在 Azure Machine Learning 中提交 Spark 作業
適用於: Azure CLI ml 延伸模組 v2 (目前)Python SDK azure-ai-ml v2 (目前)
Azure CLI ml 延伸模組 v2 (目前)Python SDK azure-ai-ml v2 (目前)
Azure 機器學習 支持獨立機器學習作業提交,以及建立涉及多個機器學習工作流程步驟的機器學習管線。 Azure Machine Learning 可處理的建立目標,包含獨立 Spark 作業,以及可在 Azure Machine Learning 管線中使用的可重複使用 Spark 元件。 在本文中,您將瞭解如何使用下列專案提交 Spark 作業:
- Azure Machine Learning 工作室 UI
- Azure Machine Learning CLI
- Azure Machine Learning SDK
如需了解 Azure Machine Learning 中的 Apache Spark,請造訪這項資源。
必要條件
- Azure 訂用帳戶;如果您沒有 Azure 訂用帳戶,請在開始前建立免費帳戶。
- Azure Machine Learning 工作區。 如需詳細資訊,請造訪建立工作區資源。
- 建立 Azure 機器學習 計算實例。
- 安裝 Azure 機器學習 CLI。
- (選擇性):Azure Machine Learning 工作區中連結的 Synapse Spark 集區。
注意
- 如需使用 Azure 機器學習 無伺服器 Spark 計算和連結 Synapse Spark 集區時的資源存取詳細資訊,請造訪確保 Spark 作業的資源存取。
- Azure 機器學習 提供共用配額集區,所有使用者都可以從中存取計算配額,以在有限的時間內執行測試。 當您使用無伺服器 Spark 計算時,Azure Machine Learning 可讓您短暫存取此共用配額。
使用 CLI 第 2 版連結使用者指派的受控識別
- 建立 YAML 檔案,定義應連結至工作區的使用者指派受控識別:
identity: type: system_assigned,user_assigned tenant_id: <TENANT_ID> user_assigned_identities: '/subscriptions/<SUBSCRIPTION_ID/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<AML_USER_MANAGED_ID>': {} - 在
--file參數中,使用az ml workspace update命令中的 YAML 檔案連結使用者指派的受控識別:az ml workspace update --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --name <AML_WORKSPACE_NAME> --file <YAML_FILE_NAME>.yaml
使用 ARMClient 連結使用者指派的受控識別
- 安裝
ARMClient,這是一個簡單的命令列工具,可叫用 Azure Resource Manager API。 - 建立 JSON 檔案,定義應連結至工作區的使用者指派受控識別:
{ "properties":{ }, "location": "<AZURE_REGION>", "identity":{ "type":"SystemAssigned,UserAssigned", "userAssignedIdentities":{ "/subscriptions/<SUBSCRIPTION_ID/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<AML_USER_MANAGED_ID>": { } } } } - 在 PowerShell 提示或命令提示字元中執行下列命令,將使用者指派的受控識別連結至工作區。
armclient PATCH https://management.azure.com/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.MachineLearningServices/workspaces/<AML_WORKSPACE_NAME>?api-version=2022-05-01 '@<JSON_FILE_NAME>.json'
注意
- 為了確保 Spark 作業成功執行,請在用於資料輸入和輸出的 Azure 儲存體帳戶上,將參與者和儲存體 Blob 資料參與者角色指派給 Spark 作業所使用的身分識別
