使用指令碼動作安全地管理 Azure HDInsight 上的 Python 環境
HDInsight 在 Spark 叢集中有兩個內建 Python 安裝,Anaconda Python 2.7 和 Python 3.5。 客戶可能需要自定義 Python 環境,例如安裝外部 Python 套件。 在這裡,我們示範如何在 HDInsight 上安全地管理 Apache Spark 叢集的 Python 環境。
必要條件
HDInsight 上的 Apache Spark 叢集。 如需指示,請參閱在 Azure HDInsight 中建立 Apache Spark 叢集。 如果您還沒有 HDInsight 上的 Spark 叢集,您可以在叢集建立期間執行腳本動作。 請流覽如何使用自訂文稿動作的檔。
支援 HDInsight 叢集上使用的開放原始碼軟體
Microsoft Azure HDInsight 服務會使用以 Apache Hadoop 為中心的開放原始碼技術環境。 Microsoft Azure 可為開放原始碼技術提供一般層級的支援。 如需詳細資訊,請參閱 Azure 支援常見問題網站。 HDInsight 服務針對內建元件提供額外等級的支援。
HDInsight 服務提供兩種類型的開放原始碼元件:
| 元件 | 描述 |
|---|---|
| 內建 | 這些元件會預安裝在 HDInsight 叢集上,並提供叢集的核心功能。 例如,Apache Hadoop YARN Resource Manager、Apache Hive 查詢語言 (HiveQL) 和 Mahout 連結庫屬於此類別。 HDInsight 提供的 Apache Hadoop 叢集版本新功能中提供叢集元件的完整清單。 |
| 自訂 | 身為叢集的使用者,您可以在您的工作負載中安裝或使用任何可在社群中取得或由您建立的元件。 |
重要
