設定 AutoML,以定型電腦視覺模型
適用於: Azure CLI ml 延伸模組 v2 (目前)Python SDK azure-ai-ml v2 (目前)
Azure CLI ml 延伸模組 v2 (目前)Python SDK azure-ai-ml v2 (目前)
在本文中,您會了解如何使用自動化 ML,在映像資料上定型電腦視覺模型。 您可以使用 Azure Machine Learning CLI 延伸模組 v2 或 Azure Machine Learning Python SDK v2 來定型模型。
自動化 ML 支援對電腦視覺工作 (例如影像分類、物件偵測和執行個體分割) 進行模型定型。 目前透過 Azure Machine Learning Python SDK 支援編寫電腦視覺工作的 AutoML 模型。 可以從 Azure Machine Learning 工作室 UI 存取產生的實驗試用、模型和輸出。 深入了解影像資料上電腦視覺工作的自動化 ML。
必要條件
- Azure Machine Learning 工作區。 若要建立工作區,請參閱建立工作區資源。
- 安裝並設定 CLI (第 2 版),並確定您已安裝
ml延伸模組。
選取您的工作類型
影像的自動化 ML 支援下列工作類型:
| 工作類型 | AutoML 作業語法 |
|---|---|
| 影像分類 | CLI 第 2 版:image_classification SDK 第 2 版: image_classification() |
| 影像分類多標籤 | CLI 第 2 版:image_classification_multilabel SDK 第 2 版: image_classification_multilabel() |
| 影像物件偵測 | CLI 第 2 版:image_object_detection SDK 第 2 版: image_object_detection() |
| 影像執行個體分割 | CLI 第 2 版:image_instance_segmentation SDK 第 2 版: image_instance_segmentation() |
此工作類型是必要參數,可以使用 task 索引鍵加以設定。
例如:
task: image_object_detection
定型及驗證資料
為了產生電腦視覺模型,您必須以 MLTable 的形式,攜帶標記的影像資料做為模型定型的輸入。 您可以從 JSONL 格式的定型資料建立 MLTable。
如果您的定型資料採用不同的格式 (例如,pascal VOC 或 COCO),您可以套用範例筆記本隨附的協助程式指令碼,將資料轉換為 JSONL。 深入了解如何使用自動化 ML 來準備用於電腦視覺工作的資料。
注意
定型資料必須至少有 10 個影像,才能提交 AutoML 作業。
警告
僅支援使用 SDK 和 CLI 從 JSONL 格式的資料建立 MLTable。 目前不支援透過 UI 建立 MLTable。
JSONL 結構描述範例
TabularDataset 的結構取決於手邊的工作。 對於電腦視覺工作類型,其是由下列欄位組成:
| 欄位 | 描述 |
|---|---|
image_url |
包含檔案路徑作為 StreamInfo 物件 |
image_details |
影像中繼資料資訊由高度、寬度和格式組成。 這是選擇性欄位,因此不一定存在。 |
label |
影像標籤的 JSONL 表示法 (以工作類型為基礎)。 |
以下程式碼是用於影像分類的範例 JSONL 檔案:
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label": "cat"
}
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_02.jpeg",
"image_details":
{
"format": "jpeg",
"width": "3456px",
"height": "3467px"
},
"label": "dog"
}
下列程式碼是用於物件偵測的範例 JSONL 檔案:
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label":
{
"label": "cat",
"topX": "1",
"topY": "0",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "true",
}
}
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_02.png",
"image_details":
{
"format": "jpeg",
"width": "1230px",
"height": "2356px"
},
"label":
{
"label": "dog",
"topX": "0",
"topY": "1",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "false",
}
}
取用資料
一旦您的資料是 JSONL 格式,您就可以如下所示,建立定型和驗證 MLTable。
paths:
- file: ./train_annotations.jsonl
transformations:
- read_json_lines:
encoding: utf8
invalid_lines: error
include_path_column: false
- convert_column_types:
- columns: image_url
