評估自動化機器學習實驗結果
在本文中,您將了解如何評估和比較自動化機器學習 (自動化 ML) 實驗所定型的模型。 在進行自動化 ML 實驗的過程中,您會建立許多作業,而且每個作業都會建立模型。 針對每個模型,自動化 ML 會產生評估計量和圖表,以協助您測量模型的效能。 此外,也可以產生負責任 AI 儀表板,對預設的建議最佳模型進行整體評量和偵錯, 包括模型說明、公平性與效能總管、資料總管、模型錯誤分析等深入解析。 進一步了解如何產生負責任 AI 儀表板。
例如,自動化 ML 會根據實驗類型產生下列圖表。
| 分類 | 迴歸/預測 |
|---|---|
| 混淆矩陣 | 殘差長條圖 |
| (ROC) 曲線 | 預測與真值 |
| (PR) 曲線 | 預測範圍 |
| 升力曲線 | |
| 累積增益曲線 | |
| 校正曲線 |
重要
本文中標示為 (預覽) 的項目目前處於公開預覽狀態。 此預覽版本會在沒有服務等級協定的情況下提供,不建議用於實際執行工作負載。 可能不支援特定功能,或可能已經限制功能。 如需詳細資訊,請參閱 Microsoft Azure 預覽版增補使用條款。
必要條件
- Azure 訂用帳戶。 (如果您沒有 Azure 訂閱,請在開始之前,先建立免費帳戶)
- 以下列其中一種方式建立的 Azure Machine Learning 實驗:
檢視作業結果
當您的自動化 ML 實驗完成之後,可以透過下列方式找到作業的歷程記錄:
- 具有 Azure Machine Learning 工作室的瀏覽器
- 使用 JobDetails Jupyter 介面控件的 Jupyter 筆記本
下列步驟和影片示範如何在工作室中檢視執行歷程記錄和模型評估計量和圖表:
- 登入工作室,並巡覽至您的工作區。
- 在左側功能表中,選取 [作業]。
- 從實驗清單中選取您的實驗。
- 在頁面底部的表格中,選取自動化 ML 作業。
- 在 [模型] 索引標籤中,為您想要評估的模型選取 [演算法名稱]。
- 在 [計量] 索引標籤中,使用左側的核取方塊,以檢視計量和圖表。
分類計量
自動化 ML 會針對您實驗所產生的每個分類模型計算效能計量。 這些計量是以 scikit learn 實作為基礎。
許多分類計量都是針對兩個類別上的二進位分類所定義,而且需要對類別算出平均,以針對多類別分類產生一個分數。 Scikit-learn 提供數個平均方法,其中三個自動化 ML 公開:宏平均、微平均和加權。
- 宏平均 - 計算每個類別的計量,並採用未加權平均
- 微平均 - 藉由計算確判為真、誤判為假和誤判為真的總數,來全域計算計量 (與類別無關)。
- 加權 - 計算每個類別的計量,並根據每個類別的樣本數目來取得加權平均。
雖然每個平均方法都有其優點,但在選取適用方法時,其中一個常見的考量是類別不平衡。 如果類別具有不同的樣本數目,使用宏平均可能更有參考價值,其中,少數類別與大多數類別的權重相同。 深入了解自動化 ML 中的二進位與多類別計量。
下表摘要說明自動化 ML 針對您實驗產生的每個分類模型所計算的模型效能計量。 如需詳細資訊,請參閱每個計量的 [計算] 欄位中所連結的 scikit-learn 文件。
注意
如需影像分類模型計量的其他詳細資料,請參閱影像計量一節。
| 計量 | 描述 | 運算 |
|---|---|---|
| AUC | AUC 是接收者作業特性曲線下方的面積。 目標: 更接近 1 範圍: [0, 1] 支援的計量名稱包括 AUC_macro,即每個類別之 AUC 的算數平均值。AUC_micro,藉由計算確判為真、誤判為假和誤判為真的總計而得。 AUC_weighted,是每個類別的分數的算術平均值,以每個類別中 true 執行個體數目為權重來加權。 AUC_binary,即 AUC 的值,會將一個特定類別視為 true 類別,並將所有其他類別合併為 false 類別。 |
運算 |
| 精確度 | 精確度是完全符合 true 類別標籤的預測比率。 目標: 更接近 1 範圍: [0, 1] |
