適用於 PostgreSQL 的 Azure 資料庫 - 彈性伺服器中的高可用性 (可靠性)
適用於: 適用於 PostgreSQL 的 Azure 資料庫 - 彈性伺服器
適用於 PostgreSQL 的 Azure 資料庫 - 彈性伺服器
本文說明「適用於 PostgreSQL 的 Azure 資料庫 - 彈性伺服器」中的高可用性,其中包含可用性區域和跨區域復原和商務持續性。 如需更多關於 Azure 可靠性的詳細概觀,請參閱 Azure 可靠性。
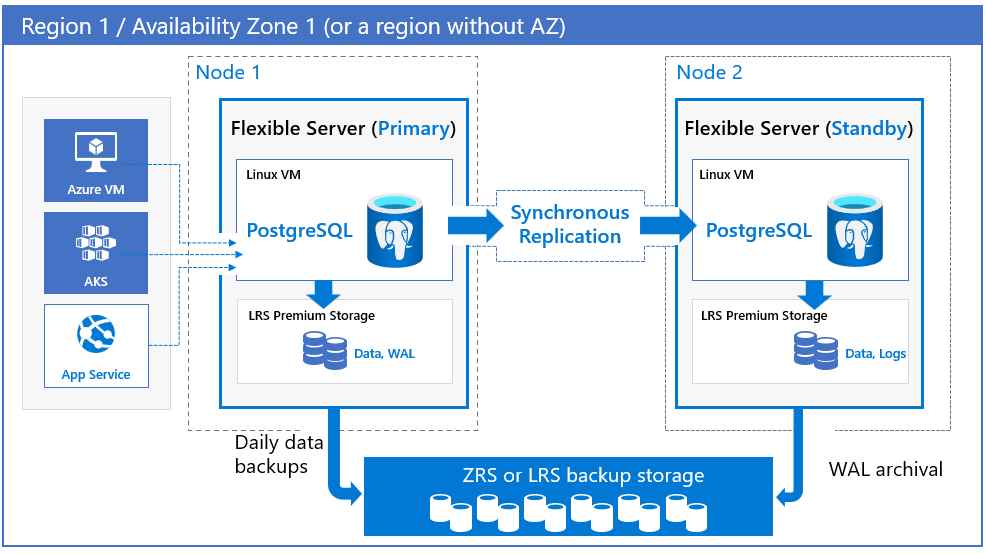
「適用於 PostgreSQL 的 Azure 資料庫 - 彈性伺服器」可提供高可用性支援,方法是在相同可用性區域 (區域性) 內或跨可用性區域 (區域備援) 佈建實際分隔的主要和待命複本。 這個高可用性模型的設計目的是為了確保在發生失敗時,絕對不會遺失已認可的資料。 在高可用性 (HA) 設定中,數據會同步認可到主要和待命伺服器。 模型的設計目的是讓資料庫不會成為軟體架構中的單一失敗點。 如需高可用性和可用性區域支援的詳細資訊,請參閱可用性區域支援。
可用性區域支援
可用性區域是每個 Azure 區域內的數據中心實體分隔群組。 當某個區域失敗時,服務可以故障轉移至其中一個其餘區域。
如需 Azure 中可用性區域的詳細資訊,請參閱 什麼是可用性區域?
