在 Azure HDInsight 中監視叢集效能
監視 HDInsight 叢集的健康情況和效能對於維護最佳效能與資源使用率而言是不可或缺的。 監視也可以協助您偵測並解決叢集設定錯誤和使用者程式碼問題。
下列各節說明如何對叢集、Apache Hadoop YARN 佇列上的負載進行監視和最佳化,以及偵測儲存體節流問題。
監視叢集負載
當叢集上的負載平均分散於所有節點時,Hadoop 叢集可以提供最佳效能。 這可讓處理工作在執行時,不會受限於個別節點上的 RAM、CPU 或磁碟資源。
若要查看您叢集的節點及其負載概況,請登入 Ambari Web UI,然後選取 [主機]。會依主機的完整網域名稱加以列出。 每個主機的操作狀態是依彩色的健康情況指示器來顯示:
| Color | 描述 |
|---|---|
| 紅色 | 主機上至少有一個主要元件已關閉。 暫留以查看列出受影響元件的工具提示。 |
| Orange | 主機上至少有一個次要元件已關閉。 暫留以查看列出受影響元件的工具提示。 |
| 黃色 | Ambari 伺服器超過 3 分鐘未收到主機的活動訊號。 |
| 綠 | 一般執行狀態。 |
您也會看到資料行顯示每個主機的核心數及 RAM 數量,以及磁碟使用量和負載平均。
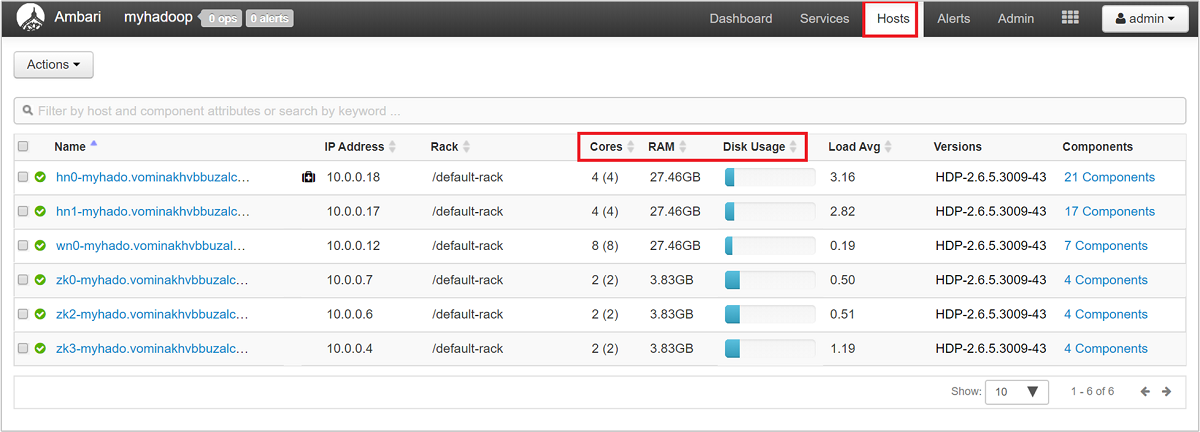
選取任何主機名稱,以詳細查看該主機和其計量上執行的元件。 計量會顯示為可選取的 CPU 使用量時間軸、負載、磁碟使用量、記憶體使用量、網路使用量和程序的數目。
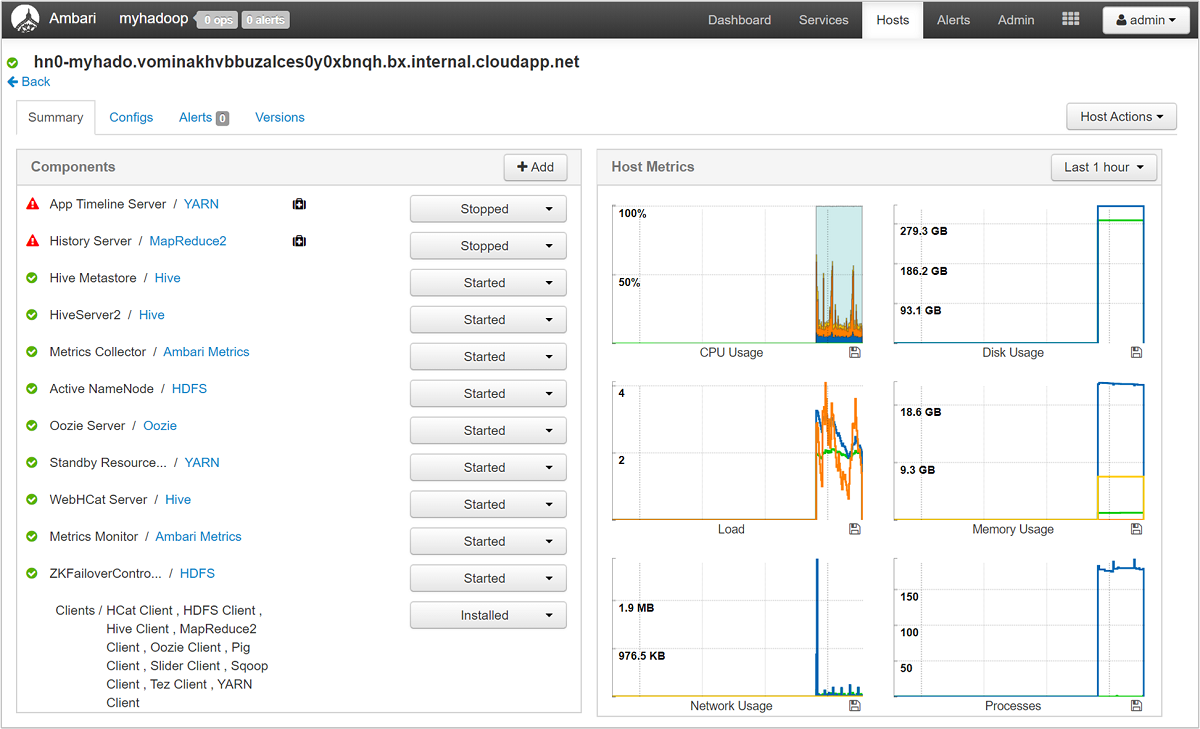
如需有關設定警示和檢視計量的詳細資料,請參閱使用 Apache Ambari Web UI 來管理 HDInsight 叢集。
YARN 佇列組態