對隨 HDInsight 叢集提供的元件會有完整支援。 Microsoft 支援服務可協助隔離和解決這些元件的相關問題。
自定義元件會收到商業上合理的支援,以協助您進一步針對問題進行疑難解答。 Microsoft 支援可以解決問題,或他們可能會要求您參與 開放原始碼 技術可用的頻道,其中找到這項技術的深度專業知識。 例如,有許多社群網站可以使用,例如:HDInsight 的 Microsoft Q&A 問題頁面。 https://stackoverflow.com 此外,Apache 專案在 上 https://apache.org也有項目網站。
了解預設 Python 安裝
HDInsight Spark 叢集已安裝 Anaconda。 叢集中有兩個 Python 安裝:Anaconda Python 2.7 和 Python 3.5。 下表顯示Spark、Livy和 Jupyter 的預設 Python 設定。
| 設定 | Python 2.7 | Python 3.5 |
|---|---|---|
| 路徑 | /usr/bin/anaconda/bin | /usr/bin/anaconda/envs/py35/bin |
| Spark 版本 | 默認設為 2.7 | 可以將組態變更為 3.5 |
| Livy 版本 | 默認設為 2.7 | 可以將組態變更為 3.5 |
| Jupyter | PySpark 核心 | PySpark3 核心 |
針對Spark 3.1.2版本,會移除Apache PySpark核心,並在下 /usr/bin/miniforge/envs/py38/bin安裝新的 Python 3.8 環境,由 PySpark3 核心使用。 PYSPARK_PYTHON與 PYSPARK3_PYTHON 環境變數會以下列專案更新:
