針對 ParallelRunStep 進行疑難排解

在本文中,您將了解在使用 Azure Machine Learning SDK 的 ParallelRunStep 類別遇到錯誤時,如何進行疑難排解。
如需針對管線進行疑難排解的一般提示,請參閱對機器學習管線進行疑難排解。
在本機測試指令碼
您的 ParallelRunStep 會做為 ML 管線中的步驟執行。 您可能想要在 本機 測試腳本作為第一個步驟。
輸入腳本需求
ParallelRunStep的輸入腳本必須包含run() 函式並選擇性包含 init() 函式:
-
init():請將此函式用於高成本或一般的準備,以進行後續的處理。 例如,使用此函式將模型載入至全域物件。 此函式只會在程序開始時呼叫一次。注意
如果您的
init方法會建立輸出目錄,請指定parents=True和exist_ok=True。 在作業執行所在的每個節點上,都會從每個背景工作處理序呼叫init方法。 -
run(mini_batch):此函式會針對每個mini_batch執行個體來執行。-
mini_batch:ParallelRunStep會叫用 run 方法,並將 list 或 pandasDataFrame作為引數傳遞給方法。 如果輸入為 ,則mini_batch中的每個專案都可以是檔案路徑,如果輸入為FileDatasetTabularDataset,則為 pandasDataFrame。 -
response:run() 方法應該傳回 pndasDataFrame或陣列。 針對 append_row output_action,這些傳回的元素會附加至一般輸出檔案。 針對 summary_only,則會忽略元素的內容。 針對所有輸出動作,每個傳回的輸出元素會指出輸入迷你批次中一次成功的輸入元素執行。 確保執行結果中有足夠的資料可將輸入對應至執行輸出結果。 執行輸出是以輸出檔撰寫,不保證會依序寫入,您應該在輸出中使用一些索引鍵將它對應至輸入。注意
一個輸入元素必須有一個輸出元素。
-
%%writefile digit_identification.py
# Snippets from a sample script.
# Refer to the accompanying digit_identification.py
# (https://github.com/Azure/MachineLearningNotebooks/tree/master/how-to-use-azureml/machine-learning-pipelines/parallel-run)
# for the implementation script.
import os
import numpy as np
import tensorflow as tf
from PIL import Image
from azureml.core import Model
def init():
global g_tf_sess
# Pull down the model from the workspace
model_path = Model.get_model_path("mnist")
# Construct a graph to execute
tf.reset_default_graph()
saver = tf.train.import_meta_graph(os.path.join(model_path, 'mnist-tf.model.meta'))
g_tf_sess = tf.Session()
saver.restore(g_tf_sess, os.path.join(model_path, 'mnist-tf.model'))
def run(mini_batch):
print(f'run method start: {__file__}, run({mini_batch})')
resultList = []
in_tensor = g_tf_sess.graph.get_tensor_by_name("network/X:0")
output = g_tf_sess.graph.get_tensor_by_name("network/output/MatMul:0")
for image in mini_batch:
# Prepare each image
data = Image.open(image)
np_im = np.array(data).reshape((1, 784))
# Perform inference
inference_result = output.eval(feed_dict={in_tensor: np_im}, session=g_tf_sess)
