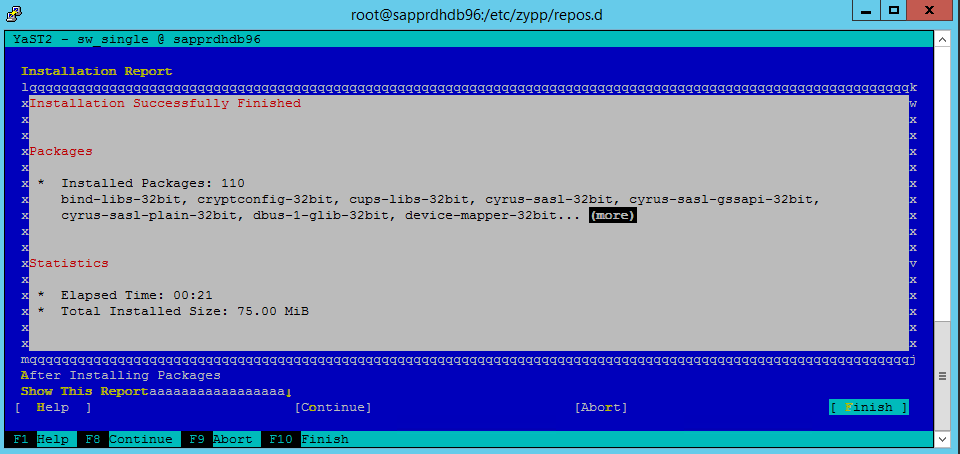
使用下列命令來安裝 libqt4 和 libyui-qt 套件。
zypper -n install libqt4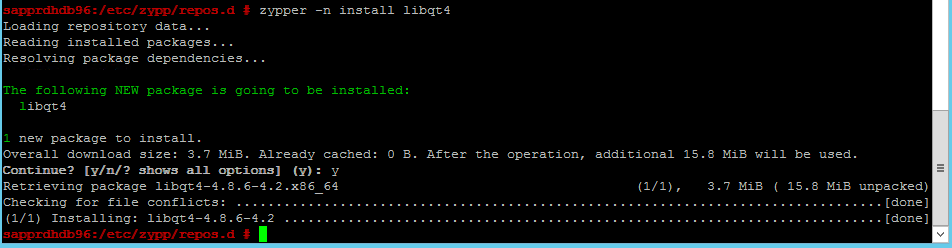
zypper -n install libyui-qt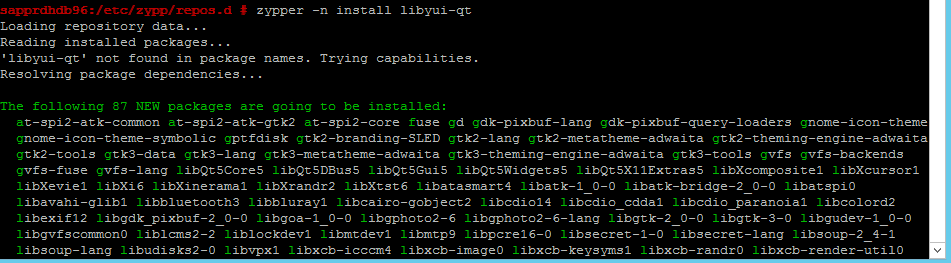

Yast2 現在可以開啟圖形化檢視。
![此螢幕擷取畫面顯示已選取 [軟體] 和 [線上更新] 的 YaST 控制中心。](media/howtohli/hasetupwithfencing/yast2-control-center.png)
案例 3:Yast2 未顯示高可用性選項
您需要安裝其他套件,才能在 yast2 控制中心上顯示 [高可用性] 選項。
移至 [Yast2]>[軟體]>[軟體管理]。 然後選取 [軟體]>[線上更新]。
選取下列項目的模式。 接著選取 [接受]。
- SAP HANA 伺服器基底
- C/C++ 編譯器和工具
- 高可用性
- SAP 應用程式伺服器基底
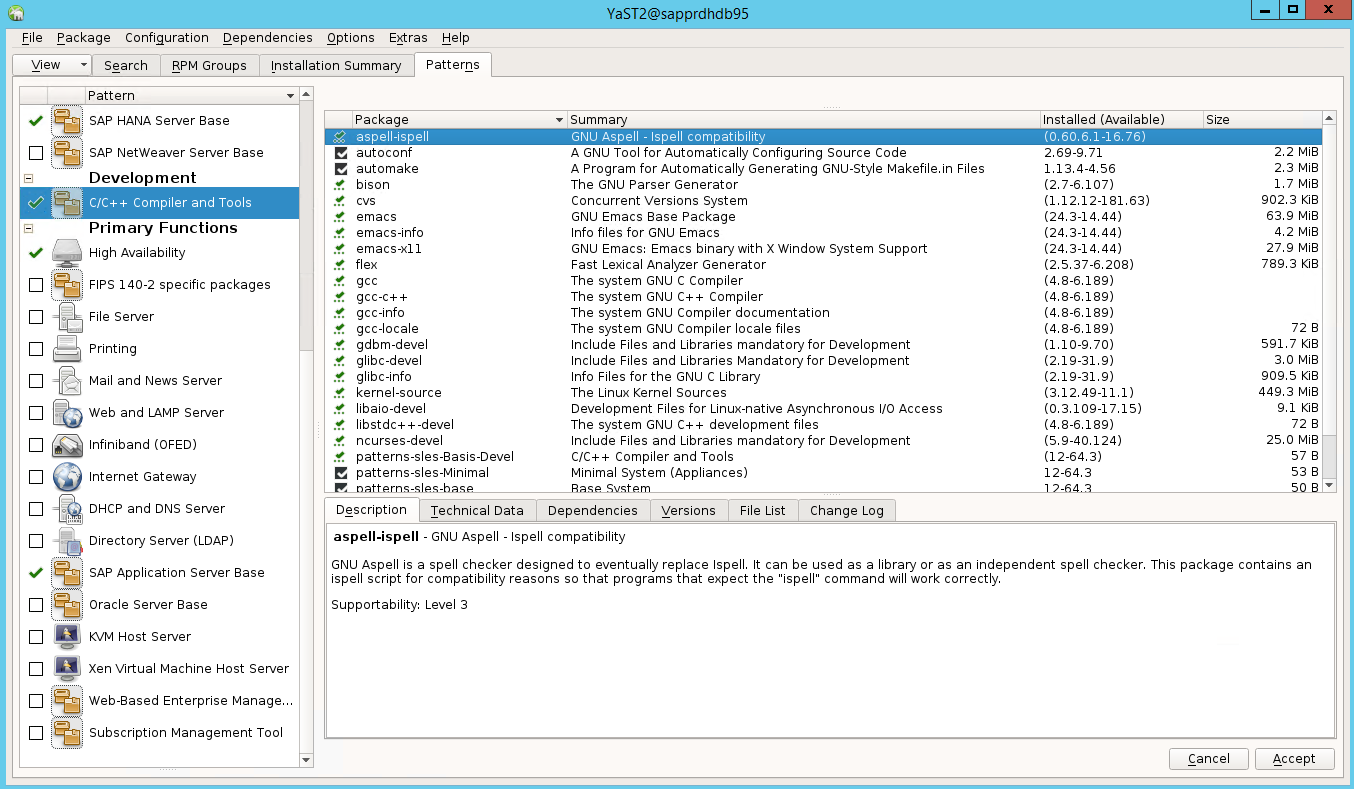
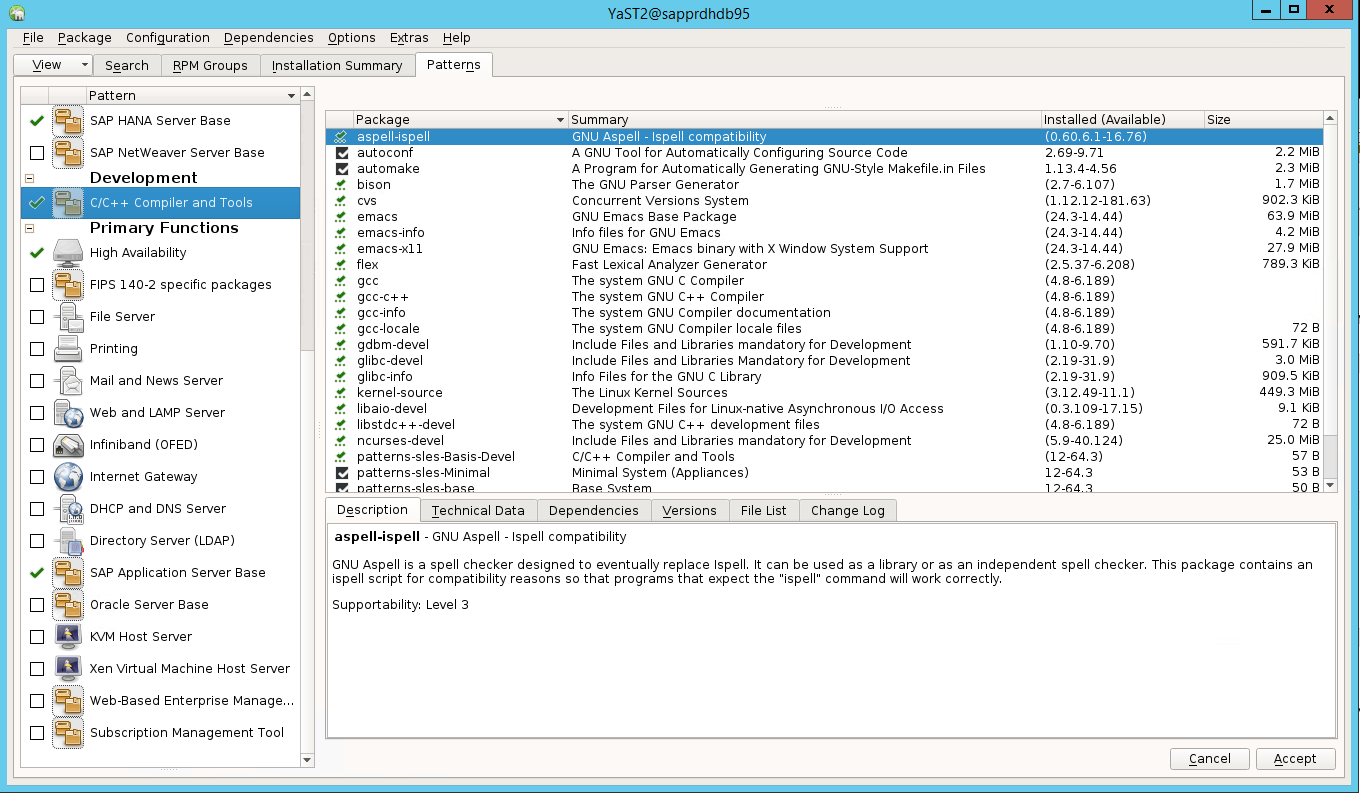
在為解析相依性而變更的套件清單中,選取 [繼續]。
