超參數使用 Azure Machine Learning (v1) 微調模型

重要
本文中的 Azure CLI 命令使用 azure-cli-ml 或 v1 (Azure Machine Learning 的擴充功能)。 v1 擴充功能的支援將於 2025 年 9 月 30 日終止。 您能夠安裝並使用 v1 延伸模組,直到該日期為止。
建議您在 2025 年 9 月 30 日之前轉換至 ml 或 v2 擴充功能。 如需 v2 擴充功能的詳細資訊,請參閱 Azure 機器學習 CLI 擴充功能和 Python SDK v2。
使用 Azure Machine Learning (v1) HyperDrive 套件,自動進行有效的超參數微調。 了解如何使用 Azure Machine Learning SDK 完成微調超參數所需的步驟:
- 定義參數搜尋空間
- 指定要最佳化的主要計量
- 針對低效能執行指定提早終止原則
- 建立和指派資源
- 使用定義的設定啟動實驗
- 視覺化定型回合
- 選取最適合您模型的設定
什麼是超參數微調?
超參數是可調整的參數,可讓您控制模型定型流程。 例如,使用神經網路時,您可以決定隱藏層的數目和每個圖層中的節點數目。 模型效能主要取決於超參數。
超參數微調也稱為超參數最佳化,是尋找產生最佳效能之超參數設定的過程。 此程序通常耗費昂貴的計算成本,而且是手動操作。
Azure Machine Learning 可讓您將超參數微調自動化,並平行執行實驗,以有效率地最佳化超參數。
定義搜尋空間
藉由探索為每個超參數定義的值範圍,來微調超參數。
超參數可以是離散或連續的,而且具有參數運算式描述的值分佈。
離散超參數
離散超參數會指定為離散值之間的一個 choice。
choice 可以是:
- 一個或多個以逗點分隔的值
-
range物件 - 任意
list物件
{
"batch_size": choice(16, 32, 64, 128)
"number_of_hidden_layers": choice(range(1,5))
}
在此案例中,batch_size 會採用 [16、32、64、128] 中的其中一個值,而 number_of_hidden_layers 會採用 [1、2、3、4] 中的其中一個值。
下列進階離散超參數也可以使用一項分佈來指定:
-
quniform(low, high, q)- 傳回 round(uniform(low, high) / q) * q 之類的值 -
qloguniform(low, high, q)- 傳回 round(exp(uniform(low, high)) / q) * q 之類的值 -
qnormal(mu, sigma, q)- 傳回 round(normal(mu, sigma) / q) * q 之類的值 -
qlognormal(mu, sigma, q)- 傳回 round(exp(normal(mu, sigma)) / q) * q 之類的值
連續超參數
連續超參數會指定為連續範圍值的分佈:
-
uniform(low, high)- 傳回在低值與高值之間均勻分佈的值 -
loguniform(low, high)- 傳回根據 exp(uniform(low, high)) 繪製的值,讓傳回值的對數均勻分佈 -