# Find the best probability, and add it to the result list
best_result = np.argmax(inference_result)
resultList.append("{}: {}".format(os.path.basename(image), best_result))
return resultList
如果推斷指令碼所在的相同目錄中有另一個檔案或資料夾,您可以藉由尋找目前的工作目錄來對其進行參照。 如果想要匯入套件,您也可以將套件資料夾附加至 sys.path。
script_dir = os.path.realpath(os.path.join(__file__, '..',))
file_path = os.path.join(script_dir, "<file_name>")
packages_dir = os.path.join(file_path, '<your_package_folder>')
if packages_dir not in sys.path:
sys.path.append(packages_dir)
from <your_package> import <your_class>
ParallelRunConfig 的參數
ParallelRunConfig 是 Azure Machine Learning 管線中 ParallelRunStep 執行個體的主要組態。 您可以用此設定來包裝指令碼並設定必要參數,包括下列各項:
entry_script:使用者腳本做為本機檔案路徑,以平行方式在多個節點上執行。 如果source_directory存在,則應該使用相對路徑。 否則,使用可在機器上存取的路徑即可。mini_batch_size:傳遞至單一run()呼叫的迷你批次大小。 (選擇性;預設值為10個檔案 (若為FileDataset) 和1MB(若為TabularDataset)。)- 針對
FileDataset,這是最小值為1的檔案數目。 您可以將多個檔案結合成一個迷你批次。 - 針對
TabularDataset,這是資料的大小。 範例值為1024、1024KB、10MB和1GB。 建議值是1MB。TabularDataset中的迷你批次絕對不會跨越檔案界限。 例如,如果有多個大小.csv檔案,則最小的檔案為 100 KB,最大為 10 MB。 如果mini_batch_size = 1MB已設定,小於 1 MB 的檔案會被視為一個迷你批次,而大於 1 MB 的檔案將會分割成多個迷你批次。注意
SQL 所支援的 TabularDataset 無法分割。 無法分割單一 parquet 檔案和單一數據列群組的 TabularDataset。
- 針對
error_threshold:處理期間應該忽略的記錄失敗數目 (針對TabularDataset) 和檔案失敗數目 (針對FileDataset)。 一旦整個輸入的錯誤計數超過此值,作業就會中止。 錯誤閾值適用於整個輸入,而非適用於傳送至run()方法的個別迷你批次。 範圍為[-1, int.max]。-1表示忽略處理期間的所有失敗。output_action:下列其中一個值指出輸出的組織方式:-
summary_only:使用者腳本必須儲存輸出檔案。 的輸出run()僅用於錯誤臨界值計算。 -
append_row:針對所有輸入,ParallelRunStep在輸出資料夾中建立單一檔案,以附加以行分隔的所有輸出。
-
append_row_file_name:若要自訂 append_row output_action 的輸出檔案名稱 (選用,預設值為parallel_run_step.txt)。source_directory:資料夾的路徑,資料夾中包含要在計算目標上執行的所有檔案 (選擇性)。compute_target:只支援AmlCompute。node_count:要用來執行使用者指令碼的計算節點數目。process_count_per_node:每個節點平行執行輸入腳本的背景工作處理序數目。 若為 GPU 機器,預設值為 1。 若為 CPU 機器,預設值為每個節點的核心數目。 背景工作進程會藉由傳遞它取得的迷你批次做為參數,重複呼叫run()。 您作業中的背景工作處理序總數為process_count_per_node * node_count,此數目會決定平行執行的run()上限數。environment:Python 環境定義。 您可以將其設定為使用現有 Python 環境,也可以設定暫存環境。 定義也會負責設定必要的應用程式相依性 (選擇性)。logging_level:記錄詳細程度。 增加詳細程度的值包括:WARNING、INFO和DEBUG。 (選擇性;預設值為INFO)run_invocation_timeout:run()方法叫用逾時 (以秒為單位)。 (選擇性;預設值為60)run_max_try:迷你批次的run()嘗試次數上限。 如果擲回例外狀況,或達到run_invocation_timeout時未傳回任何內容 (選用;預設值為3),則run()會失敗。