運算 |
| average_precision | Average precision 摘要出精確度-召回率曲線,為每個閾值到達的精確度加權平均值,並以上個閾值的召回率中的增值作為權重。 目標: 更接近 1 範圍: [0, 1] 支援的計量名稱包括 average_precision_score_macro,是每個類別其平均精確度分數的算術平均值。average_precision_score_micro,藉由計算確判為真、誤判為假和誤判為真的總計而得。average_precision_score_weighted,是每個類別其平均精確度分數的算術平均值,以每個類別中 true 執行個體的數目為權重來加權。 average_precision_score_binary,即平均精確度的值,會將某個特定類別視為 true 類別,並將所有其他類別合併成 false 類別。 |
運算 |
| balanced_accuracy | Balanced accuracy 是每個類別其召回率的算術平均值。 目標: 更接近 1 範圍: [0, 1] |
運算 |
| f1_score | F1 分數是精確度和召回率的調和平均數。 這是誤判為真和誤判為假的對稱量值。 不過,其中並不會納入確判為假。 目標: 更接近 1 範圍: [0, 1] 支援的計量名稱包括 f1_score_macro:每個類別其 F1 分數的算術平均值。 f1_score_micro:藉由計算確判為真、誤判為假和誤判為真的總計而得。 f1_score_weighted:以每個類別的 F1 分數其類別頻率將平均值加權。 f1_score_binary,f1 的值,會將一個特定類別視為 true 類別,並將所有其他類別合併為 false 類別。 |
運算 |
| log_loss | 這是損失函數,用於 (多維度) 羅吉斯迴歸及其擴充功能,例如,類神經網路,如果有機率分類器的預測時,則定義為 true 標籤的負數對數似然比。 目標: 更接近 0 範圍: [0, inf) |
運算 |
| norm_macro_recall | 標準化的宏平均重新叫用是重新叫用的宏平均,並已經過標準化,因此隨機效能的分數為 0,完美效能的分數為 1。 目標: 更接近 1 範圍: [0, 1] |
(recall_score_macro - R) / (1 - R) 其中, R 是 recall_score_macro 的預測值,適用於隨機預測。R = 0.5 適用於二進位分類。 R = (1 / C) 適用於 C 類別分類問題。 |
| matthews_correlation | 馬修斯相互關聯係數是精確度的對稱量值,即使某個類別的樣本數超過另一個類別,也可以使用此量值。 係數 1 表示完美預測、0 表示隨機預測,-1 表示反向預測。 目標: 更接近 1 範圍: [-1, 1] |
運算 |
| 有效位數 | 精確度可讓模型避免將負樣本標記為正。 目標: 更接近 1 範圍: [0, 1] 支援的計量名稱包括 precision_score_macro,每個類別其精確度的算術平均值。 precision_score_micro,透過計算確判為真和誤判為真的總計,進行全域計算而得。 precision_score_weighted,每個類別的精確度算術平均值,以每個類別中 true 執行個體數目為權重加權。 precision_score_binary,精確度的值,會將某個特定類別視為 true 類別,並將所有其他類別合併成 false 類別。 |
運算 |
| 召回率 | 重新叫用是使用模型來偵測所有正樣本的能力。 目標: 更接近 1 範圍: [0, 1] 支援的計量名稱包括 recall_score_macro:每個類別重新叫用的算術平均值。 recall_score_micro:透過計算確判為真、誤判為假和誤判為真的總計,進行全域計算而得。recall_score_weighted:每個類別的重新叫用算術平均值,以每個類別中 true 執行個體數目為權重加權。 recall_score_binary,重新叫用的值,會將某個特定類別視為 true 類別,並將所有其他類別合併為 false 類別。 |
運算 |
| weighted_accuracy | 加權精確度是每個樣本都是由屬於相同類別的樣本總數加權的精確度。 目標: 更接近 1 範圍: [0, 1] |
運算 |
二進位與多類別分類計量
自動 ML 會自動偵測資料是否為二進位,而且即使資料是多類別,也允許使用者藉由指定 true 類別來啟動二進位分類計量。 如果資料集有兩個或以上的類別,便會回報多類別分類計量。 只有當資料為二進位時,才會回報二進位分類計量。
請注意,多類別分類計量適用於多類別分類。 套用至二進位資料集時,這些計量並不會如您預期,將任何類別視為 true 類別。 明確適用於多類別的計量會加上後置字元 micro、macro 或 weighted。 範例包括 average_precision_score、f1_score、precision_score、recall_score 和 AUC。 例如,多類別平均重新叫用 (micro、macro 或 weighted) 是平均計算二進位分類資料集的兩個類別,而不是將重新叫用計算為 tp / (tp + fn)。 這相當於個別針對 true 類別和 false 類別計算重新叫用,然後取得兩者的平均值。
此外,雖然支援自動偵測二進位分類,但仍建議您一律手動指定 true 類別,以確定針對正確的類別計算二進位分類計量。
若要在資料集本身為多類別時,為二進位分類啟動計量,使用者只需要指定要視為 true 類別的類別,系統就會計算這些計量。
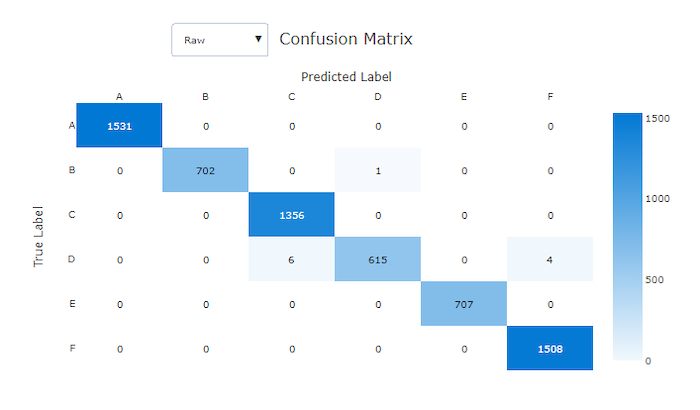
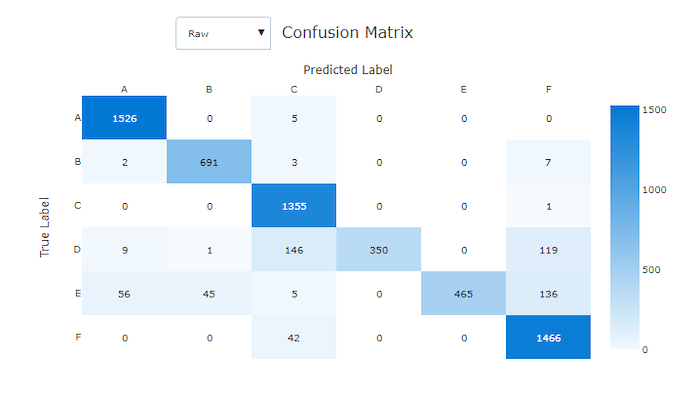
混淆矩陣
混淆矩陣讓機器學習模型如何在其分類模型的預測中出現系統錯誤,提供了視覺效果。 名稱中的「confusion」一詞來自模型「confusing」或標記錯誤的樣本。 混淆矩陣中資料列 i 和資料行 j 的儲存格包含屬於類別 C_i 之評估資料集中的樣本數目,以及由模型分類為類別 C_j 的樣本數目。
在工作室中,深色的儲存格表示較高的樣本數目。 在下拉式清單中選取 [標準化] 檢視,會在每個矩陣資料列進行標準化,以顯示預測為類別 C_j 的類別 C_i 百分比。 預設原始檢視的優點是,您可以看到實際類別分布的不平衡是否造成模型對少數類別的樣本進行錯誤分類,這是不平衡資料集的一個常見問題。
良好模型的混淆矩陣其大部分樣本會沿著對角線。
良好模型的混淆矩陣
不良模型的混淆矩陣
ROC 曲線
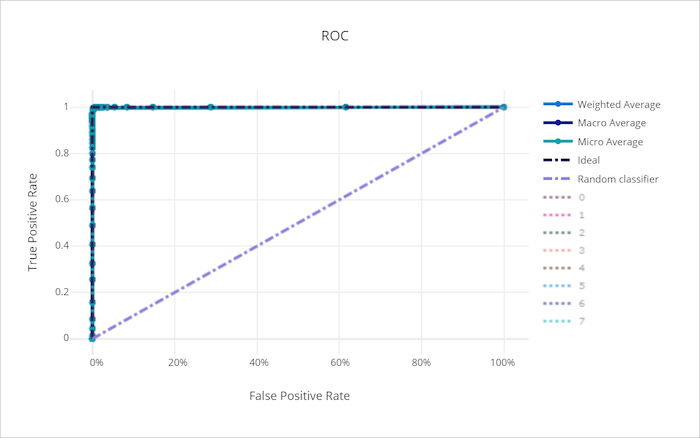
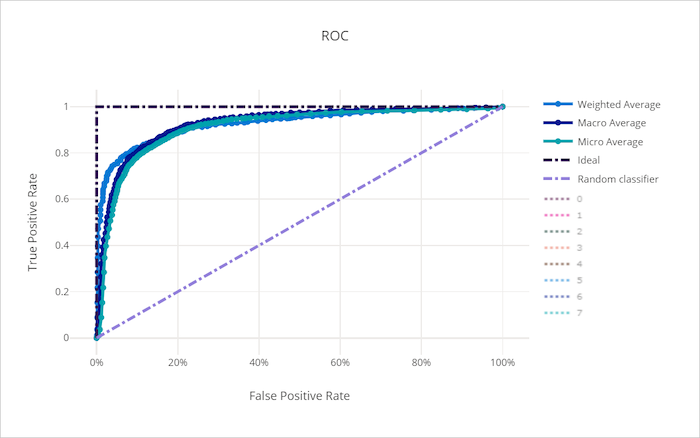
受試者操作特徵 (ROC) 曲線繪製隨著決策閾值的變化,確判為真比率 (TPR) 和誤判為真比率 (FPR)之間的關聯性。 在高類別不平衡的資料集上定型模型時,ROC 曲線的資訊量可能較少,因為大多數類別可能會蓋過少數類別的貢獻。
曲線下方面積 (AUC) 可以解譯為正確分類樣本的比例。 更確切地說,AUC 是分類器將隨機選擇的正樣本排在高於隨機選擇之負樣本的可能性。 曲線的形狀為 TPR 和 FPR 之間的關聯性,做為分類閾值或決策界限的功能,提供直觀印象。
接近圖表左上角的曲線會接近 100% TPR 和 0% FPR,這是可能的最佳模型。 隨機模型會沿著左下角到右上角的 y = x 線條,產生 ROC 曲線。 比隨機模型更糟的是,它的 ROC 曲線會低於 y = x 線條。
提示
對於分類實驗,針對自動化 ML 模型產生的每個折線圖都可以用來針對每個類別或所有類別的平均值來評估模型。 您可以按一下圖表右邊圖例中的類別標籤,在這些不同的檢視之間切換。
良好模型的 ROC 曲線
不良模型的 ROC 曲線
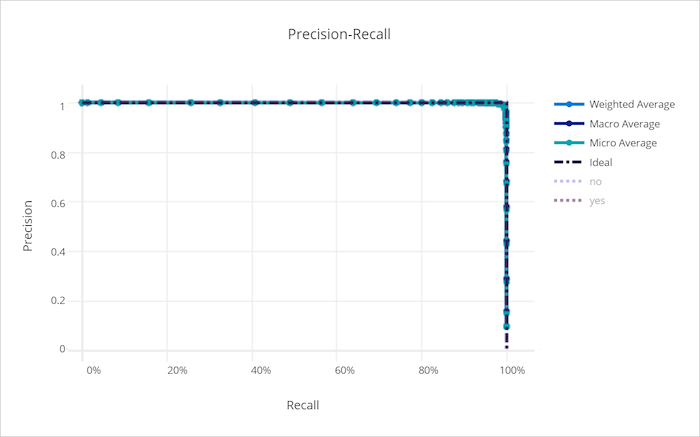
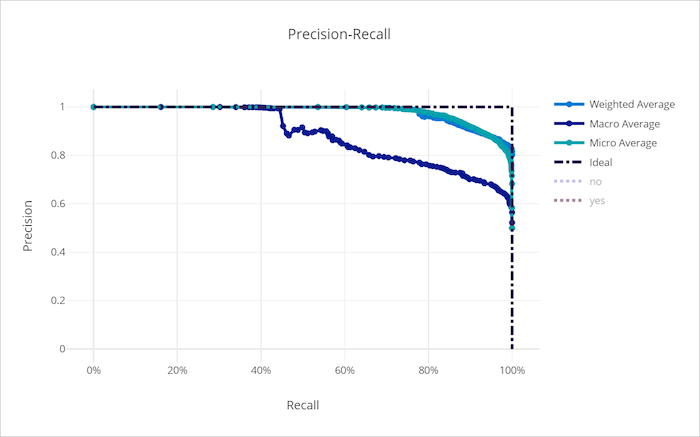
精確度 - 重新叫用曲線
精確度重新叫用曲線會繪製精確度和重新叫用之間的關聯性,以做為決策閾值的變更。 重新叫用是模型偵測所有正樣本的能力,而精確度可讓模型避免將負樣本標記為正。 某些商務問題可能需要較高的重新叫用和更高的精確度,取決於避免誤判為假與誤判為真的相對重要性。
提示
對於分類實驗,針對自動化 ML 模型產生的每個折線圖都可以用來針對每個類別或所有類別的平均值來評估模型。 您可以按一下圖表右邊圖例中的類別標籤,在這些不同的檢視之間切換。
良好模型的精確性 - 重新叫用曲線
不良模型的精確性 - 重新叫用曲線
累積增益曲線
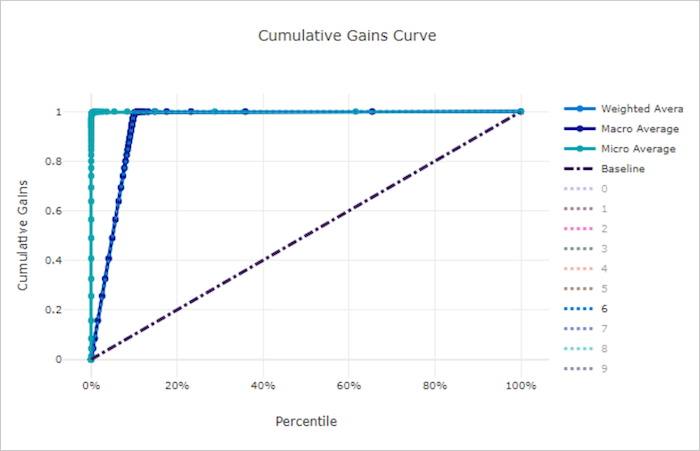
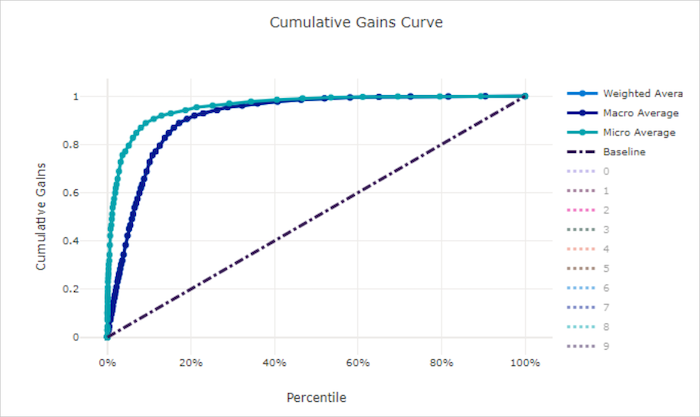
累積增益曲線繪製正確分類為正樣本百分比的函式,並根據預測可能性的順序來考量樣本。
若要計算增益,請先將所有樣本從模型預測的最高可能性排序到最低可能性。 然後採用最高信賴度預測的 x%。 將 x% 偵測到的正樣本數目除以正樣本總數,以取得增益。 累積增益是指在考慮最可能屬於正類別的一些資料百分比時,所偵測到的正樣本百分比。
完美的模型會將所有正樣本排在所有負樣本之上,提供以兩個直線段組成的累積增益曲線。 第一個是斜率為 1 / x 的線條,從 (0, 0) 到 (x, 1),其中 x 是屬於正類別的樣本比例 (如果類別為平衡,則為 1 / num_classes)。 第二個是從 (x, 1) 到 (1, 1) 的水平線。 在第一個區段中,會正確分類所有正樣本,並在考慮樣本的第一個 x% 樣本內,累積增益達到 100%。
基準線隨機模型具有一個累積增益曲線,即 y = x,其中,對於所考量樣本的 x%,只會偵測大約 x% 個正樣本總計。 平衡資料集的理想模型具有微平均曲線和宏平均線,其斜率為 num_classes,直到累計增率為 100%,然後水平發展,直到資料百分比為 100 為止。
提示
對於分類實驗,針對自動化 ML 模型產生的每個折線圖都可以用來針對每個類別或所有類別的平均值來評估模型。 您可以按一下圖表右邊圖例中的類別標籤,在這些不同的檢視之間切換。
良好模型的累積增益曲線
不良模型的累積增益曲線
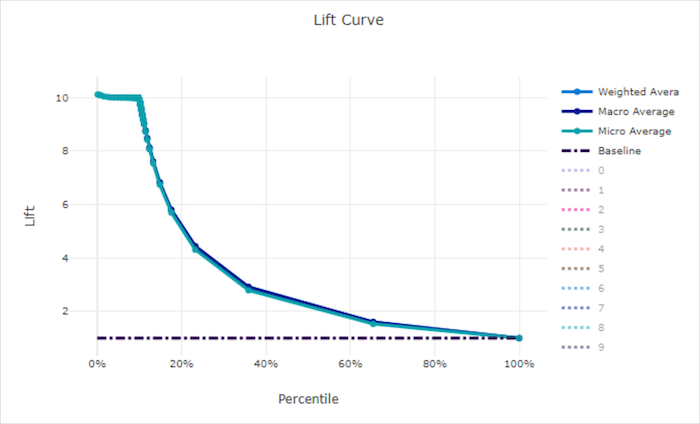
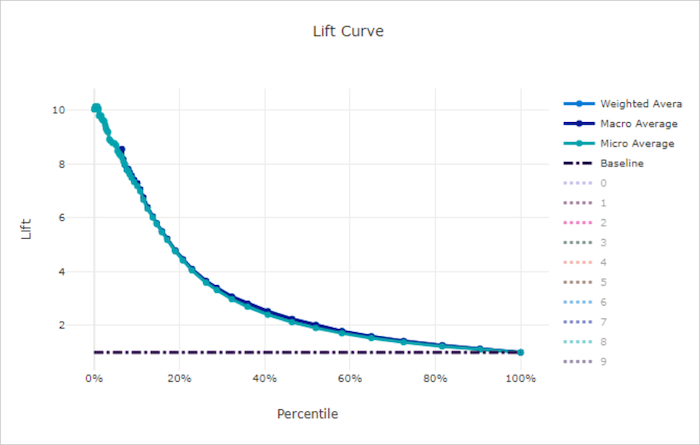
升力曲線
增益曲線顯示相較於隨機模型,模型的表現好多少倍。 增益是定義為隨機模型累積增益的比率 (應一律為 1)。
這項相對效能考量到當您增加類別數目時,分類會變得更困難。 (隨機模型錯誤地預測一個具有 10 個類別的資料集,與具有兩個類別的資料集相比,有較高的樣本比例)
基準線增益曲線是模型效能與該隨機模型一致的 y = 1 線。 一般情況下,良好模型的增益曲線在該圖表上會更高,並離 X 軸更遠,顯示當模型對其精確度最有信心時,其表現比隨機猜測好很多倍。
提示
對於分類實驗,針對自動化 ML 模型產生的每個折線圖都可以用來針對每個類別或所有類別的平均值來評估模型。 您可以按一下圖表右邊圖例中的類別標籤,在這些不同的檢視之間切換。
良好模型的增益曲線
不良模型的增益曲線
校正曲線
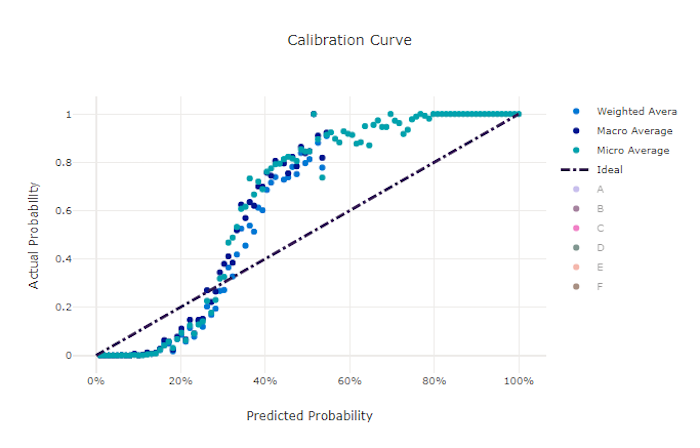
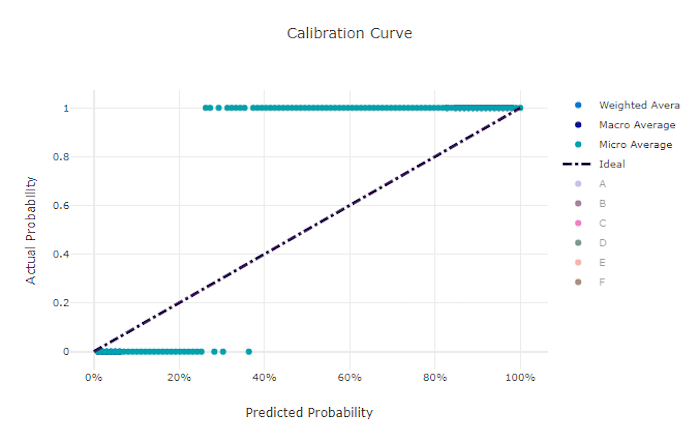
校正曲線會根據每個信賴等級的正樣本比例,在其預測中繪製模型的信賴度。 經過妥善校正的模型會針對指派 100% 信賴度的預測進行 100% 的正確分類,對 50% 的預測指派 50% 的信賴度,對 20% 的預測指派 20% 的信賴度,依此類推。 完美校正的模型在 y = x 線條之後會提供校正曲線,其中,模型會完美預測樣本屬於每個類別的可能性。
