在 Azure HDInsight 上搭配使用 Apache Zeppelin Notebook 和 Apache Spark 叢集
HDInsight Spark 叢集包含 Apache Zeppelin 筆記本。 使用筆記本來執行 Apache Spark 作業。 在本文中,您將學習如何在 HDInsight 叢集上使用 Zeppelin Notebook。
必要條件
- HDInsight 上的 Apache Spark 叢集。 如需指示,請參閱在 Azure HDInsight 中建立 Apache Spark 叢集。
- 您叢集主要儲存體的 URI 結構描述。 此配置在 Azure Blob 儲存體中為
wasb://,在 Azure Data Lake Storage Gen2 中為abfs://,而在 Azure Data Lake Storage Gen1 中為adl://。 如果已對 Blob 儲存體啟用安全傳輸,URI 會是wasbs://。 如需詳細資訊,請參閱在 Azure 儲存體中需要安全傳輸。
啟動 Apache Zeppelin Notebook
在 Spark 叢集 [概觀] 中,從 [叢集儀表板] 中選取 [Zeppelin 筆記本]。 輸入叢集的管理員認證。
注意
您也可以在瀏覽器中開啟下列 URL,來連接到您叢集的 Zeppelin Notebook。 使用您叢集的名稱取代 CLUSTERNAME :
https://CLUSTERNAME.azurehdinsight.net/zeppelin建立新的 Notebook。 從標題窗格中,瀏覽至 [筆記本]>[建立新記事]。
輸入筆記本的名稱,然後選取 [建立記事]。
請確定筆記本標題顯示的是已連線狀態。 右上角的綠點即表示此狀態。
將範例資料載入暫存資料表。 當您在 HDInsight 中建立 Spark 叢集時,範例資料檔案
hvac.csv會複製到相關聯的儲存體帳戶的\HdiSamples\SensorSampleData\hvac下。將以下程式碼片段貼入新 Notebook 中預設建立的空白段落。
%livy2.spark //The above magic instructs Zeppelin to use the Livy Scala interpreter // Create an RDD using the default Spark context, sc val hvacText = sc.textFile("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") // Define a schema case class Hvac(date: String, time: String, targettemp: Integer, actualtemp: Integer, buildingID: String) // Map the values in the .csv file to the schema val