Azure Logic Apps 中工作流程的剖析或區塊內容 (預覽)
適用於:Azure Logic Apps (使用量 + 標準)
重要
此功能處於預覽狀態,且受限於 Microsoft Azure 預覽版的補充使用規定。
有時候,您必須將內容轉換成標記,也就是文字或字元區塊,或將大型檔分割成較小的片段,才能搭配某些動作使用此內容。 例如, Azure AI 搜尋 或 Azure OpenAI 動作需要令牌化輸入,而且只能處理有限的令牌數目。
針對這些案例,請在邏輯應用程式工作流程中使用名為剖析檔和區塊文字的數據作業動作。 這些動作會分別根據令牌數目,將內容,例如 PDF 檔、CSV 檔案、Excel 檔案等轉換成標記化的字串輸出,然後將字串分割成片段。 然後,您可以參考並使用這些輸出搭配工作流程中的後續動作。
提示
若要深入了解,您可以詢問 Azure Copilot 下列問題:
- 什麼是 AI 中的令牌?
- 什麼是標記化輸入?
- 什麼是標記化字串輸出?
- AI 中的剖析是什麼?
- AI 中的區塊化是什麼?
若要尋找 Azure Copilot,請在 Azure 入口網站工具列上,選取 [Copilot]。
本作指南示範如何在工作流程中新增和設定這些作業。
已知問題與限制
剖析檔和區塊文字動作目前不支援主機檔案,例如大型主機和中型二進位檔,例如虛擬記憶體存取方法 (VSAM) 檔案。 不過,如果您使用標準工作流程,您可以改用名為 Parse Host File Contents 的 IBM 主機檔案內建動作。
必要條件
Azure 帳戶和訂用帳戶。 如果您沒有 Azure 訂用帳戶,請先註冊免費的 Azure 帳戶。
具有現有觸發程式的取用或標準邏輯應用程式工作流程,因為剖析檔和區塊文字作業只能當做動作使用。 請確定擷取您想要剖析的內容或區塊的動作在這些數據作業之前。
剖析檔
剖 析檔 動作會將 PDF 檔、CSV 檔案、Excel 檔案等內容轉換成標記化字串。 在此範例中,假設您的工作流程從收到 HTTP 要求時名為 的要求觸發程序開始。 此觸發程式會等候接收從另一個元件傳送的 HTTP 要求,例如 Azure 函式、另一個邏輯應用程式工作流程等等。 HTTP 要求包含可供工作流程擷取和剖析之新上傳檔的 URL。 HTTP 動作會緊接在觸發程序之後,並將 HTTP 要求傳送至檔的 URL,並從其儲存位置傳回文件內容。
如果您使用其他內容來源,例如 Azure Blob 儲存體、SharePoint、OneDrive、文件系統、FTP 等,您可以檢查這些來源是否可使用觸發程式。 您也可以檢查動作是否可供擷取這些來源的內容。 如需詳細資訊,請參閱 內建作業 和 Managed 連接器。
在 Azure 入口網站中,於設計工具內開啟您的邏輯應用程式資源和工作流程。
在現有的觸發程式和動作下,遵循這些一般步驟,將名為剖析文件的數據作業動作新增至您的工作流程。
在設計工具上,選取 [ 剖析檔 ] 動作。
動作資訊窗格開啟之後,在 [參數 ] 索引標籤的 [文件內容 ] 屬性中,依照下列步驟指定要剖析的內容:
選取 [ 文件內容] 方塊內。
動態內容清單 (閃電圖示) 和表示式編輯器 (函式圖示) 的選項隨即出現。
若要從上述動作選擇輸出,請選取動態內容清單。
若要建立作上述動作輸出的表達式,請選取表達式編輯器。
此範例會繼續選取動態內容清單的閃電圖示。
動態內容清單開啟之後,請從先前的作業中選取您想要的輸出。
在此範例中,剖析檔動作會參考 HTTP 動作的 Body 輸出。
![此螢幕快照顯示工作流程設計工具,其動作名為剖析已開啟動態內容清單的檔,以及從 HTTP 動作選取的 [本文輸出]。](media/parse-document-chunk-text/select-http-body.png)
本文輸出現在會出現在 [文件內容] 方塊中:
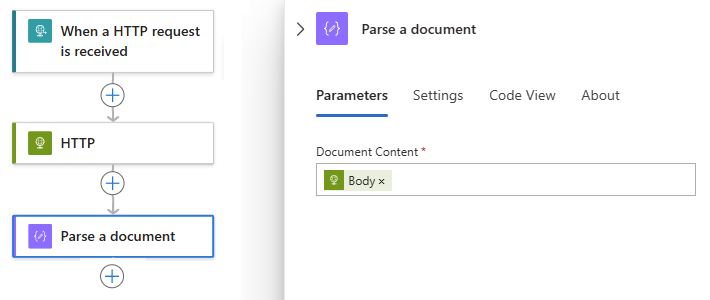
在剖 析檔 動作底下,新增您想要使用標記化字串輸出的動作,例如 ,本指南稍後將說明的區塊文字。
剖析檔案 - 參考
參數
| 名稱 | 值 | 資料類型 | 描述 | 限制 |
|---|---|---|---|---|
| 檔內容 | < content-to-parse> | 任意 | 要剖析的內容。 | 無 |
輸出
| 名稱 | 資料類型 | 描述 |
|---|---|---|
| 剖析的結果文字 | 字串陣列 | 字串的陣列。 |
| 剖析的結果 | Object | 物件,包含整個剖析的文字。 |
區塊文字
區塊文字動作會將內容分割成較小的片段,以供後續動作更輕鬆地在目前的工作流程中使用。 下列步驟以剖析檔區段的範例為基礎,並分割令牌字串輸出,以搭配預期令牌化、小型內容區塊的 Azure AI 作業使用。
注意
使用區塊處理的先前動作不會影響區塊文字動作,區塊文字動作也不會影響使用區塊處理的後續動作。
在 Azure 入口網站中,於設計工具內開啟您的邏輯應用程式資源和工作流程。
在剖析檔動作底下,遵循這些一般步驟來新增名為區塊文字的數據作業動作。
在設計工具上,選取 [ 區塊文字 ] 動作。
動作資訊窗格開啟之後,在 [參數] 索引卷標的 [區塊化策略] 屬性上,如果尚未選取,請選取 [TokenSize] 作為區塊化方法。
