使用 AutoML 預測進行深度學習
本文著重於 AutoML 中用於時間序列預測的深度學習方法。 如需在 AutoML 中定型預測模型的指示和範例,請參閱我們的設定 AutoML 以進行時間序列預測一文。
深度學習在語言模型到蛋白質摺疊等眾多領域具有大量使用案例。 時間序列預測也受益於深度學習技術的最新進展。 例如,在備受矚目的 Makridakis 預測競賽第四次和第五次反覆運算中,深度神經網路 (DNN) 模型在一眾表現優異的模型中表現突出。
在本文中,我們會介紹 AutoML 中 TCNForecaster 模型的結構與作業,協助您掌握將模型套用至案例的最佳做法。
TCNForecaster 簡介
TCNForecaster 是一種時態性卷積網路或 TCN,具有為時間序列資料設計的 DNN 架構。 此模型會針對目標數量使用歷程記錄資料以及相關特徵,在指定的預測範圍內對目標進行機率預測。 下圖顯示 TCNForecaster 架構的主要元件:
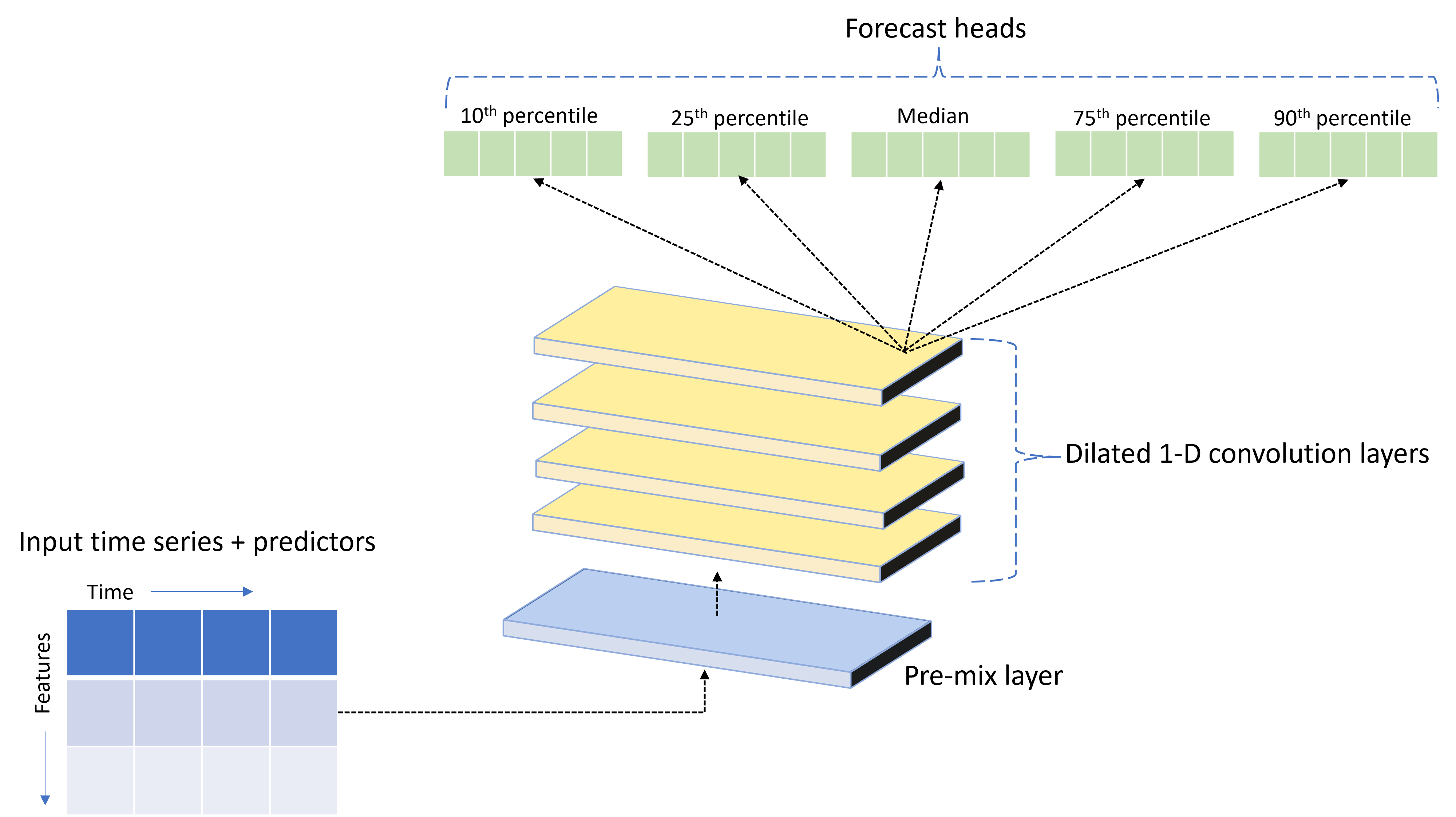
TCNForecaster 具有下列主要元件:
- 預先混合層,將輸入時間序列和特徵資料混合至卷積堆疊處理的訊號通道陣列中。
- 一個堆疊擴張卷積層,循序處理通道陣列;堆疊中的每一層都會處理上一層的輸出,以產生新的通道陣列。 此輸出中的每個通道都包含來自輸入通道的卷積篩選訊號混合。
- 預測前端單位的集合,這些單位會聯合來自卷積層的輸出訊號,並根據該潛在表示產生目標數量的預測。 每個前端單位都會針對預測分佈的分位數產生水平線預測。
擴張因果卷積