hvac = hvacText.map(s => s.split(",")).filter(s => s(0) != "Date").map( s => Hvac(s(0), s(1), s(2).toInt, s(3).toInt, s(6) ) ).toDF() // Register as a temporary table called "hvac" hvac.registerTempTable("hvac")按下 SHIFT + ENTER,或選取 [執行] 按鈕讓段落執行程式碼片段。 段落右上角的狀態應該會從「準備就緒」逐一轉變成「擱置」、「執行中」及「已完成」。 輸出會顯示在同一個段落的底部。 螢幕擷取畫面如下圖所示:
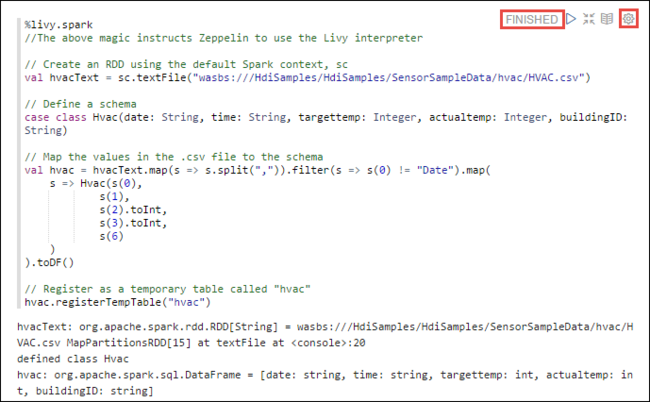
您也可以為每個段落提供標題。 從段落的右側,選取設定圖示 (鏈輪),然後選取 [顯示標題]。
注意
所有 HDInsight 版本的 Zeppelin 筆記本不支援 %spark2 解釋器,而且 HDInsight 4.0 以後不支援 %sh 解釋器。
現在,您可以對
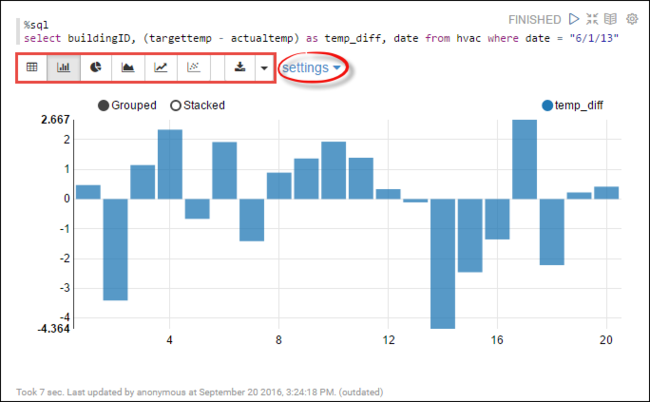
hvac資料表執行 Spark SQL 陳述式。 將以下查詢貼入新段落。 此查詢會擷取建築物識別碼。 還有在某一天每棟建築物的目標溫度與實際溫度之間的差異。 按下 SHIFT + ENTER。%sql select buildingID, (targettemp - actualtemp) as temp_diff, date from hvac where date = "6/1/13"開頭的 %Sql 陳述式會告訴 Notebook 使用 Livy Scala 解譯器。
選取長條圖圖示以變更顯示。 設定 會出現在您選取 的條形圖之後,可讓您選擇 [索引鍵] 和 [值]。 以下螢幕擷取畫面顯示輸出。
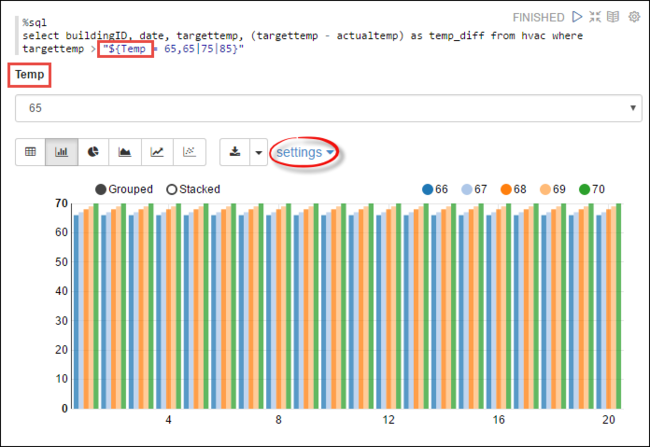
您也可以在查詢中使用變數來執行 Spark SQL 陳述式。 下一個程式碼片段示範如何在查詢中以您要查詢的可能值來定義
Temp變數。 當您第一次執行查詢時,下拉式清單會自動填入您指定的變數值。%sql select buildingID, date, targettemp, (targettemp - actualtemp) as temp_diff from hvac where targettemp > "${Temp = 65,65|75|85}"將此程式碼片段貼到新的段落中,然後按下 SHIFT + ENTER。 然後從 [Temp] 下拉式清單中選取 [65]。
選取長條圖圖示以變更顯示。 然後選取 [設定],並進行下列變更:
群組:新增 targettemp。
值:1。 移除 date。 2. 新增 temp_diff。 3. 將彙總工具從 SUM 變更為 AVG。
以下螢幕擷取畫面顯示輸出。
如何搭配 Notebook 使用外部套件?
在 HDInsight 上的 Apache Spark 叢集,Zeppelin 筆記本可以使用社群貢獻的外部套件 (不在叢集內)。 請在 Maven 存放庫中搜尋可用套件的完整清單。 您也可以從其他來源取得可用套件清單。 例如,從 Spark 套件可以取得社群提供套件的完整清單。
在本文中,您將瞭解如何搭配 Jupyter Notebook 使用 spark-csv 套件。
開啟解譯器設定。 從右上角選取已登入的使用者名稱,然後選取 [解譯器]。
捲動至 [livy2],然後選取 [編輯]。
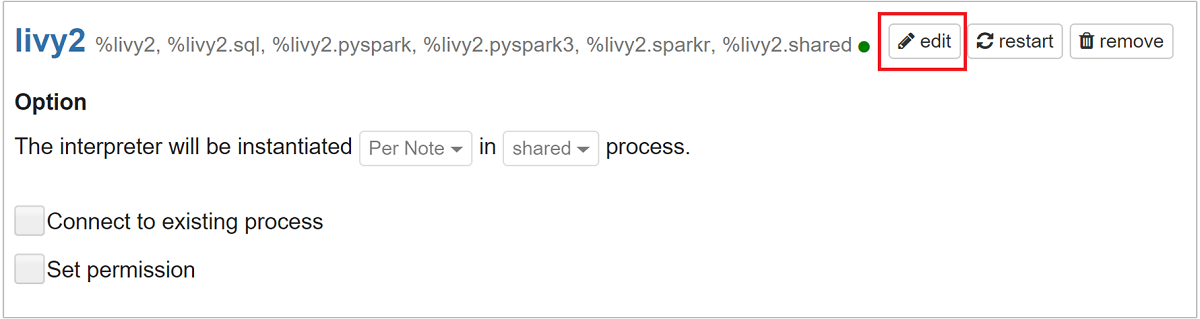
瀏覽至索引鍵
livy.spark.jars.packages,並以格式group:id:version來設定值。 因此,如果您想要使用 spark-csv 套件,您必須將金鑰值設為com.databricks:spark-csv_2.10:1.4.0。
選取 [儲存],然後選取 [確定],以重新啟動 Livy 解譯器。
如果您想要瞭解如何到達輸入的索引鍵值,以下是做法。
a. 在「Maven 儲存機制」中找出套件。 在本文中,我們使用 spark-csv。
b. 從儲存機制收集 [GroupId]、[ArtifactId] 及 [版本] 的值。
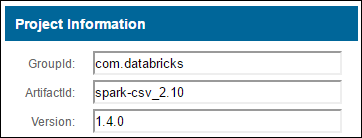
c. 串連三個值,其中以冒號分隔 (:)。
com.databricks:spark-csv_2.10:1.4.0
Zeppelin Notebook 儲存在哪裡?
儲存至叢集前端節點的 Zeppelin 筆記本。 因此,如果您刪除叢集,Notebook 會一併刪除。 如果您想要保留筆記本以供稍後在其他叢集上使用,您必須在完成執行作業之後加以匯出。 若要匯出筆記本,請選取 [導出 ] 圖示,如下圖所示。
此動作會將筆記本儲存為 JSON 檔案放在您的下載位置中。
注意
在 HDI 4.0 中,zeppelin Notebook 目錄路徑為
/usr/hdp/<version>/zeppelin/notebook/<notebook_session_id>/例如: /usr/hdp/4.1.17.10/zeppelin/2JMC9BZ8X/
而在 HDI 5.0 中,此路徑不同
/usr/hdp/<version>/zeppelin/notebook/<Kernel_name>/例如: /usr/hdp/5.1.4.5/zeppelin/notebook/Scala/
儲存在 HDI 5.0 中的檔案名稱不同。 儲存為
<notebook_name>_<sessionid>.zpln例如: testzeppelin_2JJK53XQA.zpln
在 HDI 4.0 中,檔案名稱只是儲存在 session_id 目錄下的 note.json。
例如: /2JMC9BZ8X/note.json
HDI Zeppelin 一律會將筆記本儲存在 hn0 本機磁碟的路徑
/usr/hdp/<version>/zeppelin/notebook/中。如果您希望筆記本即使在叢集刪除之後仍可供使用,您可以嘗試使用 Azure 檔案記憶體(使用 SMB 通訊協定),並將它連結至本機路徑。 如需詳細資訊,請參閱 在Linux上掛接SMB Azure檔案共用
掛接之後,您可以將 zeppelin 設定 zeppelin.notebook.dir 修改為 Ambari UI 中掛接的路徑。
- zeppelin 0.10.1 版不建議使用 SMB 檔案共享作為 GitNotebookRepo 記憶體
在企業安全性套件 (ESP) 叢集上使用 Shiro 來設定對 Zeppelin 解譯器的存取權
如上所述,自 HDInsight 4.0 起不支援 %sh 解譯器。 此外,由於 %sh 解譯器引起潛在的安全性問題,例如使用殼層命令存取金鑰表,因此也已從 HDInsight 3.6 ESP 叢集移除。 這表示按一下 [建立新記事] 時,或在解譯器 UI 中,預設無法使用解譯器 %sh。
特殊權限網域使用者可以使用 Shiro.ini 檔案來控制對解譯器 UI 的存取權。 只有這些使用者可以建立新的 %sh 解譯器,並在每個新的 %sh 解譯器上設定權限。 若要使用 shiro.ini 檔案來控制存取權,請使用下列步驟:
使用現有的網域群組名稱來定義新的角色。 在下列範例中,
adminGroupName是一組Microsoft Entra ID 中具有特殊許可權的使用者。 請勿在群組名稱中使用特殊字元或空白字元。=後面的字元將權限授與此角色。*表示群組具有完整權限。[roles] adminGroupName = *新增角色以存取 Zeppelin 解譯器。 在下列範例中,
adminGroupName中的所有使用者都有權限存取 Zeppelin 解譯器,還可以建立新的解譯器。 您可以在roles[]中的方括弧之間放入多個角色,並以逗號分隔。 具有必要權限的使用者就可以存取 Zeppelin 解譯器。[urls] /api/interpreter/** = authc, roles[adminGroupName]
多個網域群組的範例 shiro.ini:
[main]
anyofrolesuser = org.apache.zeppelin.utils.AnyOfRolesUserAuthorizationFilter
[roles]
group1 = *
group2 = *
group3 = *
[urls]
/api/interpreter/** = authc, anyofrolesuser[group1, group2, group3]
Livy 工作階段管理
Zeppelin 筆記本中的執行第一個程式碼段落在叢集上建立新的 Livy 工作階段。 您稍後建立的所有 Zeppelin 筆記本會共用此工作階段。 如果 Livy 工作階段出於任何原因而終止,則不會從 Zeppelin 筆記本執行作業。
在這種情況下,您必須先執行下列步驟,才能開始從 Zeppelin 筆記本執行作業。
從 Zeppelin Notebook 重新啟動 Livy 解譯器。 作法是從右上角選取已登入的使用者名稱,以開啟解譯器設定,然後選取 [解譯器]。
捲動至 [livy2],然後選取 [重新啟動]。
從現有的 Zeppelin Notebook 執行程式碼單元。 此程式碼在 HDInsight 叢集上建立新的 Livy 工作階段。
一般資訊
驗證服務
若要從 Ambari 驗證服務,請瀏覽至 https://CLUSTERNAME.azurehdinsight.net/#/main/services/ZEPPELIN/summary,其中 CLUSTERNAME 是叢集的名稱。
若要從命令列驗證服務,請透過 SSH 連線到前端節點。 使用 sudo su zeppelin 命令將使用者切換至 zeppelin。 狀態命令:
| Command | 描述 |
|---|---|
/usr/hdp/current/zeppelin-server/bin/zeppelin-daemon.sh status |
服務狀態。 |
/usr/hdp/current/zeppelin-server/bin/zeppelin-daemon.sh --version |
服務版本。 |
ps -aux | grep zeppelin |
識別 PID。 |
記錄位置
| 服務 | 路徑 |
|---|---|
| zeppelin-server | /usr/hdp/current/zeppelin-server/ |
| 伺服器記錄 | /var/log/zeppelin |
設定解譯器、Shiro、site.xml、log4j |
/usr/hdp/current/zeppelin-server/conf 或 /etc/zeppelin/conf |
| PID 目錄 | /var/run/zeppelin |
啟用偵錯記錄
瀏覽至
https://CLUSTERNAME.azurehdinsight.net/#/main/services/ZEPPELIN/summary,其中 CLUSTERNAME 是叢集的名稱。流覽至 [設定]>[進階 zeppelin-log4j-properties]>[log4j_properties_content]。
將
log4j.appender.dailyfile.Threshold = INFO修改為log4j.appender.dailyfile.Threshold = DEBUG。加入
log4j.logger.org.apache.zeppelin.realm=DEBUG。儲存變更並重新啟動服務。