Hadoop 有各種服務在其分散式平台之間執行。 YARN (Yet Another Resource Negotiator) 可協調這些服務並配置叢集資源,確保將任何負載平均分散於叢集。
YARN 會將 JobTracker、資源管理及作業排程/監視的兩個責任分割為兩個精靈:全域 Resource Manager 和每個應用程式 ApplicationMaster (AM)。
Resource Manager 是純排程器,且會單獨仲裁所有競爭應用程式之間的可用資源。 Resource Manager 可確保所有資源一律在使用中、最佳化各種常數,例如 SLA、容量保證等等。 ApplicationMaster 會交涉 Resource Manager 的資源,並使用 NodeManager(s) 來執行及監視容器和其資源耗用量。
當多個租用戶共用大型叢集時,叢集資源會進行競爭。 CapacityScheduler 是隨插即用的排程器,可藉由將要求排入佇列來協助資源共用。 CapacityScheduler 也支援階層式佇列,以確保在允許其他應用程式的佇列使用可用資源之前,在組織的子佇列之間共用資源。
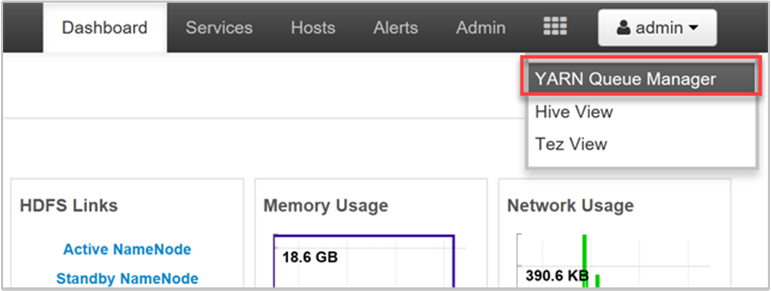
YARN 可讓我們將資源配置給這些佇列,並顯示是否已指派所有可用的資源。 若要檢視您佇列的相關資訊,請登入 Ambari Web UI,然後從頂端功能表中選取 [YARN 佇列管理員]。
[YARN 佇列管理員] 頁面左側會顯示您的佇列清單,以及指派給每個佇列的容量百分比。
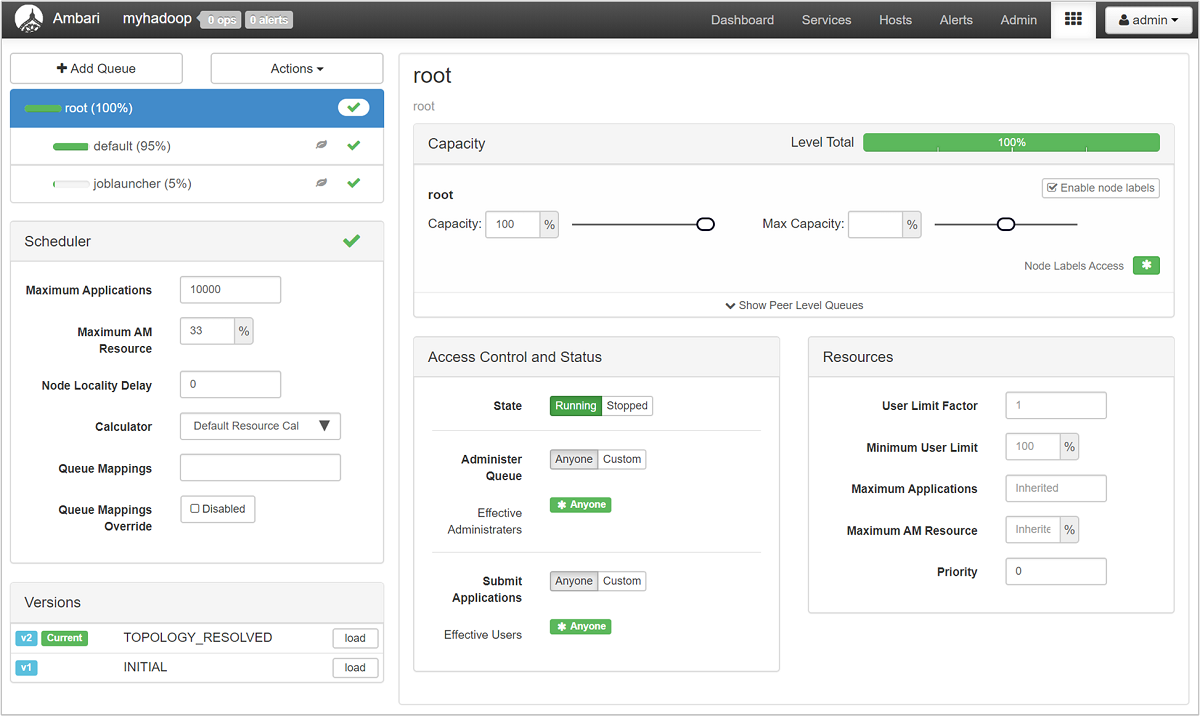
若要更詳細查看您的佇列,請從 Ambari 儀表板中的左側清單選取 [YARN] 服務。 然後在 [快速連結] 下拉式功能表中,選取作用中節點下的 [Resource Manager UI]。