export PYSPARK_PYTHON=${PYSPARK_PYTHON:-/usr/bin/miniforge/envs/py38/bin/python}
export PYSPARK3_PYTHON=${PYSPARK_PYTHON:-/usr/bin/miniforge/envs/py38/bin/python}
安全地安裝外部 Python 套件
HDInsight 叢集取決於內建的 Python 環境,Python 2.7 和 Python 3.5。 直接在這些預設內建環境中安裝自定義套件可能會導致非預期的連結庫版本變更。 再進一步中斷叢集。 若要安全地為您的Spark應用程式安裝自定義外部 Python 套件,請遵循下列步驟。
使用 conda 建立 Python 虛擬環境。 虛擬環境會為您的專案提供隔離的空間,而不會中斷其他人。 建立 Python 虛擬環境時,您可以指定要使用的 Python 版本。 即使您想要使用 Python 2.7 和 3.5,您仍然需要建立虛擬環境。 此需求是確保叢集的默認環境未中斷。 針對具有下列腳本的所有節點,在您的叢集上執行腳本動作,以建立 Python 虛擬環境。
--prefix指定 conda 虛擬環境所在的路徑。 有幾個設定必須根據這裡指定的路徑進一步變更。 在此範例中,我們使用 py35new,因為叢集已經有名為 py35 的現有虛擬環境。python=指定虛擬環境的 Python 版本。 在此範例中,我們使用 3.5 版,其版本與一個內建的叢集相同。 您也可以使用其他 Python 版本來建立虛擬環境。anaconda會將package_spec指定為 anaconda,以在虛擬環境中安裝 Anaconda 套件。
