在 Azure Machine Learning 工作室中管理提示流程計算工作階段
提示流程計算工作階段能提供執行應用程式所需的運算資源,包括包含所有必要相依性套件的 Docker 映像。 這個可靠且可調整的環境可讓提示流程有效率地執行其工作和功能,以獲得順暢的使用者體驗。
計算工作階段管理的權限和角色
若要指派角色,您必須擁有資源的 owner 或 Microsoft.Authorization/roleAssignments/write 權限。
針對計算工作階段的使用者,請在工作區中指派 AzureML Data Scientist 角色。 若要深入了解,請參閱管理對 Azure Machine Learning 工作區的存取。
角色指派最多可能需要幾分鐘的時間才會生效。
在 Studio 中開始計算工作階段
使用 Azure Machine Learning 工作室開始計算工作階段之前,請確定:
- 您擁有工作區中的
AzureML Data Scientist角色。 - 工作區中的預設資料存放區 (通常是
workspaceblobstore) 為 Blob 類型。 - 工作目錄 (
workspaceworkingdirectory) 存在於工作區中。 - 如果使用虛擬網路進行提示流程,則您必須了解提示流程中的網路隔離考量。
在流程頁面上開始計算工作階段
一個流程會繫結至一個計算工作階段。 您可以在流程頁面上開始計算工作階段。
選取 [開始]。 使用流程資料夾中的
flow.dag.yaml中定義的環境來開始計算工作階段,其會以虛擬機器 (VM) 大小的無伺服器計算執行,且您在工作區中必須有足夠的配額。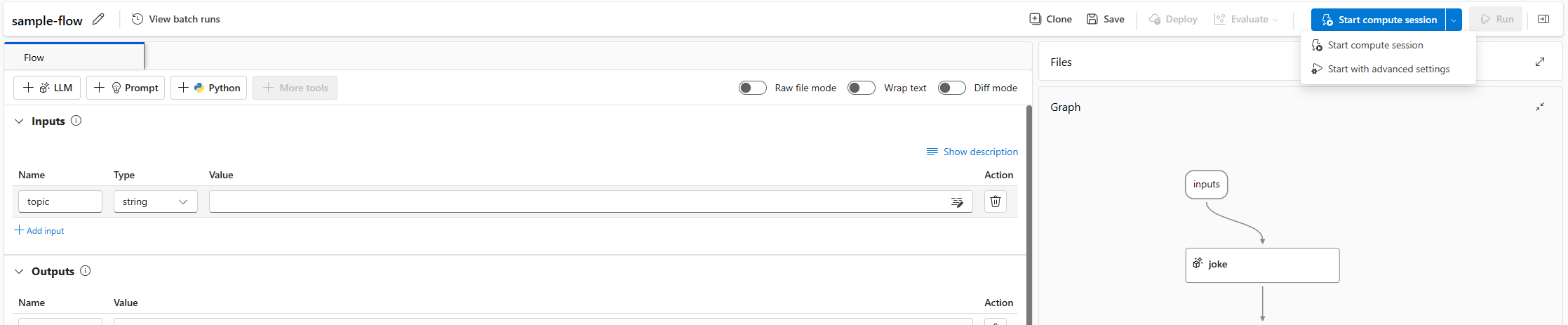
選取 [使用進階設定開始]。 在進階設定中,您可以:
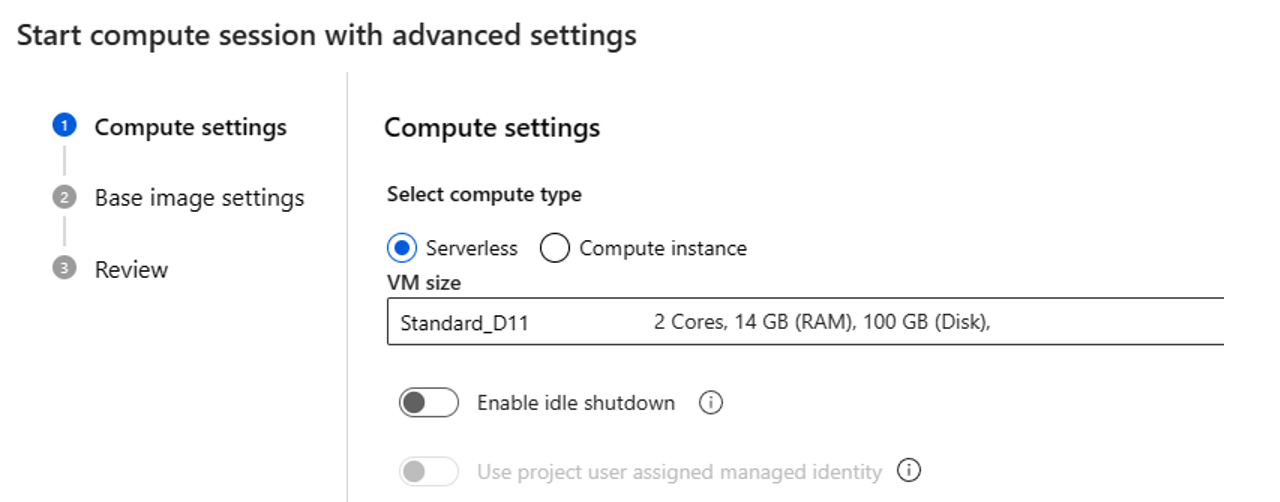
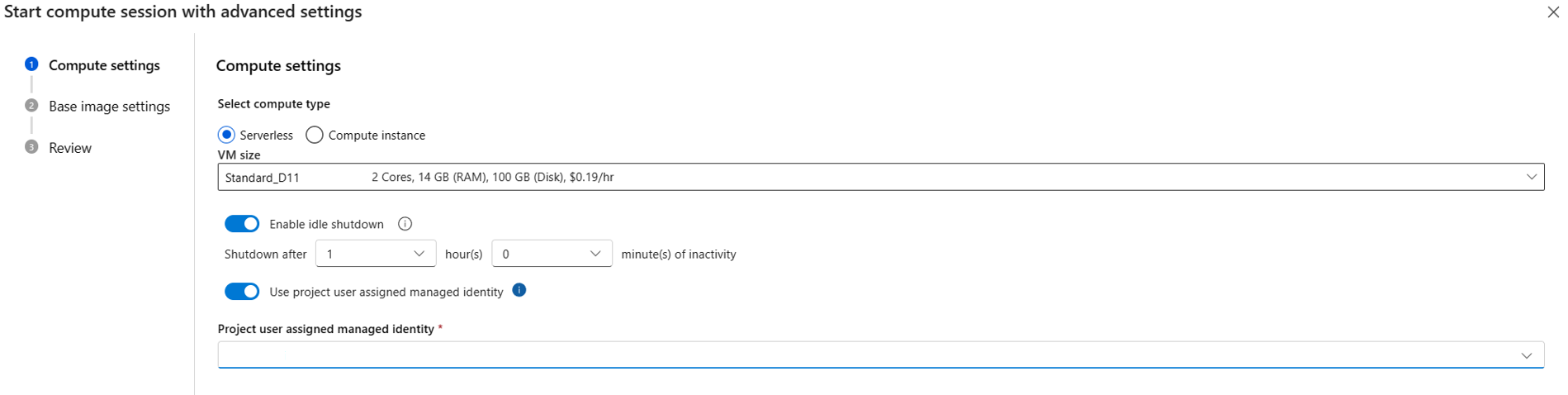
- 選取計算類型。 您可以在無伺服器計算和計算執行個體之間選擇。
如果您選擇無伺服器計算,您可以設定下列設定:
- 自訂計算工作階段使用的 VM 大小。 請選擇 VM 系列 D 和更高效能的系列。 如需詳細資訊,請參閱支援的 VM 系列和大小一節
- 自訂閒置時間,其會在計算工作階段有一段時間未使用的情況下,會自動刪除該計算工作階段。
- 設定使用者指派的受控識別。 計算工作階段會使用此身分識別來提取基礎映像、對連線進行驗證,並安裝套件。 請確定使用者指派的受控識別具有足夠的權限。 如果您未設定此身分識別,我們預設會使用使用者身分識別。
- 您可以使用下列 CLI 命令,將使用者指派的受控識別指派給工作區。 深入了解如何為工作區建立和更新使用者指派的身分識別。