![此螢幕擷取畫面顯示 [已變更的套件] 對話方塊,其中包含已變更以解析相依性的套件。](media/howtohli/hasetupwithfencing/yast-changed-packages.png)
在 [執行安裝] 狀態頁面上,選取 [下一步]。
![顯示 [執行安裝狀態] 頁面的螢幕擷取畫面。](media/howtohli/hasetupwithfencing/yast2-performing-installation.png)
安裝完成時,會出現安裝報告。 選取 [完成]。
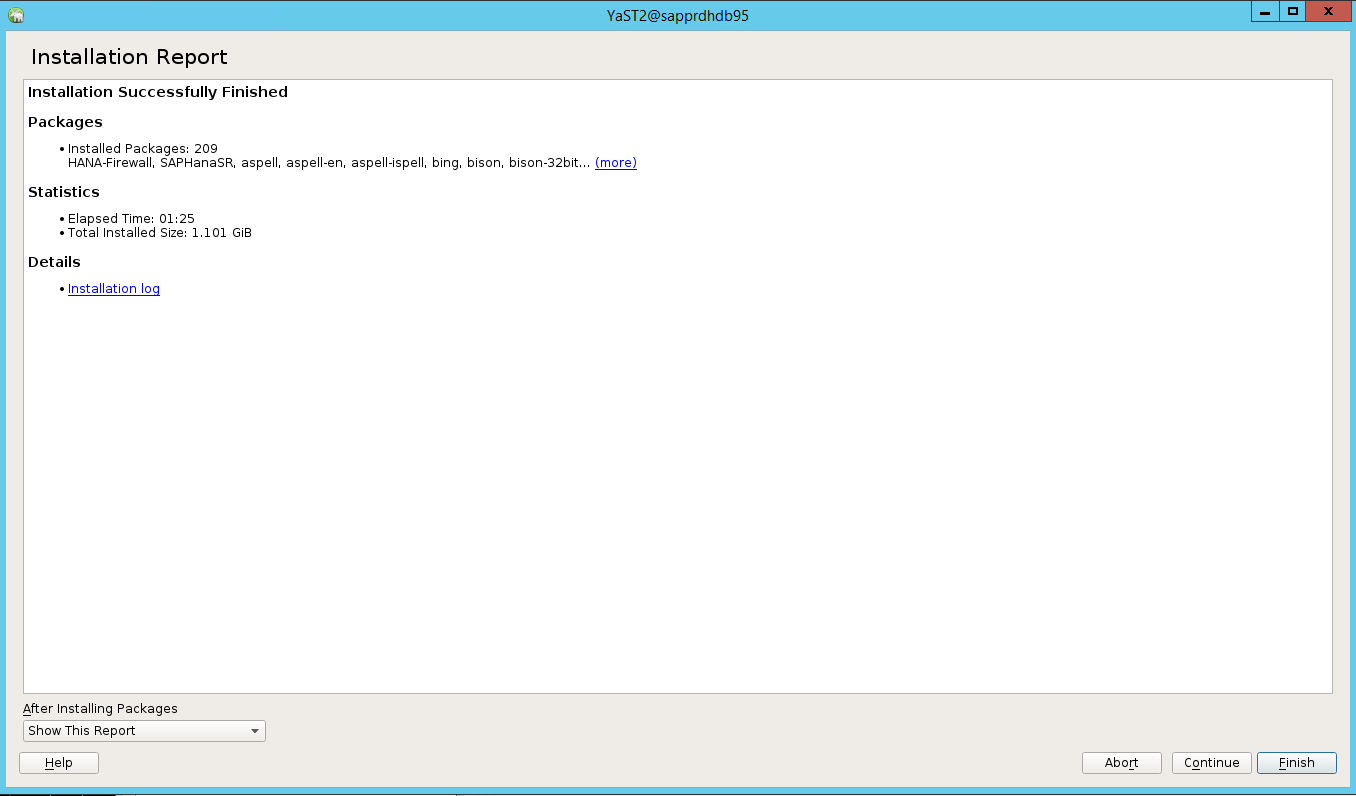
案例 4:HANA 安裝失敗並顯示 gcc 組件錯誤
如果 HANA 安裝失敗,您可能會收到下列錯誤。
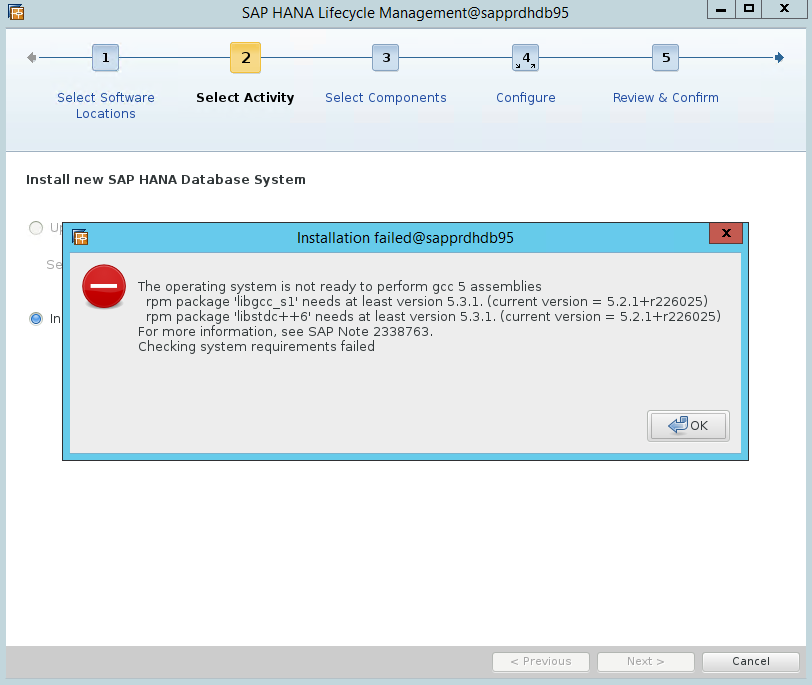
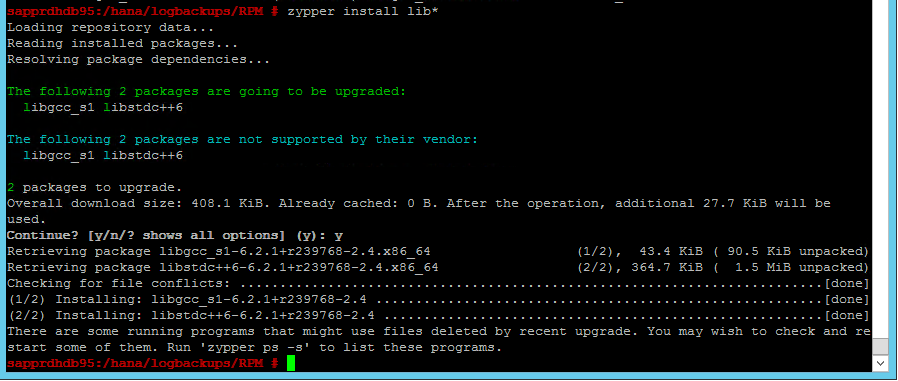
若要修正此問題,請安裝 libgcc_sl 和 libstdc++6 程式庫,如下列螢幕擷取畫面所示。
案例 5:Pacemaker 服務失敗
如果 Pacemaker 服務無法啟動,則會顯示下列資訊。
sapprdhdb95:/ # systemctl start pacemaker
A dependency job for pacemaker.service failed. See 'journalctl -xn' for details.
sapprdhdb95:/ # journalctl -xn
-- Logs begin at Thu 2017-09-28 09:28:14 EDT, end at Thu 2017-09-28 21:48:27 EDT. --
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync configuration map
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [QB ] withdrawing server sockets
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync configuration ser
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [QB ] withdrawing server sockets
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync cluster closed pr
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [QB ] withdrawing server sockets
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync cluster quorum se
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync profile loading s
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [MAIN ] Corosync Cluster Engine exiting normally
Sep 28 21:48:27 sapprdhdb95 systemd[1]: Dependency failed for Pacemaker High Availability Cluster Manager
-- Subject: Unit pacemaker.service has failed
-- Defined-By: systemd
-- Support: https://lists.freedesktop.org/mailman/listinfo/systemd-devel
--
-- Unit pacemaker.service has failed.
--
-- The result is dependency.
sapprdhdb95:/ # tail -f /var/log/messages
2017-09-28T18:44:29.675814-04:00 sapprdhdb95 corosync[57600]: [QB ] withdrawing server sockets
2017-09-28T18:44:29.676023-04:00 sapprdhdb95 corosync[57600]: [SERV ] Service engine unloaded: corosync cluster closed process group service v1.01
2017-09-28T18:44:29.725885-04:00 sapprdhdb95 corosync[57600]: [QB ] withdrawing server sockets
2017-09-28T18:44:29.726069-04:00 sapprdhdb95 corosync[57600]: [SERV ] Service engine unloaded: corosync cluster quorum service v0.1
2017-09-28T18:44:29.726164-04:00 sapprdhdb95 corosync[57600]: [SERV ] Service engine unloaded: corosync profile loading service
2017-09-28T18:44:29.776349-04:00 sapprdhdb95 corosync[57600]: [MAIN ] Corosync Cluster Engine exiting normally
2017-09-28T18:44:29.778177-04:00 sapprdhdb95 systemd[1]: Dependency failed for Pacemaker High Availability Cluster Manager.