針對高可用性設定,「適用於 PostgreSQL 的 Azure 資料庫 - 彈性伺服器」同時支援區域備援模型和區域性模型。 這兩種高可用性設定都會啟用自動容錯移轉功能,可在計劃性和非計劃性事件發生期間不遺失任何資料。
區域備援。 區域備援高可用性會在不同的區域中,部署具有自動容錯移轉功能的備用複本。 區域備援提供最高層級的可用性,但需要您設定跨區域的應用程式備援。 為此,當您想要避免可用性區域層級的失敗,並且可以接受跨可用性區域的延遲時,請選擇區域備援。 雖然由於同步復寫而對寫入和認可有一些延遲影響,但不會影響讀取查詢。 此影響非常專屬於您的工作負載、您選取的 SKU 類型,以及區域。
您可以選擇主要和待命伺服器的區域和可用性區域。 待命複本會在與主要伺服器相同區域的所選可用性區域中進行佈建,並具有類似的計算、儲存體和網路設定。 資料檔案和交易記錄檔 (預寫記錄檔 (WAL)) 會儲存在每個可用性區域內的本地備援儲存體 (LRS) 上,並自動儲存三個資料複本。 區域備援設定可為主要和待命伺服器之間的整體堆疊提供實體隔離。

區域性。 當您想要在具有最低網路延遲的單一可用性區域內達到最高層級的可用性時,請選擇區域性部署。 您可以選擇用來部署主要資料庫伺服器的區域和可用性區域。 待命複本會在與主要伺服器相同的可用性區域中自動進行佈建和管理,並具有類似的計算、儲存體和網路設定。 區域性設定可防止資料庫發生節點層級的失敗,並且可協助降低計劃性與非計劃性停機事件發生期間的應用程式停機時間。 主要伺服器中的資料以同步模式複寫到待命複本。 在主要伺服器發生任何中斷的事件中,伺服器會自動容錯移轉至待命複本。


注意
區域性部署模型和區域備援部署模型在架構上的行為都相同。 除非另有說明,否則下列各節中的各種討論皆適用於這兩者。
必要條件
區域備援:
區域備援選項僅適用於支援可用性區域的區域。
下列項目不支援區域備援:
- 適用於 PostgreSQL 的 Azure 資料庫 - 單一伺服器 SKU。
- 可高載計算層。
- 具有單一區域可用性的區域。
區域性:
- 區域性部署選項適用於所有可部署彈性伺服器的 Azure 區域。
高可用性功能
待命複本會部署在與主要伺服器相同的 VM 設定中,包括虛擬核心、儲存體、網路設定。
您可以為現有資料庫伺服器新增可用性區域支援。
您可以藉由停用高可用性來移除待命複本。
針對區域備援可用性,您可以選擇主要和待命資料庫伺服器的可用性區域。
停止、啟動和重新啟動等作業會在主要和待命資料庫伺服器上同時執行。
在區域備援模型和區域性模型中,系統會定期從主要資料庫伺服器執行自動備份。 同時,交易記錄會持續從待命複本封存到備份儲存體中。 如果該區域支援可用性區域,則備份資料會儲存在區域備援儲存體上 (ZRS)。 在不支援可用性區域的區域中,備份資料會儲存在本機備援儲存體 (LRS) 上。
用戶端一律會連線到主要資料庫伺服器的端點主機名稱。
伺服器參數的任何變更也會套用到待命複本。
可重新啟動伺服器以挑出任何靜態伺服器參數變更。
定期維護活動 (例如次要版本升級) 會先在待命伺服器上進行,為了減少停機時間,待命伺服器會升階為主要伺服器,讓工作負載可以繼續運作,與此同時則在其餘節點上套用維護工作。
監視高可用性健康情況
