快速入門:使用 Apache Zeppelin 在 Azure HDInsight 中執行 Apache Hive 查詢
在此快速入門中,您將會了解如何使用 Apache Zeppelin 在 Azure HDInsight 中執行 Apache Hive 查詢。 HDInsight 互動式查詢叢集包含 Apache Zeppelin Notebook,可供您用來執行互動式 Hive 查詢。
如果您沒有 Azure 訂用帳戶,請在開始前建立免費帳戶。
必要條件
HDInsight 互動式查詢叢集。 請參閱建立叢集以建立 HDInsight 叢集。 請務必選擇 [互動式查詢] 叢集類型。
建立 Apache Zeppelin 記事
在下列 URL (
https://CLUSTERNAME.azurehdinsight.net/zeppelin) 中,將CLUSTERNAME取代為您的叢集名稱。 在網頁瀏覽器中輸入該 URL。輸入您的叢集登入使用者名稱與密碼。 透過 [Zeppelin] 頁面,您可以建立新的記事或開啟現有記事。 HiveSample 包含一些 Hive 查詢範例。
選取 [建立新記事]。
從 [建立新記事] 對話方塊,輸入或選取下列值:
- 記事名稱:輸入記事的名稱。
- 預設解譯器:從下拉式清單中選取 [jdbc]。
選取 [建立記事]。
在程式碼區段中輸入下列 Hive 查詢,然後按 Shift + Enter:
%jdbc(hive) show tables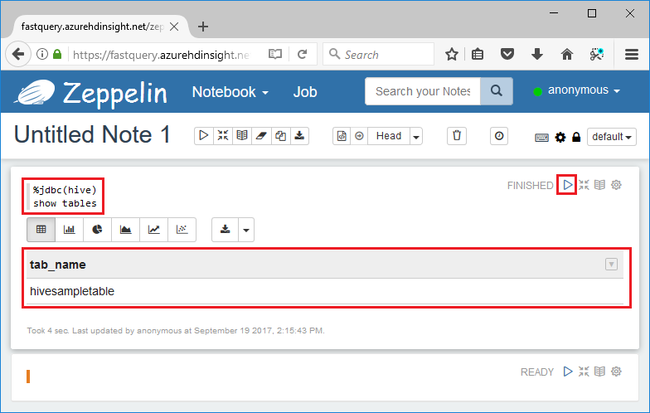
%jdbc(hive)第一行中的 語句會指示筆記本使用Hive JDBC解釋器。此查詢應該會傳回一個 Hive 資料表,其名稱為 hivesampletable。
以下是您可以針對 hivesampletable 執行的兩個Hive查詢:
%jdbc(hive) select * from hivesampletable limit 10 %jdbc(hive) select ${group_name}, count(*) as total_count from hivesampletable group by ${group_name=market,market|deviceplatform|devicemake} limit ${total_count=10}相較於傳統的Hive,查詢結果會更快回復。
更多範例
建立資料表。 在 Zeppelin Notebook 中執行程序代碼:
%jdbc(hive) CREATE EXTERNAL TABLE log4jLogs ( t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE;將資料載入到新的資料表。 在 Zeppelin Notebook 中執行程序代碼:
%jdbc(hive) LOAD DATA INPATH 'wasbs:///example/data/sample.log' INTO TABLE log4jLogs;插入單一記錄。 在 Zeppelin Notebook 中執行程序代碼:
%jdbc(hive) INSERT INTO TABLE log4jLogs2 VALUES ('A', 'B', 'C', 'D', 'E', 'F', 'G');
如需更多語法,請檢閱 Hive語言手冊 。
清除資源
完成此快速入門之後,您可以刪除叢集。 利用 HDInsight,您的資料會儲存在 Azure 儲存體中,以便您在未使用叢集時安全地刪除該叢集。 您也需支付 HDInsight 叢集的費用 (即使未使用該叢集)。 由於叢集費用是儲存體費用的許多倍,所以刪除未使用的叢集符合經濟效益。
若要刪除叢集,請參閱使用您的瀏覽器、PowerShell 或 Azure CLI 刪除 HDInsight 叢集。
下一步
在此快速入門中,您已了解如何使用 Apache Zeppelin 在 Azure HDInsight 中執行 Apache Hive 查詢。 若要深入了解 Hive 查詢,下一篇文章將會說明如何使用 Visual Studio 來執行查詢。