column_type: stream_info
自動化 ML 不會對電腦視覺工作的定型或驗證資料大小強加任何限制。 資料集大小上限僅受資料集背後的儲存層所限制 (範例:Blob 存放區)。 影像或標籤數量沒有下限。 不過,我們建議您從每個標籤最少 10-15 個樣本開始,以確保輸出模型足以進行定型。 標籤/類別總數愈高,每個標籤所需的範例越多。
定型資料是必要參數,而且使用 training_data 索引鍵傳入。 您可以選擇性地使用 validation_data 索引鍵,將另一個 MLtable 指定為驗證資料。 如果未指定驗證資料,除非您使用不同值傳遞 validation_data_size 引數,否則預設會使用 20% 的定型資料來進行驗證。
目標資料行名稱是必要參數,可做為受監督 ML 工作的目標。 其使用 target_column_name 索引鍵傳入。 例如,
target_column_name: label
training_data:
path: data/training-mltable-folder
type: mltable
validation_data:
path: data/validation-mltable-folder
type: mltable
計算要執行的實驗
提供自動化 ML 的計算目標來進行模型定型。 電腦視覺工作的自動化 ML 模型需要 GPU SKU 並支援 NC 和 ND 系列。 我們建議 NCsv3 系列 (含 v100 GPU),以進行更快的定型。 具有多重 GPU VM SKU 的計算目標會使用多個 GPU 來加速定型。 此外,當設定具有多個節點的計算目標時,您可以在調整模型的超參數時,透過平行處理原則進行更快的模型定型。
會使用 compute 參數傳入計算目標。 例如:
compute: azureml:gpu-cluster
設定實驗
針對電腦視覺工作,您可以啟動個別試用、手動掃掠或自動掃掠。 建議您從自動掃掠開始,以取得第一個基準模型。 然後,您可以使用特定模型和超參數設定來試用個別試用。 最後,透過手動掃掠,您可以在更大有可為的模型和超參數設定附近探索多個超參數值。 這三個步驟工作流程 (自動掃掠、個別試用、手動) 可避免搜尋整個超參數空間,超參數數目會以指數方式成長。
自動掃掠可產生許多資料集的競爭結果。 此外,它們不需要進階模型結構的知識,會考慮超參數相互關聯,而且可在不同的硬體設定之間順暢地運作。 這裡的所有原因都使其成為實驗程序初期的強式選項。
主要計量
AutoML 定型作業會針對模型最佳化和超參數調整使用主要計量。 主要計量取決於工作類型,如下所示;目前不支援其他主要計量值。
作業限制
您可如下面範例所述,在限制設定中指定作業的 timeout_minutes、max_trials 和 max_concurrent_trials,以控制在 AutoML 影像定型作業上花費的資源。
| 參數 | 詳細資料 |
|---|---|
max_trials |
要掃掠的試用數目上限的參數。 必須為介於 1 到 1000 之間的整數。 只探索給定模型結構的預設超參數時,請將此參數設定為 1。 預設值是 1。 |
max_concurrent_trials |
可同時執行的試用數目上限。 如果已指定,必須是介於 1 到 100 之間的整數。 預設值是 1。 注意: max_concurrent_trials 會限制在 max_trials。 例如,如果使用者設定 max_concurrent_trials=4、max_trials=2,則值會在內部更新為 max_concurrent_trials=2、max_trials=2。 |
timeout_minutes |
實驗終止前的時間量 (以分鐘為單位)。 如果未指定,則預設實驗逾時分鐘數為七天 (最長 60 天)。 |
limits:
timeout_minutes: 60
max_trials: 10
max_concurrent_trials: 2
自動掃掠模型超參數 (AutoMode)
重要
此功能目前處於公開預覽。 在此提供的這個預覽版本並無服務等級協定。 可能不支援特定功能,或可能已經限制功能。 如需詳細資訊,請參閱 Microsoft Azure 預覽版增補使用條款。
難以預測資料集的最佳模型結構和超參數。 此外,在某些情況下,配置給調整超參數的人力時間可能會受到限制。 針對電腦視覺工作,您可以指定任意數目的試用,系統會自動決定要掃掠的超參數空間區域。 您不需要定義超參數搜尋空間、取樣方法或早期終止原則。
正在觸發 AutoMode
您可以在 limits 中將 max_trials 設定為大於 1 的值,且不指定搜尋空間、取樣方法和終止原則,以執行自動掃掠。 我們將此功能稱為 AutoMode;請參閱以下範例。
limits:
max_trials: 10
max_concurrent_trials: 2
10 到 20 之間的試用數目在許多資料集上可能很適用。 仍然可以設定 AutoML 作業的時間預算,但建議只有在每個試用可能需要很長的時間時才執行此動作。
警告
目前不支援透過 UI 啟動自動掃掠。
個別試用
在個別試用中,您可以直接控制模型結構和超參數。 模型結構會透過 model_name 參數傳遞。
支援的模型結構
下表摘要說明每一個電腦視覺工作支援的舊版模型。 僅使用這些舊版模型,會使用舊版執行階段觸發執行 (其中每個個別執行或試用都會提交為命令作業)。 如需 HuggingFace 和 MMDetection 支援,請參閱下方。
| Task | 模型結構 | 字串常值語法 以 * 表示的 default_model* |
|---|---|---|
| 影像分類 (多類別和多標籤) |