適用於 PostgreSQL 的 Azure 資料庫 中的高可用性 (HA) 健康狀態監視 - 彈性伺服器提供已啟用 HA 實例健康情況和整備狀態的持續概觀。 這項監視功能會利用 Azure 的 資源健康狀態 檢查 (RHC) 架構,偵測並警示可能影響資料庫故障轉移整備或整體可用性的任何問題。 藉由評估連線狀態、故障轉移狀態和數據復寫健康情況等關鍵計量,HA 健全狀態監視可啟用主動式疑難解答,並協助維護資料庫的運行時間和效能。
客戶可以使用HA健康狀態監視來:
- 取得主要和待命複本健康情況的即時深入解析,並顯示潛在問題的狀態指標,例如效能降低或網路封鎖。
- 針對HA狀態中任何變更的及時通知設定警示,確保立即採取動作來解決潛在的中斷。
- 藉由識別並解決影響資料庫作業之前的問題,將故障轉移整備程度優化。
如需設定和解譯 HA 健全狀況狀態的詳細指南,請參閱高可用性 (HA) 健康狀態監視 適用於 PostgreSQL 的 Azure 資料庫 - 彈性伺服器的主要文章。
高可用性限制
由於需同步複寫至待命伺服器,特別是使用區域備援設定時,因此應用程式的寫入和認可延遲可能會提高。
待命複本無法用於讀取查詢。
根據主要伺服器上的工作負載和活動,容錯移轉程序可能會因為待命複本升階之前所需的復原作業,而費時 120 秒以上。
待命伺服器通常會以每秒 40 MB 的速率復原 WAL 檔案。 對於較大的 SKU,此速率可增加至 200 MB/秒。 如果您的工作負載超過此限制,在容錯移轉期間或建立新待命複本之後,您完成復原的時間可能會延長。
重新啟動主要資料庫伺服器也會重新啟動待命複本。
不支援設定額外的待命伺服器。
無法在受管理的維護時段安排設定客戶起始的管理工作。
諸如調整計算和調整儲存體等計劃性事件會先在待命伺服器上進行,然後再於主要伺服器上進行。 伺服器目前不會針對這些計劃性作業進行容錯移轉。
如果邏輯解碼或邏輯複寫是以設定了可用性的彈性伺服器進行設定的,則在容錯移轉至待命伺服器時,邏輯複寫位置並不會複製到待命伺服器。 若要維護邏輯複寫位置,並確保容錯移轉後的資料一致性,建議使用 PG 容錯移轉位置擴充功能。 如需如何啟用此擴充功能的詳細資訊,請參閱文件。
不支援使用私人端點在私人 (VNET) 和公用存取之間設定可用性區域。 您必須使用私人端點在 VNET 內 (橫跨某個區域內的可用性區域) 或公用存取內設定可用性區域。
可用性區域只會設定在單一區域內。 無法跨區域設定可用性區域。
SLA
區域性模型提供 99.95% 的運作時間 SLA。
區域備援模型提供 99.99% 的運作時間 SLA。
建立已啟用可用性區域的「適用於 PostgreSQL 的 Azure 資料庫 - 彈性伺服器」
若要了解如何建立「適用於 PostgreSQL 的 Azure 資料庫 - 彈性伺服器」以使用可用性區域實現高可用性,請參閱快速入門:在 Azure 入口網站中建立適用於 PostgreSQL 的 Azure 資料庫 - 彈性伺服器。
可用性區域重新部署和移轉
若要了解如何在區域備援部署模型和區域性部署模型中啟用或停用彈性伺服器中的高可用性設定,請參閱在彈性伺服器中管理高可用性。
高可用性元件和工作流程
交易完成
應用程式交易觸發的寫入和認可會先記錄到主要伺服器上的 WAL。 然後,其會使用 Postgres 串流通訊協定串流至待命伺服器。 一旦記錄保存在待命伺服器儲存體上,主要伺服器就會被通知寫入完成。 只有這樣,應用程式才會確認其交易的認可。 這類額外的往返會對您的應用程式增加更多延遲。 影響百分比取決於應用程式。 此通知程序不會等候待命伺服器套用記錄。 待命伺服器會永久處於復原模式,直到升階為止。
