建立及管理資料資產
適用於: Azure CLI ml 延伸模組 v2 (目前)Python SDK azure-ai-ml v2 (目前)
Azure CLI ml 延伸模組 v2 (目前)Python SDK azure-ai-ml v2 (目前)
本文說明如何在 Azure Machine Learning 中建立和管理資料資產。
需要這些項目時,資料資產可協助您執行以下操作:
- 版本設定:資料資產支援資料版本設定。
- 重現性:資料資產版本建立後,會固定不變。 無法修改或刪除。 因此,可以重現取用資料資產的定型作業或管線。
- 可稽核性:因為資料資產版本為固定不變,所以您可以追蹤資產版本、更新版本的人員,以及發生版本更新的時間。
- 譜系:針對任何指定的資料資產,您可以檢視哪些作業或管線會取用資料。
- 方便使用:Azure Machine Learning 資料資產類似於網頁瀏覽器書籤 (我的最愛)。 您可以建立資料資產版本,然後以易記名稱 (例如
azureml:<my_data_asset_name>:<version>) 存取該資產版本,而不是記住參考您在 Azure 儲存體上常用資料的長期儲存路徑 (URI)。
提示
若要在互動式工作階段 (例如筆記本) 或作業中存取資料,就不需要先建立資料資產。 您可以使用資料存放區 URI 來存取資料。 資料存放區 URI 提供簡單的方法存取開始使用 Azure Machine Learning 的資料。
必要條件
若要建立並使用資料資產,您需要:
Azure 訂用帳戶。 如果您沒有 Azure 訂用帳戶,請在開始前建立免費帳戶。 試用免費或付費版本的 Azure Machine Learning。
Azure Machine Learning 工作區。 建立工作區資源。
建立資料資產
若要建立資料資產,您必須設定資料資產類型。 Azure Machine Learning 支援三種資料類型:
| 類型 | API | 標準案例 |
|---|---|---|
| 檔案 參考單一檔案 |
uri_file |
讀取 Azure 儲存體上的單一檔案 (檔案可以是任何格式)。 |
| 資料夾 參考資料夾 |
uri_folder |
將 parquet/CSV 檔案的資料夾讀入 Pandas/Spark。 讀取位於資料夾中的非結構化資料 (影像、文字、音訊等)。 |
| Table 參考資料表 |
mltable |
您的複雜結構描述可能會經常變更,或需要大型表格式資料的子集。 含有資料表的 AutoML。 讀取分散在多個儲存位置的非結構化資料 (影像、文字、音訊等)。 |
注意
如果您將資料註冊為MLTable,只能在 csv 檔案中使用內嵌新行字元。 讀取資料時,csv 檔案中的內嵌新行字元可能會導致未對齊的欄位值。 MLTable 在 read_delimited 中轉換中有此 support_multi_line參數,用於將以引號括住的分行符號解譯為一筆記錄。
在 Azure Machine Learning 作業中取用資料資產時,您可以將資產掛接或下載到計算節點。 如需詳細資訊,請造訪模式。
此外,您必須指定指向資料資產位置的 path 參數。 支援的路徑包括:
| Location | 範例 |
|---|---|
| 本機電腦上的路徑 | ./home/username/data/my_data |
| 資料存放區上的路徑 | azureml://datastores/<data_store_name>/paths/<path> |
| 公用 HTTP 伺服器的路徑 | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
| Azure 儲存體上的路徑 | (Blob) wasbs://<containername>@<accountname>.blob.core.windows.net/<path_to_data>/(ADLS gen2) abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> (ADLS gen1) adl://<accountname>.azuredatalakestore.net/<path_to_data>/ |
注意
從本機路徑建立資料資產時,將自動上傳至預設 Azure Machine Learning 雲端資料存放區。
建立資料資產:檔案類型
檔案 (uri_file) 類型資料資產會指向儲存體上的單一檔案 (例如 CSV 檔案)。 您可以用下列項目來建立檔案類型的資料資產:
建立 YAML 檔案,然後複製並貼上下列程式碼片段。 請務必更新 <> 和 預留位置,搭配
- 資料資產的名稱
- 版本
- description
- 支援位置上單一檔案的路徑
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
# Supported paths include:
# local: './<path>/<file>' (this will be automatically uploaded to cloud storage)
# blob: 'wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>/<file>'
# ADLS gen2: 'abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>/<file>'
# Datastore: 'azureml://datastores/<data_store_name>/paths/<path>/<file>'
type: uri_file
name: <NAME OF DATA ASSET>
version: <VERSION>
description: <DESCRIPTION>
path: <SUPPORTED PATH>
接著,在 CLI 中執行下列命令。 請務必將 <filename> 預留位置更新為 YAML 檔名。
az ml data create -f <filename>.yml
![醒目提示 [資料資產] 索引標籤中的 [建立] 螢幕擷取畫面。](media/how-to-create-data-assets/data-assets-create.png?view=azureml-api-2)
![在此螢幕擷取畫面中,在 [類型] 下拉式清單中選擇 [檔案] (uri 資料夾)。](media/how-to-create-data-assets/create-data-asset-file-type.png?view=azureml-api-2)
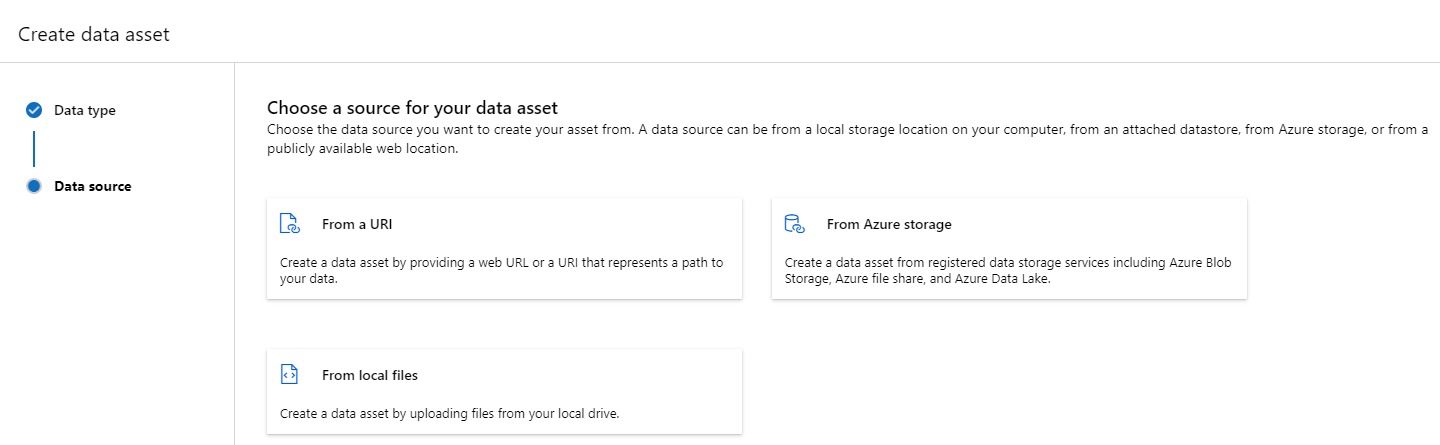
建立資料資產:資料夾類型
屬於資料夾 (uri_folder) 類型資料資產指儲存資源上的資料夾,例如包含數個映像子資料夾的資料夾。 您可以透過下列項目建立資料夾類型的資料資產:
複製以下程式碼並貼到新的 YAML 檔案中。 請務必更新 <> 和 預留位置,搭配
- 資料資產的名稱
- 版本
- 描述
- 支援位置上資料夾的路徑
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
# Supported paths include:
# local: './<path>/<folder>' (this will be automatically uploaded to cloud storage)
# blob: 'wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>/<folder>'
# ADLS gen2: 'abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>/<folder>'
# Datastore: 'azureml://datastores/<data_store_name>/paths/<path>/<folder>'
type: uri_folder
name: <NAME OF DATA ASSET>
version: <VERSION>
description: <DESCRIPTION>
path: <SUPPORTED PATH>
接著,在 CLI 中執行下列命令。 請務必將 <filename> 預留位置更新為 YAML 檔名。
az ml data create -f <filename>.yml
![在此螢幕擷取畫面中,在 [類型] 下拉式清單中選擇 [資料夾] (uri 資料夾)。](media/how-to-create-data-assets/create-data-asset-folder-type.png?view=azureml-api-2)
建立資料資產:資料表類型
Azure Machine Learning 資料表 (MLTable) 有豐富的功能,詳情請參閱在 Azure Machine Learning 中使用資料表。 與其在這裡重複該文件,請使用位於公開可用的 Azure Blob 儲存體帳戶上的 Titanic 資料,閱讀描述如何建立資料表類型資料資產的範例。
首先,建立名為 data 的新目錄,並建立名為 MLTable 的檔案:
mkdir data
touch MLTable
接著,將下列 YAML 複製並貼到您在上一個步驟中建立的 MLTable 檔案中:
警告
請勿將 MLTable 檔案重新命名為 MLTable.yaml 或 MLTable.yml。 Azure Machine Learning 預期 MLTable 檔案。
paths:
- file: wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv
transformations:
- read_delimited:
delimiter: ','
empty_as_string: false
encoding: utf8
header: all_files_same_headers
include_path_column: false
infer_column_types: true
partition_size: 20971520
path_column: Path
support_multi_line: false
- filter: col('Age') > 0
- drop_columns:
- PassengerId
- convert_column_types:
- column_type:
boolean:
false_values:
- 'False'
- 'false'
- '0'
mismatch_as: error
true_values:
- 'True'
- 'true'
- '1'
columns: Survived
type: mltable
在 CLI 中執行下列命令。 請確實使用資料資產名稱和版本值來更新 <> 預留位置。
az ml data create --path ./data --name <DATA ASSET NAME> --version <VERSION> --type mltable
重要
path 應該是包含有效 MLTable 檔案的資料夾。
從作業輸出建立資料資產
您可以從 Azure Machine Learning 工作建立資料資產。 若要這樣做,請在輸出中設定 name 參數。 在此範例中,您會提交作業,以將資料從公用 Blob 存放區複製到預設 Azure Machine Learning 資料存放區,並建立名為 job_output_titanic_asset 的資料資產。
建立作業規格 YAML 檔案 (<file-name>.yml):