sudo /usr/bin/anaconda/bin/conda create --prefix /usr/bin/anaconda/envs/py35new python=3.5 anaconda=4.3 --yes視需要在建立的虛擬環境中安裝外部 Python 套件。 針對具有下列腳本的所有節點,在您的叢集上執行腳本動作,以安裝外部 Python 套件。 您必須擁有 sudo 許可權,才能將檔案寫入虛擬環境資料夾。
搜尋 套件索引 以取得可用套件的完整清單。 您也可以從其他來源取得可用套件清單。 例如,您可以安裝透過 conda-forge 提供的套件。
如果您要安裝具有最新版本的連結庫,請使用下列命令:
使用 conda 通道:
seaborn是您想要安裝的套件名稱。-n py35new指定剛建立的虛擬環境名稱。 請務必根據您的虛擬環境建立對應變更名稱。
sudo /usr/bin/anaconda/bin/conda install seaborn -n py35new --yes或者,使用 PyPi 存放庫,變更
seaborn並py35new對應:sudo /usr/bin/anaconda/envs/py35new/bin/pip install seaborn
如果您要安裝具有特定版本的連結庫,請使用下列命令:
使用 conda 通道:
numpy=1.16.1是您想要安裝的套件名稱和版本。-n py35new指定剛建立的虛擬環境名稱。 請務必根據您的虛擬環境建立對應變更名稱。
sudo /usr/bin/anaconda/bin/conda install numpy=1.16.1 -n py35new --yes或者,使用 PyPi 存放庫,變更
numpy==1.16.1並py35new對應:sudo /usr/bin/anaconda/envs/py35new/bin/pip install numpy==1.16.1
如果您不知道虛擬環境名稱,您可以透過 SSH 連線到叢集的前端節點,並執行
/usr/bin/anaconda/bin/conda info -e以顯示所有虛擬環境。變更 Spark 和 Livy 設定,並指向已建立的虛擬環境。