MobileNet:行動應用程式的輕加權模型 ResNet:殘差網路 ResNeSt:分散注意力網路 SE-ResNeXt50:Squeeze-and-Excitation 網路 ViT:視覺轉換器網路 |
mobilenetv2 resnet18 resnet34 resnet50 resnet101 resnet152 resnest50 resnest101 seresnext vits16r224 (小型) vitb16r224* (基礎) vitl16r224 (大型) |
| 物件偵測 | YOLOv5:一個階段物件偵測模型 更快的 RCNN ResNet FPN:兩個階段物件偵測模型 RetinaNet ResNet FPN:失去焦點的位址類別不平衡 注意:如需 YOLOv5 模型大小,請參閱 model_size超參數。 |
yolov5* fasterrcnn_resnet18_fpn fasterrcnn_resnet34_fpn fasterrcnn_resnet50_fpn fasterrcnn_resnet101_fpn fasterrcnn_resnet152_fpn retinanet_resnet50_fpn |
| 執行個體分割 | MaskRCNN ResNet FPN | maskrcnn_resnet18_fpn maskrcnn_resnet34_fpn maskrcnn_resnet50_fpn* maskrcnn_resnet101_fpn maskrcnn_resnet152_fpn |
支援的模型結構 - HuggingFace 和 MMDetection (預覽)
透過在 Azure Machine Learning 管線上執行的新後端,您可以額外使用來自 HuggingFace 中樞的任何影像分類,該中樞是轉換器程式庫的一部分 (例如 microsoft/beit-base-patch16-224),以及使用來自 MMDetection 3.1.0 版模型園地 (例如 atss_r50_fpn_1x_coco) 的任何物件偵測或執行個體分割模型。
除了支援 HuggingFace Transfomers 和 MMDetection 3.1.0 的任何模型之外,我們也會在 azureml 登錄中提供來自這些程式庫的策劃模型清單。 這些策劃的模型已經過徹底測試,並使用從廣泛效能評定中選取的預設超參數,以確保有效定型。 下表摘要說明這些策劃的模型。
我們不斷更新策劃的模型清單。 您可以使用 Python SDK 取得指定工作策劃模型的最新清單:
credential = DefaultAzureCredential()
ml_client = MLClient(credential, registry_name="azureml")
models = ml_client.models.list()
classification_models = []
for model in models:
model = ml_client.models.get(model.name, label="latest")
if model.tags['task'] == 'image-classification': # choose an image task
classification_models.append(model.name)
classification_models
輸出:
['google-vit-base-patch16-224',
'microsoft-swinv2-base-patch4-window12-192-22k',
'facebook-deit-base-patch16-224',
'microsoft-beit-base-patch16-224-pt22k-ft22k']
若使用任何 HuggingFace 或 MMDetection 模型,將會使用管線元件來觸發執行。 如果同時使用舊版和 HuggingFace/MMdetection 模型,所有執行/試用版將會使用元件來觸發。
除了控制模型結構,您也可以調整用於模型定型的超參數。 雖然許多公開的超參數都與模型無關,但還是有一些執行個體,其中的超參數是工作特有的或模型特有的。 深入了解這些執行個體可用的超參數。
如果您想要針對指定的結構 (假設 yolov5) 使用預設超參數值,您可以在 training_parameters 區段中使用 model_name 索引鍵來加以指定。 例如,
training_parameters:
model_name: yolov5
手動掃掠模型超參數
定型電腦視覺模型時,模型效能主要取決於選取的超參數值。 通常,您可能會想要調整超參數以取得最佳效能。 針對電腦視覺工作,您可以掃掠超參數以找出模型的最佳設定。 這項功能會在 Azure Machine Learning 中套用超參數調整功能。 了解如何調整超參數。
search_space:
- model_name:
type: choice
values: [yolov5]
learning_rate:
type: uniform
min_value: 0.0001
max_value: 0.01
model_size:
type: choice
values: [small, medium]
- model_name:
type: choice
values: [fasterrcnn_resnet50_fpn]
learning_rate:
type: uniform
min_value: 0.0001
max_value: 0.001
optimizer:
type: choice