過度信賴的模型會過度預測接近零和一的可能性,很少對每個樣本的類別不確定,而校正曲線看起來會像反向的「S」。信賴不足的模型會把其預測的類別平均指派一個較低的可能性,而相關聯的校正曲線看起來會像「S」。 校正曲線不會描繪模型正確分類的能力,而是能夠正確地將信賴度指派給其預測。 如果模型正確指派低信賴度和高不確定性,則不良模型仍會有良好的校正曲線。
注意
校正曲線對樣本數目很敏感,因此,小的驗證集可能會產生可能難以解讀的雜訊結果。 這不一定表示模型的校正不良。
良好模型的校正曲線
不良模型的校正曲線
迴歸/預測計量
無論是迴歸或預測實驗,自動化 ML 都會針對每個產生的模型計算相同的效能計量。 這些計量也會進行標準化,以便在具有不同範圍之資料上定型的模型之間進行比較。 若要深入了解,請參閱計量標準化。
下表摘要說明針對迴歸和預測實驗產生的模型效能計量。 就像分類計量一樣,這些計量也是以 scikit learn 的實作為基礎。 適當的 scikit learn 文件會在 [計算] 欄位中視情況連結。
| 計量 | 描述 | 運算 |
|---|---|---|
| explained_variance | 說明的變異數會測量模型帳戶在目標變數中的變化。 它是原始資料其變異數中減少至錯誤變異數的百分比。 當錯誤的平均數為 0,它等於判斷的係數 (請參閱下列表格中的 r2_score)。 目標: 更接近 1 範圍: (-inf, 1] |
運算 |
| mean_absolute_error | 平均絕對誤差是目標與預測之間差異絕對值的預期值。 目標: 更接近 0 範圍: [0, inf) 類型: mean_absolute_error normalized_mean_absolute_error,mean_absolute_error 除以資料的範圍。 |
運算 |
| mean_absolute_percentage_error | 平均絕對百分比誤差 (MAPE) 是預測值與實際值之間的平均差異量值。 目標: 更接近 0 範圍: [0, inf) |
|
| median_absolute_error | Median absolute error (中位數絕對誤差) 是目標與預測值之間所有絕對值差異的中位數。 此遺失是強固極端值。 目標: 更接近 0 範圍: [0, inf) 類型: median_absolute_errornormalized_median_absolute_error:median_absolute_error 除以資料的範圍。 |
運算 |
| r2_score | R2 (判斷的係數) 衡量相對於觀察資料的變異數總計,平均平方誤差 (MSE) 的按比例減少。 目標: 更接近 1 範圍: [-1, 1] 注意:R2 通常範圍為 (-inf, 1]。 MSE 可以大於觀察到的變異數,因此,R2 可以有任意大的負值,視資料和模型預測而定。 自動化 ML 片段會回報 R2 分數 -1,因此,R2 的值為 -1 可能表示 true R2 分數小於 -1。 在解讀負的 R2 分數時,請考慮其他計量值和資料的屬性。 |
運算 |
| root_mean_squared_error | 均方根誤差是目標與預測之間預期平方差的平方根。 對於非偏誤估算器,RMSE 等於標準差。 目標: 更接近 0 範圍: [0, inf) 類型: root_mean_squared_error normalized_root_mean_squared_error:root_mean_squared_error 除以資料的範圍。 |
運算 |
| root_mean_squared_log_error | 均方根對數誤差是預期平方對數誤差的平方根。 目標: 更接近 0 範圍: [0, inf) 類型: root_mean_squared_log_error normalized_root_mean_squared_log_error:root_mean_squared_log_error 除以資料的範圍。 |
運算 |