您可以將 mini_batch_size、node_count、process_count_per_node、logging_level、run_invocation_timeout 和 run_max_try 指定為 PipelineParameter,以便在重新提交管線執行時,可以微調參數值。
CUDA 裝置可見度
針對配備 GPU 的計算目標,環境變數 CUDA_VISIBLE_DEVICES 會在背景工作進程中設定。 在 AmlCompute 中,您可以在環境變數 AZ_BATCHAI_GPU_COUNT_FOUND 中找到自動設定的 GPU 裝置總數。 如果您想要讓每個背景工作進程都有專用的 GPU,請將 設定 process_count_per_node 為等於電腦上的 GPU 裝置數目。 然後,每個背景工作進程都會以唯一索引指派給 CUDA_VISIBLE_DEVICES。 當背景工作進程因任何原因停止時,下一個啟動的背景工作進程會採用發行的 GPU 索引。
當 GPU 裝置總數小於 process_count_per_node時,可以使用較小的索引指派 GPU 索引的背景工作進程,直到所有 GPU 都已佔用為止。
假設 GPU 裝置總數為 2, process_count_per_node = 4 例如,進程 0 和進程 1 會採用索引 0 和 1。 進程 2 和 3 沒有環境變數。 針對使用此環境變數進行 GPU 指派的程式庫,處理序 2 和 3 不會有 GPU,也不會嘗試取得 GPU 裝置。 進程 0 會在停止時釋放 GPU 索引 0。 如果適用,即進程 4,下一個進程將會指派 GPU 索引 0。
如需詳細資訊,請參閱 CUDA 專業提示:使用 CUDA_VISIBLE_DEVICES 控制 GPU 可見度。
用於建立 ParallelRunStep 的參數
使用指令碼、環境組態和參數來建立 ParallelRunStep。 指定您已附加至工作區的計算目標以作為推斷指令碼的執行目標。 使用 ParallelRunStep 來建立批次推斷管線步驟,其採用下列所有參數:
-
name:步驟的名稱,具有下列命名限制:唯一的、3 至 32 個字元,且 regex ^[a-z]([-a-z0-9]*[a-z0-9])?$。 -
parallel_run_config:如先前所定義的ParallelRunConfig物件。 -
inputs:要分割以進行平行處理的一或多個單一類型 Azure Machine Learning 資料集。 -
side_inputs:一或多個參考資料或資料集,用來作為不需要分割的端輸入。 -
outputOutputFileDatasetConfig:物件,表示輸出數據應該儲存所在的目錄路徑。 -
arguments:傳遞至使用者指令碼的引數清單。 使用 unknown_args,在您的輸入腳本中擷取 (選用)。 -
allow_reuse:在使用相同設定/輸入執行時,步驟是否應重複使用先前的結果。 如果此參數為False,則在管線執行期間,一律會為此步驟產生新的執行。 (選擇性;預設值為True。)
from azureml.pipeline.steps import ParallelRunStep
parallelrun_step = ParallelRunStep(
name="predict-digits-mnist",
parallel_run_config=parallel_run_config,
inputs=[input_mnist_ds_consumption],
output=output_dir,
allow_reuse=True
)
從遠端內容偵錯指令碼
從在本機對評分指令碼進行偵錯轉換到在實際管線中對評分指令碼進行偵錯,可能是困難的一大步驟。 如需在入口網站中尋找記錄的詳細資訊,請參閱機器學習管線一節,以了解如何從遠端內容偵錯指令碼。 該區段中的資訊也適用於 ParallelRunStep。
ParallelRunStep 作業具有分散的特性,因此會有來自數個不同來源的記錄。 不過,系統會建立兩個提供高階資訊的合併檔案:
~/logs/job_progress_overview.txt:此檔案會提供關於目前為止所建立的迷你批次 (也稱為工作) 數目,以及目前為止處理的迷你批次數目的高階資訊。 在這部分,會顯示作業的結果。 如果作業失敗,它會顯示錯誤訊息,以及啟動疑難解答的位置。~/logs/job_result.txt:它會顯示作業的結果。 如果作業失敗,則會顯示錯誤訊息,以及應從何處開始進行疑難排解。~/logs/job_error.txt:此檔案摘要說明文本中的錯誤。~/logs/sys/master_role.txt:此檔案提供執行中作業的主體節點 (也稱為協調器) 檢視。 其中包含工作建立、進度監視和執行結果。~/logs/sys/job_report/processed_mini-batches.csv:已處理之所有迷你區數據表。 它會顯示每個迷你批次執行的結果、其執行代理程式節點標識碼和進程名稱。 此外,也會包含經過的時間和錯誤訊息。 您可以遵循節點識別碼和行程名稱,找到每個迷你區執行的記錄。
您可以在下列檔案中找到使用 EntryScript 協助程式和 print 語句從專案腳本產生的記錄:
~/logs/user/entry_script_log/<node_id>/<process_name>.log.txt:這些檔案是使用 EntryScript 協助程式從 entry_script 寫入的記錄。~/logs/user/stdout/<node_id>/<process_name>.stdout.txt:這些檔案是 stdout (的記錄,例如 entry_script 的 print 語句) 。~/logs/user/stderr/<node_id>/<process_name>.stderr.txt:這些檔案是 entry_script 的 stderr 記錄。
例如,螢幕快照顯示節點 0 process001 上的minibatch 0 失敗。 您可以在與中找到~/logs/user/entry_script_log/0/process001.log.txt項目文稿的對應記錄檔。 ~/logs/user/stdout/0/process001.log.txt~/logs/user/stderr/0/process001.log.txt
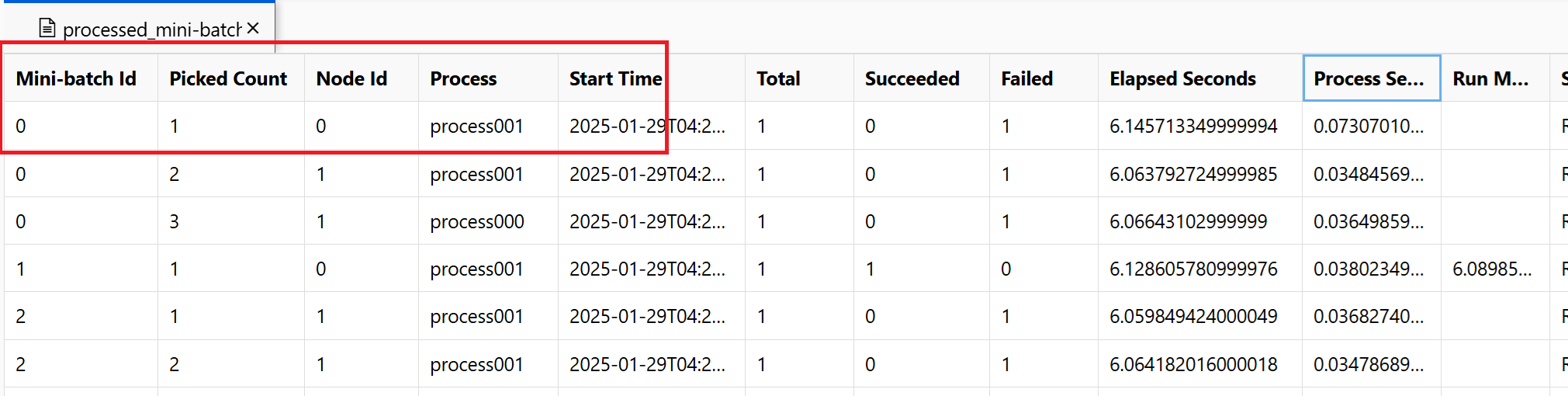
如果您需要完整了解每個節點執行分數指令碼的方式,請查看每個節點的個別程序記錄。 程序記錄會位於 ~/logs/sys/node 資料夾中,依背景工作節點分組:
~/logs/sys/node/<node_id>/<process_name>.txt:此檔案提供有關背景工作角色所挑選或完成之每個迷你批次的詳細資訊。 針對每個迷你批次,此檔案會包含:- 背景工作程序的 IP 位址和 PID。
- 項目總數、成功處理的項目計數,以及失敗的項目計數。
- 開始時間、持續時間、處理時間和執行方法時間。
針對每個節點,您也可以檢視資源使用量定期檢查的結果。 記錄檔和安裝檔案位於此資料夾中:
~/logs/perf:設定--resource_monitor_interval來變更檢查間隔 (秒)。 預設間隔為600,大約 10 分鐘。 若要停止監視,請將值設定為0。 每個<node_id>資料夾包含:-
os/:節點中所有執行中程序的相關資訊。 一項檢查會執行作業系統命令,並將結果儲存至檔案。 在 Linux 上,命令為ps。 針對 Windows,請使用tasklist。-
%Y%m%d%H:子資料夾名稱是精確至小時的時間。-
processes_%M:檔案的結尾是檢查時間的分鐘。
-
-
-
node_disk_usage.csv:節點的詳細磁碟使用量。 -
node_resource_usage.csv:節點的資源使用量概觀。 -
processes_resource_usage.csv:每個程序的資源使用量概觀。
-
常見的作業失敗原因
SystemExit:42
結束 41 和 42 是 PRS 設計的結束代碼。 背景工作節點會以 41 結束,以通知計算管理員獨立終止。 這是預期的結果。 領導者節點可能會以 0 或 42 結束,表示作業結果。 結束 42 表示作業失敗。 在中找到 ~/logs/job_result.txt失敗原因。 您可以依照上一節進行偵錯作業。
數據許可權
作業的錯誤表示計算無法存取輸入數據。 如果身分識別型用於計算叢集和記憶體,您可以參考 以身分識別為基礎的數據驗證。
進程意外終止
進程可能會因為非預期或未處理的例外狀況而損毀,系統會因為記憶體不足例外狀況而終止進程。 在 PRS 系統記錄中 ~/logs/sys/node/<node-id>/_main.txt,可以找到如下的錯誤。
<process-name> exits with returncode -9.
記憶體已用盡
~/logs/perf 會記錄進程的計算資源耗用量。 可以找到每個工作處理器的記憶體使用量。 您可以估計節點上的記憶體使用量總計。
在中找到 ~/system_logs/lifecycler/<node-id>/execution-wrapper.txt記憶體不足錯誤。
如果計算資源已關閉限制,建議您減少每個節點的進程數目,或升級 VM 大小。
未處理的例外狀況
在某些情況下,Python 進程無法攔截失敗的堆疊。 您可以新增環境變數 env["PYTHONFAULTHANDLER"]="true" 來啟用 Python 內建錯誤處理程式。
Minibatch 逾時
您可以根據您的迷你批次工作來調整 run_invocation_timeout 自變數。 當您看到 run() 函式需要比預期更多的時間時,以下是一些秘訣。
檢查迷你批次的經過時間和處理時間。 進程時間會測量進程的CPU時間。 當處理時間明顯短於經過時,您可以檢查工作中是否有一些繁重的 IO 作業或網路要求。 這些作業的長時間延遲是迷你批次逾時的常見原因。
一些特定的迷你菜需要比其他人更長的時間。 您可以更新組態,或嘗試使用輸入數據來平衡迷你批次處理時間。
如何從遠端內容中的使用者指令碼進行記錄?
ParallelRunStep 可根據 process_count_per_node,在一個節點上執行多個處理序。 為了組織節點上每個進程的記錄,並結合 print 和 log 語句,建議使用 ParallelRunStep 記錄器,如下所示。 您可以從 EntryScript 取得記錄器,並使記錄顯示在入口網站的 logs/user 資料夾中。
使用記錄器的範例輸入指令碼:
from azureml_user.parallel_run import EntryScript
def init():
"""Init once in a worker process."""
entry_script = EntryScript()
logger = entry_script.logger
logger.info("This will show up in files under logs/user on the Azure portal.")
def run(mini_batch):
"""Call once for a mini batch. Accept and return the list back."""
# This class is in singleton pattern. It returns the same instance as the one in init()
entry_script = EntryScript()
logger = entry_script.logger
logger.info(f"{__file__}: {mini_batch}.")
...
return mini_batch
Python logging 的訊息會由何處接收?
ParallelRunStep 會在根記錄器上設定處理常式,以將訊息接收至 logs/user/stdout/<node_id>/processNNN.stdout.txt。
logging 預設為 INFO 層級。 依預設,低於 INFO 的層級不會顯示,例如 DEBUG。
如何寫入檔案以顯示在入口網站中?