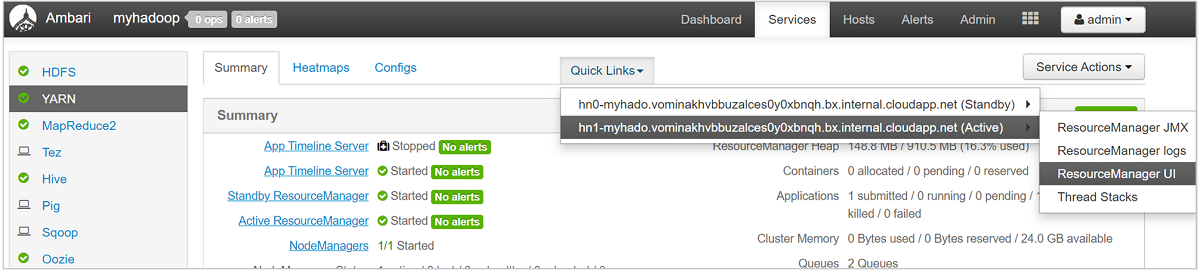
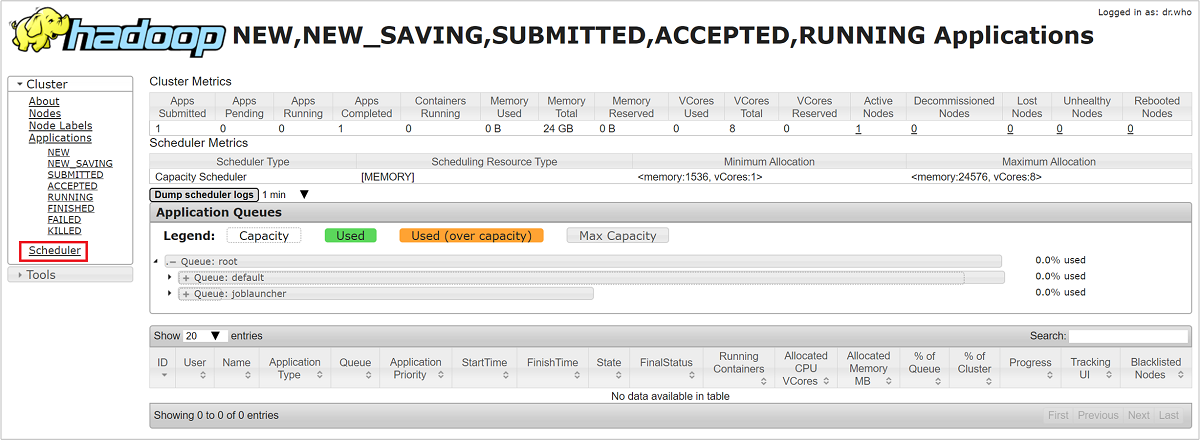
在 Resource Manager UI 中,從左側功能表選取 [排程器]。 您會在 [應用程式佇列] 下方看到您的佇列清單。 您可以在這裡查看每個佇列使用的容量,作業在它們之間散發的情況,以及是否有任何作業為有限資源。
儲存體節流
叢集的效能瓶頸可能會發生在儲存層級中。 這種類型的瓶頸最常因為封鎖輸入/輸出 (IO) 作業,在您執行的工作傳送之 IO 超過儲存體服務可以處理的範圍時就會發生這個狀況。 此封鎖會建立 IO 要求的佇列,等候目前 IO 處理完成後才會予以處理。 區塊是由於儲存體節流,這並不是實體的限制,而是服務等級協定 (SLA) 的儲存體服務所加諸的限制。 這項限制可確保沒有任何單一用戶端或租用戶可以獨佔服務。 SLA 會限制 Azure 儲存體每秒的 IO 數 (IOPS) - 如需詳細資訊,請參閱 標準儲存體帳戶的可擴縮性和效能目標。
如果您是使用 Azure 儲存體,如需監視儲存體相關問題的資訊 (包括節流),請參閱監視、診斷 Microsoft Azure 儲存體,及對其進行疑難排解。
如果叢集的備份存放區是 Azure Data Lake Storage (ADLS),您的節流很有可能是因為頻寬限制。 在此情況下,透過觀察工作記錄中的節流錯誤即可識別節流。 如需 ADLS,請參閱這些文章中的節流一節以了解適當服務:
- HDInsight 和 Azure Data Lake Storage 上的 Apache Hive 效能微調方針
- HDInsight 和 Azure Data Lake Storage 上的 MapReduce 效能微調方針
