處理文字
本文說明 Azure 機器學習 設計工具中的元件。
使用前置處理文字元件來清除和簡化文字。 它支援這些常見的文字處理作業:
- 拿掉停用字詞
- 使用正則表達式來搜尋並取代特定目標字串
- Lemmatization,可將多個相關單字轉換成單一標準形式
- 案例正規化
- 拿掉某些字元類別,例如數位、特殊字元,以及重複字元序列,例如 “aaaa”
- 識別和移除電子郵件和 URL
前置處理文字元件目前僅支援英文。
設定文字前置處理
將 [前置處理文字] 元件新增至 Azure 機器學習 中的管線。 您可以在 文字分析 下找到此元件。
連接包含文字至少一個數據行的數據集。
從 [ 語言] 下拉式清單中選取語言 。
要清除的文字數據行:選取您要前置處理的數據行。
拿掉停用字詞:如果您想要將預先定義的停用字詞清單套用至文字數據行,請選取此選項。
停用字詞清單與語言相關且可自定義。
Lemmatization:如果您想要以標準格式表示單字,請選取此選項。 這個選項有助於減少其他類似文字標記的唯一出現次數。
語境化程式與語言高度相關。。
偵測句子:如果您想要元件在執行分析時插入句子界限標記,請選取此選項。
此元件會使用三個管道字元
|||的數列來表示句子終止符。使用正則表達式執行選擇性的尋找和取代作業。 正則表達式會先處理,再處理所有其他內建選項。
- 自定義正則表示式:定義您要搜尋的文字。
- 自訂取代字串:定義單一取代值。
將大小寫正規化:如果您想要將 ASCII 大寫字元轉換成小寫表單,請選取此選項。
如果未正規化字元,則大寫和小寫字母中的同一個單字會被視為兩個不同的單字。
您也可以從已處理的輸出文字中移除下列型態的字元或字元序列:
拿掉數字:選取此選項可移除指定語言的所有數值字元。 標識碼是網域相依和語言相依。 如果數值字元是已知單字的整數部分,則可能不會移除數位。 如需詳細資訊,請參閱 技術注意事項。
拿掉特殊字元:使用此選項可移除任何非英數位元的特殊字元。
拿掉重複字元:選取此選項可移除重複兩次以上之任何序列中的額外字元。 例如,類似 「aaaaa」 的序列會縮減為 「aa」。
拿掉電子郵件地址:選取此選項可移除格式
<string>@<string>的任何序列。移除 URL:選擇此選項可移除包含下列 URL 前置詞的任何序列:
http、、https、ftpwww
展開動詞收縮:此選項僅適用於使用動詞收縮的語言;目前僅適用於英文。
例如,藉由選取此選項,您可以將「不會留在那裡」的片語取代為「不會留在那裡」。
將反斜杠正規化為斜線:選取此選項可將 的所有實體
\\對應至/。在特殊字元上分割標記:如果您想要中斷 、、 等字元
&-的文字,請選取此選項。 此選項也可以在重複兩次以上時減少特殊字元。例如,字串
MS---WORD會分成三個標記、MS、-和WORD。提交管線。
技術注意事項
Studio(傳統版) 和設計工具中的前置處理文字元件使用不同的語言模型。 設計工具會使用來自 spaCy 的多任務 CNN 定型模型。 不同的模型會提供不同的 Tokenizer 和部分語音標記器,這會導致不同的結果。
下列是一些範例:
| 組態 | 輸出結果 |
|---|---|
| 選取所有選項 說明: 針對 'WC-3 3 3test 4test' 中 '3test' 之類的案例,設計工具會移除整個字 '3test',因為在此內容中,部分語音標記器會將此標記 '3test' 指定為數位,而且根據語音部分,元件會移除它。 |
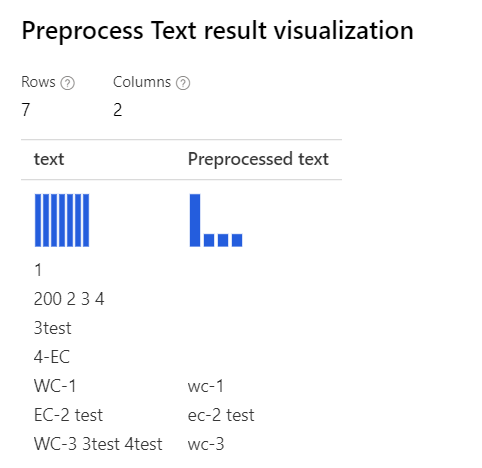
|
僅 Removing number 選取 [說明]: 針對 '3test'、'4-EC' 等案例,設計工具 Tokenizer 劑量不會分割這些案例,並將它們視為整個令牌。 因此,它不會移除這些字組的數位。 |
![只選取 [移除數位]](media/module/preprocess-text-removing-numbers-selected.png?view=azureml-api-2)
|
您也可以使用正規表示式來輸出自訂的結果:
| 組態 | 輸出結果 |
|---|---|
| 選取所有選項 的自訂正規表示式: (\s+)*(-|\d+)(\s+)* 自訂取代字串: \1 \2 \3 |

|
只有 Removing number 選取的 自訂正規表示式: (\s+)*(-|\d+)(\s+)* 自訂取代字串: \1 \2 \3 |
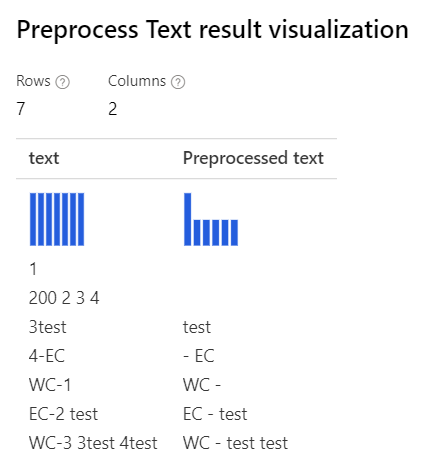
|