$schema: https://azuremlschemas.azureedge.net/latest/commandJob.schema.json
# path: Set the URI path for the data. Supported paths include
# local: `./<path>
# Blob: wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>
# ADLS: abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# Data Asset: azureml:<my_data>:<version>
# type: What type of data are you pointing to?
# uri_file (a specific file)
# uri_folder (a folder)
# mltable (a table)
# mode: Set INPUT mode:
# ro_mount (read-only mount)
# download (download from storage to node)
# mode: Set the OUTPUT mode
# rw_mount (read-write mount)
# upload (upload data from node to storage)
type: command
command: cp ${{inputs.input_data}} ${{outputs.output_data}}
compute: azureml:cpu-cluster
environment: azureml://registries/azureml/environments/sklearn-1.1/versions/4
inputs:
input_data:
mode: ro_mount
path: wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv
type: uri_file
outputs:
output_data:
mode: rw_mount
path: azureml://datastores/workspaceblobstore/paths/quickstart-output/titanic.csv
type: uri_file
name: job_output_titanic_asset
接著,使用 CLI 提交作業:
az ml job create --file <file-name>.yml
管理資料資產
刪除資料資產
重要
依設計,不支援刪除資料資產。
如果 Azure Machine Learning 允許刪除資料資產,則會產生下列不良和負面影響:
- 取用稍後刪除之資料資產的生產作業將會失敗。
- 重現 ML 實驗會變得更加困難。
- 作業譜系會中斷,因為無法檢視已刪除的資料資產版本。
- 您無法正確追蹤和稽核,因為版本可能遺失。
因此,在小組中建立生產工作負載時,資料資產不變性可提供保護層級。
針對錯誤建立的資料資產 - 例如,名稱、類型或路徑不正確,Azure Machine Learning 會提供解決方案來處理這種情況,而不會造成刪除的負面後果:
| 我想要刪除此資料資產,因為以下原因: | 解決方案 |
|---|---|
| 名稱不正確 | 封存資料資產 |
| 小組不再使用此資料資產 | 封存資料資產 |
| 其使資料資產清單雜亂無章 | 封存資料資產 |
| 路徑不正確 | 使用正確的路徑建立新版的資料資產 (相同名稱)。 如需詳細資訊,請造訪建立資料資產。 |
| 其類型不正確 | 目前,Azure Machine Learning 不允許建立與初始版本不同類型的新版本。 (1) 封存資料資產 (2) 使用正確的類型以不同的名稱建立新的資料資產。 |
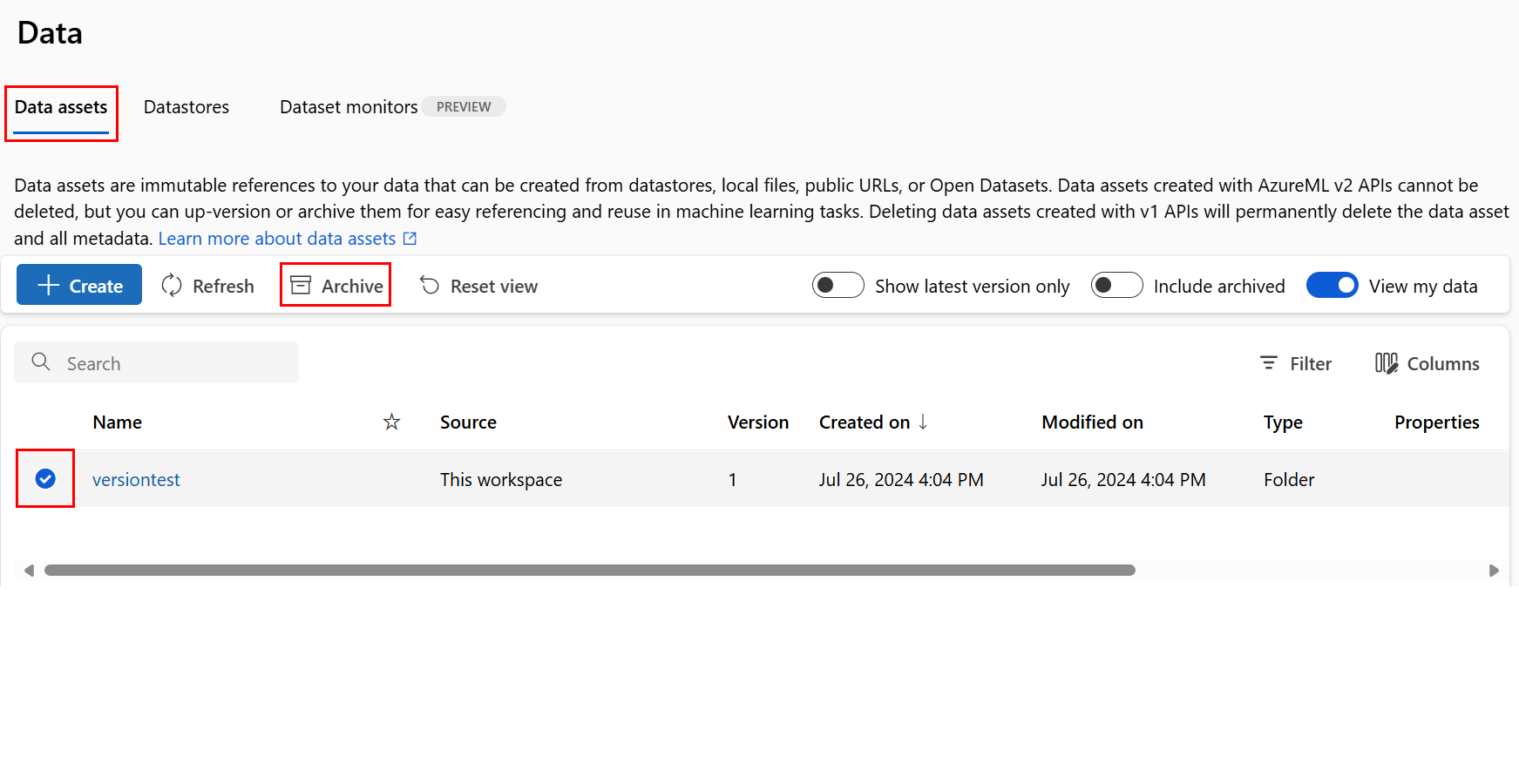
封存資料資產