針對緩慢節點效能進行疑難排解
在某些情況下,可能會因為叢集上的磁碟空間不足而發生效能緩慢的問題。 使用下列步驟調查:
使用 ssh 命令連線到每個節點。
執行下列其中一個命令來檢查磁碟使用量:
df -h du -h --max-depth=1 / | sort -h檢閱輸出,並檢查
mnt資料夾或其他資料夾中是否有任何大型檔案。 一般而言,usercache和appcache(mnt/resource/hadoop/yarn/local/usercache/hive/appcache/) 等資料夾會包含大型檔案。如果發現大型檔案,表示目前的作業導致檔案大小增長,或先前失敗的作業造成此結果。 若要檢查此行為是否由目前的作業所造成,請執行下列命令:
sudo du -h --max-depth=1 /mnt/resource/hadoop/yarn/local/usercache/hive/appcache/如果此命令指出特定的作業,您可以選擇使用類似下列的命令來終止作業:
yarn application -kill -applicationId <application_id>將
application_id取代為應用程式識別碼。 如果並未提出特定的作業,請移至下一個步驟。在以上命令完成後,如果沒有指出特定的作業,請執行類似下列的命令來刪除您找到的大型檔案:
rm -rf filecache usercache
如需磁碟空間問題的詳細資訊,請參閱磁碟空間不足。
注意
如果您有想要保留的大型檔案,但該檔案會造成磁碟空間不足的問題,則必須相應增加 HDInsight 叢集,並重新啟動服務。 完成此程序並稍候幾分鐘後,您會注意到儲存體已釋出空間,同時也會還原節點的正常效能。
下一步
請造訪下列連結以取得關於疑難排解和監視您叢集的詳細資訊: