使用 MLflow 查詢和比較實驗和執行
您可以使用 MLflow 查詢 Azure Machine Learning 中的實驗和作業 (或執行)。 您不需要安裝任何特定的 SDK 來管理定型作業內發生的情況,藉由移除雲端特定相依性,在本機執行與雲端之間建立更順暢的轉換。 在本文中,您將了解如何使用 Python 中的 Azure Machine Learning 和 MLflow SDK,查詢及比較工作區中的實驗和執行。
MLflow 讓您可以:
- 在工作區中建立、查詢、刪除及搜尋實驗。
- 在工作區中查詢、刪除和搜尋執行。
- 從執行中追蹤並擷取計量、參數、成品及模型。
如需連線至 Azure Machine Learning 時,MLflow 開放原始碼和 MLflow 間的詳細比較,請參閱 Azure Machine Learning 中查詢執行和實驗的支援矩陣。
注意
Azure Machine Learning Python SDK v2 不提供原生記錄或追蹤功能。 這不僅可套用於記錄,也可套用至查詢記錄的計量。 請改用 MLflow 來管理實驗和執行。 本文說明如何使用 MLflow 管理 Azure Machine Learning 中的實驗和執行。
您也可以使用 MLflow REST API 來查詢和搜尋實驗並執行。 如需如何使用 MLflow REST 的範例,請參閱使用 MLflow REST 搭配 Azure Machine Learning。
必要條件
安裝 MLflow SDK
mlflow套件和適用於 MLflow 的 Azure 機器學習azureml-mlflow外掛程式,如下所示:pip install mlflow azureml-mlflow提示
您可使用
mlflow-skinny套件,這是輕量型 MLflow 套件,沒有 SQL 儲存體、伺服器、UI 或資料科學相依性。 對於主要需要 MLflow 追蹤和記錄功能的使用者,而不需匯入完整的功能套件,包括部署,建議使用此套件。建立 Azure Machine Learning 工作區。 若要建立工作區,請參閱 建立您需要開始使用的資源。 檢閱您在工作區中執行 MLflow 作業所需的存取權限。
若要執行遠程追蹤,或追蹤在 Azure 機器學習 外部執行的實驗,請將 MLflow 設定為指向 Azure 機器學習 工作區的追蹤 URI。 如需如何將 MLflow 連線至工作區的詳細資訊,請參閱設定適用於 Azure Machine Learning 的 MLflow。
查詢和搜尋實驗
使用 MLflow 來搜尋工作區內的實驗。 請參閱下列範例:
取得所有作用中的實驗:
mlflow.search_experiments()注意
在舊版 MLflow (<2.0) 中,請改用
mlflow.list_experiments()方法。取得所有實驗,包括已封存的:
from mlflow.entities import ViewType mlflow.search_experiments(view_type=ViewType.ALL)依名稱取得特定實驗:
mlflow.get_experiment_by_name(experiment_name)依識別碼取得特定實驗:
mlflow.get_experiment('1234-5678-90AB-CDEFG')
搜尋實驗
search_experiments() 方法自 Mlflow 2.0 起可用,可讓您使用 filter_string 搜尋與準則相符的實驗。
根據識別碼擷取多個實驗:
mlflow.search_experiments(filter_string="experiment_id IN (" "'CDEFG-1234-5678-90AB', '1234-5678-90AB-CDEFG', '5678-1234-90AB-CDEFG')" )擷取在指定時間之後建立的所有實驗:
import datetime dt = datetime.datetime(2022, 6, 20, 5, 32, 48) mlflow.search_experiments(filter_string=f"creation_time > {int(dt.timestamp())}")擷取具有指定標籤的所有實驗:
mlflow.search_experiments(filter_string=f"tags.framework = 'torch'")
查詢和搜尋執行
MLflow 可讓您搜尋任何實驗內的執行,包括同時進行多項實驗。 mlflow.search_runs() 方法接受引數 experiment_ids 和 experiment_name,以指出您要搜尋的實驗。 如果您想要搜尋工作區中的所有實驗,也可以指出 search_all_experiments=True:
依實驗名稱:
mlflow.search_runs(experiment_names=[ "my_experiment" ])依實驗識別碼:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ])搜尋工作區中的所有實驗:
mlflow.search_runs(filter_string="params.num_boost_round='100'", search_all_experiments=True)
請注意,experiment_ids 支援提供實驗陣列,因此您可以視需要搜尋跨多個實驗執行。 如果您想要比較在不同實驗中記錄相同模型的執行 (例如,由不同的人或不同的專案反覆項目),這可能很有用。
重要
如果未指定 experiment_ids、experiment_names 或 search_all_experiments,則 MLflow 預設會在目前的作用中實驗內搜尋。 您可使用 mlflow.set_experiment() 來設定作用中實驗。
根據預設,MLflow 會以 Pandas Dataframe 格式傳回資料,這可讓您在進一步處理執行分析時使用。 傳回的資料包含具有下列專案的資料行:
- 回合基本資訊。
- 具有資料行名稱
params.<parameter-name>的參數。 - 計量 (每個最後記錄的值),其資料行名稱為
metrics.<metric-name>。
查詢執行時,也會傳回所有計量和參數。 不過,對於包含多個值的計量 (例如遺失曲線或 PR 曲線),只會傳回計量的最後一個值。 如果您想要擷取指定計量的所有值,請使用 mlflow.get_metric_history 方法。 如需範例,請參閱從執行取得參數和計量。
順序執行
根據預設,實驗會依 start_time 遞減順序,也就是實驗在 Azure Machine Learning 中排入佇列的時間。 不過,您可以使用參數 order_by 變更此預設值。
依屬性將順序排序,例如
start_time:mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], order_by=["attributes.start_time DESC"])排序執行並限制結果。 下列範例會傳回實驗中的最後一個執行:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], max_results=1, order_by=["attributes.start_time DESC"])依
duration屬性將執行排序:mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], order_by=["attributes.duration DESC"])提示
attributes.duration不存在於 MLflow OSS 中,但為了方便而在 Azure Machine Learning 中提供。依計量值將執行排序:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ]).sort_values("metrics.accuracy", ascending=False)警告
目前不支援在參數
order_by中使用包含metrics.*、params.*或tags.*的運算式order_by。 請改用 Pandas 的order_values方法,如範例所示。
篩選執行
您也可以使用參數 filter_string,在超參數中尋找具有特定組合的回合。 使用 params 來存取執行的參數,使用 metrics 來存取執行中記錄的計量,以及使用 attributes 來存取執行資訊詳細資料。 MLflow 支援 AND 關鍵字聯結的運算式 (此語法不支援 OR):