健康情況檢查
彈性伺服器狀況監控會定期檢查主要和待命伺服器的健康情況。 Ping 了多次之後,如果狀況監控偵測到主要伺服器無法連線,該服務便會起始自動容錯移轉至待命伺服器。 狀況監控演算法會以多個資料點為基礎,以避免誤判情況。
容錯移轉模式
彈性伺服器支援兩種容錯移轉模式,分別是計劃性容錯移轉和非計劃性容錯移轉。 在這兩種模式中,一旦複寫中斷,待命伺服器會先執行復原,再升階為主要伺服器,然後開啟以供讀取/寫入。 使用新的主要伺服器端點更新自動 DNS 項目後,應用程式可以使用相同的端點連線到該伺服器。 新的待命伺服器會在背景建立,讓應用程式可以維持連線能力。
高可用性狀態
您可以持續監視主要伺服器和待命伺服器的健康情況,並採取適當的動作來補救問題,包括觸發容錯移轉至待命伺服器。 下表列出可能的高可用性狀態:
| 狀態 | 說明 |
|---|---|
| 正在初始化 | 正在建立新的待命伺服器。 |
| 正在複寫資料 | 待命伺服器在建立之後會趕上主要伺服器。 |
| 良好 | 複寫處於穩定狀態且狀況良好。 |
| 正在容錯移轉 | 資料庫伺服器正在容錯移轉至待命伺服器。 |
| 正在移除待命伺服器 | 正在刪除待命伺服器。 |
| 未啟用 | 未啟用高可用性。 |
注意
您也可以在伺服器建立時或之後啟用高可用性。 如果您要在伺服器建立後的階段中啟用或停用高可用性,建議您在主要伺服器的活動較少時進行作業。
穩定狀態作業
PostgreSQL 用戶端應用程式會使用資料庫伺服器名稱連接到主要伺服器。 應用程式讀取會直接從主要伺服器提供。 同時,對應用程式的認可和寫入只有在主要伺服器和待命複本上都保存記錄資料後才會確認。 由於此額外的往返,應用程式可以預期寫入和認可的延遲會增加。 您可以在入口網站上監視高可用性的健康情況。
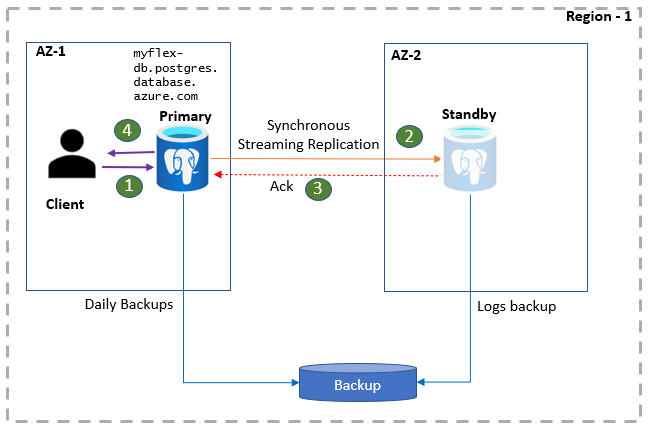
- 用戶端會連線到彈性伺服器並執行寫入作業。
- 變更會複寫至待命網站。
- 主要伺服器接收通知。
- 確認寫入/認可。
高可用性伺服器的時間點還原
針對設定了高可用性的彈性伺服器,記錄資料會即時複寫到待命伺服器。 主要伺服器上的任何使用者錯誤 (例如意外卸除資料表或不正確的資料更新) 都會複寫到待命伺服器。 因此,您無法使用待命伺服器從這類邏輯錯誤中復原。 若要從此類錯誤中復原,您必須從備份執行時間點還原。 使用彈性伺服器的時間點還原功能,您可以還原到錯誤發生之前的時間。 針對設定了高可用性的資料庫,新的資料庫伺服器會還原為單一區域彈性伺服器,並具有使用者所提供的新伺服器名稱。 您可以針對少數使用案例中使用還原的伺服器:
您可以將還原的伺服器用於生產,並選擇在相同區域 (zone) 上或相同區域 (region) 中的另一個區域 (zone) 上啟用待命複本的高可用性。
如果您想要還原物件,請從還原的資料庫伺服器匯出物件,並將其匯入至生產資料庫伺服器。
如果您想要複製資料庫伺服器以供測試和開發之用,或想要針對任何其他用途進行還原,您可以執行時間點還原。
若要了解如何進行彈性伺服器的時間點還原,請參閱彈性伺服器時間點還原。
容錯移轉支援
計劃性容錯移轉
計劃性停機事件包括由 Azure 排定的定期軟體更新和次要版本升級。 您也可以使用計劃性容錯移轉,讓主要伺服器回到偏好的可用性區域。 在高可用性中設定時,這些作業會先套用至待命複本,而應用程式會繼續存取主要伺服器。 更新待命複本之後,系統會清空主要伺服器連線,並觸發容錯移轉,啟動待命複本成為具有相同資料庫伺服器名稱的主要伺服器。 用戶端應用程式必須使用相同資料庫伺服器名稱來重新連線到新的主要伺服器,且可以繼續執行其作業。 新的待命伺服器會建立在與舊的主要伺服器相同的區域中。