TCN 的核心作業是沿著輸入訊號時間維度進行擴張的因果卷積。 直觀上,卷積會將輸入中附近時間點的值混合在一起。 混合的比例是卷積的核心或權數,而混合中各點之間的區隔是擴張。 沿著輸入及時滑動核心並在每個位置累積混合,即可從輸入產生輸出訊號。 因果卷積的核心僅混合過去相對於每個輸出點的輸入值,從而防止輸出「查看」未來。
堆疊擴張卷積可讓 TCN 以相對較少的核心權數,針對輸入訊號中的長時間相互關聯建立模型。 例如,下圖顯示三個堆疊層,每層都具備雙權核心,以及呈指數遞增的擴張因數:
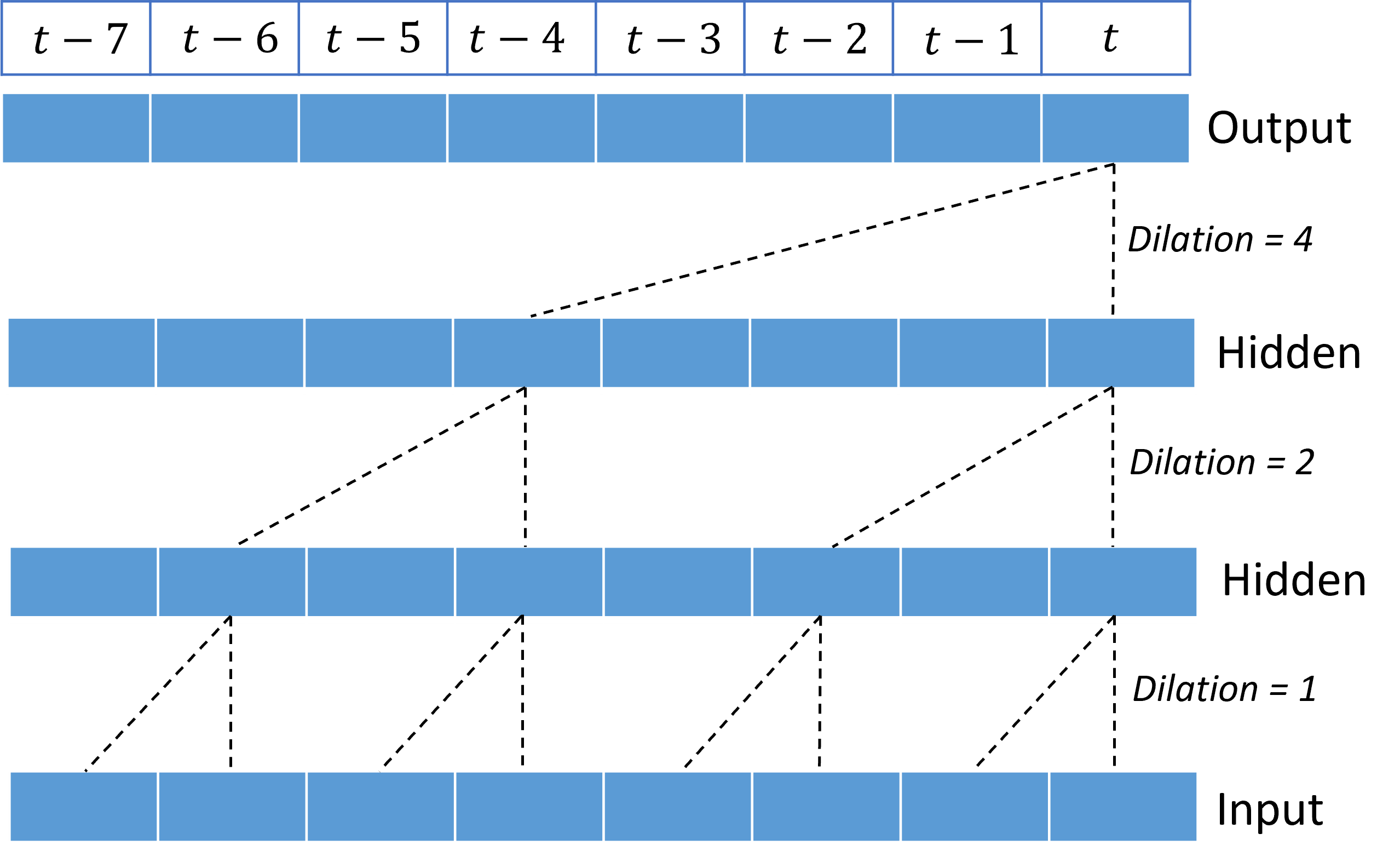
虛線會顯示結束於 $t$ 時間的輸出網路路徑。 這些路徑涵蓋輸入中的最後八個點,說明每個輸出點都是輸入中八個相對最近點的函數。 卷積網路用於預測的歷程記錄長度或「回顧」,稱為接受域,完全由 TCN 架構決定。
TCNForecaster 架構
TCNForecaster 架構的核心是預先混合和預測前端之間的卷積層堆疊。 堆疊在邏輯上分成稱為區塊的重複單位,而區塊又由剩餘資料格組成。 剩餘儲存格在設定的擴張下套用因果卷積,以及正規化和非線性活化。 重要的是,每個剩餘儲存格都會使用所謂的剩餘連線,將輸出新增至輸入。 這些連線已證實為有利於 DNN 訓練,也許是因為它們促進網路中更有效率的資訊流量。 下圖顯示範例網路的卷積層架構,該網路具有兩個區塊,每個區塊中有三個剩餘資料格:
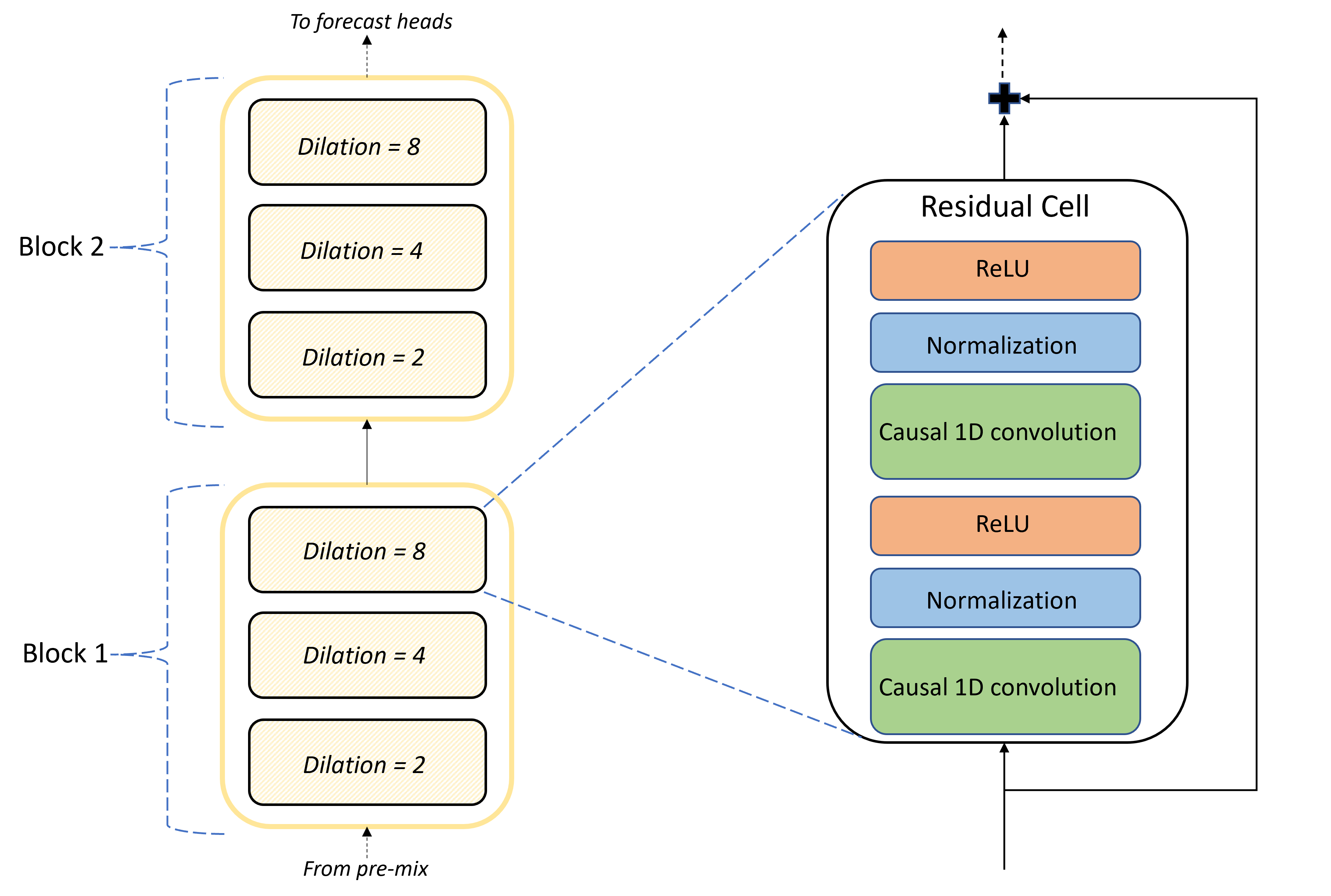
區塊和資料格的數目以及每層的訊號通道數目,控制著網路的大小。 TCNForecaster 的架構參數概要如下表所述:
| 參數 | 描述 |
|---|---|
| $n_{b}$ | 網路中的區塊數目,亦稱為深度 |
| $n_{c}$ | 每個區塊的資料格數目 |
| $n_{\text{ch}}$ | 隱藏層中的通道數目 |
接受域取決於深度參數,並由下列公式得出:
$t_{\text{rf}} = 4n_{b}\left(2^{n_{c}} - 1\right) + 1.$
我們可以運用公式更精確地定義 TCNForecaster 架構。 讓 $X$ 成為輸入陣列,其中每列都包含輸入資料中的特徵值。 我們可以將 $X$ 分割成數值和類別特徵陣列,$X_{\text{num}}$ 和 $X_{\text{cat}}$。 然後,TCNForecaster 可由下列公式得出:
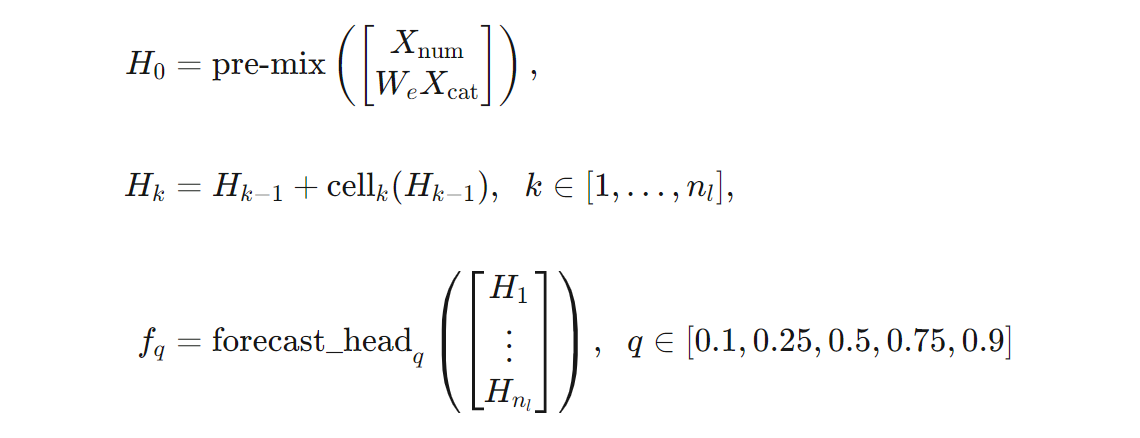
其中 $W_{e}$ 是類別特徵的內嵌矩陣,$n_{l} = n_{b}n_{c}$ 是剩餘資料格的總數,$H_{k}$ 表示隱藏層輸出,而 $f_{q}$ 是預測分佈給定分位數的預測輸出。 為了協助理解,這些變數的維度如下表所示:
| 變數 | 描述 | 維度 |
|---|---|---|
| $X$ | 輸入陣列 | $n_{\text{input}} \times t_{\text{rf}}$ |
| $H_{i}$ | $i=0,1,\ldots,n_{l}$ 的隱藏層輸出 | $n_{\text{ch}} \times t_{\text{rf}}$ |
| $f_{q}$ | 分位數 $q$ 的預測輸出 | $h$ |