normal(mu, sigma)- 傳回以平均值 mu 和標準差 sigma 進行常態分佈的實數值 -
lognormal(mu, sigma)- 傳回根據 exp(normal(mu, sigma)) 繪製的值,讓傳回值的對數常態分佈
參數空間定義的範例:
{
"learning_rate": normal(10, 3),
"keep_probability": uniform(0.05, 0.1)
}
此程式碼會以兩個參數定義搜尋空間 - learning_rate 和 keep_probability。
learning_rate 有平均值 10 和標準差 3 的常態分佈。
keep_probability 有最小值 0.05 和最大值 0.1 的均勻分佈。
取樣超參數空間
指定要對超參數空間使用的參數取樣方法。 Azure Machine Learning 支援以下方法:
- 隨機取樣
- 格線取樣
- 貝氏取樣
隨機取樣
隨機取樣支援離散和連續超參數。 其支援提早終止低效能執行。 有些使用者會透過隨機取樣進行初始搜尋,然後縮小搜尋空間範圍來改善結果。
在隨機取樣中,超參數值會從定義的搜尋空間隨機選取。
from azureml.train.hyperdrive import RandomParameterSampling
from azureml.train.hyperdrive import normal, uniform, choice
param_sampling = RandomParameterSampling( {
"learning_rate": normal(10, 3),
"keep_probability": uniform(0.05, 0.1),
"batch_size": choice(16, 32, 64, 128)
}
)
格線取樣
網格取樣支援離散超參數。 如果您可以透過預算對搜尋空間進行徹底搜尋,請使用網格取樣。 其支援提早終止低效能執行。
網格取樣會對所有可能值進行簡單的網格搜尋。 網格取樣只能搭配使用 choice 超參數。 例如,下列空間共有六個樣本:
from azureml.train.hyperdrive import GridParameterSampling
from azureml.train.hyperdrive import choice
param_sampling = GridParameterSampling( {
"num_hidden_layers": choice(1, 2, 3),
"batch_size": choice(16, 32)
}
)
貝氏取樣
貝氏取樣是以貝氏最佳化演算法為基礎。 它會根據先前樣本的執行方式來挑選樣本,讓新樣本改善主要計量。
如果您有足夠的預算可探索超參數空間,建議使用貝氏取樣。 為了獲得最佳結果,我們建議的執行數目上限大於或等於待微調超參數數目的 20 倍。
同時執行的數目會影響微調程序的有效性。 較少的並行執行數目可能會產生較好的取樣收斂,因為較低程度的平行處理可讓更多執行受益於先前已完成的執行。
貝氏取樣僅支援搜尋空間上的 choice、uniform 和 quniform 分佈。
from azureml.train.hyperdrive import BayesianParameterSampling
from azureml.train.hyperdrive import uniform, choice
