HDInsight 中的 Azure 儲存體概觀
Azure 儲存體是強大的一般用途儲存體解決方案,其完美整合了 HDInsight。 HDInsight 可以使用 Azure 儲存體中的 Blob 容器做為叢集的預設檔案系統。 透過 HDFS 介面,HDInsight 中的完整元件集可直接處理儲存為 Blob 的結構化或非結構化資料。
建議您讓預設叢集儲存體和商務資料使用不同的儲存體容器, 這麼做是為了將 HDInsight 記錄和暫存檔案與您自己的商務資料隔離。 我們也建議您在每次使用完畢後刪除包含應用程式和系統記錄檔的預設 Blob 容器,以減少儲存體成本。 請務必先擷取記錄再刪除容器。
若您選擇使用所選網路上的防火牆與虛擬網路限制保護儲存體帳戶,請務必啟用 [允許信任的 Microsoft 服務...] 例外狀況。例外狀況是 HDInsight 可以存取儲存體帳戶。
HDInsight 儲存架構
下圖提供 Azure 儲存體的 HDInsight 架構摘要檢視:
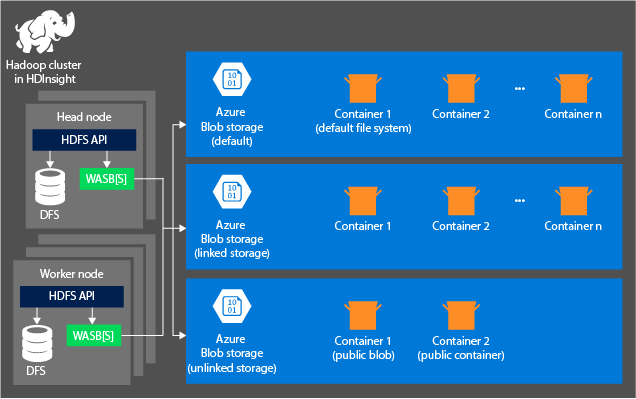
HDInsight 可以存取本機連接至計算節點的分散式檔案系統。 可使用完整 URI 來存取此檔案系統,例如:
hdfs://<namenodehost>/<path>
您也可以透過 HDInsight 存取 Azure 儲存體中的資料, 語法如下所示:
wasb://<containername>@<accountname>.blob.core.windows.net/<path>
針對具有階層命名空間 (Azure Data Lake Storage Gen2) 的帳戶,語法如下所示:
abfs://<containername>@<accountname>.dfs.core.windows.net/<file.path>/
使用 Azure 儲存體帳戶搭配 HDInsight 叢集時,請考量下列原則:
儲存體帳戶中連線至叢集的容器: 因為在建立期間帳戶名稱和金鑰會與叢集相關聯,所以您對這些容器中的 Blob 具有完整存取權。
儲存體帳戶中未連線至叢集的公用容器或公用 Blob:您對這些容器中的 Blob 只有唯讀權限。
注意
公用容器可讓您取得該容器中所有可用的 Blob 清單,並取得容器中繼資料。 公用 Blob 只在您知道確切的 URL 時才可讓您存取 Blob。 如需詳細資訊,請參閱 管理對容器與 Blob 的匿名讀取權限。
儲存體帳戶中未連接至叢集的私人容器:除非您在提交 WebHCat 工作時定義了儲存體帳戶,否則無法存取這些容器中的 Blob。
建立程序及其金鑰中定義的儲存體帳戶會儲存在叢集節點的 %HADOOP_HOME%/conf/core-site.xml 中。 根據預設,HDInsight 會使用 core-site.xml 檔案中定義的儲存體帳戶。 您可以使用 Apache Ambari 來修改此設定。 如需進一步了解可在 core-site.xml 檔案中修改或放置的儲存體帳戶設定,請參閱下列文章:
Apache Hive、 MapReduce、Apache Hadoop 串流、Apache Pig 等多項 WebHCat 作業均承載了儲存體帳戶和中繼資料的說明 (此層面目前適合於含儲存體帳戶的 Pig,但不適合於中繼資料。)如需詳細資訊,請參閱在其他儲存體帳戶和 Metastores 上使用 HDInsight 叢集。
Blob 可使用於結構化和非結構化資料。 Blob 容器會將資料儲存為索引鍵/值組,沒有目錄階層。 不過,索引鍵名稱可以包含斜線字元 (/),使檔案看起來有如儲存在目錄結構中。 例如,Blob 的機碼可以是 input/log1.txt。 實際上,input 目錄並不存在,但是因為索引碼名稱中有斜線字元,索引碼才會看起來像是檔案路徑。
Azure 儲存體的優點
未共置的計算叢集和儲存體資源具有隱含的效能成本。 讓所建立的計算叢集靠近 Azure 區域中的儲存體帳戶資源,即可降低這些成本。 在此區域中,計算節點可透過高速網路有效地存取 Azure 儲存體內的資料。
將資料儲存在 Azure 儲存體而非 HDFS 有許多優點:
資料重複使用和共用: HDFS 中的資料位於計算叢集內。 只有可存取計算叢集的應用程式,才能利用 HDFS API 來使用資料。 相較之下,可以透過 HDFS API 或 Blob 儲存體 REST API 存取 Azure 儲存體中的資料。 因為這種安排,許多應用程式 (包括其他 HDInsight 叢集) 和工具都可用來產生和取用資料。
資料封存:將資料儲存在 Azure 儲存體時,可安全地刪除用於計算的 HDInsight 叢集,而不會遺失使用者資料。
資料儲存體成本:長期將資料儲存在 DFS 中的成本高於將資料儲存於 Azure 儲存體, 因為計算叢集的成本比 Azure 儲存體的成本高。 此外,因為不需要每次產生計算叢集時都重新載入資料,也能節省資料載入成本。
彈性向外延展: 雖然HDFS 提供向外延展的檔案系統,但延展程度取決於您建立給叢集的節點數目。 變更縮放程度較為複雜,因此可改用 Azure 儲存體自動提供的彈性縮放功能。
異地複寫:Azure 儲存體可以進行異地複寫。 雖然異地複寫可提供地理位置復原和資料備援性,但容錯移轉至異地複寫的位置會嚴重影響效能,且可能產生額外的成本。 因此,請謹慎選擇異地複寫,且最好在資料的價值大於額外成本時才這樣做。
某些 MapReduce 工作和封裝可能會產生中繼結果,但您不會想要將這些結果儲存在 Azure 儲存體中。 在此情況下,您仍可選擇將資料儲存在本機 HDFS。 在 Hive 工作和其他程序中,HDInsight 會使用 DFS 來儲存許多這些中繼結果。
注意
大部分 HDFS 命令 (例如,ls、copyFromLocal 和 mkdir) 可在 Azure 儲存體中正常運作。 只有原生 HDFS 實作 (稱為 DFS) 的特定命令 (例如 fschk 和 dfsadmin) 才會在 Azure 儲存體上出現不同的行為。