在資料表中,$n_{\text{input}} = n_{\text{features}} + 1$,預測變數/特徵變數的數目加上目標數量。 預測前端會在單一階段產生最大範圍 $h$ 的所有預測,因此 TCNForecaster 是直接預測器。
AutoML 中的 TCNForecaster
TCNForecaster 是 AutoML 中的選擇性模型。 若要了解使用方式,請參閱啟用深度學習。
在本節中,我們會介紹 AutoML 如何使用您的資料組建 TCNForecaster 模型,包括資料前置處理、定型和模型搜尋的說明。
資料前置處理步驟
AutoML 會針對資料執行多個前置處理步驟,為模型定型做足準備。 下表按執行順序說明這些步驟:
| 步驟 | 描述 |
|---|---|
| 填補遺漏資料 | 插補遺漏值和觀察間距,並選擇性地填補或卸除短時間序列 |
| 建立行事曆功能 | 使用衍生自行事曆的功能增強輸入資料,例如星期幾以及特定國家/地區的假日 (可選)。 |
| 編碼類別資料 | 標籤編碼字串和其他類別類型;這包括所有時間序列 ID 資料行。 |
| 目標轉換 | 視特定統計測試結果而定,可以選擇將自然對數函數套用至目標。 |
| 正規化 | Z 分數將所有數值資料正規化;根據時間序列 ID 資料行所定義,依特徵和時間序列群組執行正規化。 |
這些步驟包含在 AutoML 的轉換管線中,因此會在推斷時間內自動套用 (如必要)。 在某些情況下,推斷管線中包含步驟的反向作業。 例如,如果 AutoML 在定型期間將 $\log$ 轉換套用至目標,則原始預測將在推斷管線中乘冪。
訓練