| spearman_correlation | Spearman correlation (斯皮爾曼相關性) 是兩個資料集之間關係其單調性的非參數量值。 不同於 Pearson correlation (皮耳森相關性),Spearman correlation 不假設這兩個資料集為常態分佈。 如同其他的相關係數,斯皮爾曼相關性的變化在 -1 到 +1 之間,其中 0 代表無相互關聯。 -1 或 + 1 的相互關聯表示真正單純的關聯性。 斯皮爾曼是順位順序相互關聯計量,這表示如果預測或實際值的變更不會變更其順位順序,則不會變更斯皮爾曼結果。 目標: 更接近 1 範圍: [-1, 1] |
運算 |
計量正規化
自動化 ML 可正規化迴歸和預測計量,讓您在具有不同範圍的資料上定型模型之間進行比較。 針對較大範圍資料定型的模型,比起針對較小範圍資料定型的相同模型,錯誤更高,除非該錯誤已標準化。
雖然沒有將誤差計量正規化的標準方法,但是自動化 ML 會採用將誤差除以資料範圍的常見方法:normalized_error = error / (y_max - y_min)
注意
資料範圍不會與模型一起儲存。 如果您在維持的測試集上使用相同的模型推斷,y_min 和 y_max 可能會根據測試資料而變更,而標準化的計量可能無法直接用來比較模型在定型和測試集上的效能。 您可以從定型集合傳入 y_min 和 y_max 的值,讓比較變得公平。
預測計量:正規化與彙總
若資料包含多個時間序列,計算用於預測模型評估的計量時會有些特殊考量。 若要在多個序列上彙總計量,可採用兩種自然選擇,包括:
- 宏平均,其中「每個序列」的評估計量權重均相同。
- 微平均,其中每個預測的評估計量權重均相同。
這些案例類似於多類別分類中的宏與微平均。
為模型選取項目選擇主要計量時,選擇宏或微平均會造成相當大的差異。 例如,假設您想在零售情境中,預測一系列消費性產品的需求, 而某些產品的銷售量高於其他產品。 如果以微觀平均 RMSE 做為多數計量,高銷量產品很可能引起模型化錯誤,並嚴重影響計量。 在此情況下,模型選取演算法可能傾向對高銷量產品具有高精確度的模型,而非對低銷量產品具有高精確度的模型。 另一方面,在宏平均正規化 RMSE 中,高銷量與低銷量產品的權重大致相同。
下表列出了 AutoML 使用宏平均與微平均所得出的預測計量:
| 宏平均 | 微平均 |
|---|---|
請注意,宏平均計量會分別將每個序列正規化。 接著,會平均計算各個序列中的正規化計量,以得出最終結果。 應選擇宏平均或微平均取決於業務情況,但通常建議使用 normalized_root_mean_squared_error。
殘差
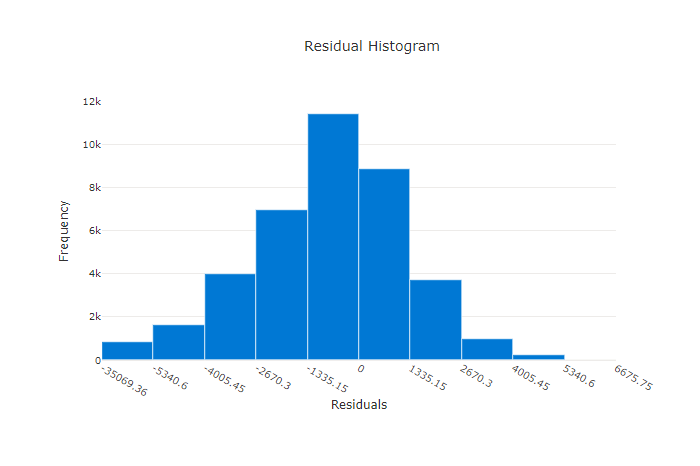
殘差圖是針對迴歸和預測實驗產生的預測錯誤 (殘差) 的長條圖。 所有樣本的殘差都計算為 y_predicted - y_true,然後以長條圖顯示,以顯示模型偏差。
在此範例中,這兩個模型會稍微偏向預測低於實際值。 這對具有扭曲的實際目標的資料集並不常見,但表示模型效能較差。 良好模型具有一個峰值為零的殘差分佈,在極端情況下很少有殘差。 較糟的模型具有分散的殘差分佈,零附近的樣本較少。
良好模型的殘差圖
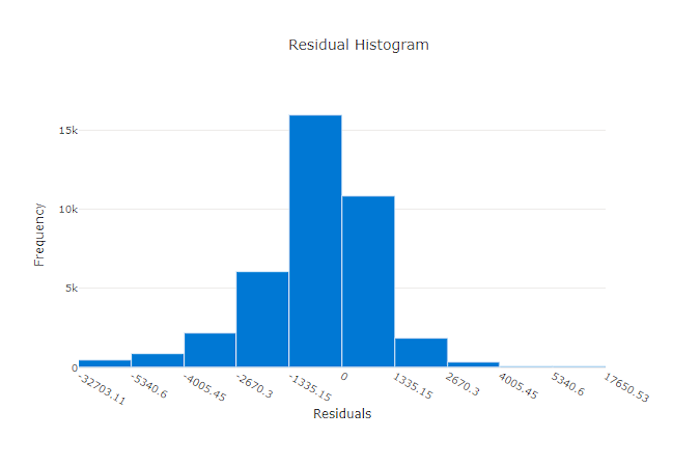
不良模型的殘差圖
預測與真值
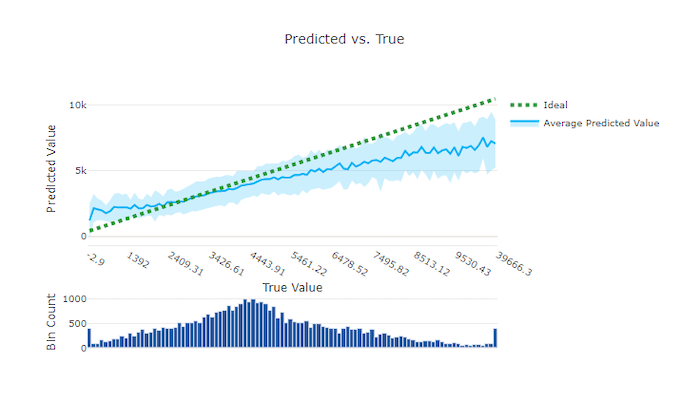
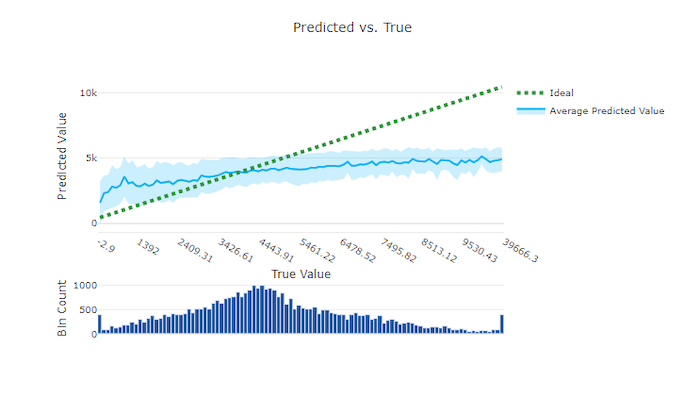
針對迴歸和預測實驗,預測與真正的圖表會繪製目標功能之間的關聯性 (真值/實際值) 和模型的預測。 真值會沿著 X 軸間隔,而每個間隔的平均預測值會以誤差線繪製。 這可讓您查看模型是否偏向於預測特定值。 這條線會顯示平均預測,而陰影區域會指出該平均值的預測變異數。
通常,最常見的真值具有最精確的預測,且變異數對低。 理想 y = x 線的趨勢線距離,其中有幾個真值是極端值上較佳的模型效能量值。 您可以使用圖表底部的長條圖,以了解實際資料分佈原因。 包含更多資料樣本,其中分佈是稀疏的,可以改善不可見資料的模型效能。