param_sampling = BayesianParameterSampling( {
"learning_rate": uniform(0.05, 0.1),
"batch_size": choice(16, 32, 64, 128)
}
)
指定主要計量
指定要讓超參數微調至最佳化的主要計量。 每個定型執行會針對此主要計量進行評估。 提早終止原則會使用主要計量來識別低效能執行。
為您的主要計量指定下列屬性:
-
primary_metric_name:主要計量名稱必須與定型指令碼所記錄的計量名稱完全相符 -
primary_metric_goal:它可以是PrimaryMetricGoal.MAXIMIZE或PrimaryMetricGoal.MINIMIZE,而且會在評估執行時,決定要最大化或最小化主要計量。
primary_metric_name="accuracy",
primary_metric_goal=PrimaryMetricGoal.MAXIMIZE
此樣本會將「精確度」提升到最高。
記錄用於超參數微調的計量
您模型的定型指令碼必須在模型定型期間記錄主要計量,以便 HyperDrive 可存取它以進行超參數微調。
使用下列範例程式碼片段,將主要計量記錄在定型指令碼中:
from azureml.core.run import Run
run_logger = Run.get_context()
run_logger.log("accuracy", float(val_accuracy))
定型指令碼會計算 val_accuracy 並將其記錄為主要計量「正確性」。 每次記錄計量時,超參數微調服務都會收到該計量。 報告的頻率由您決定。
如需有關在模型定型執行中記錄值的詳細資訊,請參閱在 Azure Machine Learning 定型執行中啟用記錄。
指定提前終止原則
使用提早終止原則自動結束執行不佳的執行。 提早終止可改善計算效率。
您可以設定下列參數來控制何時套用原則:
-
evaluation_interval:套用原則的頻率。 每次定型指令碼記錄主要計量都算是一個間隔。evaluation_interval為 1,表示每當定型指令碼回報主要計量時,就會套用原則。evaluation_interval為 2,表示將每隔一段時間就套用原則。 如果未指定,evaluation_interval會預設為 1。 -
delay_evaluation:將第一次原則評估延遲到指定間隔數目之後。 這是選擇性參數,允許所有設定執行最小的間隔數目,藉此避免過早終止定型執行。 如果指定,則會每隔 evaluation_interval (大於或等於 delay_evaluation) 的倍數套用原則一次。
Azure Machine Learning 支援下列提早終止原則:
Bandit 原則
Bandit 原則是以寬限時間因數/寬限時間數量,以及評估間隔為基準。 當主要計量不在最成功執行的指定寬限時間因數/寬限時間數量內,Bandit 會終止執行。
注意
貝氏取樣不支援提早終止。 使用貝氏取樣時,請設定 early_termination_policy = None。
指定下列設定參數︰
slack_factor或slack_amount:為取得效能最佳之定型執行所允許的寬限時間。slack_factor將允許的寬限時間指定為小數比。slack_amount將允許的寬限時間指定為絕對數量,而不是小數比。例如,請考慮在間隔 10 套用的 Bandit 原則。 假設在間隔 10 之效能最佳的執行回報主要計量為 0.8,而目標是要最大化主要計量。 如果原則指定
slack_factor為 0.2,在間隔 10 之最佳計量小於 0.66 (0.8/(1+slack_factor)) 的任何定型執行都會終止。evaluation_interval:(選擇性) 套用原則的頻率delay_evaluation:(選擇性) 將第一次原則評估延遲到指定間隔數目之後
from azureml.train.hyperdrive import BanditPolicy
early_termination_policy = BanditPolicy(slack_factor = 0.1, evaluation_interval=1, delay_evaluation=5)
在此範例中,自評估間隔 5 起,每隔一段時間回報計量時,就會套用提早終止原則。 如果任何執行的最佳計量小於效能最佳之執行的 (1/(1+0.1) 或 91%,該執行將會終止。
中位數停止原則
中位數停止是提早終止原則,並以執行所回報的主要計量移動平均為基準。 此原則會計算所有定型執行的執行平均數,並停止那些主要計量值比平均中位數還要差的執行。
此原則接受下列設定參數:
-
evaluation_interval:套用原則的頻率 (選擇性參數)。 -
delay_evaluation:將第一次原則評估延遲到指定間隔數目之後 (選擇性參數)。
from azureml.train.hyperdrive import MedianStoppingPolicy
early_termination_policy = MedianStoppingPolicy(evaluation_interval=1, delay_evaluation=5)
在此範例中,自評估間隔 5 起,每隔一段時間,就會套用提早終止原則。 如果執行的最佳計量在所有定型執行之間比間隔 1:5 的移動平均中位數還要差,該執行將會在間隔 5 停止。
截斷選取原則
截斷選取會根據百分比,取消每個評估間隔上效能最低的執行。 執行會使用主要計量進行比較。
此原則接受下列設定參數:
-
truncation_percentage:每個評估間隔效能最低之執行所要終止的百分比。 1 到 99 之間的整數值。 -
evaluation_interval:(選擇性) 套用原則的頻率 -
delay_evaluation:(選擇性) 將第一次原則評估延遲到指定間隔數目之後 -
exclude_finished_jobs:指定套用原則時是否排除已完成的作業
from azureml.train.hyperdrive import TruncationSelectionPolicy
early_termination_policy = TruncationSelectionPolicy(evaluation_interval=1, truncation_percentage=20, delay_evaluation=5, exclude_finished_jobs=true)
在此範例中,自評估間隔 5 起,每隔一段時間,就會套用提早終止原則。 如果執行在第 5 個間隔的效能,落在所有執行於第 5 個間隔的 20% 最低效能內,則會在第 5 個間隔終止,並在套用原則時排除已完成的作業。
無終止原則 (預設)
如果未指定原則,超參數微調服務會讓所有定型執行到完成。
policy=None
選取提早終止原則
- 對於可節省成本,但不會終止大有可為作業的保守原則,可考慮使用「中位數停止原則」搭配
evaluation_interval1 和delay_evaluation5。 這些是保守的設定,可在不遺失主要計量的情況下省下約 25%-35% (取決於我們的評估資料)。 - 若要更積極地節省成本,請使用 Bandit 原則,其提供較小的允許寬限時間,或較大截斷百分比的截斷選取原則。
建立和指派資源
藉由指定定型執行數目的上限,來控制您的資源預算。
-
max_total_runs:定型執行數目上限。 必須為介於 1 到 1000 之間的整數。 -
max_duration_minutes:(選擇性) 超參數微調實驗的持續時間上限 (以分鐘為單位)。 在此期間取消之後執行。
注意
如果同時指定 max_total_runs 和 max_duration_minutes,在達到這兩個閾值的第一個時,就會終止超參數微調實驗。
此外,也可指定要在超參數微調搜尋期間同時執行的定型執行數目上限。
-
max_concurrent_runs:(選擇性) 可同時執行的執行數目上限。 如果未指定,則會以平行方式啟動所有執行。 如果已指定,必須是介於 1 到 100 之間的整數。
注意
同時執行之數目會受限於指定計算目標中的可用資源。 請確保計算目標有資源可用於所需的並行作業。
max_total_runs=20,
max_concurrent_runs=4
此程式碼會將超參數微調實驗設定為使用最多 20 個執行,一次執行四個設定。
設定超參數微調實驗
若要設定您的超參數微調實驗,請提供下列各項:
- 定義的超參數搜尋空間
- 您的提早終止原則
- 主要計量
- 資源配置設定
- ScriptRunConfig
script_run_config
ScriptRunConfig 是透過取樣超參數執行的定型指令碼。 它會定義每個作業的資源 (單一或多節點),以及要使用的計算目標。
注意
script_run_config 中使用的計算目標必須有足夠的資源來滿足您的並行層級。 如需 ScriptRunConfig 的詳細資訊,請參閱設定定型執行。
設定您的超參數微調實驗:
from azureml.train.hyperdrive import HyperDriveConfig
from azureml.train.hyperdrive import RandomParameterSampling, BanditPolicy, uniform, PrimaryMetricGoal
param_sampling = RandomParameterSampling( {
'learning_rate': uniform(0.0005, 0.005),
'momentum': uniform(0.9, 0.99)
}
)
early_termination_policy = BanditPolicy(slack_factor=0.15, evaluation_interval=1, delay_evaluation=10)
hd_config = HyperDriveConfig(run_config=script_run_config,
hyperparameter_sampling=param_sampling,
policy=early_termination_policy,
primary_metric_name="accuracy",
primary_metric_goal=PrimaryMetricGoal.MAXIMIZE,
max_total_runs=100,
max_concurrent_runs=4)
HyperDriveConfig 設定傳遞至 ScriptRunConfig script_run_config 的參數。 接著,script_run_config 會將參數傳遞至定型指令碼。 上述程式碼片段取自範例筆記本定型、超參數微調,以及使用 PyTorch 進行部署。 在此範例中,將微調 learning_rate 和 momentum 參數。 執行的提早停止將由 BanditPolicy 決定,其會停止落在 slack_factor 外部的主要計量 (請參閱 BanditPolicy 類別參考)。
範例中的下列程式碼示範如何接收、剖析和傳遞要微調的值給定型指令碼的 fine_tune_model 函式:
# from pytorch_train.py
def main():
print("Torch version:", torch.__version__)
# get command-line arguments
parser = argparse.ArgumentParser()
parser.add_argument('--num_epochs', type=int, default=25,
help='number of epochs to train')
parser.add_argument('--output_dir', type=str, help='output directory')
parser.add_argument('--learning_rate', type=float,
default=0.001, help='learning rate')
parser.add_argument('--momentum', type=float, default=0.9, help='momentum')
args = parser.parse_args()
data_dir = download_data()
print("data directory is: " + data_dir)
model = fine_tune_model(args.num_epochs, data_dir,
args.learning_rate, args.momentum)
os.makedirs(args.output_dir, exist_ok=True)
torch.save(model, os.path.join(args.output_dir, 'model.pt'))
重要
每個超參數執行會從頭開始重新啟動定型,包括重建模型和所有資料載入器。 您可以使用 Azure Machine Learning 管線或手動程序,在定型執行之前,盡可能執行最多的資料準備工作,以將這項成本降至最低。
提交超參數微調實驗
定義超參數微調設定之後,請提交實驗:
from azureml.core.experiment import Experiment
experiment = Experiment(workspace, experiment_name)
hyperdrive_run = experiment.submit(hd_config)
暖開機超參數微調 (選擇性)
為您的模型尋找最佳的超參數值可能是一個反覆的流程。 您可以對前五個執行反覆運用知識,以加速超參數微調。
暖開機的處理方式不同於取樣方法:
- 貝氏取樣:先前執行的試用版會用來做為挑選新樣本的先前知識,以及改善主要計量。
- 隨機取樣或網格取樣:提早終止會對先前的執行運用知識,以判斷效能不佳的執行。
指定您想要暖開機的父代執行清單。
from azureml.train.hyperdrive import HyperDriveRun
warmstart_parent_1 = HyperDriveRun(experiment, "warmstart_parent_run_ID_1")
warmstart_parent_2 = HyperDriveRun(experiment, "warmstart_parent_run_ID_2")
warmstart_parents_to_resume_from = [warmstart_parent_1, warmstart_parent_2]
如果取消超參數微調實驗,您可以從最後一個檢查點繼續定型執行。 不過,您的定型指令碼必須處理檢查點邏輯。
定型執行必須使用相同的超參數設定,並掛接輸出資料夾。 定型指令碼必須接受 resume-from 引數,其包含要從中繼續定型執行的檢查點或模型檔案。 您可以使用下列程式碼片段,繼續執行個別的定型執行:
from azureml.core.run import Run
resume_child_run_1 = Run(experiment, "resume_child_run_ID_1")
resume_child_run_2 = Run(experiment, "resume_child_run_ID_2")
child_runs_to_resume = [resume_child_run_1, resume_child_run_2]
您可以設定您的超參數微調實驗,以從先前的實驗中開始暖開機,或在設定中使用選擇性參數 resume_from 和 resume_child_runs,繼續執行個別的定型執行 :
from azureml.train.hyperdrive import HyperDriveConfig
hd_config = HyperDriveConfig(run_config=script_run_config,
hyperparameter_sampling=param_sampling,
policy=early_termination_policy,
resume_from=warmstart_parents_to_resume_from,
resume_child_runs=child_runs_to_resume,
primary_metric_name="accuracy",
primary_metric_goal=PrimaryMetricGoal.MAXIMIZE,
max_total_runs=100,
max_concurrent_runs=4)
視覺化超參數微調執行
您可以將 Azure Machine Learning 工作室中的超參數微調執行視覺化,也可以使用筆記本介面控件。
Studio
您可以將 Azure Machine Learning 工作室中的所有超參數定型執行視覺化。 如需如何在入口網站中檢視實驗的詳細資訊,請參閱在工作室中檢視執行記錄。
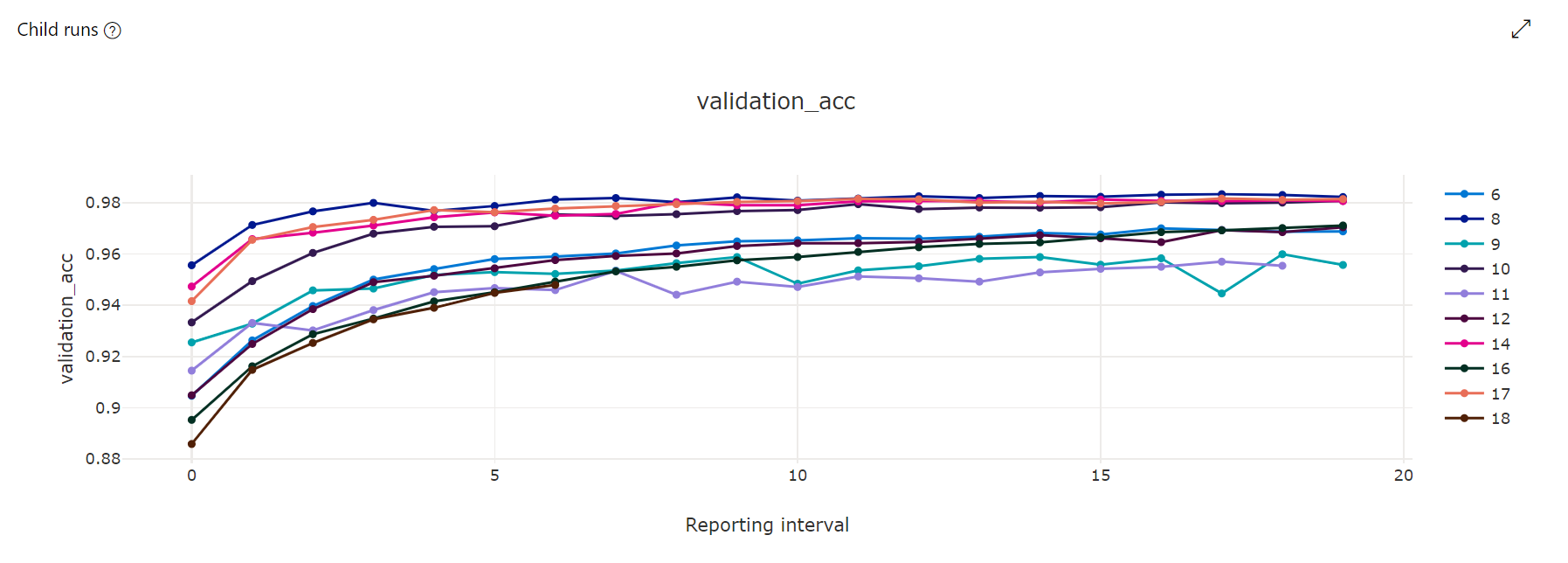
計量圖表:此視覺效果會追蹤在超參數微調期間,針對每個 hyperdrive 子系執行所記錄的計量。 每一行代表一個子系執行,而每個點會測量執行時間之反覆運算的主要計量值。
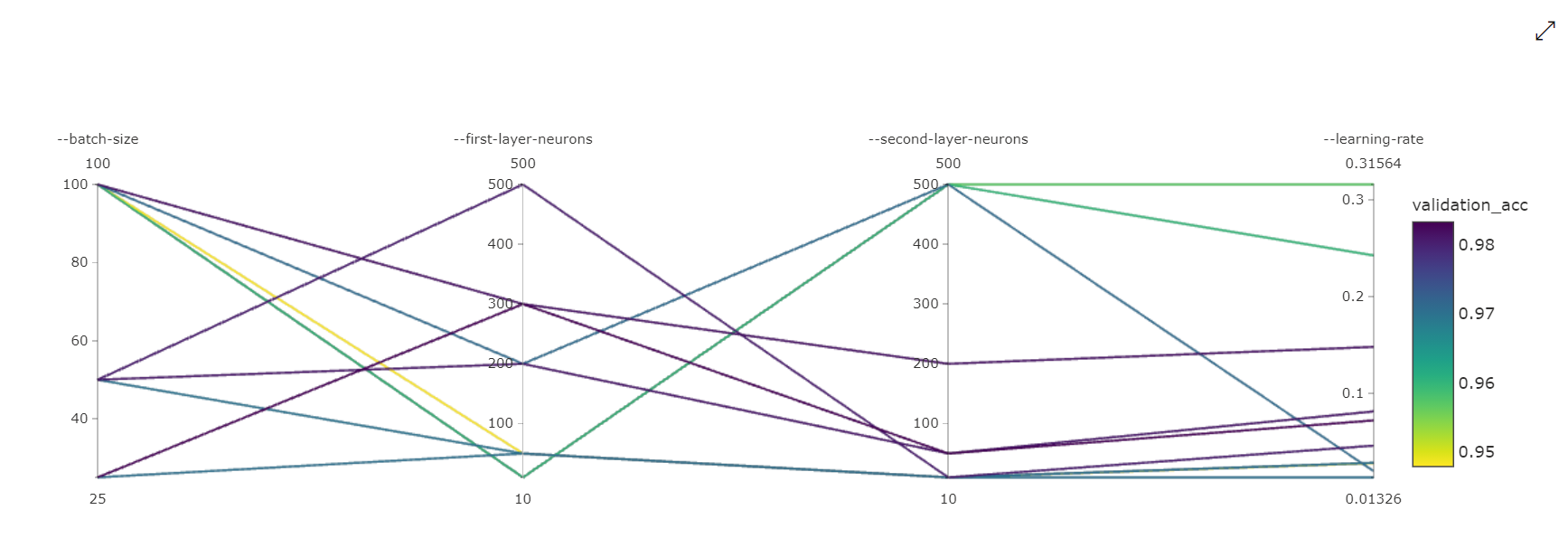
平行座標圖:此視覺效果會顯示主要計量效能和個別超參數值之間的相互關聯。 此圖表是透過軸移動的互動方式 (選取並拖曳軸標籤),以及藉由在單一軸上反白顯示值 (選取然後沿著單一軸垂直拖曳,以反白顯示所需值的範圍)。 平行座標圖包含圖表最右側的座標軸,繪製對應至該執行執行個體之超參數集的最佳計量值。 提供此軸的目的是要以更容易閱讀的方式,將圖表梯度圖例投射到資料上。
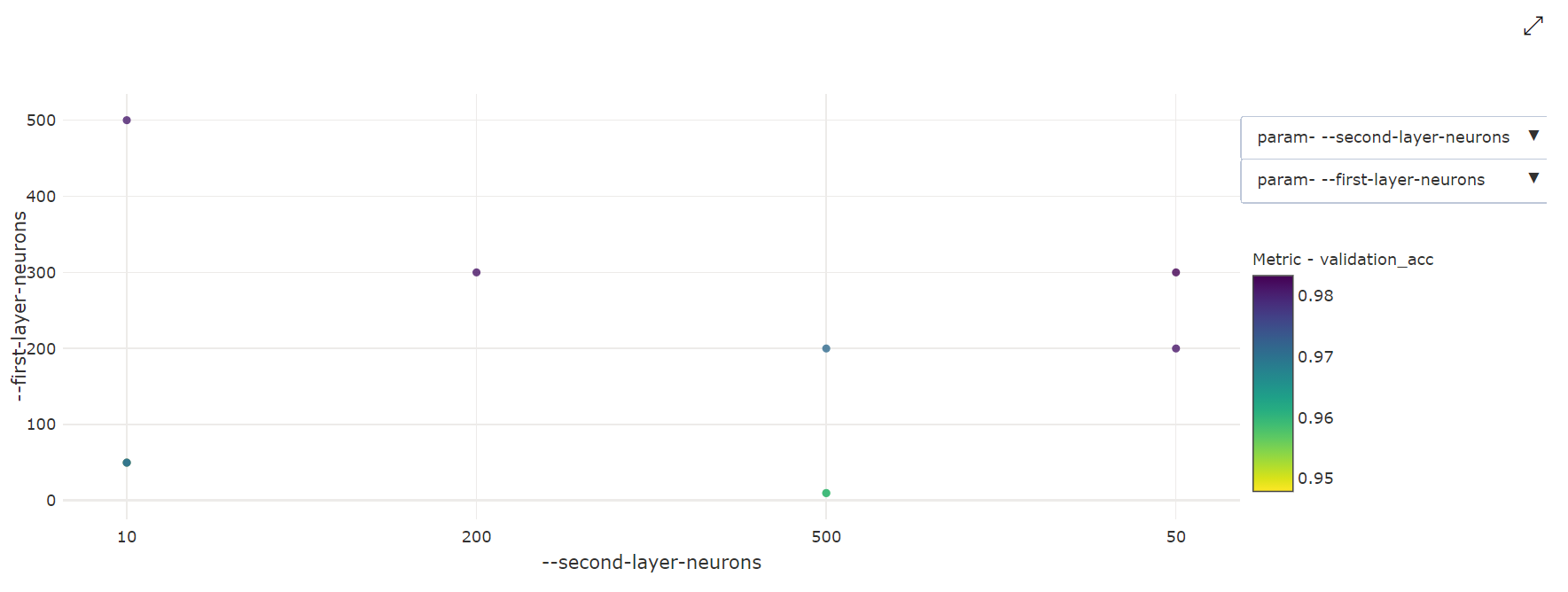
2D 散佈圖:此視覺效果會顯示任何兩個個別超參數與其相關聯的主要計量值之間的相互關聯。
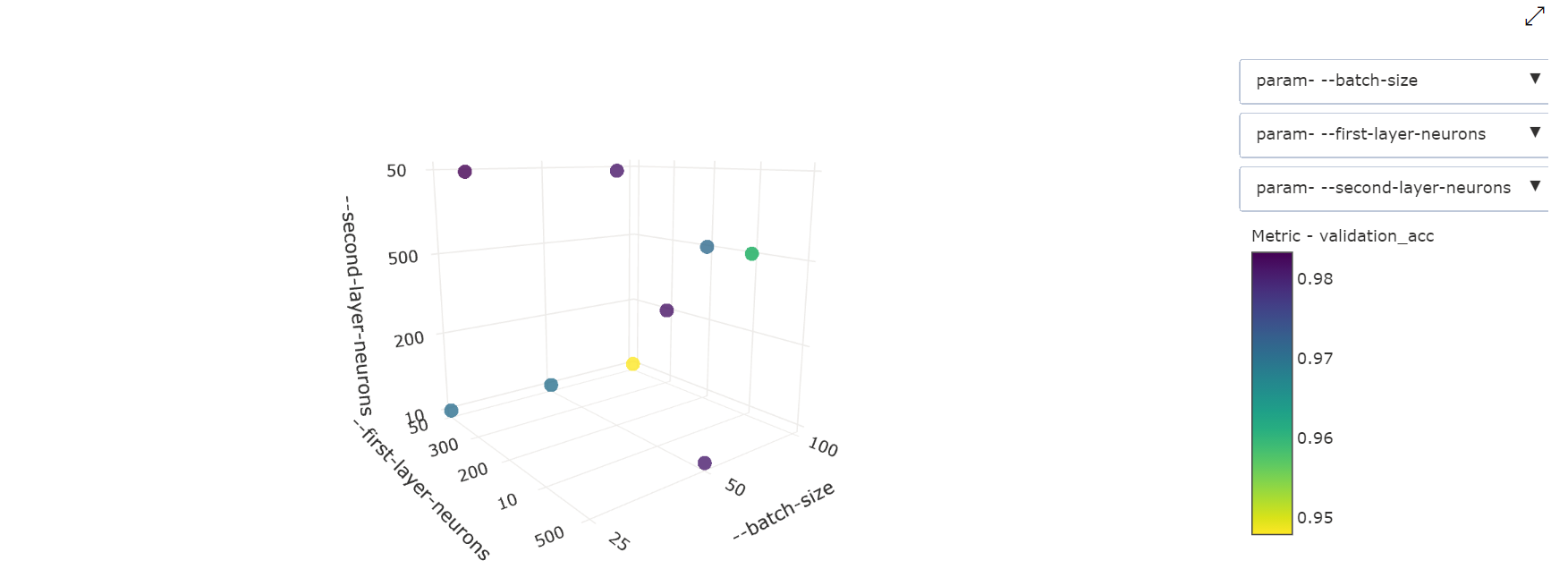
3D 散佈圖:此視覺效果與 2D 相同,但允許三個超參數維度與主要計量值的相互關聯。 您也可以選取並拖曳,藉此重新定向圖表以在3D 空間中檢視不同的相互關聯。
Notebook 小工具
使用Notebook 介面控件來視覺化定型執行的進度。 您可以在 Jupyter Notebook 中使用下列程式碼片段,在同一個位置視覺化您所有的超參數微調執行:
from azureml.widgets import RunDetails
RunDetails(hyperdrive_run).show()
此程式碼會顯示一個表格,其中包含每個超參數設定的定型執行相關詳細資料。
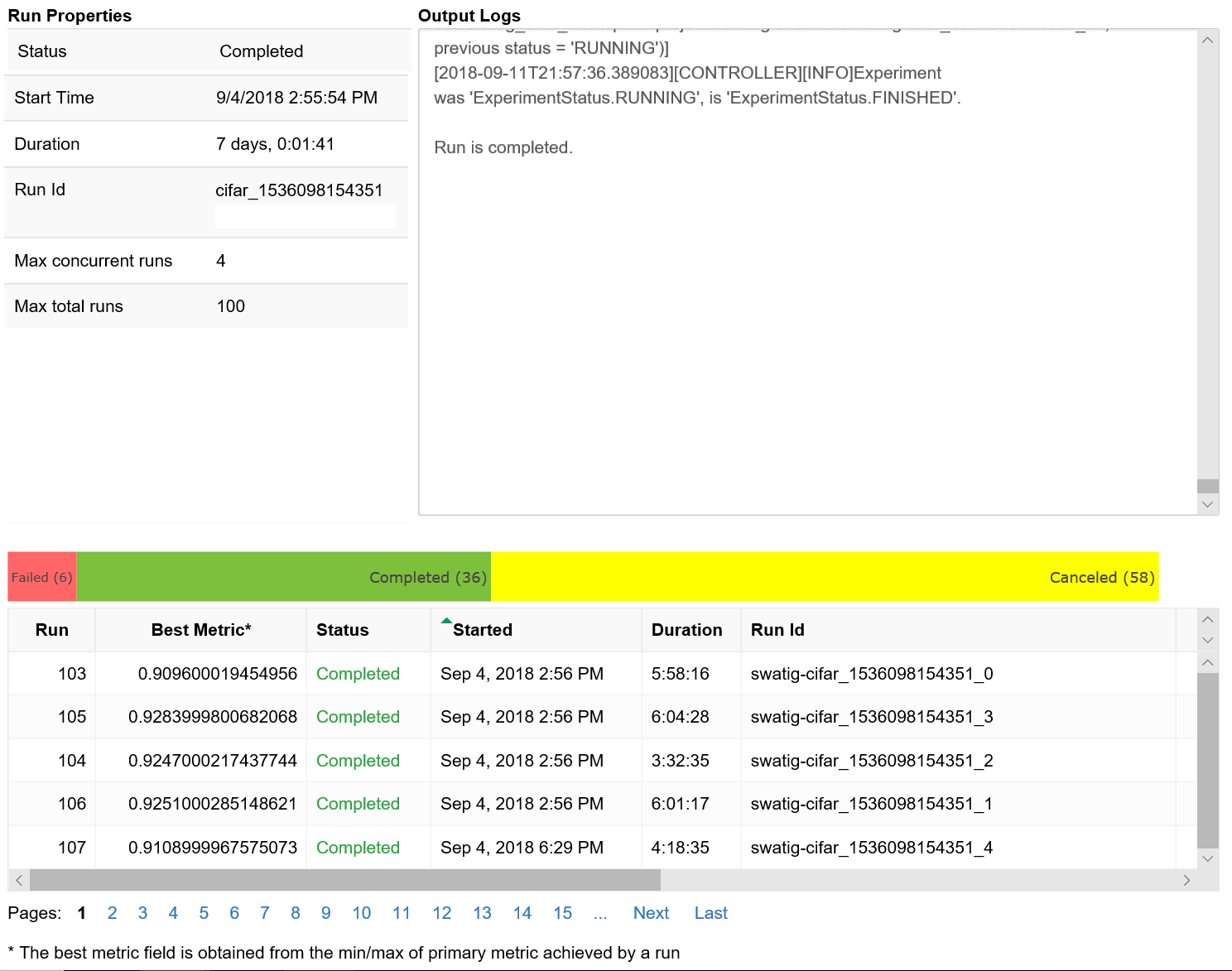
您也可以依照定型進度視覺化每個執行的效能。
尋找最佳模型
一旦所有超參數微調執行完成,即可識別最佳效能設定和超參數值:
best_run = hyperdrive_run.get_best_run_by_primary_metric()
best_run_metrics = best_run.get_metrics()
parameter_values = best_run.get_details()['runDefinition']['arguments']
print('Best Run Id: ', best_run.id)
print('\n Accuracy:', best_run_metrics['accuracy'])
print('\n learning rate:',parameter_values[3])
print('\n keep probability:',parameter_values[5])
print('\n batch size:',parameter_values[7])
範例筆記本
請參閱此資料夾中的 train-hyperparameter-* 筆記本:
了解如何依照使用 Jupyter 筆記本來探索這項服務一文來執行筆記本。