TCNForecaster 遵循 DNN 定型最佳做法,常見用於映像和語言領域的其他應用程式。 AutoML 將前置處理的定型資料分割成範例,並將這些範例隨機合併成批次。 網路會依序處理批次,使用反向傳播和隨機梯度下降,針對損失函數將網路權數最佳化。 定型可能需要多次經歷完整的定型資料;每個階段稱為 Epoch。
下表列出並描述 TCNForecaster 定型的輸入設定和參數:
| 定型輸入 | 描述 | 值 |
|---|---|---|
| 驗證資料 | 從定型中保留的部分資料,用於引導網路最佳化並減少過度學習。 | 由使用者提供或根據定型資料自動建立 (若未提供)。 |
| 主要計量 | 根據每個定型 Epoch 結束時驗證資料的中位數預測所計算的計量;用於早期停止和模型選擇。 | 由使用者選擇;將均方根誤差或平均絕對誤差正規化。 |
| 定型 Epoch | 針對網路權數最佳化執行的 Epoch 數目上限。 | 100;自動化早期停止邏輯可能會以較少的 Epoch 數目終止定型。 |
| 提早停止 patience | 停止定型之前,等待主要計量改善的 Epoch 數目。 | 20 |
| Loss 函式 | 網路權數最佳化的目標函數。 | 分位數損失平均超過第 10、25、50、75 和 90 個百分位數預測。 |
| 批次大小 | 批次中的範例數目。 每個範例的輸入維度為 $n_{\text{input}} \times t_{\text{rf}}$,輸出維度為 $h$。 | 根據定型資料中的範例總數自動決定;最大值為 1024。 |