values: [sgd, adam, adamw]
min_size:
type: choice
values: [600, 800]
定義參數搜尋空間
您可以定義要在參數空間中掃掠的模型結構和超參數。 您可以指定單一模型結構或多個模型結構。
- 如需每個工作類型支援的模型結構清單,請參閱個別試用。
- 請參閱適用於電腦視覺工作的超參數超參數,以了解每一種電腦視覺工作類型。
- 請參閱離散和連續超參數支援的散發詳細資料。
用於掃掠的取樣方法
在掃掠超參數時,您必須指定取樣方法,以用於掃掠定義的參數空間。 目前,參數支援下列取樣方法搭配 sampling_algorithm 參數:
| 取樣類型 | AutoML 作業語法 |
|---|---|
| 隨機取樣 | random |
| 格線取樣 | grid |
| 貝氏取樣 | bayesian |
注意
目前只有隨機和網格取樣支援條件式超參數空間。
提前終止原則
您可以使用提前終止原則自動結束效果不佳的試用。 提早終止可改善計算效率,節省原本花費在較不具期望試用上的計算資源。 影像的自動化 ML 支援使用 early_termination 參數的下列提早終止原則。 如果未指定終止原則,則會執行所有試用,直到完成。
| 提前終止原則 | AutoML 作業語法 |
|---|---|
| Bandit 原則 | CLI 第 2 版:bandit SDK 第 2 版: BanditPolicy() |
| 中位數停止原則 | CLI 第 2 版:median_stopping SDK 第 2 版: MedianStoppingPolicy() |
| 截斷選取原則 | CLI 第 2 版:truncation_selection SDK 第 2 版: TruncationSelectionPolicy() |
深入了解如何為您的超參數掃掠設定提早終止原則。
注意
如需完整的掃掠設定範例,請參閱這個教學課程。
您可以如下列範例所示,設定所有掃掠相關參數。
sweep:
sampling_algorithm: random
early_termination:
type: bandit
evaluation_interval: 2
slack_factor: 0.2
delay_evaluation: 6
已修正設定
您可以如下列範例所示,傳遞未在參數空間掃掠期間變更的固定設定或參數。
training_parameters:
early_stopping: True
evaluation_frequency: 1
資料增強
一般來說,深度學習模型效能通常可以藉由更多資料來改善。 資料增強是一種實用的技巧,可擴大資料集的資料大小和變化性,有助於防止過度學習,並改善模型對未見資料的一般化能力。 自動 ML 會根據電腦視覺工作,在將輸入影像饋送至模型之前,先套用不同的資料增強技巧。 目前,沒有任何公開的超參數可控制資料增強。
| Task | 受影響的資料集 | 已套用資料增強技巧 |
|---|---|---|
| 影像分類 (多類別和多標籤) | 訓練 驗證和測試 |
隨機大小調整和裁切、水平翻轉、色彩抖動 (亮度、對比、飽和度和色調)、使用全通道 ImageNet 平均值和標準差的正規化 調整大小、置中裁切、正規化 |
| 物件偵測、執行個體分割 | 訓練 驗證和測試 |
隨機裁切周框方塊、展開、水平翻轉、正規化、調整大小 正規化、調整大小 |
| 使用 yolov5 的物件偵測 | 訓練 驗證和測試 |
馬賽克、隨機仿射 (旋轉、平移、縮放、剪切)、水平翻轉 上下黑邊調整大小 |
目前針對映像作業的自動化 ML,預設會套用上方定義的增強功能。 為了提供增強功能的控制權,影像的自動化 ML 會在兩個旗標下公開,以關閉特定增強功能。 目前,只有物件偵測和執行個體分割工作支援這些旗標。
- apply_mosaic_for_yolo:此旗標為 Yolo 模型專屬。 將其設定為 False 會關閉在定型時間套用的馬賽克資料增強。
- apply_automl_train_augmentations:將此旗標設定為 False 會關閉在定型時間針對物件偵測和執行個體分割模型套用的增強。 如需增強功能,請參閱上表中的詳細資料。
- 對於非 yolo 物件偵測模型和執行個體分割模型,此旗標只會關閉前三個增強。 例如:隨機裁切周框方塊、展開、水平翻轉。 不論此旗標為何,仍會套用正規化和調整大小增強。
- 若為 Yolo 模型,此旗標會關閉隨機仿射和水平翻轉增強。
這兩個旗標可透過 training_parameters 底下的 advanced_settings 支援,並可透過下列方式控制。
training_parameters:
advanced_settings: >
{"apply_mosaic_for_yolo": false}
training_parameters:
advanced_settings: >
{"apply_automl_train_augmentations": false}
請注意,這兩個旗標彼此獨立,也可以使用下列設定組合使用。
training_parameters:
advanced_settings: >
{"apply_automl_train_augmentations": false, "apply_mosaic_for_yolo": false}
在我們的實驗中,我們發現這些增強有助於模型更妥善地一般化。 因此,當這些增強關閉時,我們建議使用者將其與其他離線增強結合,以取得更好的結果。
累加式定型 (選用)
完成定型作業之後,您可以選擇載入已定型的模型檢查點來進一步將模型定型。 您可以使用相同的資料集或不同的資料集進行累加式定型。 如果您對模型感到滿意,您可以選擇停止定型並使用目前的模型。