寫入 /logs 資料夾的檔案將會上傳並顯示在入口網站中。
您可以將 logs/user/entry_script_log/<node_id> 資料夾調整如下,並撰寫您的檔案路徑來寫入:
from pathlib import Path
from azureml_user.parallel_run import EntryScript
def init():
"""Init once in a worker process."""
entry_script = EntryScript()
log_dir = entry_script.log_dir
log_dir = Path(entry_script.log_dir) # logs/user/entry_script_log/<node_id>/.
log_dir.mkdir(parents=True, exist_ok=True) # Create the folder if not existing.
proc_name = entry_script.agent_name # The process name in pattern "processNNN".
fil_path = log_dir / f"{proc_name}_<file_name>" # Avoid conflicting among worker processes with proc_name.
如何處理新處理序中的記錄?
您可以使用 subprocess 模組在輸入腳本中產生新的處理常式、連接至其輸入/輸出/錯誤管道,並取得傳回碼。
建議的方法是使用 run() 函式並設定 capture_output=True。 錯誤會顯示在中 logs/user/error/<node_id>/<process_name>.txt。
如果您想要使用 Popen(),stdout/stderr 應該重新導向至檔案,例如:
from pathlib import Path
from subprocess import Popen
from azureml_user.parallel_run import EntryScript
def init():
"""Show how to redirect stdout/stderr to files in logs/user/entry_script_log/<node_id>/."""
entry_script = EntryScript()
proc_name = entry_script.agent_name # The process name in pattern "processNNN".
log_dir = Path(entry_script.log_dir) # logs/user/entry_script_log/<node_id>/.
log_dir.mkdir(parents=True, exist_ok=True) # Create the folder if not existing.
stdout_file = str(log_dir / f"{proc_name}_demo_stdout.txt")
stderr_file = str(log_dir / f"{proc_name}_demo_stderr.txt")
proc = Popen(
["...")],
stdout=open(stdout_file, "w"),
stderr=open(stderr_file, "w"),
# ...
)
注意
背景工作處理序會在相同的處理序中執行「系統」程式碼和輸入腳本程式碼。
stdout如果沒有或stderr指定,工作進程的設定將會由在專案腳本中建立Popen()的子進程繼承。
stdout寫入 至 ~/logs/sys/node/<node_id>/processNNN.stdout.txt 和 stderr 。~/logs/sys/node/<node_id>/processNNN.stderr.txt
如何將檔案寫入輸出目錄,然後在入口網站中查看?
您可以從 類別取得輸出目錄 EntryScript ,並將其寫入其中。 若要檢視寫入的檔案,請在 Azure Machine Learning 入口網站的 [執行] 檢視步驟中,選取 [輸出 + 記錄] 索引標籤。選取資料輸出連結,然後完成對話方塊中所述的步驟。
在您的輸入腳本中使用 EntryScript,如此範例中所示:
from pathlib import Path
from azureml_user.parallel_run import EntryScript
def run(mini_batch):
output_dir = Path(entry_script.output_dir)
(Path(output_dir) / res1).write...
(Path(output_dir) / res2).write...
如何將側邊輸入,例如包含查閱表格的檔案或檔案傳遞給所有背景工作角色?
使用者可以使用 ParalleRunStep 的 side_inputs 參數,將參考資料傳遞給指令碼。 每個背景工作節點上都會掛接以side_inputs提供的所有數據集。 使用者可以藉由傳遞引數來取得掛接的位置。
建構包含參考資料的資料集、指定本機掛接路徑,並將其註冊至您的工作區。 將其傳至您 ParallelRunStep 的 side_inputs 參數。 此外,您可以在 arguments 區段中新增其路徑,以輕鬆存取其掛接路徑。
注意
FileDatasets 僅適用於 side_inputs。
local_path = "/tmp/{}".format(str(uuid.uuid4()))
label_config = label_ds.as_named_input("labels_input").as_mount(local_path)
batch_score_step = ParallelRunStep(
name=parallel_step_name,
inputs=[input_images.as_named_input("input_images")],
output=output_dir,
arguments=["--labels_dir", label_config],
side_inputs=[label_config],
parallel_run_config=parallel_run_config,
)
之後,您可以在腳本中存取它(例如,在 init() 方法中,如下所示:
parser = argparse.ArgumentParser()
parser.add_argument('--labels_dir', dest="labels_dir", required=True)
args, _ = parser.parse_known_args()
labels_path = args.labels_dir
如何透過服務主體驗證使用輸入資料集?