針對其他由使用者起始的作業 (例如,scale-compute 或 scale-storage),系統會先在待命伺服器上套用變更,然後再套用至主要伺服器。 目前,服務不會容錯移轉到待命伺服器,因此在主要伺服器上執行縮放作業時,應用程式會短暫停機。
您也可以使用此功能來容錯移轉至待命伺服器,並縮短停機時間。 例如,在非計劃性容錯移轉之後,您的主要伺服器可能位於與應用程式不同的可用性區域。 您想要讓主要伺服器回到先前的區域,以與應用程式共置。
執行這項功能時,待命伺服器會先準備好,確保更新到最近的交易,讓應用程式能夠繼續執行讀取/寫入。 接下來,待命伺服器會升階,並中斷與主要伺服器的連線。 當新的待命伺服器在背景建立的同時,您的應用程式可以繼續寫入主要伺服器。 以下是與計劃性容錯移轉相關的步驟:
| Step | 說明 | 應用程式是否預期會停機? |
|---|---|---|
| 1 | 等候待命伺服器趕上主要伺服器。 | No |
| 2 | 內部監視系統會起始容錯移轉工作流程。 | No |
| 3 | 當待命伺服器接近主要伺服器的記錄序號 (LSN) 時,會封鎖應用程式寫入。 | Yes |
| 4 | 待命伺服器會升階成為獨立伺服器。 | Yes |
| 5 | DNS 記錄會以新待命伺服器的 IP 位址更新。 | Yes |
| 6 | 應用程式重新連線,並以新的主要伺服器繼續讀取/寫入。 | No |
| 7 | 新的待命伺服器會在另一個區域中建立。 | No |
| 8 | 待命伺服器會開始從 Azure Blob 復原其在建立期間遺漏的記錄。 | No |
| 9 | 主要伺服器與待命伺服器之間的穩定狀態會建立起來。 | No |
| 10 | 計劃性容錯移轉程序完成。 | No |
應用程式停機時間從步驟 3 開始,並在步驟 5 之後繼續作業。 其餘步驟會在背景中發生,不會影響應用程式寫入和認可。
提示
您可以選擇透過彈性伺服器排程 Azure 起始的維護活動,方法是在資料庫上活動預期很少的時候,依偏好選擇一天中 60 分鐘的時段。 如修補或次要版本升級等 Azure 維護工作會在該時段進行。 如果您未選擇自訂時段,則會為您的伺服器選取系統所配置、當地時間下午 11 點到上午 7 點之間的 1 小時時段。 針對設定了可用性區域的彈性伺服器,待命複本上也會執行這些 Azure 起始的維護活動。
如需可能的計劃性停機事件清單,請參閱計劃性停機事件。
未規劃的容錯移轉
可能會因為未預期的中斷 (例如基礎硬體故障、網路問題與軟體 Bug) 而發生非計劃性停機。 若設定高可用性的資料庫伺服器意外關閉,則會啟動待命複本,而且用戶端可以繼續其作業。 若未設定高可用性 (HA),則在重新啟動嘗試失敗時,會自動佈建新的資料庫伺服器。 雖然無法避免非計劃性停機,但彈性伺服器可不經人為介入就自動執行復原作業,協助減輕停機問題。
如需非計劃性容錯移轉和停機的相關資訊,包括可能的案例,請參閱非計劃性停機風險降低。
容錯移轉測試 (強制容錯移轉)
透過強制容錯移轉,您可以模擬非計劃性中斷案例,同時執行生產工作負載,並觀察應用程式的停機時間。 當您的主要伺服器沒有回應時,您也可以使用強制容錯移轉。
強制容錯移轉會將主要伺服器關閉,並起始執行待命伺服器升階作業的容錯移轉工作流程。 一旦待命伺服器完成復原程序至上次認可的資料,待命伺服器就會升階為主要伺服器。 DNS 記錄會更新,而且您的應用程式可以連線到升階的主要伺服器。 您的應用程式可以在新的待命伺服器於背景建立時繼續寫入主要伺服器,不會影響到運作時間。
以下是強制容錯移轉期間的步驟:
| Step | 說明 | 應用程式是否預期會停機? |
|---|---|---|
| 1 | 在收到容錯移轉要求之後,主要伺服器很快就會停止。 | Yes |
| 2 | 由於主要伺服器關閉,應用程式會經歷停機時間。 | Yes |
| 3 | 內部監視系統偵測到失敗,並起始容錯移轉至待命伺服器。 | Yes |
| 4 | 待命伺服器會在完全升階為獨立伺服器之前進入復原模式。 | Yes |
| 5 | 容錯移轉程序會等候待命復原作業完成。 | Yes |
| 6 | 伺服器啟動之後,DNS 記錄會以相同的主機名稱更新,但會使用待命伺服器的 IP 位址。 | Yes |
| 7 | 應用程式可以重新連線到新的主要伺服器,並繼續作業。 | No |
| 8 | 系統會建立慣用區域中的待命伺服器。 | No |
| 9 | 待命伺服器會開始從 Azure Blob 復原其在建立期間遺漏的記錄。 | No |
| 10 | 主要伺服器與待命伺服器之間的穩定狀態會建立起來。 | No |
| 11 | 強制容錯移轉程序完成。 | No |
應用程式停機預期會在步驟 1 之後啟動,並持續執行到步驟 6 完成為止。 其餘步驟會在背景中發生,不會影響應用程式寫入和認可。
重要
端對端容錯移轉流程包括 (a) 主要伺服器失敗後容錯移轉至待命伺服器和 (b) 建立處於穩定狀態的新待命伺服器。 由於在容錯移轉至待命伺服器的作業完成之前,您的應用程式都會停機,因此請從您的應用程式/用戶端視角衡量停機時間,而不是從整體的端對端容錯移轉流程來衡量。
執行強制容錯移轉時的考量
整體端對端作業時間可能看似比應用程式經歷的實際停機時間更長。
重要
請一律從應用程式的觀點觀察停機時間!
請勿執行立即、連續的容錯移轉。 在容錯移轉之間等候至少 15-20 分鐘,以讓新的待命伺服器得以完全建立。
建議您在低活動期間執行強制容錯移轉,以減少停機時間。
故障轉移後PostgreSQL統計數據的最佳做法
在 PostgreSQL 故障轉移之後,維護最佳資料庫效能的主要機制牽涉到瞭解pg_statistic和pg_stat_* 數據表的不同角色。 數據表 pg_statistic 包含優化工具統計數據,這對查詢規劃工具至關重要。 這些統計數據包括數據表中的數據分佈,並在故障轉移后保持不變,確保查詢規劃工具可以根據精確的歷程記錄數據散發資訊,有效地優化查詢執行。
相反地, pg_stat_* 記錄活動統計數據的數據表,例如掃描數目、讀取 Tuple 和更新,會在故障轉移時重設。 這類數據表的範例是 pg_stat_user_tables,它會追蹤使用者定義數據表的活動。 此重設的設計目的是要準確反映新的主要作業狀態,但也表示遺失可通知自動數據清理程式和其他作業效率的歷史活動計量。
鑒於此差異,遵循 PostgreSQL 故障轉移的最佳做法是執行 ANALYZE。 此動作會 pg_stat_* 使用全新的活動統計數據來更新數據表, pg_stat_user_tables協助自動清理程式並確保資料庫效能在其新角色中保持最佳狀態。 此主動式步驟可橋接保留基本優化工具統計數據與重新整理活動計量之間的差距,以符合資料庫的目前狀態。