az ml workspace update -f workspace_update_with_multiple_UAIs.yml --subscription <subscription ID> --resource-group <resource group name> --name <workspace name>其中 workspace_update_with_multiple_UAIs.yml 的內容如下:
identity: type: system_assigned, user_assigned user_assigned_identities: '/subscriptions/<subscription_id>/resourcegroups/<resource_group_name>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<uai_name>': {} '<UAI resource ID 2>': {}提示
Azure Machine Learning 工作區的使用者指派受控識別上需要下列 Azure RBAC 角色指派,才能存取工作區相關聯資源上的資料。
資源 權限 Azure Machine Learning 工作區 參與者 Azure 儲存體 參與者 (控制平面) + 儲存體 Blob 資料參與者 + 儲存體檔案資料特殊權限參與者 (資料平面,取用檔案共用中的流程草稿和 Blob 中的資料) Azure Key Vault (使用存取原則權限模型時) 參與者 + 清除作業以外的任何存取原則權限,這是連結 Azure Key Vault 的 預設模式。 Azure Key Vault (使用 RBAC 權限模型時) 參與者 (控制平面) + Key Vault 系統管理員 (資料平面) Azure Container Registry 參與者 Azure Application Insights 參與者 注意
作業提交者需要使用者指派受控識別的
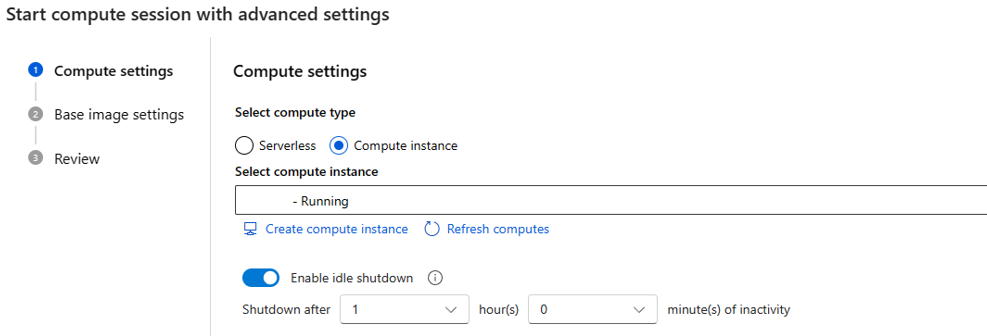
assign權限,您可以指派Managed Identity Operator角色,因為每次建立無伺服器計算工作階段時,都會指派使用者指派的受控識別,以進行計算。如果您選擇計算執行個體作為計算類型,則只能設定閒置關機時間。
因為其是在現有的計算執行個體上執行,因此 VM 大小已經固定,且無法從工作階段端加以變更。
此工作階段所使用的身分識別也會在計算執行個體中定義,其預設會使用使用者身分識別。 深入了解如何將身分識別指派給計算執行個體 (部分機器翻譯)
針對閒置關機時間,其會用來定義計算工作階段的生命週期,如果工作階段在您設定的時間內皆處於閒置狀態,系統就會自動加以刪除。 而且,若您已在計算執行個體上啟用閒置關機,則其便會在計算層級生效。
深入了解如何建立和管理計算執行個體 (部分機器翻譯)
- 選取計算類型。 您可以在無伺服器計算和計算執行個體之間選擇。



使用計算工作階段在 CLI/SDK 中提交流程執行
此外,您也可以在提交流程執行時,在 CLI/SDK 中指定計算工作階段。
您也可以在資源組件下指定執行個體類型或計算執行個體名稱。 如果您未指定執行個體類型或計算執行個體名稱,Azure Machine Learning 會根據配額、成本、效能和磁碟大小等因素選擇執行個體類型 (VM 大小)。 深入了解無伺服器計算。
$schema: https://azuremlschemas.azureedge.net/promptflow/latest/Run.schema.json
flow: <path_to_flow>
data: <path_to_flow>/data.jsonl
# specify identity used by serverless compute.
# default value
# identity:
# type: user_identity
# use workspace first UAI
# identity:
# type: managed
# use specified client_id's UAI
# identity:
# type: managed
# client_id: xxx
column_mapping:
url: ${data.url}
# define cloud resource
resources:
instance_type: <instance_type> # serverless compute type
# compute: <compute_instance_name> # use compute instance as compute type
透過 CLI 提交此執行:
pfazure run create --file run.yml
注意
如果您使用 CLI/SDK 提交流程執行,則閒置關機為一小時。 您可以移至計算頁面以釋放計算。
流程資料夾外部的參考檔案
有時候,您可能想要參考流程資料夾外的 requirements.txt 檔案。 例如,您可能有包含多個流程的複雜專案,而且它們共用相同的 requirements.txt 檔案。 若要這樣做,您可以將此 additional_includes 欄位新增至 flow.dag.yaml。 此欄位的值是流程資料夾的相對檔案/資料夾路徑清單。 例如,如果 requirements.txt 位於流程資料夾的父資料夾中,您可以將 ../requirements.txt 新增至 additional_includes 欄位。
inputs:
question:
type: string
outputs:
output:
type: string
reference: ${answer_the_question_with_context.output}
environment:
python_requirements_txt: requirements.txt
additional_includes:
- ../requirements.txt
...
requirements.txt 檔案會複製到流程資料夾,並加以用來開始計算工作階段。
在 Studio 流程頁面上更新計算工作階段
在流程頁面上,您可以使用下列選項來管理計算工作階段:
- 變更計算工作階段設定,您可以針對無伺服器計算變更 VM 大小和使用者指派的受控識別等計算設定,如果您使用計算執行個體,則可以變更為使用其他執行個體。 您也可以變更
- 也可以變更使用者指派的受控識別以進行無伺服器計算。 如果您變更 VM 大小,計算工作階段會搭配新的 VM 大小重設。 如果您
- 從 requirements.txt 安裝套件 在提示流程 UI 中開啟
requirements.txt,您可以在其中安裝套件。 - [檢視已安裝的套件] 會顯示在計算工作階段安裝的套件。 其中包括安裝至基礎映像的套件,以及流程資料夾中
requirements.txt檔案中指定的套件。 - [重設計算工作階段] 會刪除目前的計算工作階段,並建立具有相同環境的新工作階段。 如果您遇到套件衝突問題,可以嘗試此選項。
- [停止計算工作階段] 會刪除目前的計算工作階段。 如果底層計算上沒有作用中的計算工作階段,也會刪除無伺服器計算資源。