策略 描述 TokenSize 根據令牌數目分割指定的內容。 選取策略之後,請在 [文字框] 內選取 ,以指定區塊化的內容。
動態內容清單 (閃電圖示) 和表示式編輯器 (函式圖示) 的選項隨即出現。
若要從上述動作選擇輸出,請選取動態內容清單。
若要建立作上述動作輸出的表達式,請選取表達式編輯器。
此範例會繼續選取動態內容清單的閃電圖示。
動態內容清單開啟之後,請從先前的作業中選取您想要的輸出。
在此範例中,區塊文字動作會參考剖析檔動作中剖析的結果文字輸出。
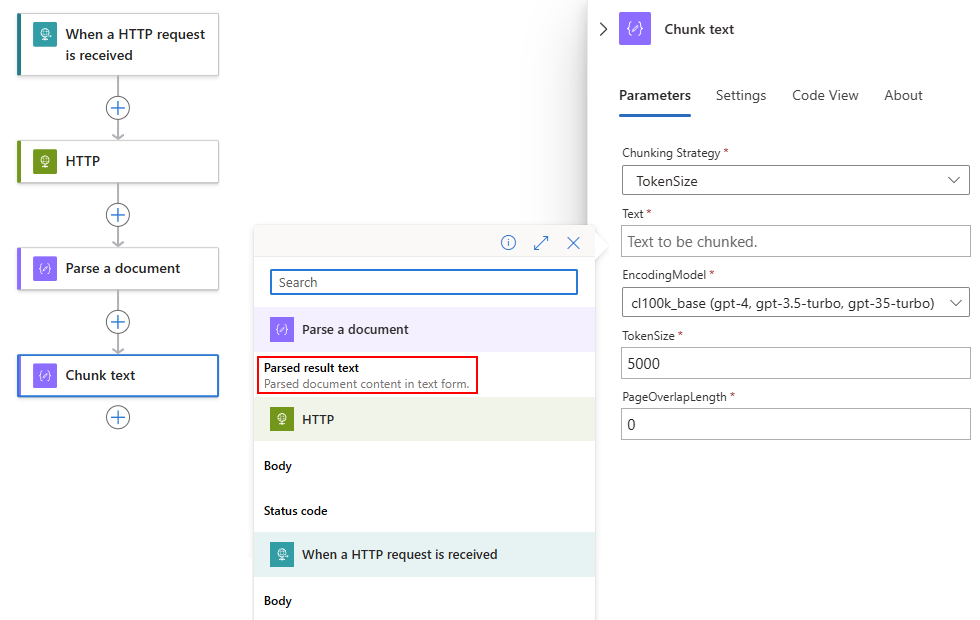
文字框現在會顯示剖析的結果動作輸出:
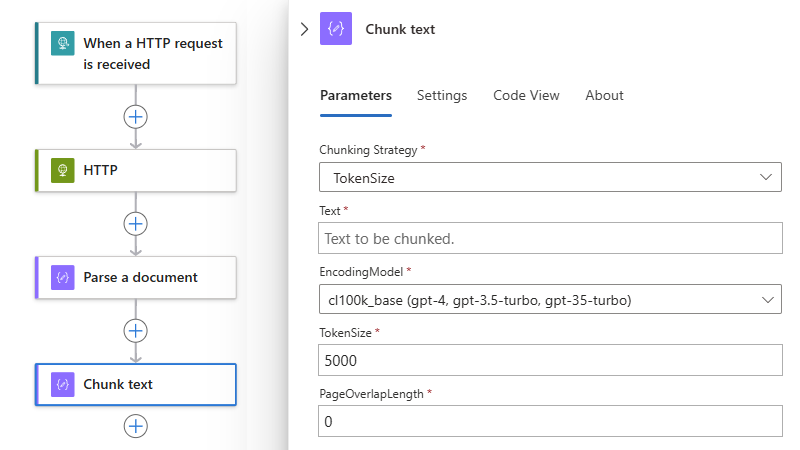
根據您選取的策略和案例,完成區塊文字動作的設定。 如需詳細資訊,請參閱 區塊文字 - 參考。
現在,當您新增預期並使用令牌化輸入的其他動作時,例如 Azure AI 動作,輸入內容會格式化以方便取用。
區塊文字 - 參考
參數
| 名稱 | 值 | 資料類型 | 描述 | 限制 |
|---|---|---|---|---|
| 區塊化策略 | TokenSize | 字串列舉 | 根據令牌數目分割內容。 默認值: TokenSize |
不適用 |
| Text | < content-to-chunk> | 任意 | 要區塊的內容。 | 請參閱 限制和設定參考指南 |
| EncodingModel | < encoding-method> | 字串列舉 | 要使用的編碼模型: - 預設值: cl100k_base (gpt4, gpt-3.5-turbo, gpt-35-turbo) - r50k_base (gpt-3) - p50k_base (gpt-3) - p50k_edit (gpt-3) - cl200k_base (gpt-4o) 如需詳細資訊,請參閱 OpenAI - 模型概觀。 |
不適用 |
| TokenSize | < max-tokens-per-chunk> | 整數 | 每個內容區塊的令牌數目上限。 預設值:None |
最小值: 1 最大值: 8000 |
| PageOverlapLength | < 重疊字元數> | 整數 | 上一個區塊結尾要包含在下一個區塊中的字元數。 此設定可協助您避免在將內容分割成區塊時遺失重要資訊,並保留跨區塊的持續性和內容。 預設值: 0 - 沒有重迭字元存在。 |
最小值: 0 |
提示
若要深入了解,您可以詢問 Azure Copilot 下列問題:
- 什麼是 PageOverlapLength 在區塊化?
- 什麼是 Azure AI 中的編碼方式?
若要尋找 Azure Copilot,請在 Azure 入口網站工具列上,選取 [Copilot]。
輸出
| 名稱 | 資料類型 | 描述 |
|---|---|---|
| 區塊化結果文字專案 | 字串陣列 | 字串的陣列。 |
| 區塊化結果文字項目專案 | String | 陣列中的單一字串。 |
| 區塊化結果 | Object | 物件,包含整個區塊化文字。 |
範例工作流程
下列範例包含其他動作,這些動作會建立完整的工作流程模式,以從任何來源內嵌數據:
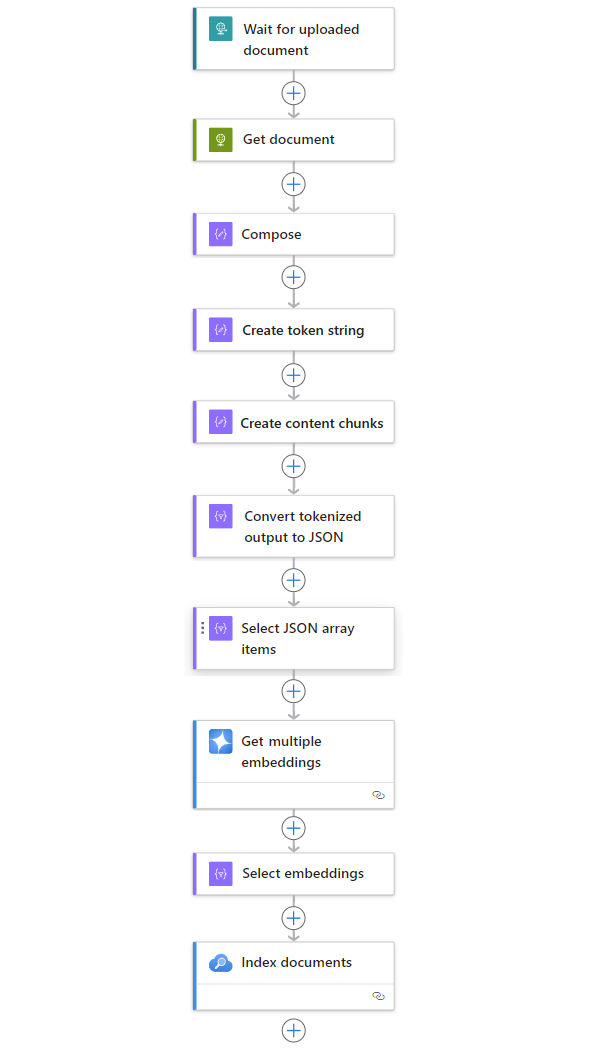
| 步驟 | Task | 基礎作業 | 描述 |
|---|---|---|---|
| 1 | 等候或檢查新內容。 | 收到 HTTP 要求時 | 觸發程式,會根據排程的週期或分別回應特定事件,輪詢或等候新數據送達。 這類事件可能是上傳至特定儲存系統的新檔案,例如 Azure Blob 儲存體、SharePoint、OneDrive、文件系統、FTP 等等。 在此範例中 ,要求 觸發程式作業會等候從另一個端點傳送的 HTTP 或 HTTPS 要求。 要求包含新上傳檔的 URL。 |
| 2 | 取得內容。 | HTTP | 使用觸發程序輸出中的檔案 URL 擷取上傳檔的 HTTP 動作。 |
| 3 | 撰寫檔詳細數據。 | 組成 |
串連各種項目的數據作業動作。 本範例會串連文件的相關索引鍵/值資訊。 |
| 4 | 建立令牌字串。 | 剖析檔 | 使用 Compose 動作的輸出產生標記化字串的數據作業動作。 |
| 5 | 建立內容區塊。 | 區塊文字 | 數據作業動作,根據每個內容區塊的令牌數目,將令牌字串分割成片段。 |
| 6 | 將標記化和區塊化文字轉換成 JSON。 | 剖析 JSON | 將資料作業動作,將區塊化輸出轉換成 JSON 陣列。 |
| 7 | 選取 [JSON 陣列專案]。 | 選取 | 從 JSON 陣組選取多個項目的數據作業 動作。 |
| 8 | 產生內嵌。 | 取得多個內嵌 | 針對 每個 JSON 陣列專案建立內嵌的 Azure OpenAI 動作。 |
| 9 | 選取內嵌和其他資訊。 | 選取 | 選取 內嵌和其他文件信息的數據作業 動作。 |
| 10 | 為數據編製索引。 | 索引檔 | Azure AI 搜尋 動作,會根據每個選取的內嵌編製數據索引。 |