使用者可以透過工作區中使用的服務主體驗證傳遞輸入資料集。 在 ParallelRunStep 中使用此類資料集需要註冊資料集,才能建立 ParallelRunStep 設定。
service_principal = ServicePrincipalAuthentication(
tenant_id="***",
service_principal_id="***",
service_principal_password="***")
ws = Workspace(
subscription_id="***",
resource_group="***",
workspace_name="***",
auth=service_principal
)
default_blob_store = ws.get_default_datastore() # or Datastore(ws, '***datastore-name***')
ds = Dataset.File.from_files(default_blob_store, '**path***')
registered_ds = ds.register(ws, '***dataset-name***', create_new_version=True)
如何檢查進度並加以分析
本節說明如何檢查 ParallelRunStep 作業的進度,以及檢查非預期行為的原因。
如何檢查作業進度?
除了查看 StepRun 的整體狀態之外,您還可以在 ~/logs/job_progress_overview.<timestamp>.txt 中查看已排程/已處理的迷你批次計數,以及產生輸出的進度。 檔案會每天輪替。 您可以檢查具有最大時間戳的時間戳,以取得最新資訊。
如果有一段時間沒有進度,我應該檢查什麼?
您可以進入 ~/logs/sys/error 以查看是否有任何例外狀況。 如果沒有,您的專案腳本可能會花費很長的時間,您可以在程式代碼中列印進度資訊,以找出耗時的部分,或將 新增"--profiling_module", "cProfile"至 ParallelRunSteparguments ,以產生名為 <process_name>.profile 的配置檔檔在資料夾下~/logs/sys/node/<node_id>。
作業何時會停止?
如果未取消,作業可能會停止狀態:
- 已完成。 所有迷你批次都會順利處理,併產生模式的
append_row輸出。 - 失敗。 如果
error_threshold超過 inParameters for ParallelRunConfig,或在作業期間發生系統錯誤。
如何找到失敗的根本原因?
您可以遵循 ~/logs/job_result.txt 中的提示以找出原因和詳細的錯誤記錄檔。
節點失敗會影響作業結果嗎?
如果指定的計算叢集中有其他可用的節點,則不會影響。 ParallelRunStep 可以在每個節點上獨立執行。 單一節點失敗不會讓整個作業失敗。
如果輸入腳本中的 init 函式失敗會有什麼結果?
ParallelRunStep 有一定時間重試的機制,讓您有機會從暫時性問題復原,而不會延遲作業失敗太久。 機制如下所示:
- 在節點啟動後,如果所有代理程式上的
init持續失敗,我們將會在3 * process_count_per_node次失敗後停止嘗試。 - 在作業開始後,當所有節點的所有代理程式上
init都持續失敗,如果作業執行超過 2 分鐘且失敗超過2 * node_count * process_count_per_node次,我們就會停止嘗試。 - 如果
init上的所有代理程式都停滯超過3 * run_invocation_timeout + 30秒,則作業將會因過長時間沒有進度而失敗。
OutOfMemory 上會發生什麼事? 如何檢查原因?
進程可能會由系統終止。 ParallelRunStep 會設定目前嘗試將迷你批次處理為失敗狀態,並嘗試重新啟動失敗的進程。 您可以檢查 ~logs/perf/<node_id> 以尋找耗費大量記憶體的處理序。
為什麼我有許多 processNNN 檔案?
ParallelRunStep 會啟動新的背景工作進程,以取代已異常結束的背景工作進程。 每個進程都會產生一組 processNNN 檔案作為記錄檔。 但是,如果處理序是因為使用者指令碼的 init 函式發生例外狀況而失敗,且錯誤連續重複發生 3 * process_count_per_node 次時,則不會啟動新的背景工作處理序。
下一步
參閱 SDK 參考以獲得 azureml-pipeline-steps 套件的協助。
遵循進階教學課程,了解如何使用具有 ParallelRunStep 的管線。 此教學課程會示範如何將另一個檔案作為端輸入傳遞。