透過作業識別碼傳遞檢查點
您可以傳遞您想要從中載入檢查點的作業識別碼。
training_parameters:
checkpoint_run_id : "target_checkpoint_run_id"
提交 AutoML 作業
若要提交 AutoML 作業,請使用 .yml 檔案的路徑、工作區名稱、資源群組和訂用帳戶識別碼來執行下列 CLI 第 2 版命令。
az ml job create --file ./hello-automl-job-basic.yml --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
輸出和評估計量
自動化 ML 定型執行會產生輸出模型檔案、評估計量、記錄與部署成品,例如評分檔案與環境檔案。 您可以從子執行的輸出以及記錄和計量索引標籤檢視這些檔案和計量。
提示
請檢查如何瀏覽至檢視作業結果區段中的作業結果。
如需每個作業所提供效能圖表與計量的定義和範例,請參閱評估自動化機器學習實驗結果。
註冊和部署模型
一旦作業完成,您就可以註冊從最佳試用 (產生最佳主要計量的設定) 建立的模型。 您可以在下載後,或使用對應的 jobid 指定 azureml 路徑,以註冊模型。 注意:當您想要變更如下所述的推斷設定時,您需要下載模型並變更 settings.json,然後使用更新的 model 資料夾來註冊。
獲得最佳試用
CLI example not available, please use Python SDK.
註冊模型
使用 azureml 路徑或本機下載的路徑來註冊模型。
az ml model create --name od-fridge-items-mlflow-model --version 1 --path azureml://jobs/$best_run/outputs/artifacts/outputs/mlflow-model/ --type mlflow_model --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
註冊要使用的模型之後,您可以使用受控線上端點 deploy-managed-online-endpoint 進行部署
設定線上端點
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineEndpoint.schema.json
name: od-fridge-items-endpoint
auth_mode: key
建立端點
使用稍早建立的 MLClient,我們現在會在工作區中建立端點。 此命令會啟動端點建立,並在端點建立繼續時傳回確認回應。
az ml online-endpoint create --file .\create_endpoint.yml --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
設定線上部署
部署是託管執行實際推斷模型所需的一組資源。 我們將使用 ManagedOnlineDeployment 類別為端點建立部署。 您可以針對您的部署叢集使用 GPU 或 CPU VM SKU。
name: od-fridge-items-mlflow-deploy
endpoint_name: od-fridge-items-endpoint
model: azureml:od-fridge-items-mlflow-model@latest
instance_type: Standard_DS3_v2
instance_count: 1
liveness_probe:
failure_threshold: 30
success_threshold: 1
timeout: 2
period: 10
initial_delay: 2000
readiness_probe:
failure_threshold: 10
success_threshold: 1
timeout: 10
period: 10
initial_delay: 2000
建立部署
使用稍早建立的 MLClient,我們現在會在工作區中建立部署。 此命令會啟動部署建立,並在部署建立繼續時傳回確認回應。
az ml online-deployment create --file .\create_deployment.yml --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
更新流量:
根據預設,目前部署設定為接收 0% 流量。 您可以設定目前部署應該接收的流量百分比。 具有一個端點的所有部署合計流量百分比不應超過 100%。
az ml online-endpoint update --name 'od-fridge-items-endpoint' --traffic 'od-fridge-items-mlflow-deploy=100' --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
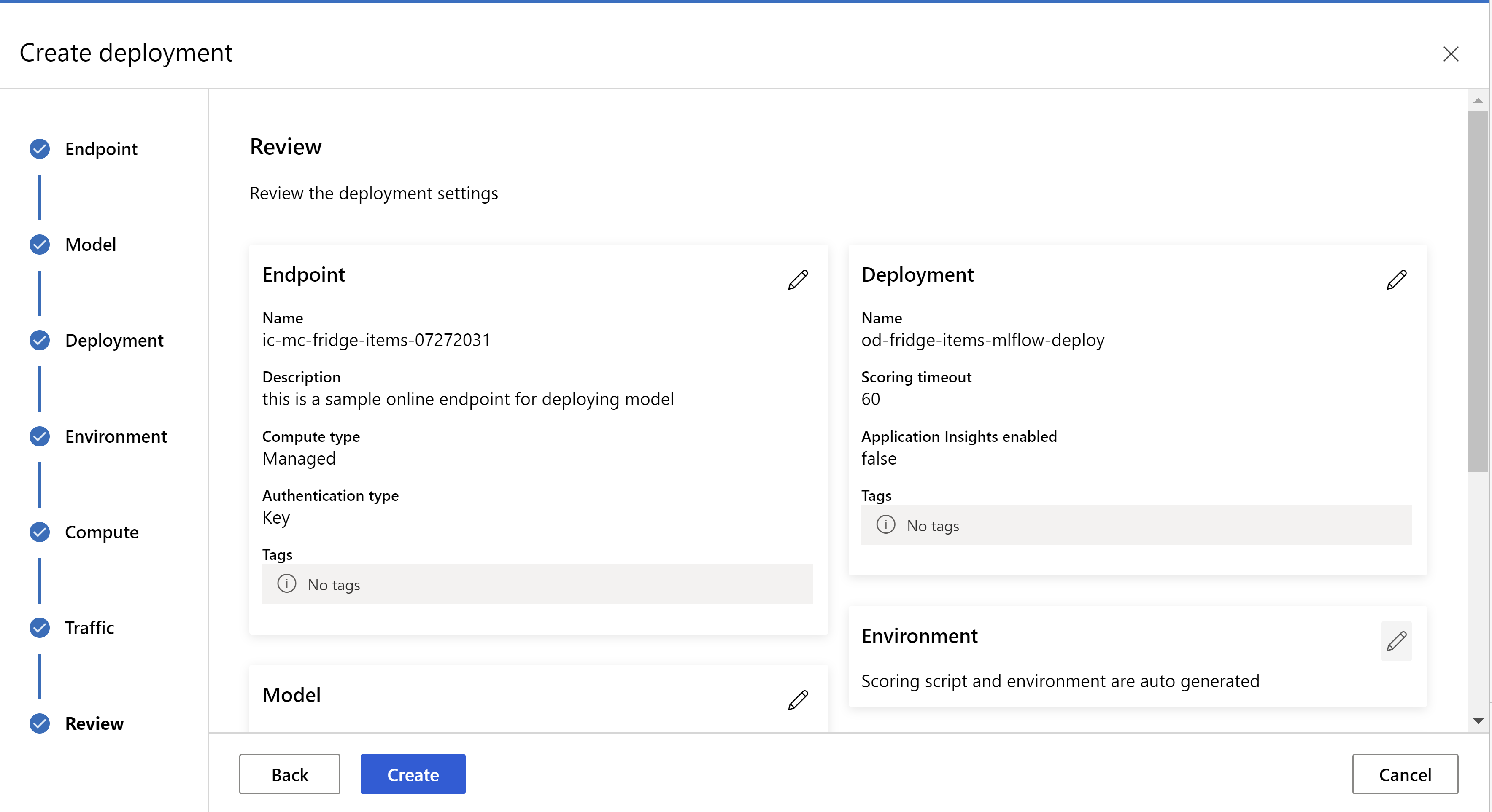
或者,您也可以從 Azure Machine Learning 工作室 UI 部署模型。 在自動化 ML 作業的 [模型] 索引標籤中瀏覽至您想要部署的模型,選取 [部署],然後選取 [部署至即時端點]。
![螢幕擷取畫面:選取 [部署] 選項後的 [部署] 頁面外觀。.](media/how-to-auto-train-image-models/deploy-end-point.png?view=azureml-api-2) .
.
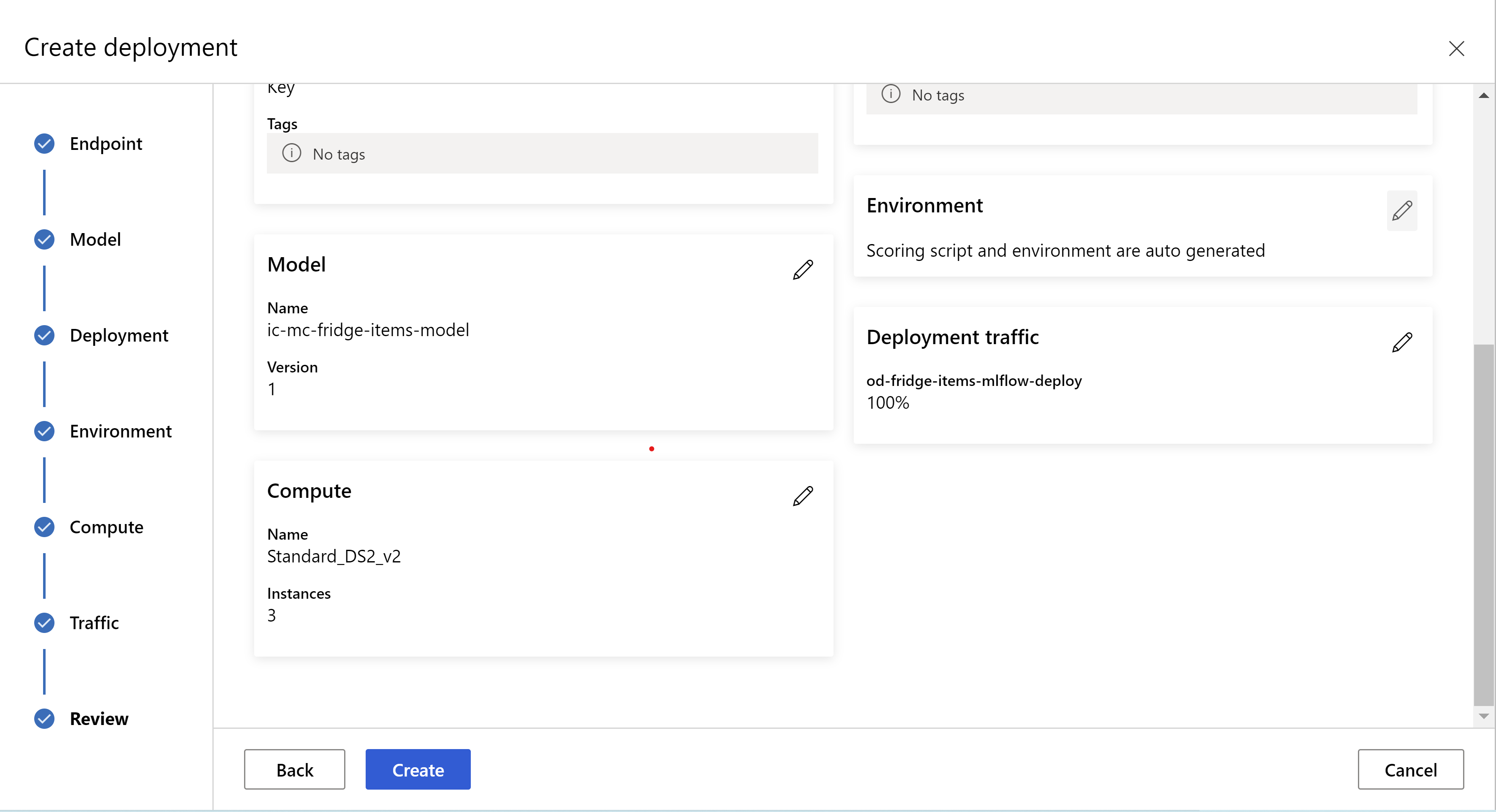
這是您的檢閱頁面外觀。 我們可以選取執行個體類型、執行個體計數,並設定目前部署的流量百分比。
 .
.
 .
.
更新推斷設定
在上一個步驟中,我們已從最佳模型下載檔案 mlflow-model/artifacts/settings.json。 在註冊模型之前,可用來更新推斷設定。 雖然建議使用與定型相同的參數,以獲得最佳效能。
每個工作 (和某些模型) 都有一組參數。 根據預設,我們會針對定型和驗證期間所使用的參數使用相同的值。 我們可以變更這些參數,取決於使用模型進行推斷時所需的行為。 您可以在下方找到每個工作類型和模型的參數清單。
| Task | 參數名稱 | 預設 |
|---|---|---|
| 影像分類 (多類別和多標籤) | valid_resize_sizevalid_crop_size |
256 224 |
| 物件偵測 | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_img |
600 1333 0.3 0.5 100 |
使用 yolov5 的物件偵測 |
img_sizemodel_sizebox_score_threshnms_iou_thresh |
640 medium 0.1 0.5 |
| 執行個體分割 | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_imgmask_pixel_score_thresholdmax_number_of_polygon_pointsexport_as_imageimage_type |
600 1333 0.3 0.5 100 0.5 100 False JPG |
如需工作專有超參數的詳細描述,請參閱自動化機器學習中電腦視覺工作的超參數。
如果您想要使用並排,並且想要控制並排行為,則可以使用下列參數:tile_grid_size、tile_overlap_ratio 和 tile_predictions_nms_thresh。 如需這些參數的詳細資訊,請參閱使用 AutoML 定型小型物件偵測模型。
測試部署
請檢查此測試部署區段以測試部署,並將模型的偵測視覺化。
產生預測的說明
重要
這些設定目前處於公開預覽狀態。 雖已提供,但沒有服務等級協定。 可能不支援特定功能,或可能已經限制功能。 如需詳細資訊,請參閱 Microsoft Azure 預覽版增補使用條款。
警告
模型可解釋性僅支援多類別分類和多標籤分類。
針對影像使用 Explainable AI (XAI) 與 AutoML 的一些優點:
- 改善複雜視覺模型預測中的透明度
- 協助使用者了解輸入影像中對模型預測有貢獻的重要功能/像素
- 協助針對模型進行疑難排解
- 協助探索偏差
解釋
說明是功能屬性或根據對模型預測的貢獻,指定給輸入影像中每個像素的權數。 每個權數可以是負數 (與預測負相關) 或正數 (與預測正相關)。 這些屬性是針對預測類別計算的。 針對多類別分類,每個樣本只會產生一個大小 [3, valid_crop_size, valid_crop_size] 的屬性矩陣,而針對多標籤分類,則會為每個樣本的每個預測標籤/類別產生大小 [3, valid_crop_size, valid_crop_size] 的屬性矩陣。
在已部署端點的 AutoML for Images 中使用 Explainable AI,使用者可以針對每個影像取得說明的視覺效果 (輸入影像上所覆蓋的屬性) 和/或屬性 (大小 [3, valid_crop_size, valid_crop_size] 的多維度陣列)。 除了視覺效果之外,使用者也可以取得屬性矩陣,以更充分掌控說明 (例如使用屬性產生自訂視覺效果,或仔細檢查屬性區段)。 所有說明演算法都會使用具有大小 valid_crop_size 的裁剪方形影像來產生屬性。
可以從線上端點或批次端點產生說明。 部署完成後,即可使用此端點來產生預測的說明。 在線上部署中,請務必將 request_settings = OnlineRequestSettings(request_timeout_ms=90000) 參數傳遞至 ManagedOnlineDeployment,並將 request_timeout_ms 設定為最大值,以避免在產生說明時發生逾時問題 (請參閱註冊和部署模型一節)。 某些可解釋性 (XAI) 方法,例如 xrai,會耗用更多時間 (特別是針對多標籤分類,因為我們需要為每個預測標籤產生屬性和/或視覺效果)。 因此,我們建議使用任何 GPU 執行個體,以取得更快速的說明。 如需產生說明的輸入和輸出結構描述詳細資訊,請參閱結構描述文件。
我們針對影像支援 AutoML 中的下列最先進可解釋性演算法:
- XRAI (xrai)
- 整合式漸層 (integrated_gradients)
- 引導式 GradCAM (guided_gradcam)
- 引導式 BackPropagation (guided_backprop)
下表描述 XRAI 和整合式漸層的可解釋性演算法特定調整參數。 引導式反向傳播和引導式 gradcam 不需要任何調整參數。
| XAI 演算法 | 演算法特有參數 | 預設值 |
|---|---|---|
xrai |
1. n_steps:逼近方法所使用的步驟數。 較大的步驟數會導致屬性 (說明) 的逼近。 n_steps 的範圍是 [2, inf),但屬性的效能在 50 個步驟之後開始收斂。 Optional, Int 2. xrai_fast:是否要使用更快的 XRAI 版本。 若為 True,說明的計算時間較快,但導致較不精確的說明 (屬性) Optional, Bool |
n_steps = 50 xrai_fast = True |
integrated_gradients |
1. n_steps:逼近方法所使用的步驟數。 較大的步驟數會導致屬性 (說明)。 n_steps 的範圍是 [2, inf),但屬性的效能在 50 個步驟之後開始收斂。Optional, Int 2. approximation_method:逼近整數的方法。 可用的逼近方法為 riemann_middle 與 gausslegendre。Optional, String |
n_steps = 50 approximation_method = riemann_middle |
在內部 XRAI 演算法會使用整合式漸層。 因此,整合式漸層和 XRAI 演算法都需要 n_steps 參數。 較大量的步驟會耗用更多時間來逼近說明,而且可能會導致線上端點發生逾時問題。
建議您使用 XRAI > 引導式 GradCAM > 整合式漸層 > 引導式 BackPropagation 演算法,以取得較佳的說明,而建議使用引導式 BackPropagation > 引導式 GradCAM > 整合式漸層 > XRAI 以更快速以指定順序取得說明。
線上端點的範例要求如下所示。 當 model_explainability 設定為 True 時,此要求會產生說明。 下列要求會使用更快速版本的 XRAI 演算法透過 50 個步驟,產生視覺效果和屬性。
import base64
import json
def read_image(image_path):
with open(image_path, "rb") as f:
return f.read()
sample_image = "./test_image.jpg"
# Define explainability (XAI) parameters
model_explainability = True
xai_parameters = {"xai_algorithm": "xrai",
"n_steps": 50,
"xrai_fast": True,
"visualizations": True,
"attributions": True}
# Create request json
request_json = {"input_data": {"columns": ["image"],
"data": [json.dumps({"image_base64": base64.encodebytes(read_image(sample_image)).decode("utf-8"),
"model_explainability": model_explainability,
"xai_parameters": xai_parameters})],
}
}
request_file_name = "sample_request_data.json"
with open(request_file_name, "w") as request_file:
json.dump(request_json, request_file)
resp = ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
deployment_name=deployment.name,
request_file=request_file_name,
)
predictions = json.loads(resp)
如需產生說明的詳細資訊,請參閱自動化機器學習範例的 GitHub 筆記本存放庫。
解譯視覺效果
如果 model_explainability 和 visualizations 都設定為 True,則部署的端點會傳回 base64 編碼的影像字串。 解碼 base64 字串,如筆記本中所述,或使用下列程式碼來解碼和視覺化預測中的 base64 影像字串。
import base64
from io import BytesIO
from PIL import Image
def base64_to_img(base64_img_str):
base64_img = base64_img_str.encode("utf-8")
decoded_img = base64.b64decode(base64_img)
return BytesIO(decoded_img).getvalue()
# For Multi-class classification:
# Decode and visualize base64 image string for explanations for first input image
# img_bytes = base64_to_img(predictions[0]["visualizations"])
# For Multi-label classification:
# Decode and visualize base64 image string for explanations for first input image against one of the classes
img_bytes = base64_to_img(predictions[0]["visualizations"][0])
image = Image.open(BytesIO(img_bytes))
下圖說明範例輸入影像的說明視覺效果。

解碼的 base64 圖在 2 x 2 方格內有四個影像區段。
- 左上角 (0, 0) 的影像是裁剪的輸入影像
- 右上角 (0, 1) 的影像是色階 bgyw (藍色綠色黃色白色) 上屬性的熱度圖,其中預測類別上白色像素的貢獻最高,而藍色像素最低。
- 左下角 (1, 0) 的影像是裁剪輸入影像上屬性的混合熱度圖
- 右下角 (1, 1) 的影像是裁剪的輸入影像,其前 30% 的像素是根據屬性分數。
解譯屬性
如果 model_explainability 和 attributions 都設定為 True,則部署的端點會傳回屬性。 如需詳細資訊,請參閱多類別分類和多標籤分類筆記本。