您也可以在流程資料夾中的 requirements.txt 檔案中新增套件,以自訂用來執行此流程的環境。 在此檔案中新增更多套件之後,您可以選擇下列其中一個選項:
- [儲存並安裝] 會在流程資料夾中觸發
pip install -r requirements.txt。 程序可能需要幾分鐘的時間,視您安裝的套件而定。 - [僅儲存] 只會儲存
requirements.txt檔案。 您稍後可以自行安裝套件。

注意
您可以變更 requirements.txt 的位置,甚至是檔名,但務必同時在流程資料夾中的 flow.dag.yaml 檔案中進行變更。
請勿在 requirements.txt 中釘選 promptflow 和 promptflow-tools 的版本,因為我們已將其包括在工作階段基礎映像中。
requirements.txt 不支援本機 Wheel 檔案。 在您的映像中加以建置,並在 flow.dag.yaml 中更新自訂基礎映像。 深入了解如何建置自訂基礎映像。
在 Azure DevOps 的私人摘要中新增套件
如果您想要在 Azure DevOps 中使用私人摘要,請遵循下列步驟:
將受控識別指派給工作區或計算執行個體。
使用無伺服器計算作為計算工作階段,您必須將使用者指派的受控識別指派給工作區。
建立使用者指派的受控識別,並在 Azure DevOps 組織中新增此身分識別。 若要深入了解,請參閱使用服務主體和受控識別。
注意
如果看不到 [新增使用者] 按鈕,您可能沒有執行此動作的必要權限。
-
注意
請確定使用者指派的受控識別在已連結至工作區的金鑰保存庫上具有
Microsoft.KeyVault/vaults/read。
使用計算執行個體作為計算工作階段時,您需要將使用者指派的受控識別指派至計算執行個體 (部分機器翻譯)。
將
{private}新增至您的私人摘要 URL。 例如,如果您想要在 Azure DevOps 中從test_feed安裝test_package,請在requirements.txt中新增-i https://{private}@{test_feed_url_in_azure_devops}:-i https://{private}@{test_feed_url_in_azure_devops} test_package在計算工作階段設定中指定使用使用者指派的受控識別。
如果您使用無伺服器計算,在計算工作階段未執行的情況下,請在 [使用進階設定開始] 中指定使用者指派的受控識別;在計算工作階段正在執行的情況下,請使用 [變更計算工作階段設定] 按鈕。
如果您使用計算執行個體,其會使用您指派給計算執行個體的使用者指派的受控識別。