在此範例中,請注意,較佳的模型具有預測與真線條,更接近理想的 y = x 線條。
良好模型的預測與真圖表
不良模型的預測與真圖表
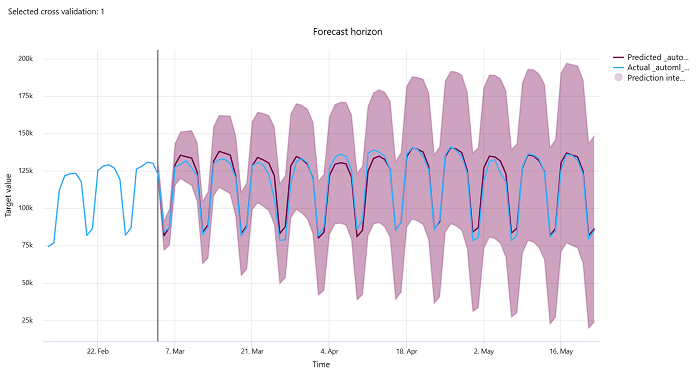
預測範圍
針對預測實驗,預測範圍圖表會繪製模型預測值與隨著時間每個交叉驗證摺疊所對應的實際值之間的關聯性,最多五個摺疊。 X 軸會根據您在定型設定期間提供的頻率來對應時間。 圖表中標示預測範圍點的垂直線也稱為範圍線,也就是您想要開始產生預測的時間期間。 在預測範圍線的左邊,您可以檢視歷史定型資料,以更清楚地將過去的趨勢視覺化。 在預測範圍右側,您可以對照不同交叉驗證摺疊的實際值 (藍色線) 與時間序列識別碼,將預測 (紫色線) 視覺化。 紫色陰影區域表示該平均數的預測信賴區間或變異數。
您可以按一下圖表右上角的編輯鉛筆圖示,來選擇要顯示的交叉驗證摺疊和時間序列識別碼組合。 從前五個交叉驗證摺疊和最多 20 個不同的時間序列識別碼選取,以將各種時間序列的圖表視覺化。
重要
此圖表適用於根據定型和驗證資料產生之模型的定型執行,以及根據定型和測試資料所進行的測試執行。 我們最多允許預測來源的前 20 個資料點,和後 80 個資料點。 此定型執行圖表顯示了最後一個 epoch,即 DNN 模型完全定型後的資料。 如果定型執行期間明確提供了驗證資料,則在測試執行圖中,預測起始點之前可能存在間隙。 這是因為測試執行中僅使用定型與測試資料,而未使用驗證資料,導致出現間隙。
映像模型的計量 (預覽版)
自動化 ML 會使用驗證資料集中的映像來評估模型的效能。 模型的效能會以 epoch-level 來測量,以了解定型的進度。 當整個資料集以正向和反向傳遞一次到神經網路時,所經過的 epoch。
影像分類計量
評估的主要計量是二進位和多類別分類模型的精確度,以及多標籤分類模型的 IoU (聯集上的交集)。 影像分類模型的分類計量與 [分類計量] 區段中定義的分類計量相同。 系統也會記錄與 epoch 相關聯的遺失值,其有助於監視定型的進度,並判斷模型是否過度學習或學習不足。
分類模型的每個預測都與信賴分數相關聯,這表示進行預測的信賴等級。 依預設,多標籤影像分類模型會以 0.5 的分數閾值進行評估,這表示只有至少具有這個信賴等級的預測,會被視為相關類別的正預測。 多分類不會使用分數閾值,而是會將具有最大信賴分數的類別視為預測。
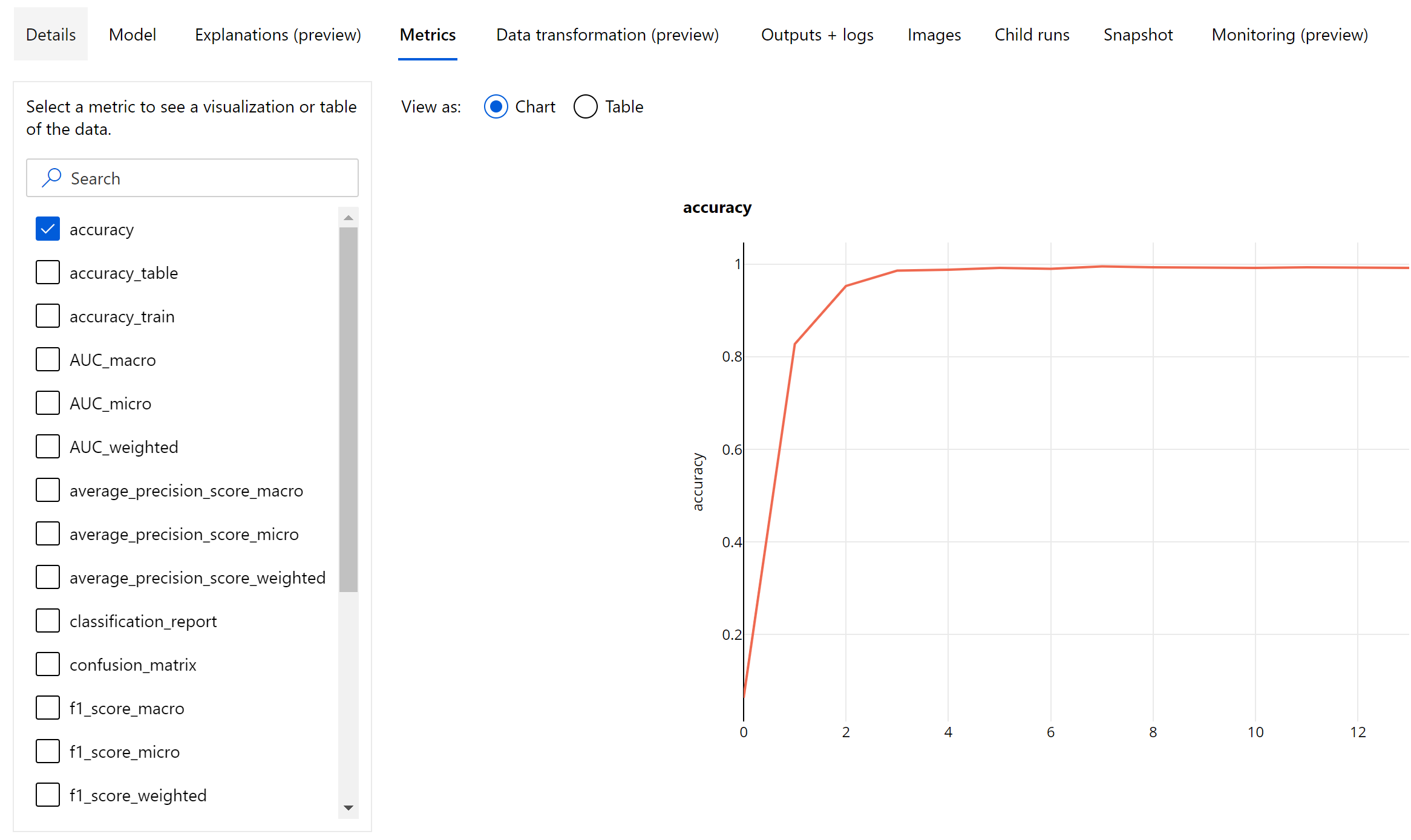
影像分類的 Epoch 層級計量
不同於表格式資料集的分類計量,影像分類模型會記錄 epoch 層級的所有分類計量,如下所示。
影像分類的摘要計量
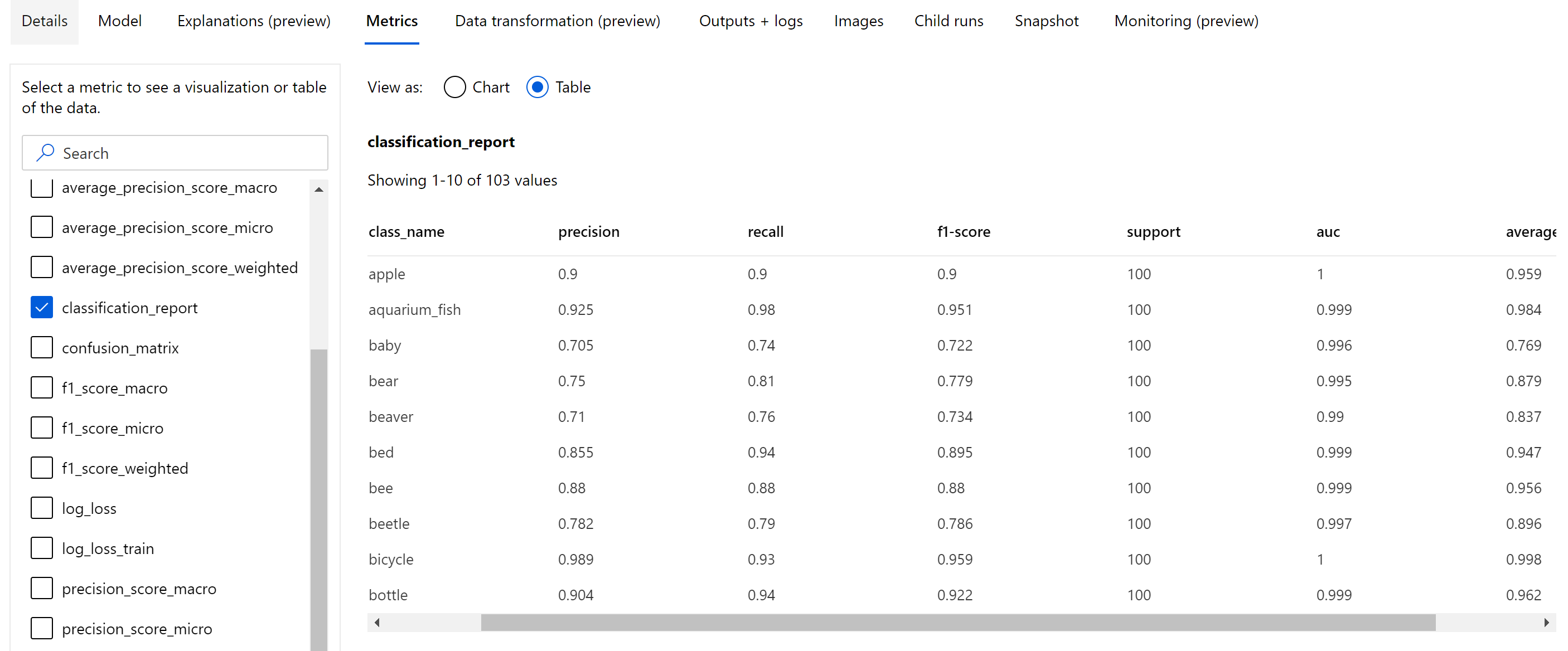
除了記錄在 epoch 層級的純量計量之外,影像分類模型也會記錄摘要計量,例如混淆矩陣、分類圖表,包括模型的 ROC 曲線、精確度-重新叫用曲線和分類報告,這些模型來自於我們獲得最高主要計量 (精確度) 分數的最佳 epoch。
分類報告提供精確度、重新叫用、f1 分數、支援、auc 和 average_precision 等計量的類別層級值,其具有各種不同層級的平均,微平均、宏平均和加權平均,如下所示。 參閱分類計量一節中的計量定義。
物件偵測和執行個體分割計量
影像物件偵測或執行個體分割模型的每個預測都與信賴分數相關聯。
信賴分數大於分數閾值的預測會輸出為預測,並在計量計算中使用,預設值為模型專屬,而且可以從超參數微調頁面(box_score_threshold 超參數) 中參考。
影像物件偵測和執行個體分割模型的計量計算,是以稱為 IoU (聯集上的交集) 的計量所定義的重疊量值為基礎,其計算方式是將實際值與預測值之間的重疊區域除以實際值與預測值的聯集區域。 從每個預測計算的 IoU 重疊閾值 (稱為 IoU 閾值) 進行比較,其決定了預測應該與使用者標註的實際值重疊多少,才能視為正預測。 如果從預測計算的 IoU 小於重疊閾值,則不會將預測視為相關類別的正預測。
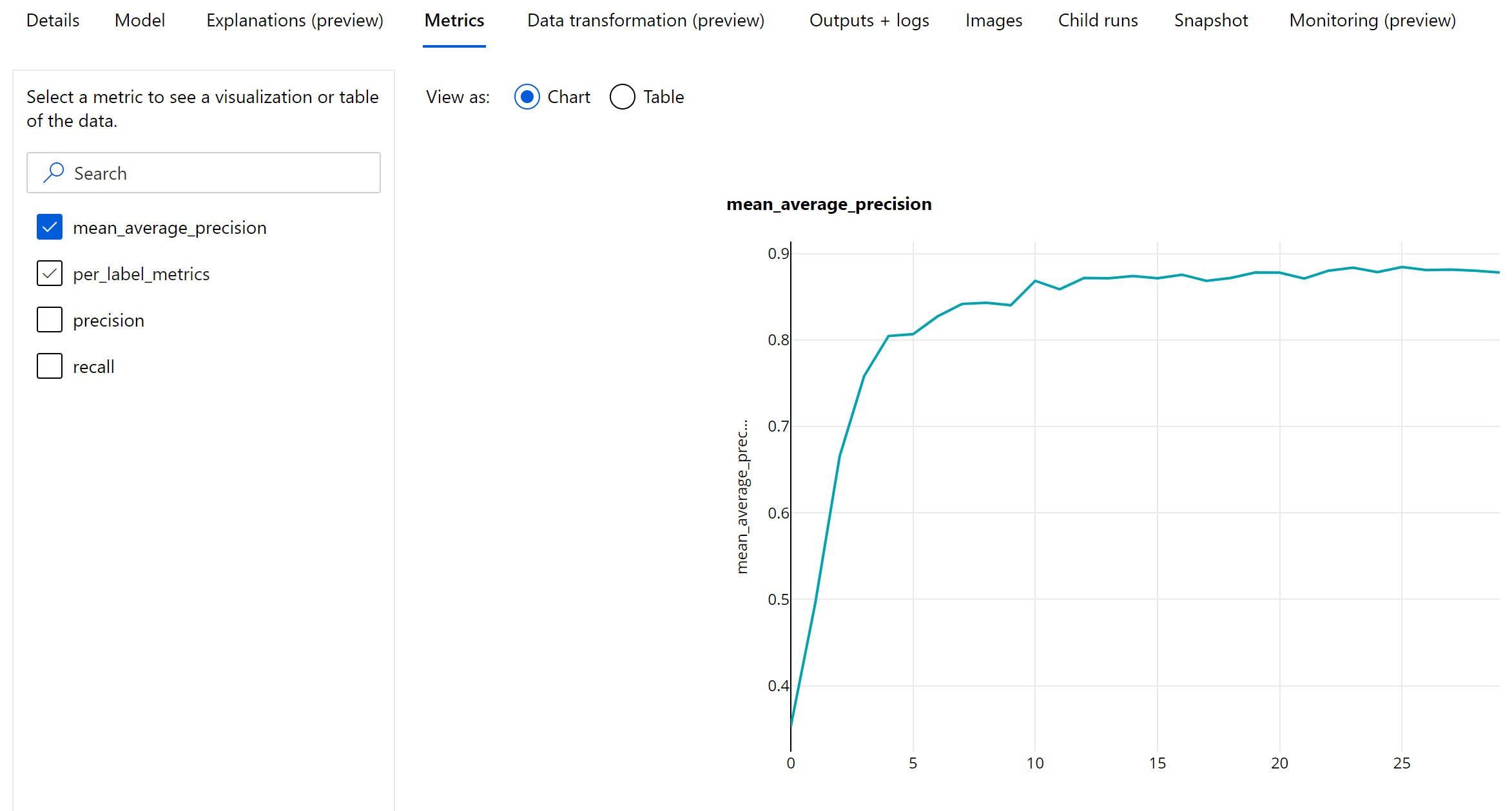
影像物件偵測和執行個體分割模型評估的主要計量是平均精度均值 (mAP)。 mAP 是所有類別之平均精確度 (AP) 的平均值。 自動化 ML 物件偵測模型支援使用下列兩個常用方法來計算 mAP。
Pascal VOC 計量:
Pascal VOC mAP 是物件偵測/執行個體分割模型的預設方法。 Pascal VOC 樣式 mAP 方法會計算某版本精確度-重新叫用曲線下方的面積。 首先是 p(rᵢ),是重新叫用 i 的精確度對所有唯一重新叫用值計算而得。 然後,p(rᵢ) 會取代為任何重新叫用 r' >= rᵢ 時獲得的最大精確度。 精確度值會在此版本的曲線中單純地遞減。 Pascal VOC mAP 計量依預設會使用 0.5 的閾值來評估。 此概念的詳細說明可在本部落格中取得。
COCO 計量:
COCO 評估方法會使用 101 點插入方法來進行 AP 計算,同時對十個 IoU 閾值進行平均。 AP@[.5:.95] 對應至 IoU 的 AP,從 0.5 至 0.95,級距大小為 0.05。 自動化 ML 會記錄 COCO 方法定義的所有 12 個計量,包括應用程式記錄中各種規模的 AP 和 AR (平均重新叫用),而計量使用者介面只會顯示 IoU 閾值為 0.5 的 mAP。
提示
如果 validation_metric_type 超參數設為「coco」(如超參數微調一節所述),影像物件偵測模型評估可使用 coco 計量。
物件偵測和執行個體分割的 Epoch 層級計量
mAP、精確度和重新叫用值會記錄在影像物件偵測/執行個體分割模型的 epoch 層級上。 mAP、精確度和重新叫用計量也會記錄在名稱為「per_label_metrics」的類別層級。 應該以資料表形式來檢視「per_label_metrics」。
注意
使用「coco」方法時,無法使用精確度、重新叫用和 per_label_metrics 的 Epoch 層級計量。
建議的最佳 AutoML 模型負責任 AI 儀表板 (預覽)
Azure Machine Learning 負責任 AI 儀表板提供單一介面,可協助您在實務上有效且有效率地實作負責任 AI。 只有使用表格式資料時才支援負責任 AI 儀表板,而且只支援分類與迴歸模型。 其會將數個成熟的負責任 AI 工具結合在下列領域中:
- 模型效能與公平性評量
- 資料探索
- 機器學習可解譯性
- 錯誤分析
雖然模型評估計量和圖表適合用來測量模型的一般品質,但實踐負責任 AI 時,檢查模型公平性、檢視模型解釋 (即模型用來進行預測的資料集功能)、檢查錯誤與潛在盲點等作業也相當重要。 這就是為什麼自動化 ML 會提供負責任 AI 儀表板,以協助您觀察有關模型的多種深入解析。 請參閱如何在 Azure Machine Learning 工作室中檢視負責任 AI 儀表板。
了解如何透過 UI 或 SDK 產生此儀表板。
模型說明和功能重要性
雖然模型評估計量和圖表適合用來測量模型的一般品質,但在實踐負責任 AI 時,檢查模型使用哪些資料集功能來進行預測也相當重要。 這就是為什麼自動化 ML 會提供模型說明儀表板來測量和報告資料集功能的相對貢獻。 請參閱如何在 Azure Machine Learning 工作室中檢視說明儀表板。
注意
可解譯性、最佳模型說明並不適用自動化 ML 預測實驗,建議將下列演算法做為最佳模型或集成:
- TCNForecaster
- AutoArima
- ExponentialSmoothing
- Prophet
- 平均
- Naive
- 季節性平均
- Seasonal Naive
下一步
- 請嘗試自動化機器學習迴歸樣本筆記本。
- 如需自動化 ML 的特定問題,請諮詢 askautomatedml@microsoft.com。