- Azure Synapse Analytics 工作區中應啟用公用網路存取,以確保能使用連結的 Synapse Spark 集區 (機器翻譯) 成功執行 Spark 作業。
- 在與它相關聯的受控虛擬網路的 Azure Synapse 工作區中,如果 連結的 Synapse Spark 集 區指向 Synapse Spark 集區,您應該 將 受控私人端點設定為記憶體帳戶,以確保數據存取。
- 無伺服器 Spark 計算支援 Azure Machine Learning 受控虛擬網路。 若為無伺服器 Spark 計算佈建受控網路,那麼也應佈建記憶體帳戶的對應私人端點 (機器翻譯),以確保資料存取。
提交獨立 Spark 作業
針對 Python 腳本參數化進行必要的變更之後,您可以使用以 互動式數據整頓 開發的 Python 腳本來提交批次作業,以處理大量數據。 您可以將數據整頓批次作業提交為獨立的 Spark 作業。
Spark 作業需要採用引數的 Python 指令碼。 您可以修改原本從 互動式數據整頓 開發的 Python 程式代碼,以開發該腳本。 這裡會顯示範例 Python 指令碼。
# titanic.py
import argparse
from operator import add
import pyspark.pandas as pd
from pyspark.ml.feature import Imputer
parser = argparse.ArgumentParser()
parser.add_argument("--titanic_data")
parser.add_argument("--wrangled_data")
args = parser.parse_args()
print(args.wrangled_data)
print(args.titanic_data)
df = pd.read_csv(args.titanic_data, index_col="PassengerId")
imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy(
"mean"
) # Replace missing values in Age column with the mean value
df.fillna(
value={"Cabin": "None"}, inplace=True
) # Fill Cabin column with value "None" if missing
df.dropna(inplace=True) # Drop the rows which still have any missing value
df.to_csv(args.wrangled_data, index_col="PassengerId")
注意
此 Python 程式碼範例會使用 pyspark.pandas。 只有 Spark 執行階段 3.2 版或更新版本才支援此功能。
此文稿會採用兩個自變數,分別傳遞輸入資料和輸出資料夾的路徑:
--titanic_data--wrangled_data
若要建立作業,您可以將獨立 Spark 作業定義為 YAML 規格檔案,您可以在 命令中 az ml job create 搭配 --file 參數使用。 在 YAML 檔案中定義這些屬性:
Spark 作業規格中的 YAML 屬性
type- 設定為spark。code- 定義包含此作業的原始程式碼和指令碼的資料夾位置。entry- 定義作業的進入點。 應該涵蓋下列其中一個屬性:file- 定義 Python 指令碼的名稱,作為作業的進入點。class_name- 定義伺服器做為作業進入點的類別名稱。
py_files- 定義.zip、.egg或.py檔案的清單,放置在PYTHONPATH中以便成功執行作業。 這個屬性為選擇性。jars- 定義要包含在 Spark 驅動程式上的.jar檔案清單,以及執行程式CLASSPATH,以成功執行作業。 這個屬性為選擇性。files- 定義應該複製到每個執行程式工作目錄的檔案清單,以成功執行作業。 這個屬性為選擇性。archives- 定義應該擷取到每個執行程式工作目錄的封存清單,以成功執行作業。 這個屬性為選擇性。conf- 定義這些 Spark 驅動程式和執行程式屬性:spark.driver.cores:Spark 驅動程式的核心數目。spark.driver.memory:為 Spark 驅動程式配置的記憶體,以 GB 為單位。spark.executor.cores:Spark 執行程式的核心數目。spark.executor.memory:Spark 執行程式的記憶體配置,以 GB 為單位。spark.dynamicAllocation.enabled- 執行程式是否應該以動態方式配置,值為True或False。- 如果啟用執行程式的動態配置,請定義下列屬性:
spark.dynamicAllocation.minExecutors- 動態配置的 Spark 執行程式執行個體數目下限。spark.dynamicAllocation.maxExecutors- 動態配置的 Spark 執行程式執行個體數目上限。
- 如果停用執行程式的動態配置,請定義此屬性:
spark.executor.instances- Spark 執行程式執行個體的數目。
environment- 用來執行作業的 Azure Machine Learning 環境。args- 應該傳遞至作業進入點 Python 指令碼的命令列引數。 如需範例,請檢閱這裡提供的 YAML 規格檔案。resources- 此屬性會定義 Azure Machine Learning 無伺服器 Spark 計算要使用的資源。 其會使用下列屬性:instance_type- 要用於 Spark 集區的計算執行個體類型。 目前支援下列執行個體類型:standard_e4s_v3standard_e8s_v3standard_e16s_v3standard_e32s_v3standard_e64s_v3
runtime_version- 定義 Spark 執行階段版本。 目前支援下列 Spark 執行階段版本:3.33.4重要
適用於 Apache Spark 的 Azure Synapse Analytics 執行階段:公告
- 適用於 Apache Spark 3.3 的 Azure Synapse 執行階段:
- EOLA 公告日期:2024 年 7 月 12 日
- 支援結束日期:2025 年 3 月 31 日。 在此日期之後,此執行階段將停用。
- 若想持續獲得支援和最佳效能,建議您移轉到 Apache Spark 3.4。
- 適用於 Apache Spark 3.3 的 Azure Synapse 執行階段:
這是 YAML 檔案範例:
resources: instance_type: standard_e8s_v3 runtime_version: "3.4"compute- 此屬性會定義連結 Synapse Spark 集區的名稱,如下列範例所示:compute: mysparkpoolinputs- 此屬性會定義 Spark 作業的輸入。 Spark 作業的輸入可以是常值,或是儲存在檔案或資料夾中的資料。- 常 值 可以是數位、布爾值或字串。 一些範例如下所示:
inputs: sampling_rate: 0.02 # a number hello_number: 42 # an integer hello_string: "Hello world" # a string hello_boolean: True # a boolean value - 儲存在檔案或資料夾中的資料應該使用下列屬性來定義:
type- 將此屬性設定為uri_file或uri_folder,分別用於檔案或資料夾中包含的輸入資料。path- 輸入資料的 URI,例如azureml://、abfss://或wasbs://。mode- 將此屬性設定為direct。 此範例顯示作業輸入的定義,稱為$${inputs.titanic_data}}:inputs: titanic_data: type: uri_file path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv mode: direct
- 常 值 可以是數位、布爾值或字串。 一些範例如下所示:
outputs- 此屬性會定義 Spark 作業輸出。 Spark 作業的輸出可以寫入檔案或資料夾位置,此位置是使用下列三個屬性定義的:type- 您可以將這個屬性設定為uri_file或uri_folder,將輸出資料分別寫入檔案或資料夾。path- 這個屬性會定義輸出位置 URI,例如azureml://、abfss://或wasbs://。mode- 將此屬性設定為direct。 這個範例顯示作業輸出的定義,您可以稱之為${{outputs.wrangled_data}}:outputs: wrangled_data: type: uri_folder path: azureml://datastores/workspaceblobstore/paths/data/wrangled/ mode: direct