| 內嵌維度 | 類別特徵的內嵌空間維度。 | 自動設定為每個特徵中相異值數目的第四個根,四捨五入至最接近的整數。 套用閾值的最小值為 3,最大值為 100。 |
| 網路架構 | 控制網路大小和形狀的參數:深度、資料格數目和通道數目。 | 由模型搜尋決定。 |
| 網路權數 | 控制訊號混合、類別內嵌、卷積核心權數,以及預測值對應的參數。 | 隨機初始化,然後針對損失函數最佳化。 |
| 學習速度* | 控制每個梯度下降反覆運算中可調整多少網路權數;動態縮減接近聚合。 | 由模型搜尋決定。 |
| 卸除比率* | 控制套用至網路權數的卸除正規化程度。 | 由模型搜尋決定。 |
以星號 (*) 標示的輸入由下一節所述的超參數搜尋決定。
模型搜尋
AutoML 使用模型搜尋方法來尋找下列超參數的值:
- 網路深度,或卷積區塊數目
- 每個區塊的資料格數目
- 每個隱藏層中的通道數目
- 網路正規化的卸除比率
- 學習速率。
這些參數的最佳值可能根據問題案例和定型資料而截然不同,因此 AutoML 會在超參數值的空間內定型數個不同模型,並根據驗證資料的主要計量分數挑選最佳模型。
模型搜尋分為兩個階段:
- AutoML 對 12 個「地標」模型執行搜尋。 地標模型是靜態的,並已選擇以合理跨越超參數空間。
- AutoML 使用隨機搜尋,繼續搜尋超參數空間。
符合停止準則時,搜尋便會終止。 停止準則取決於預測定型作業設定,但一些範例包括時間限制、要執行的搜尋試驗數目限制,以及驗證計量未改善時的早期停止邏輯。
下一步
- 了解如何設定 AutoML 定型時間序列預測模型。
- 了解 AutoML 中的預測方法。
- 瀏覽 AutoML 中預測的常見問題。