這些屬性可讓使用者更充分掌控產生自訂視覺效果,或仔細檢查像素層級屬性分數。 下列程式碼片段描述使用屬性矩陣產生自訂視覺效果的方法。 如需多類別分類和多標籤分類屬性結構描述的詳細資訊,請參閱結構描述文件。
使用所選取模型的確切 valid_resize_size 和 valid_crop_size 值來產生說明 (預設值分別為 256 和 224)。 下列程式碼會使用 Captum 視覺效果功能來產生自訂視覺效果。 使用者可以利用任何其他程式庫來產生視覺效果。 如需詳細資訊,請參閱 captum 視覺效果公用程式。
import colorcet as cc
import numpy as np
from captum.attr import visualization as viz
from PIL import Image
from torchvision import transforms
def get_common_valid_transforms(resize_to=256, crop_size=224):
return transforms.Compose([
transforms.Resize(resize_to),
transforms.CenterCrop(crop_size)
])
# Load the image
valid_resize_size = 256
valid_crop_size = 224
sample_image = "./test_image.jpg"
image = Image.open(sample_image)
# Perform common validation transforms to get the image used to generate attributions
common_transforms = get_common_valid_transforms(resize_to=valid_resize_size,
crop_size=valid_crop_size)
input_tensor = common_transforms(image)
# Convert output attributions to numpy array
# For Multi-class classification:
# Selecting attribution matrix for first input image
# attributions = np.array(predictions[0]["attributions"])
# For Multi-label classification:
# Selecting first attribution matrix against one of the classes for first input image
attributions = np.array(predictions[0]["attributions"][0])
# visualize results
viz.visualize_image_attr_multiple(np.transpose(attributions, (1, 2, 0)),
np.array(input_tensor),
["original_image", "blended_heat_map"],
["all", "absolute_value"],
show_colorbar=True,
cmap=cc.cm.bgyw,
titles=["original_image", "heatmap"],
fig_size=(12, 12))
大型資料集
如果您使用 AutoML 來定型大型資料集,有一些實驗性設定可能很實用。
重要
這些設定目前處於公開預覽狀態。 雖已提供,但沒有服務等級協定。 可能不支援特定功能,或可能已經限制功能。 如需詳細資訊,請參閱 Microsoft Azure 預覽版增補使用條款。
多 GPU 和多節點定型
根據預設,每個模型都會在單一 VM 上定型。 如果定型模型花費太多時間,使用包含多個 GPU 的 VM 可能有所幫助。 在大型資料集上定型模型所需的時間,應該會以大致線性比例減少到所使用的 GPU 數目。 (例如,模型在具有兩個 GPU 的 VM 上的定型速度應該大約是具有一個 GPU 的 VM 上的兩倍。)如果具有多個 GPU 的 VM 上定型模型的時間仍然很高,您可以增加用來定型每個模型的 VM 數目。 類似於多 GPU 定型,在大型資料集上定型模型所需的時間,也應該以大致線性比例減少到使用的 VM 數目。 在跨多個 VM 定型模型時,請務必使用支援 InfiniBand 的計算 SKU 來獲得最佳結果。 您可設定 AutoML 作業的 node_count_per_trial 屬性,藉此設定用來定型單一模型的 VM 數目。
properties:
node_count_per_trial: "2"
從儲存體串流處理影像檔
根據預設,所有影像檔案都會在模型定型之前下載到磁碟。 如果影像檔案的大小大於可用的磁碟空間,則作業會失敗。 您可以選取從 Azure 儲存體串流處理影像檔案 (因為定型期間需要),而不是將所有影像都下載到磁碟。 影像檔案會直接從 Azure 儲存體串流處理至系統記憶體,略過磁碟。 同時,磁碟上會快取儲存體中盡可能多的檔案,以將對儲存體的要求數目降到最低。
注意
若已啟用串流處理,請確定 Azure 儲存體帳戶位於與計算相同的區域中,以將成本和延遲降到最低。
training_parameters:
advanced_settings: >
{"stream_image_files": true}
Notebook 範例
在自動化機器學習範例的 GitHub 筆記本存放庫中,檢閱詳細的程式碼範例和使用案例。 請檢查具有 'automl-image-' 前置詞的資料夾,以取得建置電腦視覺模型的特定範例。
程式碼範例
在自動化機器學習樣本的 azureml-examples 存放庫中,檢閱詳細的程式碼範例和使用案例。