2017-09-28T18:44:40.141030-04:00 sapprdhdb95 systemd[1]: [/usr/lib/systemd/system/fstrim.timer:8] Unknown lvalue 'Persistent' in section 'Timer'
2017-09-28T18:45:01.275038-04:00 sapprdhdb95 cron[57995]: pam_unix(crond:session): session opened for user root by (uid=0)
2017-09-28T18:45:01.308066-04:00 sapprdhdb95 CRON[57995]: pam_unix(crond:session): session closed for user root
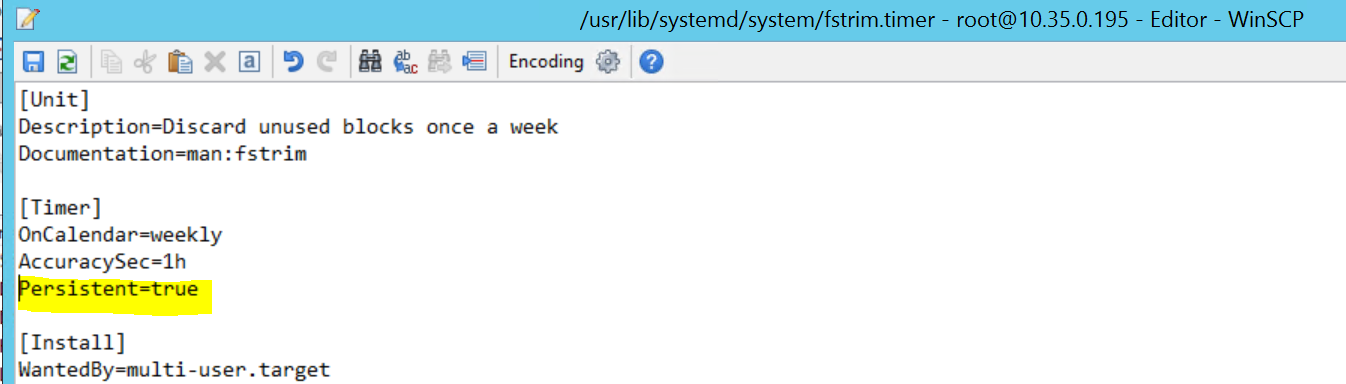
若要修正此問題,請從檔案 /usr/lib/systemd/system/fstrim.timer 中刪除下行:
Persistent=true
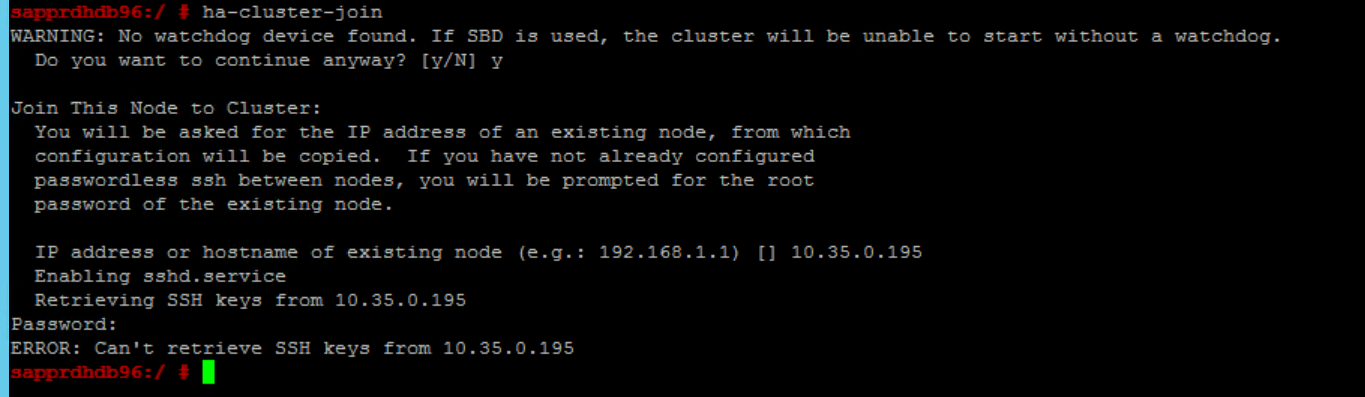
案例 6:Node2 無法加入叢集
如果透過 ha-cluster-join 命令將 node2 加入現有叢集時發生問題,則會出現下列錯誤。
ERROR: Can’t retrieve SSH keys from <Primary Node>
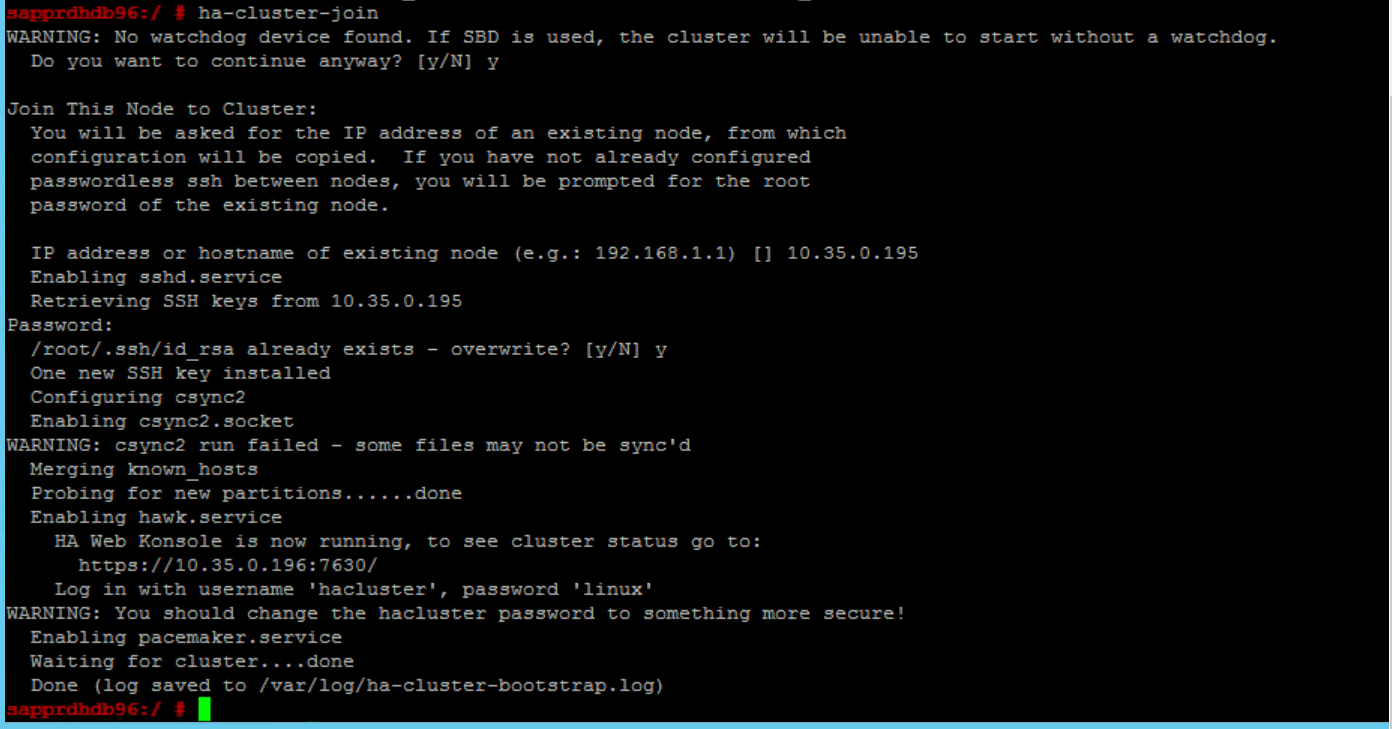
修正此問題:
在這「兩個節點」上執行下列命令。
ssh-keygen -q -f /root/.ssh/id_rsa -C 'Cluster Internal' -N '' cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys

確認 node2 已新增至叢集。
下一步
您可以在下列文章中找到有關 SUSE HA 設定的詳細資訊:
- SAP HANA SR 效能最佳化案例 (英文) (SUSE 網站)
- 隔離和隔離裝置 (SUSE 網站)
- 準備好使用 SAP Hana 的 Pacemaker 叢集 – 第 1 部分:基本概念 (英文) (SAP 部落格)
- 準備好使用 SAP Hana 的 Pacemaker 叢集 – 第 2 部分:兩個節點皆失敗 (英文) (SAP 部落格)
- OS 備份和還原 (部分機器翻譯)