identity- 這個選擇性屬性會定義用來提交此作業的身分識別。 可以有user_identity和managed值。 如果 YAML 規格未定義身分識別,則 Spark 作業會使用預設身分識別。
獨立 Spark 作業
此範例 YAML 規格會顯示獨立 Spark 作業。 此作業使用 Azure Machine Learning 無伺服器 Spark 計算:
$schema: http://azureml/sdk-2-0/SparkJob.json
type: spark
code: ./
entry:
file: titanic.py
conf:
spark.driver.cores: 1
spark.driver.memory: 2g
spark.executor.cores: 2
spark.executor.memory: 2g
spark.executor.instances: 2
inputs:
titanic_data:
type: uri_file
path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv
mode: direct
outputs:
wrangled_data:
type: uri_folder
path: azureml://datastores/workspaceblobstore/paths/data/wrangled/
mode: direct
args: >-
--titanic_data ${{inputs.titanic_data}}
--wrangled_data ${{outputs.wrangled_data}}
identity:
type: user_identity
resources:
instance_type: standard_e4s_v3
runtime_version: "3.4"
注意
若要使用連結的 Synapse Spark 集區,請定義上述範例 YAML 規格檔案中的 compute 屬性,而不是 resources 屬性。
您可以使用命令稍早 az ml job create 顯示的 YAML 檔案搭配 --file 參數來建立獨立 Spark 作業,如下所示:
az ml job create --file <YAML_SPECIFICATION_FILE_NAME>.yaml --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
您可以在下列位置執行上述命令:
- Azure Machine Learning 計算執行個體的終端機。
- Visual Studio Code 終端機,已連線至 Azure 機器學習 計算實例。
- 已安裝 Azure Machine Learning CLI 的本機電腦。
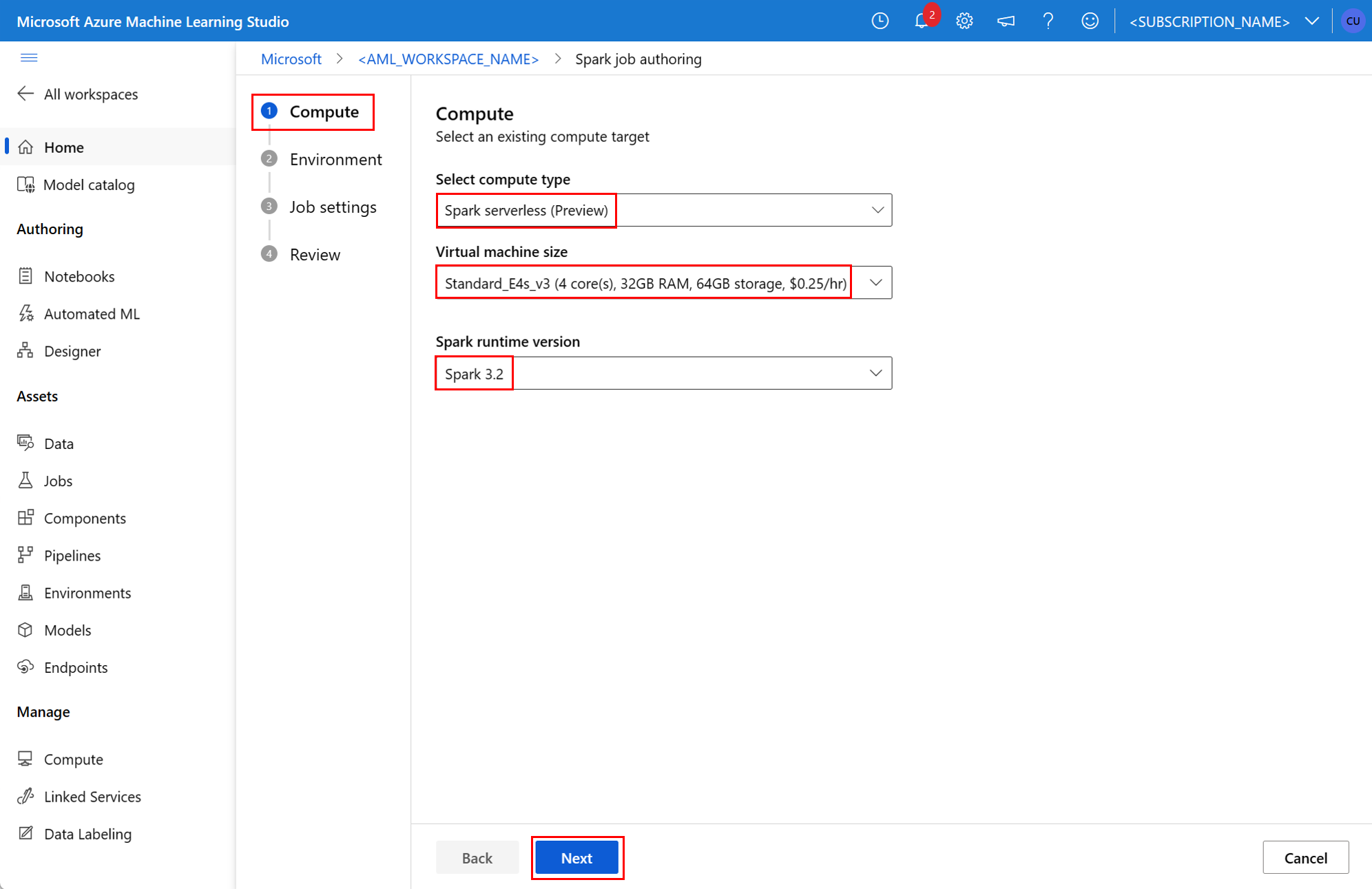
管線作業中的 Spark 元件
Spark 元件可讓您彈性地在多個 Azure Machine Learning 管線中使用相同的元件作為管線步驟。
Spark 元件的 YAML 語法與 Spark 作業規格的 YAML 語法 (機器翻譯) 大致類似。 這些屬性在 Spark 元件 YAML 規格中會以不同的方式定義:
name- Spark 元件的名稱。version- Spark 元件的版本。display_name- 要在 UI 和其他位置顯示的 Spark 元件名稱。description- Spark 元件的描述。inputs- 這個屬性類似於inputsSpark 作業規格 YAML 語法中所述的屬性,不同之處在於它不會定義path屬性。 此程式碼片段顯示 Spark 元件inputs屬性的範例:inputs: titanic_data: type: uri_file mode: directoutputs- 這個屬性類似於outputsSpark 作業規格 YAML 語法中所述的屬性,不同之處在於它不會定義path屬性。 此程式碼片段顯示 Spark 元件outputs屬性的範例:outputs: wrangled_data: type: uri_folder mode: direct
注意
Spark 元件不會定義 identity、 compute 或 resources 屬性。 管線 YAML 規格檔案為這些屬性提供了定義。
此 YAML 規格檔案提供 Spark 元件的範例:
$schema: http://azureml/sdk-2-0/SparkComponent.json
name: titanic_spark_component
type: spark
version: 1
display_name: Titanic-Spark-Component
description: Spark component for Titanic data
code: ./src
entry:
file: titanic.py
inputs:
titanic_data:
type: uri_file
mode: direct
outputs:
wrangled_data:
type: uri_folder
mode: direct
args: >-
--titanic_data ${{inputs.titanic_data}}
--wrangled_data ${{outputs.wrangled_data}}
conf:
spark.driver.cores: 1
spark.driver.memory: 2g
spark.executor.cores: 2
spark.executor.memory: 2g
spark.dynamicAllocation.enabled: True
spark.dynamicAllocation.minExecutors: 1
spark.dynamicAllocation.maxExecutors: 4
您可以使用 Azure 機器學習 管線作業中上述 YAML 規格檔案中定義的 Spark 元件。 請流覽管線作業 YAML 架構資源,以深入瞭解定義管線作業的 YAML 語法。 此範例顯示管線作業的 YAML 規格檔案、Spark 元件,以及 Azure Machine Learning 無伺服器 Spark 計算:
$schema: http://azureml/sdk-2-0/PipelineJob.json
type: pipeline
display_name: Titanic-Spark-CLI-Pipeline
description: Spark component for Titanic data in Pipeline
jobs:
spark_job:
type: spark
component: ./spark-job-component.yaml
inputs:
titanic_data:
type: uri_file
path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv
mode: direct
outputs:
wrangled_data:
type: uri_folder
path: azureml://datastores/workspaceblobstore/paths/data/wrangled/
mode: direct
identity:
type: managed
resources:
instance_type: standard_e8s_v3
runtime_version: "3.4"
注意
若要使用連結的 Synapse Spark 集區,請定義上述範例 YAML 規格檔案中的 compute 屬性,而不是 resources 屬性。
您可以使用命令中所 az ml job create 見的 YAML 規格檔案,使用 --file 參數來建立管線作業,如下所示:
az ml job create --file <YAML_SPECIFICATION_FILE_NAME>.yaml --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
您可以在下列位置執行上述命令:
對 Spark 作業進行疑難排解
若要對 Spark 作業進行疑難排解,您可以在 Azure Machine Learning 工作室中存取為該作業產生的記錄。 如何檢視 Spark 作業的記錄:
- 從 Azure Machine Learning 工作室 UI 的左側面板,瀏覽至 [作業]
- 選取 [所有作業] 索引標籤
- 選取作業的 [顯示名稱] 值
- 在 [作業詳細資料] 頁面上,選取 [輸出 + 記錄] 索引標籤
- 在檔案總管中,依序展開 [logs] 資料夾與 [azureml] 資料夾
- 存取 [驅動程式] 與 [程式庫管理員] 資料夾中的 Spark 作業記錄
注意
若要針對在筆記本工作階段中的互動式資料整頓期間所建立的 Spark 作業,進行疑難排解,請選取筆記本 UI 右上角的 [作業詳細資料]。 互動式筆記本工作階段中的 Spark 作業建立時,會採用實驗名稱 notebook-runs。