開啟Ambari UI,移至Spark 2頁面,[設定] 索引標籤。
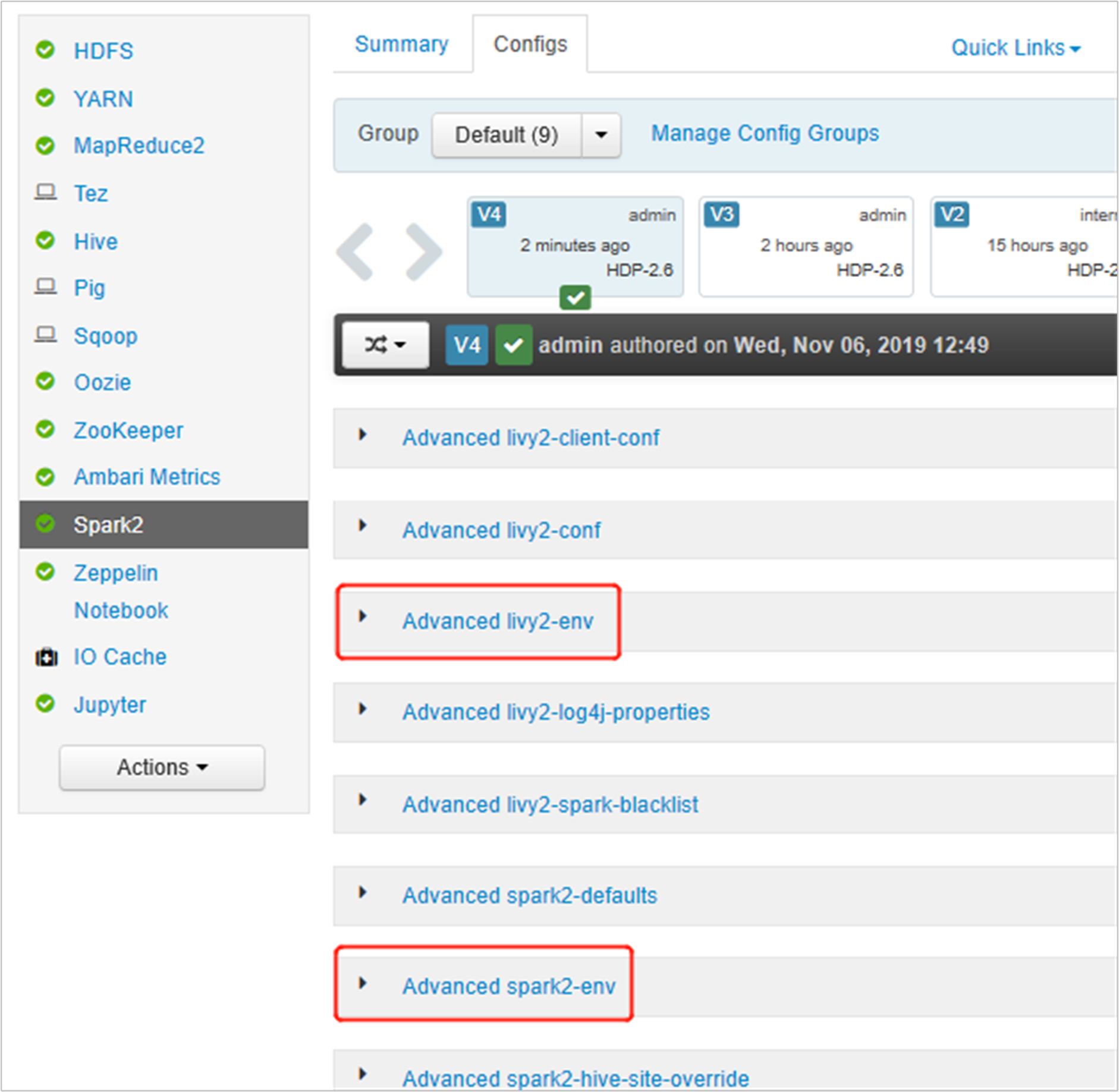
展開 [進階 livy2-env],在底部新增下列語句。 如果您已安裝具有不同前置詞的虛擬環境,請對應變更路徑。
export PYSPARK_PYTHON=/usr/bin/anaconda/envs/py35new/bin/python export PYSPARK_DRIVER_PYTHON=/usr/bin/anaconda/envs/py35new/bin/python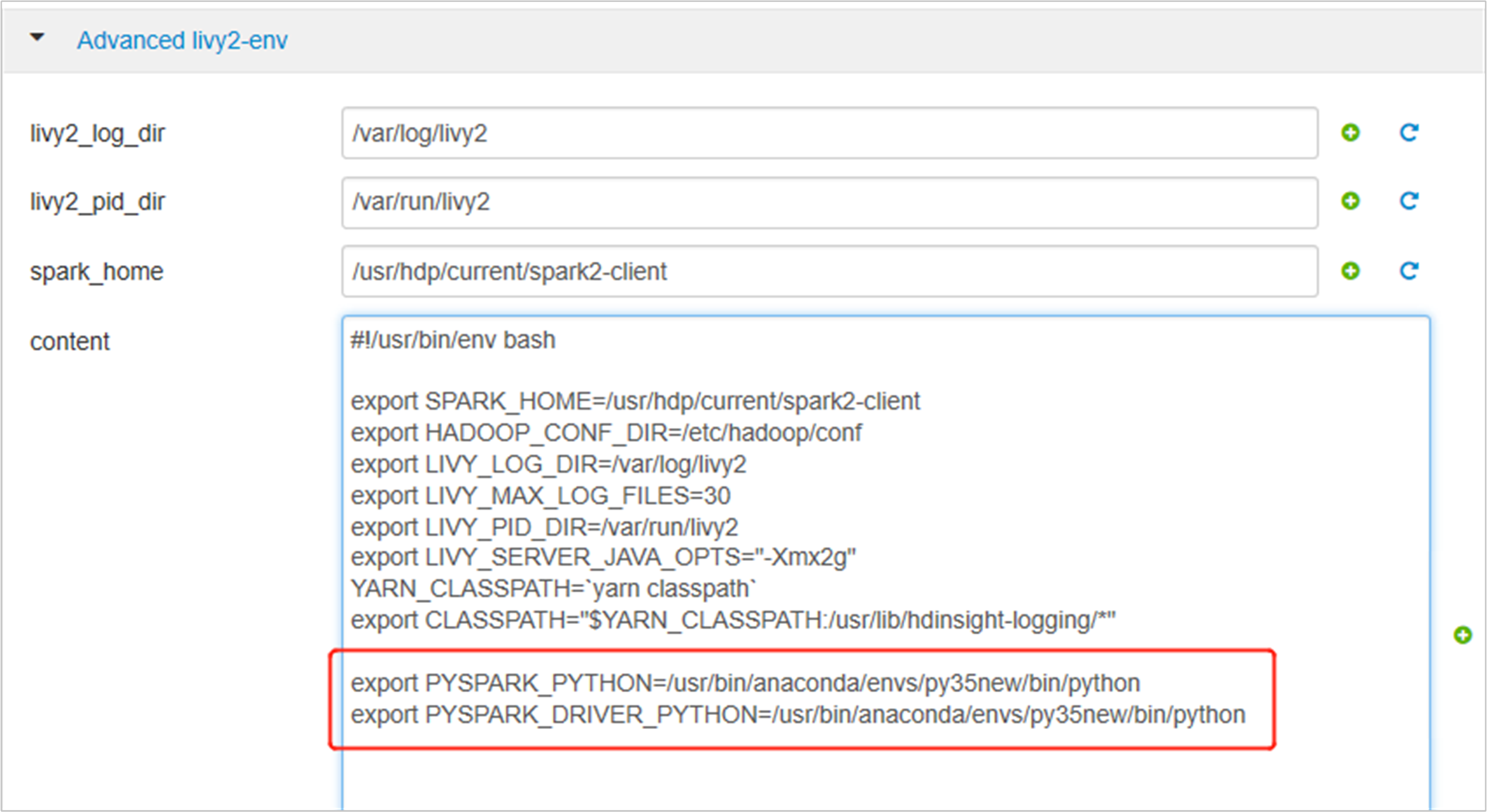
展開 [進階 spark2-env],取代底部的現有導出PYSPARK_PYTHON語句。 如果您已安裝具有不同前置詞的虛擬環境,請對應變更路徑。
export PYSPARK_PYTHON=${PYSPARK_PYTHON:-/usr/bin/anaconda/envs/py35new/bin/python}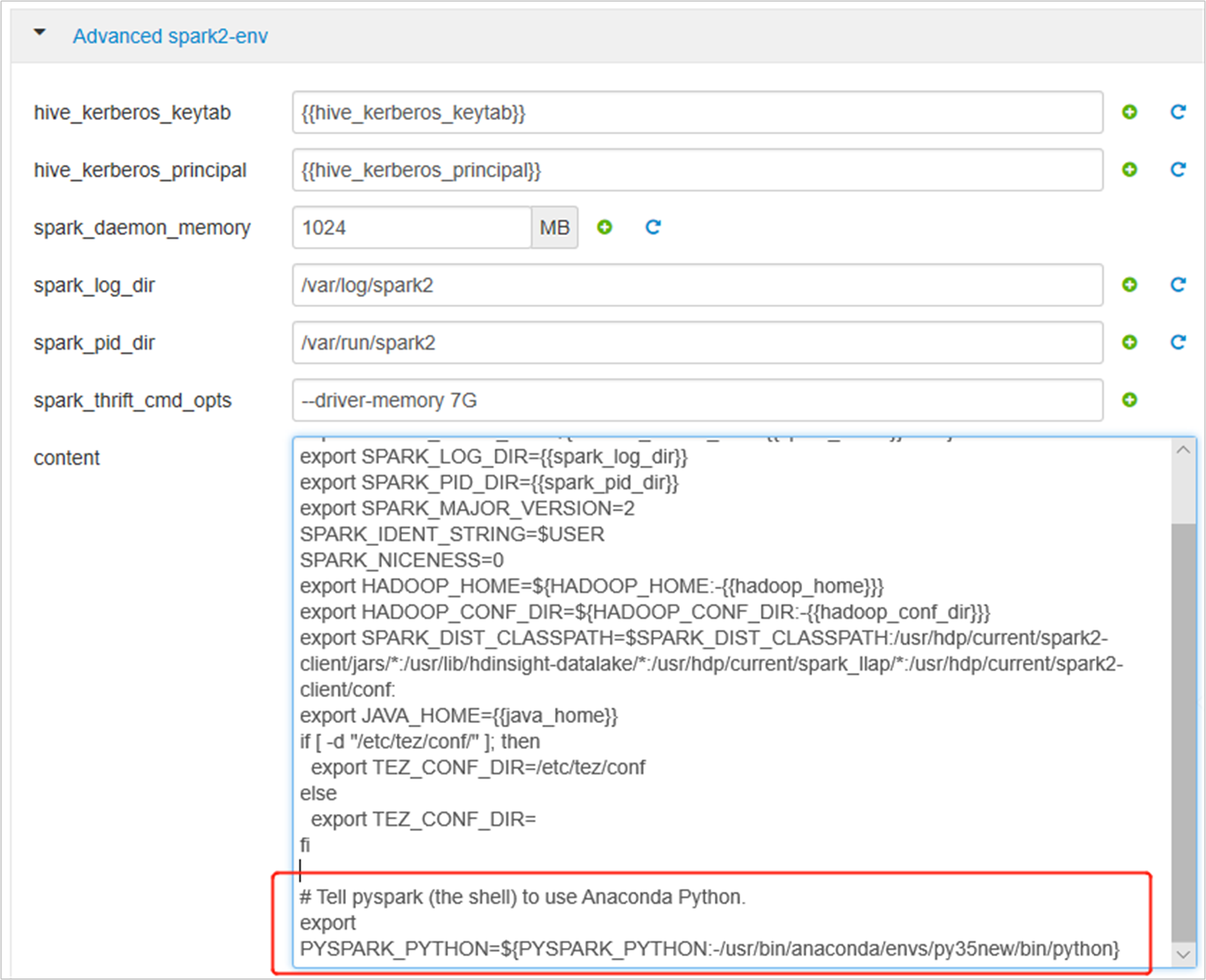
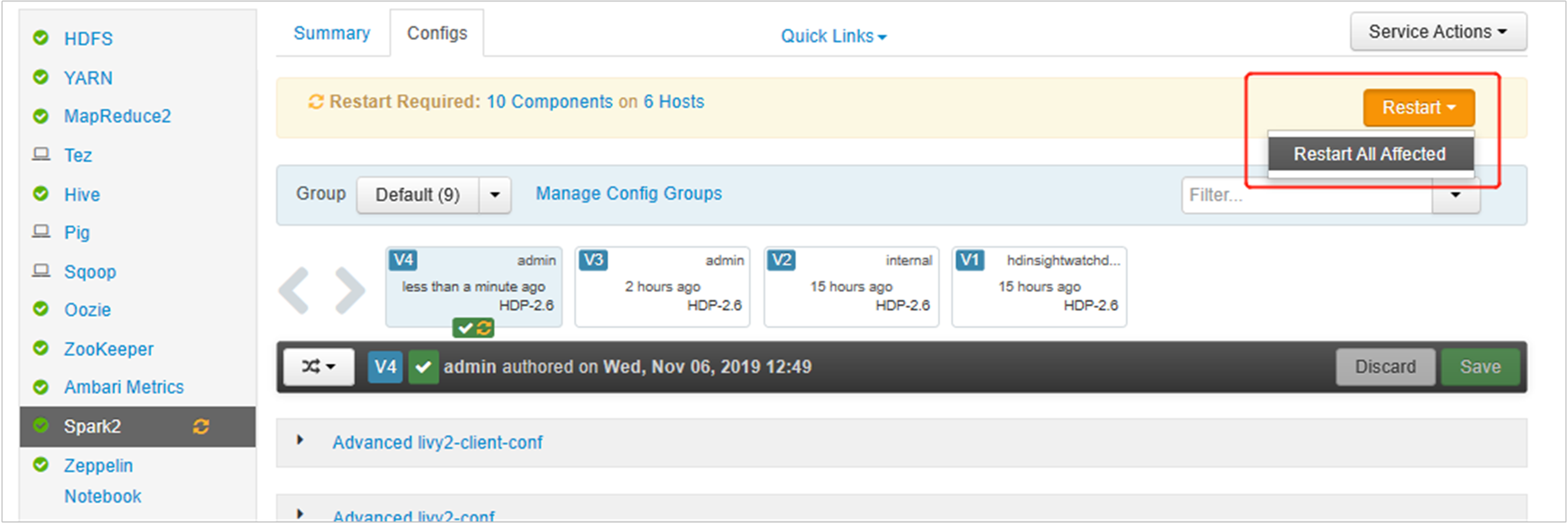
儲存變更並重新啟動受影響的服務。 這些變更需要重新啟動 Spark 2 服務。 Ambari UI 會提示必要的重新啟動提醒,按兩下 [重新啟動] 以重新啟動所有受影響的服務。
將兩個屬性設定為 Spark 工作階段,以確保作業指向更新的 Spark 組態:
spark.yarn.appMasterEnv.PYSPARK_PYTHON和spark.yarn.appMasterEnv.PYSPARK_DRIVER_PYTHON。使用終端機或筆記本,請使用 函式