區域關閉體驗
區域性:若要從區域層級失敗中復原,您可以使用備份執行時間點還原。 您可以選擇時間最新的自訂還原點來還原最新資料。 新的彈性伺服器會部署在另一個未受影響的區域中。 還原所花費的時間取決於先前的備份,以及要復原的交易記錄量。
如需時間點還原的詳細資訊,請參閱適用於 PostgreSQL 的 Azure 資料庫 - 彈性伺服器中的備份與還原。
區域備援:彈性伺服器會在 60-120 秒內自動容錯移轉至待命伺服器,且零資料遺失。
沒有可用性區域的設定
您可以設定不啟用高可用性的彈性伺服器,但不建議這麼做。 若為未設定高可用性的彈性伺服器,該服務能提供有三個資料複本的區域備援儲存體、區域備援備份 (在支援的區域中) 以及內建的伺服器復原功能,以自動重新啟動損毀的伺服器,並將伺服器重新放置到另一個實體節點。 此設定提供 99.9% 的運作時間 SLA。 如果伺服器在計劃性或非計劃性的容錯移轉事件期間關閉,服務會使用下列自動化程序來維持伺服器的可用性:
- 佈建新的計算 Linux VM。
- 將具有資料檔案的儲存體對應到新的虛擬機器。
- PostgreSQL 資料庫引擎會在新的虛擬機器上上線。
下圖顯示 VM 和儲存體失敗之間的轉換。

跨區域災害復原和商務持續性
在發生全區域災害的情況下,Azure 可透過災害復原功能,使用另一個區域防範區域性災害或大地理區域的災害。 如需 Azure 災害復原架構的詳細資訊,請參閱 Azure 至 Azure 災害復原架構。
彈性伺服器提供的功能可保護資料,並在計劃性與非計劃性停機事件期間,降低任務關鍵性資料庫的停機時間。 建置在會提供強固恢復能力與可用性的 Azure 基礎結構之上,彈性伺服器可提供商務持續性功能,以提供錯誤保護、解決復原時間需求,以及降低資料外洩暴露風險。 建構應用程式時,應該考慮停機時間容錯 (復原時間目標 (RTO)) 與資料外洩暴露風險 (復原點目標 (RPO))。 例如,相較於測試資料庫,業務關鍵資料庫需要更嚴格的運作時間。
多區域地理位置的災害復原
異地備援備份和還原
異地備援備份和還原可讓您在發生災害時,於不同區域還原伺服器。 這也提供在一年中至少 99.99999999999999% (16 個 9) 的備份物件持久性。
異地備援備份只能在伺服器建立時設定。 伺服器設定為異地備援備份時,備份資料和交易記錄會透過儲存體複寫以非同步方式複製到配對的區域。
如需異地備援備份和還原的詳細資訊,請參閱異地備援備份和還原。
讀取複本
您可以部署跨區域讀取複本,以保護資料庫免於區域層級的失敗。 讀取複本會使用 PostgreSQL 的實體複寫技術以非同步方式更新,而且可能會延遲主要複本。 一般用途與記憶體最佳化的計算層會支援讀取複本。
如需讀取複本功能和考量事項的詳細資訊,請參閱讀取複本。
中斷偵測、通知和管理
若您的伺服器已設定異地備援備份,則可以在配對的區域中執行異地還原。 新伺服器會佈建並復原到最後一個複製到此區域的資料。
您也可以使用跨區域讀取複本。 發生區域失敗時,您可以將讀取複本升階為獨立的可讀寫伺服器,以執行災害復原作業。 RPO 預期最多只有 5 分鐘 (可能會遺失資料),但發生伺服器區域失敗時例外,這時 RPO 會接近複寫延遲。
如需區域性災害後的非計劃性停機風險降低和復原詳細資訊,請參閱非計劃性停機風險降低。