封存資料資產預設會同時在清單查詢 (例如 CLI az ml data list 中) 和 Studio UI 中的資料資產清單中將其隱藏。 您仍然可以繼續在工作流程中參考並使用封存的資料資產。 您可以封存下列其中一項:
- 指定名稱下資料資產的所有版本
或
- 資料資產的特定版本
封存資料資產的所有版本
若要封存指定的名稱下資料資產的所有版本,請使用:
執行以下命令。 請務必更新 <> 和 預留位置,搭配您的資訊。
az ml data archive --name <NAME OF DATA ASSET>
封存資料資產的特定版本
若要封存資料資產的特定版本,請使用:
執行以下命令。 請確實使用資料資產名稱和版本來更新 <> 預留位置。
az ml data archive --name <NAME OF DATA ASSET> --version <VERSION TO ARCHIVE>
還原封存的資料資產
您可以還原封存的資料資產。 如果封存資料資產的所有版本,您就無法還原個別版本的資料資產,您必須還原所有版本。
還原資料資產的所有版本
若要還原指定的名稱下資料資產的所有版本,請使用:
執行以下命令。 請確實使用資料資產名稱來更新 <> 預留位置。
az ml data restore --name <NAME OF DATA ASSET>
![顯示 [已選取封存] 的螢幕擷取畫面。](media/how-to-create-data-assets/data-asset-restore-incarc.png?view=azureml-api-2)
![顯示選取 [還原] 的螢幕擷取畫面。](media/how-to-create-data-assets/data-asset-restore.png?view=azureml-api-2)
還原資料資產的特定版本
重要
如果封存所有版本的資料資產,您就無法還原個別版本的資料資產,您必須還原所有版本。
若要還原資料資產的特定版本,請使用:
執行以下命令。 請確實使用資料資產名稱和版本來更新 <> 預留位置。
az ml data restore --name <NAME OF DATA ASSET> --version <VERSION TO ARCHIVE>
資料譜系
廣義來說,「資料譜系」是指跨越資料的來源生命週期,以及其隨時間在儲存體之間移動的位置。 不同類型的回溯案例會使用,例如
- 疑難排解
- 追蹤 ML 管線中的根本原因
- 偵錯
資料品質分析、合規性和「假設狀況」案例也會使用譜系。 譜系會以視覺化方式呈現,以顯示從來源移至目的地的資料,而且還涵蓋資料轉換。 鑑於大部分企業資料環境的複雜程度,若未對周邊資料點進行彙總或遮罩,這些檢視可能難以理解。
在 Azure Machine Learning 管線中,資料資產會顯示資料的原點,以及資料的處理方式,例如:
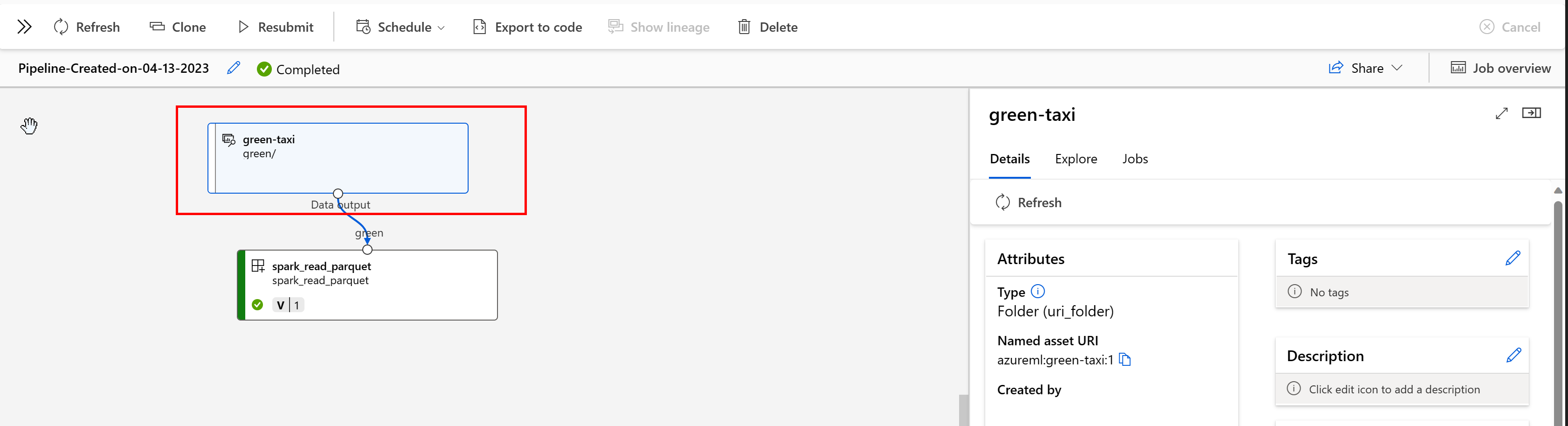
您可以在 Studio UI 中檢視取用資料資產的工作。 首先,從左側功能表中選取 [資料],然後選取資料資產名稱。 請注意取用資料資產的作業:
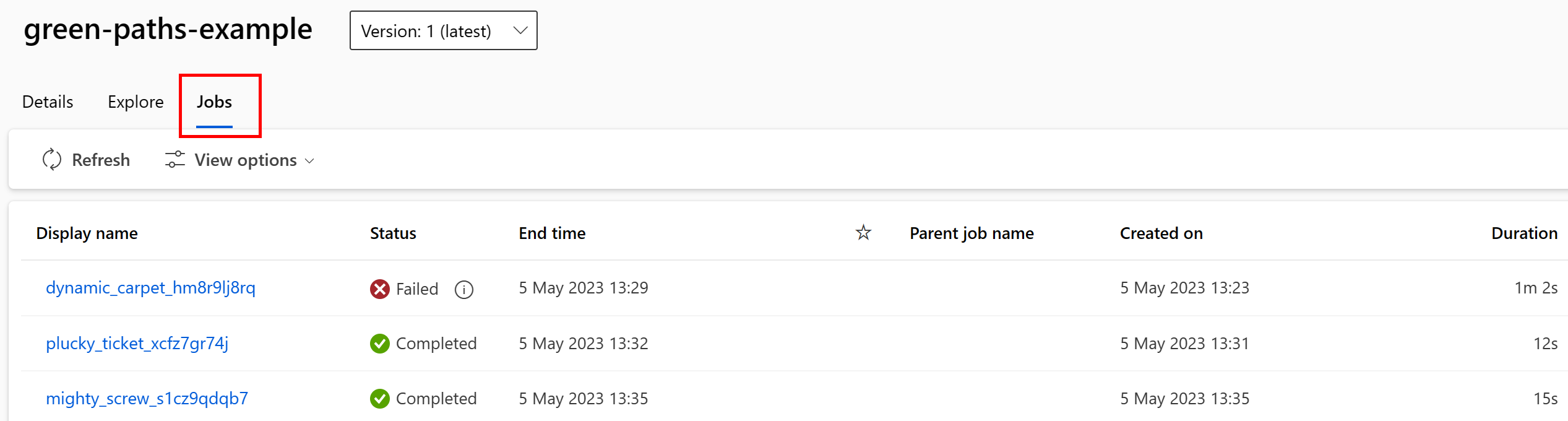
資料資產中的作業檢視可讓您更輕鬆地尋找作業失敗,並在 ML 管線和偵錯中執行根原因分析。
資料資產標記
資料資產支援標記,這是作為索引鍵/值組套用至資料資產的額外中繼資料。 資料標記提供許多優點:
- 資料品質描述。 例如,如果貴公司使用 medallion 湖存放庫架構,您可以使用
medallion:bronze(原始)、medallion:silver(已驗證) 和medallion:gold(已擴充) 來標記資產。 - 有效率的資料搜尋和篩選,以協助資料探索。
- 識別機密個人資料,以正確管理和規範資料存取。 例如:
sensitivity:PII/sensitivity:nonPII。 - 判斷負責任 AI (RAI) 稽核是否核准資料。 例如:
RAI_audit:approved/RAI_audit:todo。
您可以將標籤新增至資料資產作為建立流程的一部分,也可以將標籤新增至現有的資料資產。 本節顯示這兩者:
將標記新增為資料資產建立流程的一部分
建立 YAML 檔案,然後複製並貼上下列程式碼至 YAML 檔案中。 請務必更新 <> 和 預留位置,搭配
- 資料資產的名稱
- 版本
- description
- 標籤 (索引鍵/值組)
- 支援位置上單一檔案的路徑
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
# Supported paths include:
# local: './<path>/<file>' (this will be automatically uploaded to cloud storage)
# blob: 'wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>/<file>'
# ADLS gen2: 'abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>/<file>'
# Datastore: 'azureml://datastores/<data_store_name>/paths/<path>/<file>'
# Data asset types, use one of:
# uri_file, uri_folder, mltable
type: uri_file
name: <NAME OF DATA ASSET>
version: <VERSION>
description: <DESCRIPTION>
tags:
<KEY1>: <VALUE>
<KEY2>: <VALUE>
path: <SUPPORTED PATH>
在 CLI 中執行下列命令。 請務必將 <filename> 預留位置更新為 YAML 檔名。
az ml data create -f <filename>.yml
將標籤新增至現有的資料資產
在 Azure CLI 中執行下列命令。 請務必更新 <> 和 預留位置,搭配
- 資料資產的名稱
- 版本
- 輸入索引建值組標籤
az ml data update --name <DATA ASSET NAME> --version <VERSION> --set tags.<KEY>=<VALUE>
![顯示在 Studio UI 中選取 [將標籤新增至資料資產] 的螢幕擷取畫面。](media/how-to-create-data-assets/data-asset-tags.png?view=azureml-api-2)
版本設定最佳做法
ETL 程序通常會依時間組織 Azure 儲存體上的資料夾結構,例如:
/
└── 📁 mydata
├── 📁 year=2022
│ ├── 📁 month=11
│ │ └── 📄 file1
│ │ └── 📄 file2
│ └── 📁 month=12
│ └── 📄 file1
│ │ └── 📄 file2
└── 📁 year=2023
└── 📁 month=1
└── 📄 file1
│ │ └── 📄 file2
時間/版本結構化資料夾和 Azure Machine Learning 資料表 (MLTable) 的組合可讓您建構版本化的資料集。 為示範如何使用 Azure Machine Learning 資料表來達成版本化的資料,我們會使用假設範例。 假設您有一個程序,每周將相機影像上傳至 Azure Blob 儲存體,在其結構中:
/myimages
└── 📁 year=2022
├── 📁 week52
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
└── 📁 year=2023
├── 📁 week1
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
注意
雖然我們示範如何設定映像 (jpeg) 資料的版本,但相同方法適用於任何檔案類型 (例如 Parquet、CSV)。
使用 Azure Machine Learning 資料表 (mltable),可以建構路徑資料表,其中包含到 2023 年第一周結束的資料。 接著建立資料資產:
import mltable
from mltable import MLTableHeaders, MLTableFileEncoding, DataType
from azure.ai.ml import MLClient
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
from azure.identity import DefaultAzureCredential
# The ** in the pattern below will glob all sub-folders (camera1, ..., camera2)
paths = [
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2022/week=52/**/*.jpeg"
},
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2023/week=1/**/*.jpeg"
},
]
tbl = mltable.from_paths(paths)
tbl.save("./myimages")
# Connect to the AzureML workspace
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# Define the Data asset object
my_data = Data(
path=mltable_folder,
type=AssetTypes.MLTABLE,
description="My images. Version includes data through to 2023-Jan-08.",
name="myimages",
version="20230108",
)
# Create the data asset in the workspace
ml_client.data.create_or_update(my_data)
在下周結束時,您的 ETL 更新資料以包含更多資料:
/myimages
└── 📁 year=2022
├── 📁 week52
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
└── 📁 year=2023
├── 📁 week1
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
├── 📁 week2
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
第一個版本 (20230108) 只會從 year=2022/week=52 和 year=2023/week=1 掛接/下載檔案,因為路徑會在 MLTable 檔案中宣告。 這可確保實驗的重現性。 若要建立包含 year=2023/week2 的新版資料資產,請使用:
import mltable
from mltable import MLTableHeaders, MLTableFileEncoding, DataType
from azure.ai.ml import MLClient
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
from azure.identity import DefaultAzureCredential
# The ** in the pattern below will glob all sub-folders (camera1, ..., camera2)
paths = [
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2022/week=52/**/*.jpeg"
},
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2023/week=1/**/*.jpeg"
},
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2023/week=2/**/*.jpeg"
},
]
# Save to an MLTable file on local storage
tbl = mltable.from_paths(paths)
tbl.save("./myimages")
# Next, you create a data asset - the MLTable file will automatically be uploaded
# Connect to the AzureML workspace
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# Define the Data asset object
my_data = Data(
path=mltable_folder,
type=AssetTypes.MLTABLE,
description="My images. Version includes data through to 2023-Jan-15.",
name="myimages",
version="20230115", # update version to the date
)
# Create the data asset in the workspace
ml_client.data.create_or_update(my_data)
您現在有兩個版本的資料,其中版本的名稱對應至影像上傳至儲存體的日期:
- 20230108:截至 2023 年 1 月 8 日的影像。
- 20230115:截至 2023 年 1 月 15 日的影像。
在這兩種情況下,MLTable 都會建立一個路徑表,其中僅包含截至這些日期的影像。
在 Azure Machine Learning 作業中,您可以使用 eval_download 或 eval_mount 模式,將版本化 MLTable 中的這些路徑掛接或下載到您的計算目標:
from azure.ai.ml import MLClient, command, Input
from azure.ai.ml.entities import Environment
from azure.identity import DefaultAzureCredential
from azure.ai.ml.constants import InputOutputModes
# connect to the AzureML workspace
ml_client = MLClient.from_config(
DefaultAzureCredential()
)
# Get the 20230115 version of the data
data_asset = ml_client.data.get(name="myimages", version="20230115")
input = {
"images": Input(type="mltable",
path=data_asset.id,
mode=InputOutputModes.EVAL_MOUNT
)
}
cmd = """
ls ${{inputs.images}}/**
"""
job = command(
command=cmd,
inputs=input,
compute="cpu-cluster",
environment="azureml://registries/azureml/environments/sklearn-1.1/versions/4"
)
ml_client.jobs.create_or_update(job)
注意
eval_mount 和 eval_download 模式是 MLTable 專用。 在此情況下,AzureML 資料執行階段功能會評估 MLTable 檔案,並在計算目標上掛接路徑。