注意
此方法主要著重於流程開發階段的快速測試,如果您也想要將此流程部署為端點,請在映像中建置此私人摘要,並在 flow.dag.yaml 中更新自訂基礎映像。 深入了解如何建置自訂基礎映像 (部分機器翻譯)
變更計算工作階段的基礎映像
根據預設,我們會使用最新的提示流程基礎映像。 如果您要使用不同的基礎映像,您可以建置自訂映像。
- 在 Studio 中,您可以在計算工作階段設定下,變更基礎映像設定中的基礎映像。

您也可以在流程資料夾中
flow.dag.yaml檔案的environment下指定新的基礎映像。
environment: image: <your-custom-image> python_requirements_txt: requirements.txt

若要使用新的基礎映像,您必須重設計算工作階段。 此程序需要幾分鐘的時間,因為它會提取新的基礎映像並重新安裝套件。
管理計算工作階段所使用的無伺服器執行個體
當您使用無伺服器計算作為計算工作階段時,您可以管理無伺服器執行個體。 在計算頁面上的 [計算工作階段清單] 索引標籤中檢視無伺服器執行個體。

您也可以在 [作用中流程和執行] 索引標籤底下存取在計算上執行的流程和執行。刪除執行個體會影響其上方的流程和執行。

計算工作階段、計算資源、流程和使用者之間的關聯性
- 一個單一使用者可以有多個計算資源 (無伺服器或計算執行個體)。 由於不同的需求,單一使用者可以有多個計算資源。 例如,一個使用者可以有具有不同 VM 大小或不同使用者指派的受控識別的多個計算資源。
- 一個計算資源只能供單一使用者使用。 計算資源會作為單一使用者的私人開發箱使用。 多個使用者無法共用相同的計算資源。
- 一個計算資源可以裝載多個計算工作階段。 計算工作階段是在底層計算資源上執行的容器。 例如,提示流程撰寫不需要太多計算資源,因此單一計算資源可以裝載來自相同使用者的多個計算工作階段。
- 一個計算工作階段同時只能屬於單一計算資源。 但您可以刪除或停止計算工作階段,並將其重新配置給另一個計算資源。
- 一個流程只能有一個計算工作階段。 每個流程都是獨立的,並會在計算工作階段的流程資料夾中定義基礎映像和必要的 Python 套件。
將執行階段切換至計算工作階段
比起計算執行個體執行階段,計算工作階段具有下列優點:
- 自動管理工作階段和底層計算的生命週期。 您不再需要手動建立和管理。
- 在流程資料夾中的
requirements.txt檔案中新增套件,而不用建立自訂環境,讓您輕鬆自訂套件。
使用下列步驟將計算執行個體執行階段切換至計算工作階段:
- 準備流程資料夾中的
requirements.txt檔案。 確保未在requirements.txt中釘選promptflow和promptflow-tools的版本,因為我們已將其包括在基礎映像中。 計算工作階段會在啟動時,將套件安裝在requirements.txt檔案中。 - 如果您建立自訂環境來建立計算執行個體執行階段,您可以從環境詳細資料頁面取得映像,並在流程資料夾中的
flow.dag.yaml檔案中指定。 若要深入了解,請參閱變更計算工作階段的基礎映像。 請確定您或工作區上相關的使用者指派受控識別具有映像的acr pull權限。

- 針對計算資源,如果您想要手動管理生命週期,可以繼續使用現有的計算執行個體,或是嘗試使用其生命週期是由系統管理的無伺服器計算。
下一步
- 如何自訂計算工作階段的基礎映像 (部分機器翻譯)
- 開發標準流程
- 開發聊天流程