根據參數值搜尋執行:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="params.num_boost_round='100'")警告
篩選
parameters僅支援=、like和!=運算子。根據計量值搜尋執行:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="metrics.auc>0.8")搜尋具指定標籤的執行:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="tags.framework='torch'")搜尋由指定使用者建立的執行:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="attributes.user_id = 'John Smith'")搜尋失敗的執行。 如需可能的值,請參閱依狀態篩選執行:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="attributes.status = 'Failed'")搜尋在指定時間之後建立的執行:
import datetime dt = datetime.datetime(2022, 6, 20, 5, 32, 48) mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string=f"attributes.creation_time > '{int(dt.timestamp())}'")提示
對於
attributes索引鍵,值應該一律為字串,因此在引號之間編碼。搜尋花費時間超過一小時的執行:
duration = 360 * 1000 # duration is in milliseconds mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string=f"attributes.duration > '{duration}'")提示
attributes.duration不存在於 MLflow OSS 中,但為了方便而在 Azure Machine Learning 中提供。搜尋在指定集合中具有此識別碼的執行:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="attributes.run_id IN ('1234-5678-90AB-CDEFG', '5678-1234-90AB-CDEFG')")
依狀態篩選執行
依狀態篩選執行時,相較於 Azure Machine Learning,MLflow 會使用不同的慣例來命名執行的不同可能狀態。 下表顯示可能的值:
| Azure Machine Learning 作業狀態 | MLFlow 的 attributes.status |
意義 |
|---|---|---|
| 未開始 | Scheduled |
Azure Machine Learning 已收到作業/執行。 |
| Queue | Scheduled |
作業/執行已排程執行,但尚未啟動。 |
| 準備 | Scheduled |
作業/執行尚未啟動,但已為其執行配置計算,且正在準備環境及其輸入。 |
| 執行中 | Running |
作業/執行目前作用中。 |
| 已完成 | Finished |
作業/執行已完成且無錯誤。 |
| 失敗 | Failed |
作業/執行已完成,但發生錯誤。 |
| 已取消 | Killed |
作業/執行已被使用者取消,或由系統終止。 |
範例:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ],
filter_string="attributes.status = 'Failed'")
取得計量、參數、成品及模型
在預設情況下,search_runs 方法會傳回 Pandas Dataframe,其中包含有限的資訊量。 如有需要,您可以取得 Python 物件,這可能有助於取得其詳細資料。 使用參數 output_format 控制如何傳回輸出:
runs = mlflow.search_runs(
experiment_ids=[ "1234-5678-90AB-CDEFG" ],
filter_string="params.num_boost_round='100'",
output_format="list",
)
然後,您可以從 info 成員存取詳細資料。 以下範例會示範如何取得 run_id:
last_run = runs[-1]
print("Last run ID:", last_run.info.run_id)
從執行取得參數和計量
用 output_format="list" 傳回執行時,您可以使用金鑰 data 輕鬆存取參數:
last_run.data.params
您可以用相同的方式查詢計量:
last_run.data.metrics
但對於包含多個值的計量 (例如遺失曲線或 PR 曲線),只會傳回計量最後一個已記錄的值。 如果您想要擷取指定計量的所有值,請使用 mlflow.get_metric_history 方法。 這個方法會要求您使用 MlflowClient:
client = mlflow.tracking.MlflowClient()
client.get_metric_history("1234-5678-90AB-CDEFG", "log_loss")
從執行取得成品
MLflow 可以查詢執行所記錄的任何成品。 成品無法使用執行物件本身進行存取,而且應該改用 MLflow 用戶端:
client = mlflow.tracking.MlflowClient()
client.list_artifacts("1234-5678-90AB-CDEFG")
上述方法會列出執行中記錄的所有成品,但這些成品仍會儲存在成品存放區 (Azure Machine Learning 儲存體) 中。 若要下載其中任何一個,請使用 download_artifact 方法:
file_path = mlflow.artifacts.download_artifacts(
run_id="1234-5678-90AB-CDEFG", artifact_path="feature_importance_weight.png"
)
注意
在舊版 MLflow (<2.0) 中,請改用 MlflowClient.download_artifacts() 方法。
從執行取得模型
也可以在執行中記錄模型,然後直接從該模型擷取。 若要擷取模型,您必須知道其儲存所在成品的路徑。 方法 list_artifacts 可用來尋找代表模型的成品,因為 MLflow 模型一律是資料夾。 您可以使用方法 download_artifact 來指定儲存模型的路徑,以下載模型:
artifact_path="classifier"
model_local_path = mlflow.artifacts.download_artifacts(
run_id="1234-5678-90AB-CDEFG", artifact_path=artifact_path
)
然後,您可以在變體特定命名空間中使用一般函式 load_model,從下載的成品載回模型。 下列範例會使用 xgboost:
model = mlflow.xgboost.load_model(model_local_path)
MLflow 也可讓您一次執行兩項作業,並以單一指令下載和載入模型。 MLflow 會將模型下載到暫存資料夾,並從該處載入。 load_model 方法會使用 URI 格式來指出必須從何處擷取模型。 以下是從執行載入模型時的 URI 結構:
model = mlflow.xgboost.load_model(f"runs:/{last_run.info.run_id}/{artifact_path}")
提示
若要查詢和載入模型登錄中註冊的模型,請參閱使用 MLflow 管理 Azure Machine Learning 中的模型登錄。
取得子系 (巢狀) 執行
MLflow 支援子系 (巢狀) 執行的概念。 當您需要分拆必須獨立於主定型流程進行追蹤的定型例程時,這些執行非常有用。 超參數微調最佳化程序或 Azure Machine Learning 管線是產生多個子執行的典型作業範例。 您可以使用屬性標籤 mlflow.parentRunId 查詢特定執行的所有子系執行,其中包含父系執行的執行識別碼。
hyperopt_run = mlflow.last_active_run()
child_runs = mlflow.search_runs(
filter_string=f"tags.mlflow.parentRunId='{hyperopt_run.info.run_id}'"
)
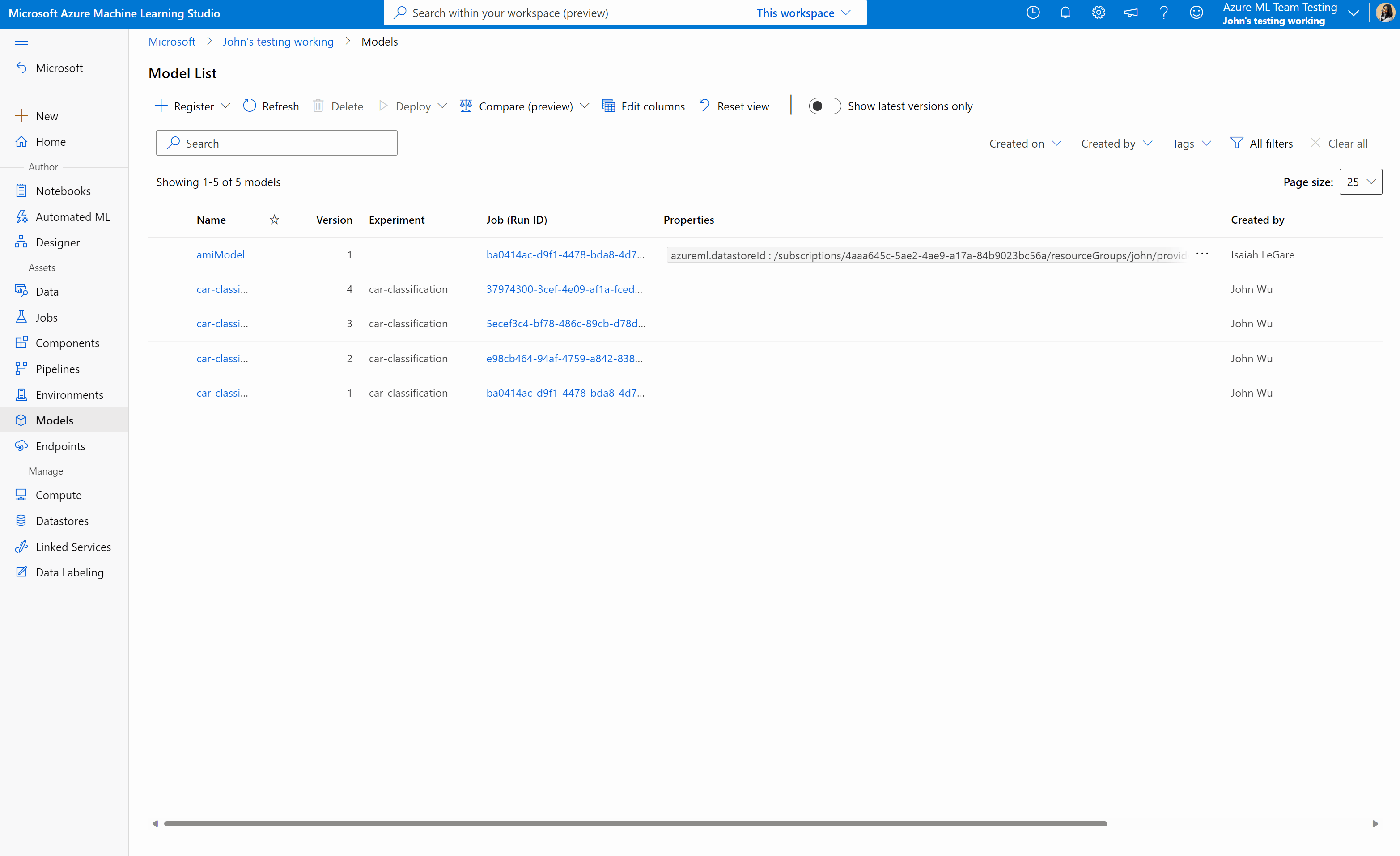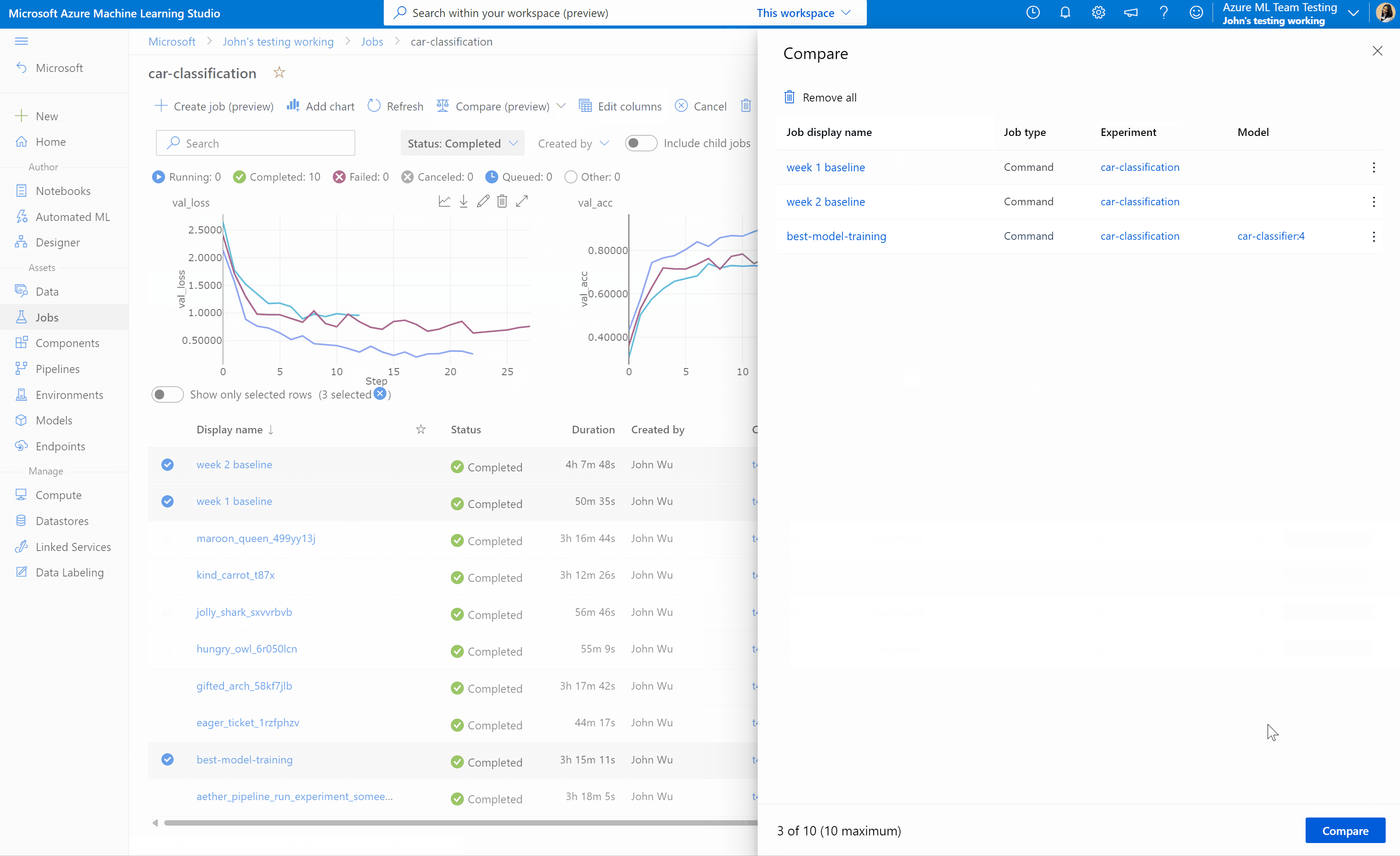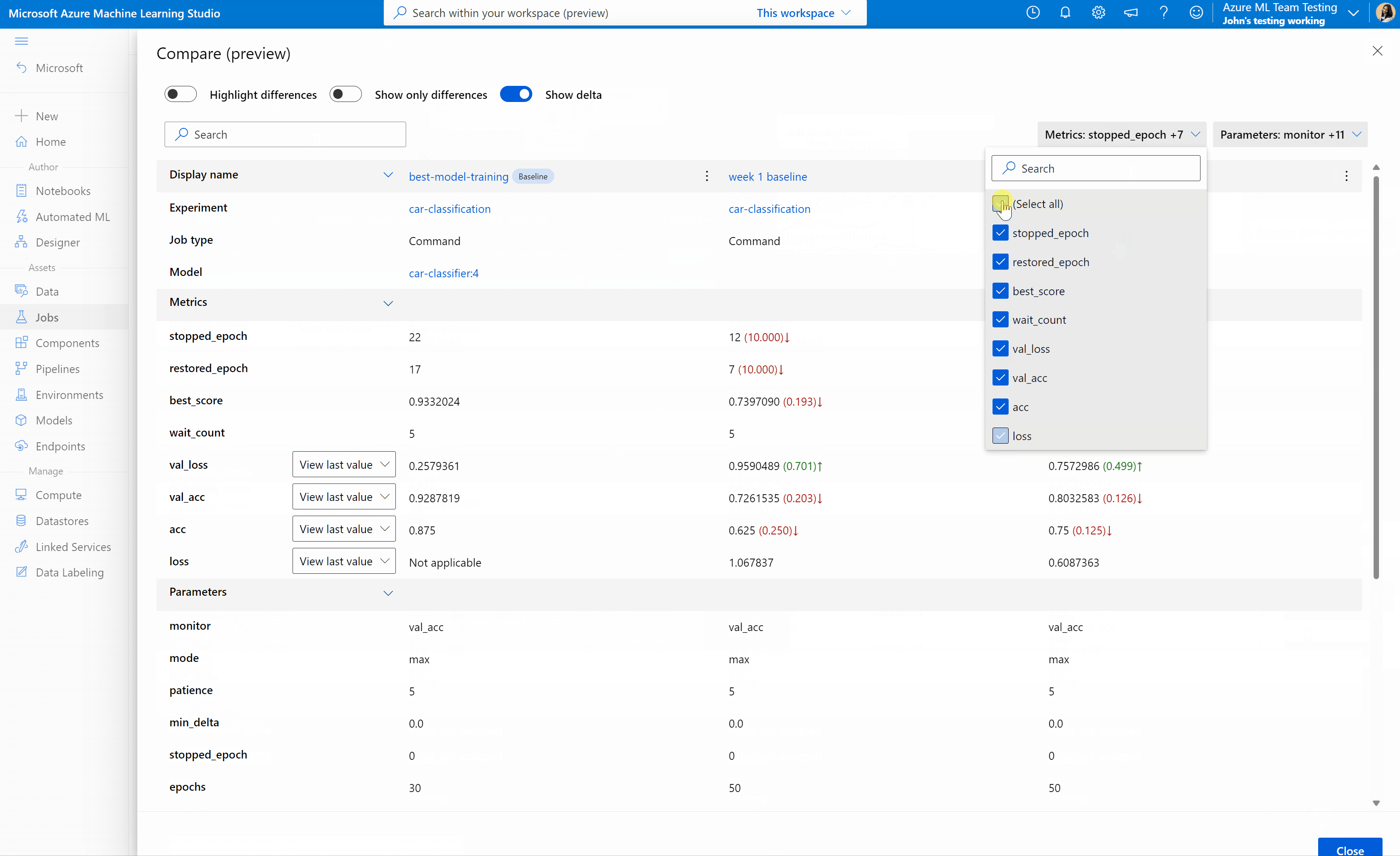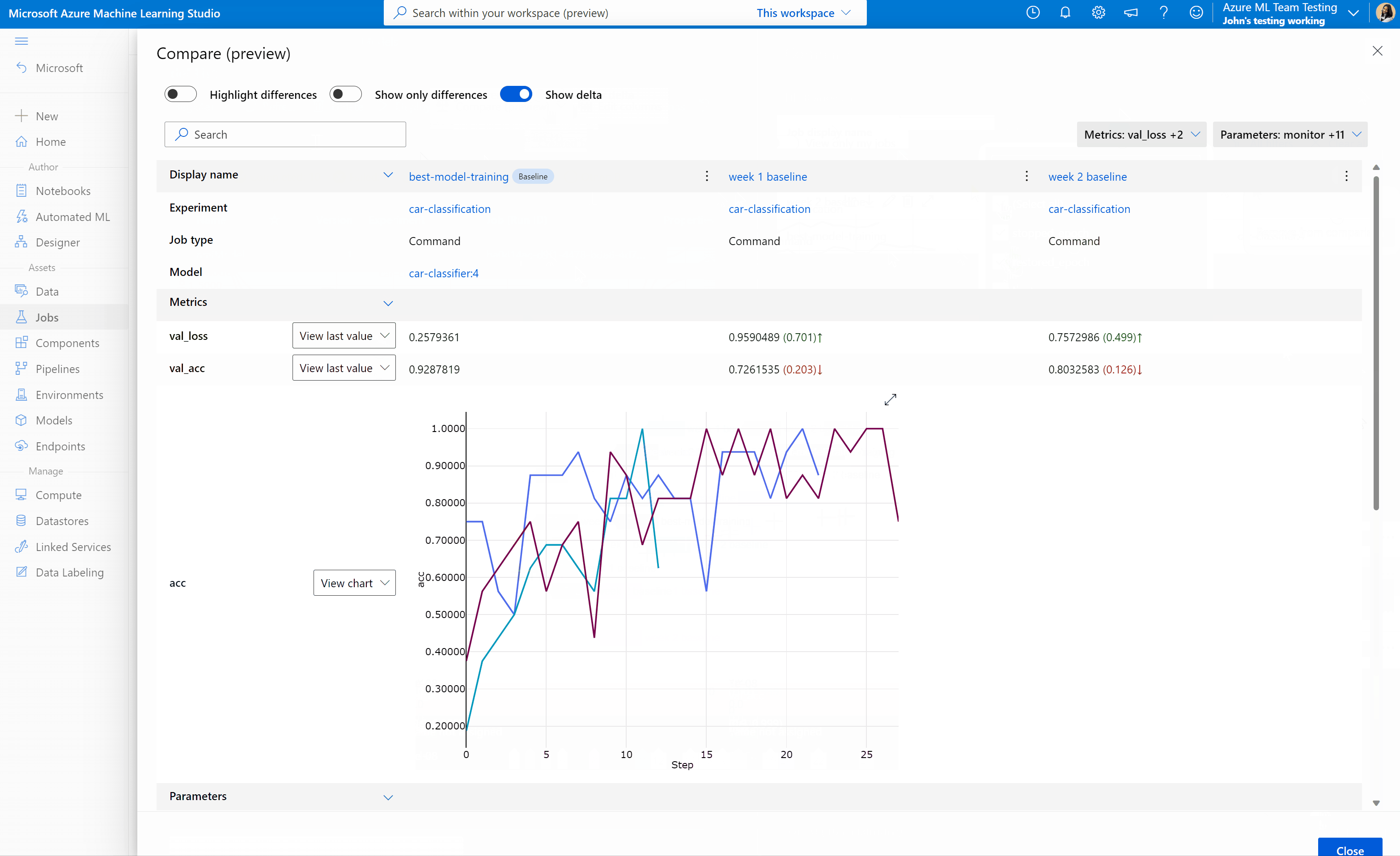
比較 Azure Machine Learning 工作室中的作業和模型 (預覽)
若要比較及評估 Azure Machine Learning 工作室中作業和模型的品質,請使用 [預覽面板] 來啟用此功能。 啟用之後,您可以比較所選作業和/或模型之間的參數、計量和標籤。
重要
本文中標示為 (預覽) 的項目目前處於公開預覽狀態。 此預覽版本會在沒有服務等級協定的情況下提供,不建議用於實際執行工作負載。 可能不支援特定功能,或可能已經限制功能。 如需詳細資訊,請參閱 Microsoft Azure 預覽版增補使用條款。
使用搭配 Azure Machine Learning 筆記本的 MLflow 示範和擴充本文所述的概念。
- 使用 MLflow 定型並追蹤分類器:示範如何使用 MLflow 追蹤實驗、記錄模型,以及將多個變體結合成管線。
- 使用 MLflow 管理實驗與執行:示範如何使用 MLflow 從 Azure Machine Learning 查詢實驗、執行、計量、參數及成品。
查詢執行和實驗的支援矩陣
MLflow SDK 會公開數個擷取執行的方法,包括控制傳回內容的選項和方法。 使用下列資料表瞭解目前連線到 Azure Machine Learning 時,MLflow 支援哪些方法:
| 功能 | MLflow 支援 | Azure Machine Learning 支援 |
|---|---|---|
| 依屬性排序執行 | ✓ | ✓ |
| 依計量排序執行 | ✓ | 1 |
| 依參數排序執行 | ✓ | 1 |
| 依標記排序執行 | ✓ | 1 |
| 依屬性篩選執行 | ✓ | ✓ |
| 依計量篩選執行 | ✓ | ✓ |
| 依具有特殊字元的計量篩選執行 (逸出) | ✓ | |
| 依參數篩選執行 | ✓ | ✓ |
| 依標記篩選執行 | ✓ | ✓ |
使用數值比較子篩選執行 (計量),包括=、!=、>、>=、< 和 <= |
✓ | ✓ |
篩選會使用字串比較子執行(參數、標記和屬性):= 和 != |
✓ | ✓2 |
篩選會使用字串比較子來執行 (參數、標記和屬性): LIKE/ILIKE |
✓ | ✓ |
使用比較子篩選執行 AND |
✓ | ✓ |
使用比較子篩選執行 OR |
||
| 重新命名實驗 | ✓ |
注意
- 1 如需如何在 Azure Machine Learning 中達到相同功能的相關說明和範例,請查看排序執行一節。
- 2
!=不支援的標籤。