大規模預測:許多模型和分散式訓練
本文是關於針對大量歷程記錄資料的定型預測模型。 如需在 AutoML 中定型預測模型的指示和範例,請參閱我們的設定 AutoML 以進行時間序列預測一文。
時間序列資料可能很大,因為資料中的序列數目和/或歷史觀察的數目。 許多模型和階層式時間序列,或 HTS,都是針對先前案例調整解決方案,其中資料是由大量的時間序列所組成。 在這些情況下,模型精確度和延展性有助於將資料分割成群組,並在群組上平行定型大量的獨立模型。 相反地,在某些情況下,一個或少數高容量模型會更好。 分散式 DNN 定型以此案例為目標。 我們會在本文的其餘部分檢閱這些案例的概念。
許多模型
AutoML 中的許多模型元件可讓您平行定型及管理數百萬個模型。 例如,假設您有大量商店的歷史銷售資料。 您可以使用許多模型來啟動每個商店的平行 AutoML 定型作業,如下圖所示:

許多模型定型元件會將 AutoML 的模型掃掠和選取項目單獨套用至此範例中的每個商店。 此模型獨立性可協助延展性,且可受益模型精確度,尤其是在商店銷售動態差異時。 不過,當有常見的銷售動態時,單一模型方法可能會產生更精確的預測。 如需該案例的相關詳細資訊,請參閱分散式 DNN 定型一節。
您可以設定資料分割、模型的 AutoML 設定,以及許多模型定型作業的平行處理原則程度。 如需範例,請在許多模型元件參閱我們的指南一節。
階層式時間序列預測
商務應用程式中的時間序列通常會有形成階層的巢狀屬性。 例如,地理位置和產品目錄屬性通常為巢狀。 假設階層具有兩個地理屬性、狀態和商店識別碼,以及兩個產品屬性、類別和 SKU:

下圖提供此階層的相關說明:

重要的是,分葉 (SKU) 層級的銷售數量會加總到狀態和總銷售層級的彙總銷售數量。 階層式預測方法會在預測階層的任何層級銷售的數量時,保留這些彙總屬性。 此屬性在階層方面的預測一致。
AutoML 針對階層式時間序列 (HTS) 支援下列功能:
- 定型階層的任何層級。 在某些情況下,分葉層級資料可能有雜訊,但彙總可能更適用於預測。
- 擷取任何階層層級的點預測。 如果預測層級「低於」定型層級,則定型層級的預測會透過平均歷史比例或歷史平均值的比例進行分類。 當預測層級「高於」定型層級時,定型層級預測會根據彙總結構加總。
- 擷取定型層級或「低於」定型層級的分位數/概率預測。 目前的模型化功能支援概率預測的分類。
AutoML 中的 HTS 元件建置在許多模型之上,因此 HTS 會共用許多模型的可調整屬性。 如需範例,請在 HTS 元件參閱我們的指南一節。
分散式 DNN 訓練 (預覽)
重要
此功能目前處於公開預覽。 此預覽版本沒有服務等級協定,不建議用於處理生產工作負載。 可能不支援特定功能,或可能已經限制功能。
如需詳細資訊,請參閱 Microsoft Azure 預覽版增補使用條款。
具有大量歷史觀察和/或大量相關時間序列的資料案例,可能會受益於可調整的單一模型方法。 據此,AutoML 支援時態性卷積網路 (TCN) 模型的分散式定型和模型搜尋,這是時間序列資料的深度神經網路類型。 如需 AutoML TCN 模型類別的詳細資訊,請參閱我們的 DNN 文章。
分散式 DNN 定型使用採用時間序列界限的資料分割演算法來達到延展性。 下圖說明具有兩個分割區的簡單範例:
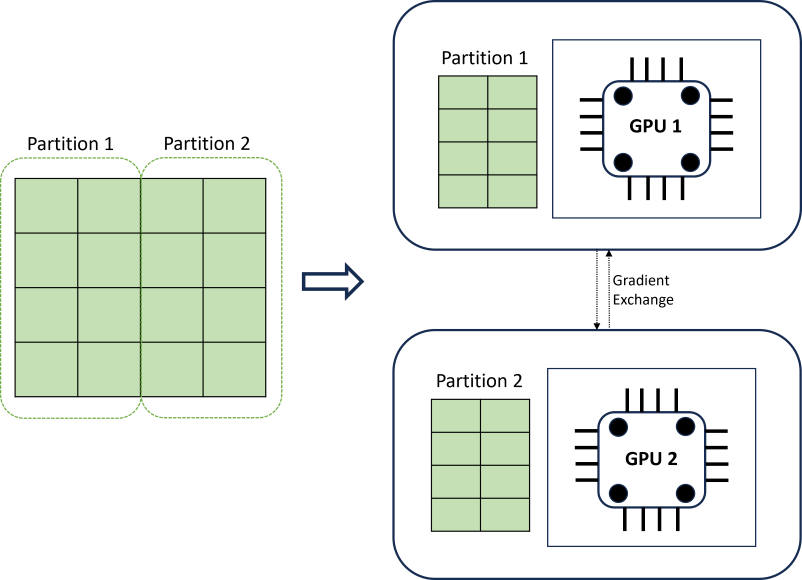
在定型期間,每個計算負載上的 DNN 資料載入器只需要完成反向傳播的反覆項目;一律不會將整個資料集讀入記憶體。 分割區會進一步分散到可能多個節點上的多個計算核心 (通常是 GPU),以加速定型。 跨計算的協調是由 Horovod 架構所提供。
下一步
- 深入了解如何設定 AutoML 定型時間序列預測模型。
- 了解 AutoML 如何使用機器學習來建置預測模型。
- 了解在 AutoML 中預測深度學習模型