spark.conf.set。spark.conf.set("spark.yarn.appMasterEnv.PYSPARK_PYTHON", "/usr/bin/anaconda/envs/py35/bin/python") spark.conf.set("spark.yarn.appMasterEnv.PYSPARK_DRIVER_PYTHON", "/usr/bin/anaconda/envs/py35/bin/python")如果您使用
livy,請將下列屬性新增至要求本文:"conf" : { "spark.yarn.appMasterEnv.PYSPARK_PYTHON":"/usr/bin/anaconda/envs/py35/bin/python", "spark.yarn.appMasterEnv.PYSPARK_DRIVER_PYTHON":"/usr/bin/anaconda/envs/py35/bin/python" }
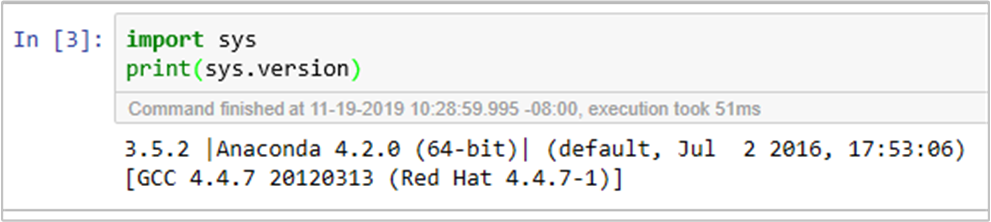
如果您想要在 Jupyter 上使用新建立的虛擬環境。 變更 Jupyter 設定並重新啟動 Jupyter。 在具有下列語句的所有標頭節點上執行腳本動作,以將 Jupyter 指向新建立的虛擬環境。 請務必修改您為虛擬環境指定的前置詞路徑。 執行此腳本動作之後,請透過Ambari UI重新啟動 Jupyter 服務,讓這項變更可供使用。
sudo sed -i '/python3_executable_path/c\ \"python3_executable_path\" : \"/usr/bin/anaconda/envs/py35new/bin/python3\"' /home/spark/.sparkmagic/config.json您可以執行程式代碼,在 Jupyter Notebook 中再次確認 Python 環境: