使用適用於 Visual Studio Code 的 Spark 與 Hive Tools
了解如何使用 Apache Spark & Hive Tools for Visual Studio Code。 使用工具建立並提交適用於 Apache Spark 的 Apache Hive 批次作業、互動式 Hive 查詢和 PySpark 指令碼。 首先,我們將說明如何在 Visual Studio Code 中安裝 Spark & Hive Tools。 然後,我們將逐步解說如何將作業提交至 Spark & Hive Tools。
您可以在 Visual Studio Code 支援的平台上安裝 Spark & Hive Tools。 請留意下列適用於不同平台的必要條件。
必要條件
若要完成此文章中的步驟,將會需要下列項目:
- Azure HDInsight 叢集。 若要建立叢集,請參閱開始使用 HDInsight。 或者,使用支援 Apache Livy 端點的 Spark 和 Hive 叢集。
- Visual Studio Code \(英文\)。
- Mono \(英文\)。 只有 Linux 和 macOS 才需要 Mono。
- Visual Studio Code 的 PySpark 互動式環境。
- 本機目錄。 本文使用
C:\HD\HDexample。
安裝 Spark & Hive Tools
符合必要條件後,您即可依照下列步驟安裝 Spark & Hive Tools for Visual Studio Code:
開啟 Visual Studio Code。
從功能表列,瀏覽至 [檢視]>[擴充功能]。
在搜尋方塊中,輸入 Spark & Hive。
從搜尋結果中選取 [Spark & Hive Tools],然後選取 [安裝]:
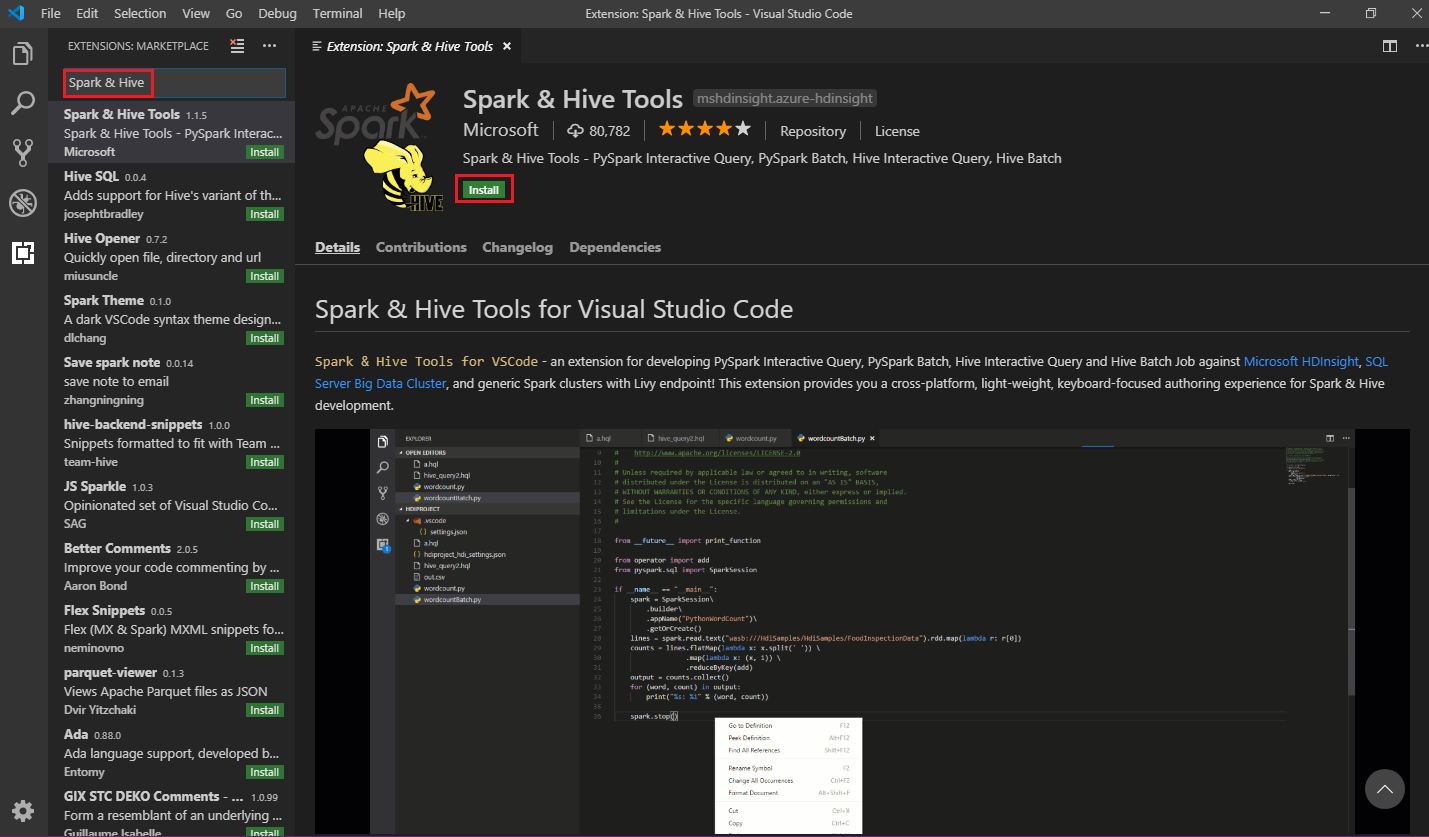
視需要選取 [重新載入]。
開啟工作資料夾
若要在 Visual Studio Code 中開啟工作資料夾並建立檔案,請執行下列步驟:
從功能表列,流覽至 [檔案>開啟資料夾...>
C:\HD\HDexample],然後選取 [選取資料夾] 按鈕。 該資料夾會出現在左側的 [檔案總管] 檢視中。在 [總管 ] 檢視中
HDexample,選取資料夾,然後選取 工作資料夾旁的 [新增檔案 ] 圖示: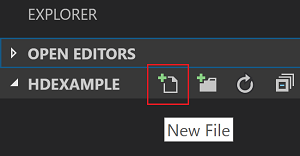
將新的檔案命名為
.hql(Hive 查詢) 或.py(Spark 指令碼) 副檔名。 這個範例使用 HelloWorld.hql。
設定 Azure 環境
針對國家雲端使用者,請先遵循下列步驟來設定 Azure 環境,然後使用 Azure: Sign In 命令登入 Azure:
瀏覽至 [檔案] > [喜好] > [設定]。
搜尋下列字串:Azure: Cloud。
從清單中選取國家雲端:
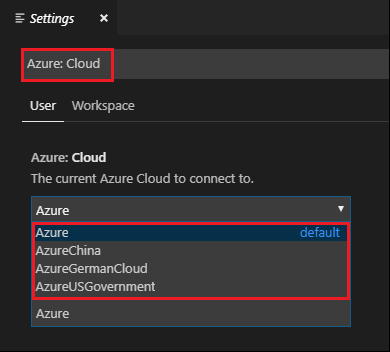
連線到 Azure 帳戶
使用者必須先登入 Azure 訂用帳戶或連結 HDInsight 叢集,您才能從 Visual Studio Code 將指令碼提交至叢集。 使用適用於 ESP 叢集的 Ambari 使用者名稱/密碼或已加入網域的認證,以連線至您的 HDInsight 叢集。 依照下列步驟連線至 Azure:
從功能表列中,瀏覽至 [檢視]>[命令選擇區...],然後輸入 [Azure: Sign In]\(Azure:登入\):
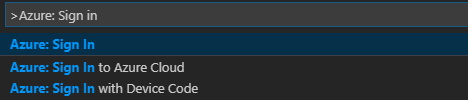
依照登入指示登入 Azure。 連線之後,您的 Azure 帳戶名稱會顯示在 Visual Studio Code 視窗底部的狀態列上。
連結叢集
連結:Azure HDInsight
您可以使用 Apache Ambari 受控使用者名稱來連結正常的叢集,或者也可以使用網域使用者名稱 (例如:user1@contoso.com) 來連結企業安全性套件保護 Hadoop 叢集。
從功能表列,瀏覽至 [檢視] > [命令選擇區...],然後輸入 Spark / Hive: Link a Cluster。

選取連結的叢集類型 Azure HDInsight。
輸入 HDInsight 叢集 URL。
輸入您的 Ambari 使用者名稱;預設值為 admin。
輸入您的 Ambari 密碼。
選取叢集類型。
設定叢集的顯示名稱 (選用)。
檢閱 [輸出] 檢視以確認。
注意
如果叢集已登入 Azure 訂用帳戶並連結叢集,則會使用連結的使用者名稱和密碼。
連結:泛型 Livy 端點
從功能表列,瀏覽至 [檢視] > [命令選擇區...],然後輸入 Spark / Hive: Link a Cluster。
選取連結的叢集類型 [泛型 Livy 端點]。
輸入泛型 Livy 端點。 例如:http://10.172.41.42:18080.
選取授權類型 [基本] 或 [無]。 如果您選取 [基本]:
輸入您的 Ambari 使用者名稱;預設值為 admin。
輸入您的 Ambari 密碼。
檢閱 [輸出] 檢視以確認。
列出叢集
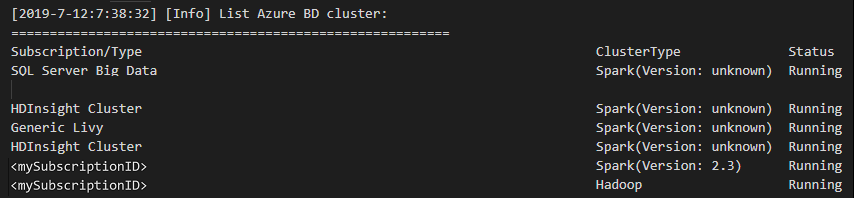
從功能表列,瀏覽至 [檢視] > [命令選擇區...],然後輸入 Spark / Hive: List Cluster。
選取您想要的訂用帳戶。
檢閱 [輸出] 檢視。 此檢視會顯示連結的叢集 (或叢集) 和 Azure 訂用帳戶下的所有叢集:
設定預設叢集
HDexample如果已關閉,請重新開啟稍早討論的資料夾。選取先前所建立的 HelloWorld.hql 檔案。 檔案會在指令碼編輯器中開啟。
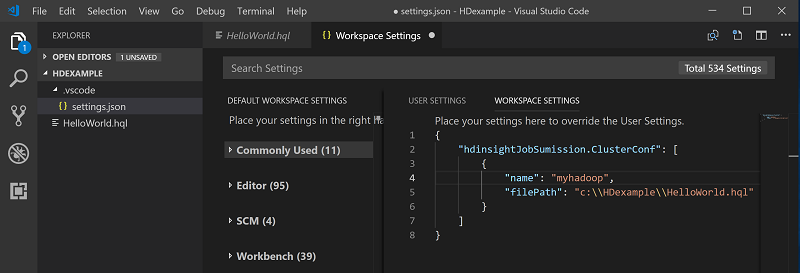
以滑鼠右鍵按一下指令碼編輯器,然後選取 [Spark / Hive: Set Default Cluster]。
連線至 Azure 帳戶,或連結至叢集 (如果您尚未這樣做)。
選取某個叢集作為目前指令檔的預設叢集。 工具會自動更新 .VSCode\settings.json 組態檔:
提交 interactive Hive 查詢與 Hive batch 指令碼
透過適用於 Visual Studio Code 的 Spark 與 Hive Tools,您可以將 interactive Hive 查詢與 Hive batch 指令碼提交至叢集。
HDexample如果已關閉,請重新開啟稍早討論的資料夾。選取先前所建立的 HelloWorld.hql 檔案。 檔案會在指令碼編輯器中開啟。
複製下列程式碼並貼上至 Hive 檔案中,然後儲存該檔案:
SELECT * FROM hivesampletable;連線至 Azure 帳戶,或連結至叢集 (如果您尚未這樣做)。
以滑鼠右鍵按一下指令碼編輯器,然後選取 [Hive: interactive] 以提交查詢,或使用 Ctrl + Alt + I 鍵盤快速鍵。 選取 [Hive: Batch] 以提交指令碼,或使用 Ctrl+Alt+H 鍵盤快速鍵。
如果您尚未指定預設叢集,請選取叢集。 工具也可讓您使用內容功能表來提交程式碼區塊,而非整個指令檔。 在幾分鐘之後,查詢結果就會顯示在新的索引標籤中:
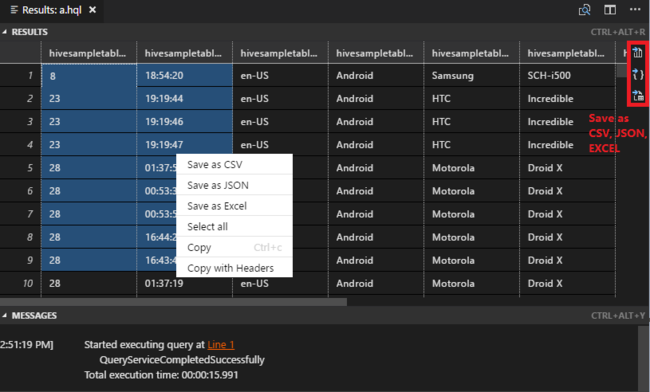
結果面板:您可以將整個結果以 CSV、JSON 或 Excel 檔案的形式儲存至本機路徑,或只選取多行。
訊息面板:當您選取行號時,便會跳至執行中指令碼的第一行。
提交互動式 PySpark 查詢
PySpark interactive 的必要條件
請注意,Jupyter 延伸模組版本 (ms-jupyter):v2022.1.1001614873 和 Python 延伸模組版本 (ms-python): v2021.12.1559732655、Python 3.6.x 和 3.7.x 是 HDInsight 互動式 PySpark 查詢所需。
使用者可以透過下列方式執行 PySpark interactive。
在 PY 檔案中使用 PySpark interactive 命令
使用 PySpark interactive 命令提交查詢,並執行下列步驟:
HDexample如果已關閉,請重新開啟稍早討論的資料夾。依照先前的步驟建立新檔案 HelloWorld.py。
將下列程式碼複製並貼到該指令檔:
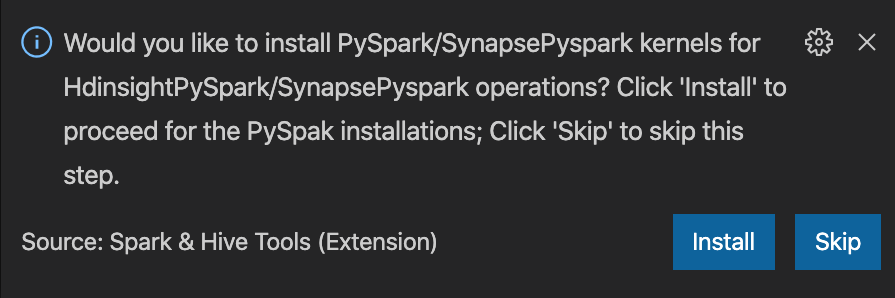
from operator import add from pyspark.sql import SparkSession spark = SparkSession.builder \ .appName('hdisample') \ .getOrCreate() lines = spark.read.text("/HdiSamples/HdiSamples/FoodInspectionData/README").rdd.map(lambda r: r[0]) counters = lines.flatMap(lambda x: x.split(' ')) \ .map(lambda x: (x, 1)) \ .reduceByKey(add) coll = counters.collect() sortedCollection = sorted(coll, key = lambda r: r[1], reverse = True) for i in range(0, 5): print(sortedCollection[i])視窗右下角會顯示安裝 PySpark/Synapse Pyspark 核心的提示。 您可以按一下 [安裝] 按鈕以繼續進行 PySpark/Synapse Pyspark 安裝,或按一下 [略過] 按鈕以略過此步驟。
若後續需要安裝,您可以瀏覽至 [檔案] > [喜好設定] > [設定],然後取消核取設定中的 [Hdinsight:啟用跳過 Pyspark 安裝]。
![顯示 [啟用 Skip Pyspark 安裝] 選項的螢幕快照。](media/hdinsight-for-vscode/enable-skip-pyspark-installation.png)
如果步驟 4 中的安裝成功,則會在視窗右下角顯示「已成功安裝 PySpark」訊息方塊。 按一下 [重新載入] 按鈕以重新載入視窗。
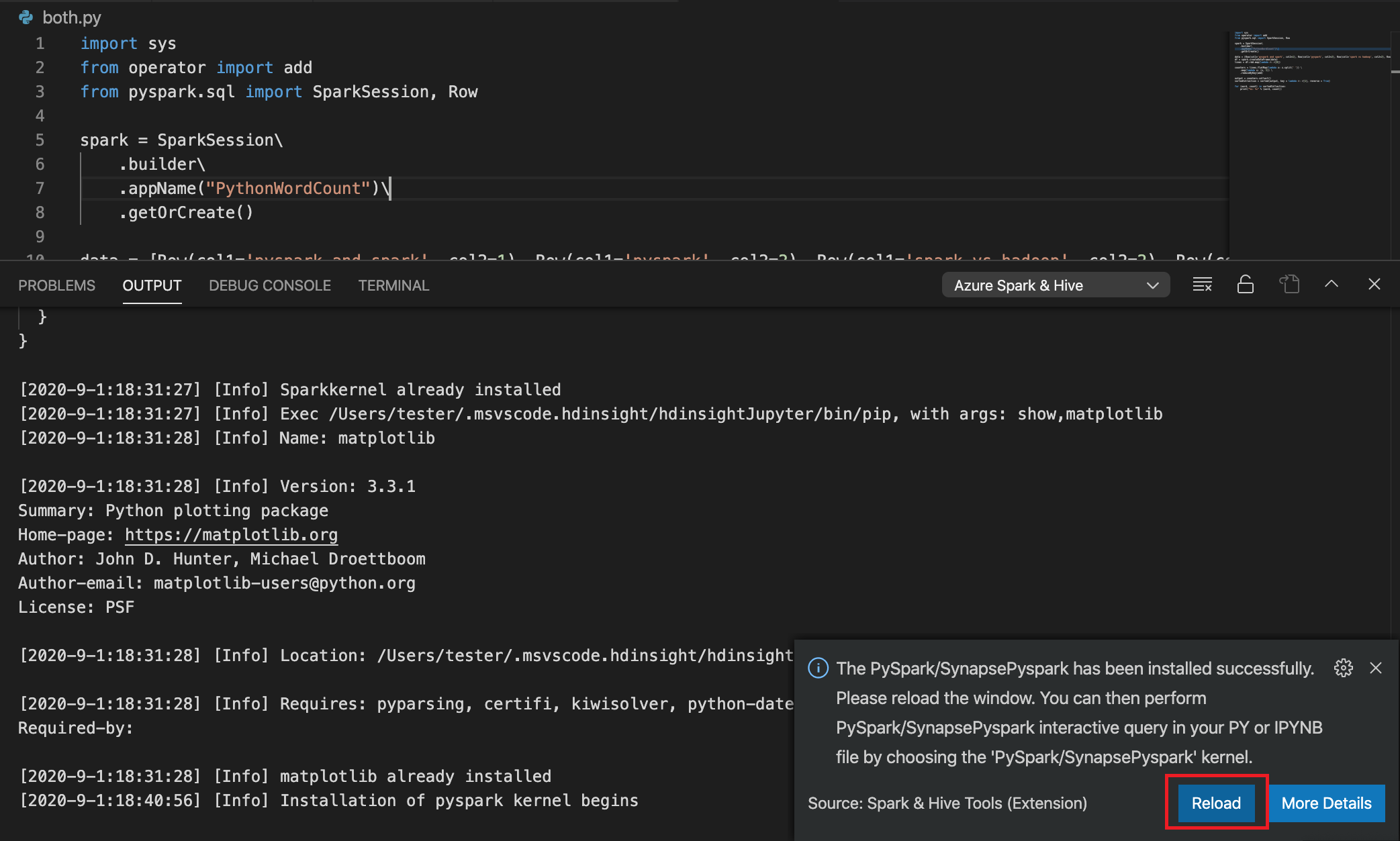
從功能表列中瀏覽至 [檢視] >[命令選擇區...],或使用 Shift + Ctrl + P 鍵盤快速鍵,然後輸入 [Python:Select Interpreter to start Jupyter Server]。

選取下方的 [Python] 選項。

從功能表列中瀏覽至 [檢視]>[命令選擇區...],或使用 Shift + Ctrl + P 鍵盤快速鍵,然後輸入 [Developer: Reload Window]。

連線至 Azure 帳戶,或連結至叢集 (如果您尚未這樣做)。
選取所有程式碼,以滑鼠右鍵按一下指令碼編輯器,選取 [Spark:Pyspark Interactive / Synapse: Pyspark Interactive] 以提交查詢。
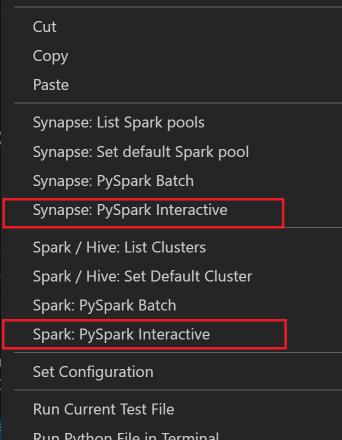
如果您尚未指定預設叢集,請選取叢集。 幾分鐘後,[Python 互動式] 結果便會出現在新的索引標籤中。按一下 PySpark,將核心切換至 PySpark /Synapse Pyspark,程式碼就會成功執行。 如果您想要切換至 Synapse Pyspark 核心,建議在 Azure 入口網站中停用自動設定。 否則,喚醒叢集並設定 Synapse 核心以供首次使用,可能需要很長的時間。 工具也可讓您使用內容功能表來提交程式碼區塊,而非整個指令檔:
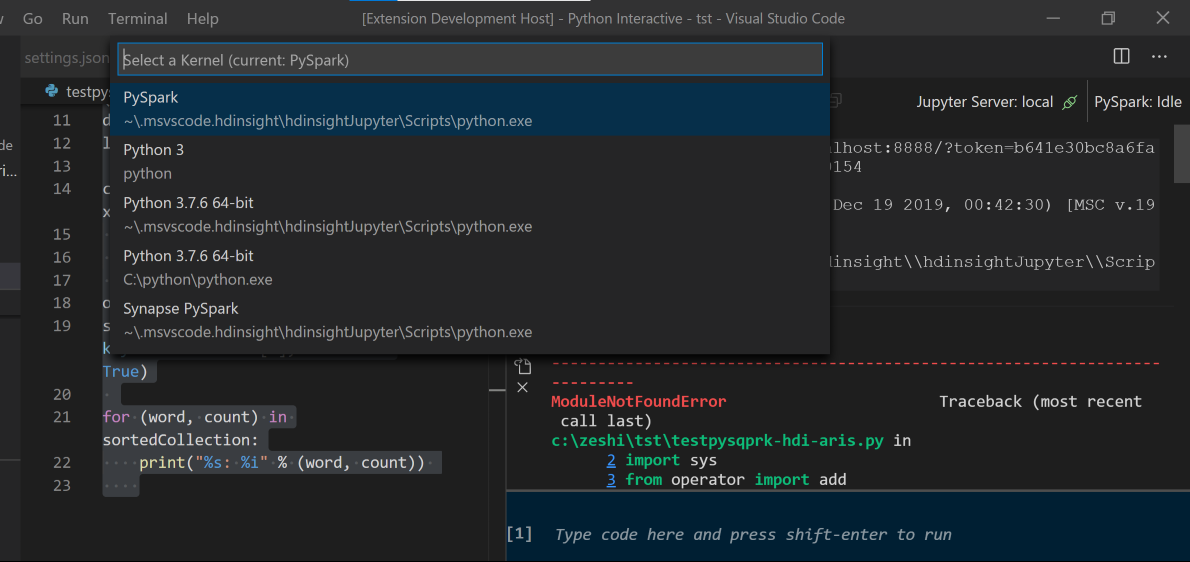
輸入 %%info,然後按 Shift+Enter 以檢視作業資訊 (選用):
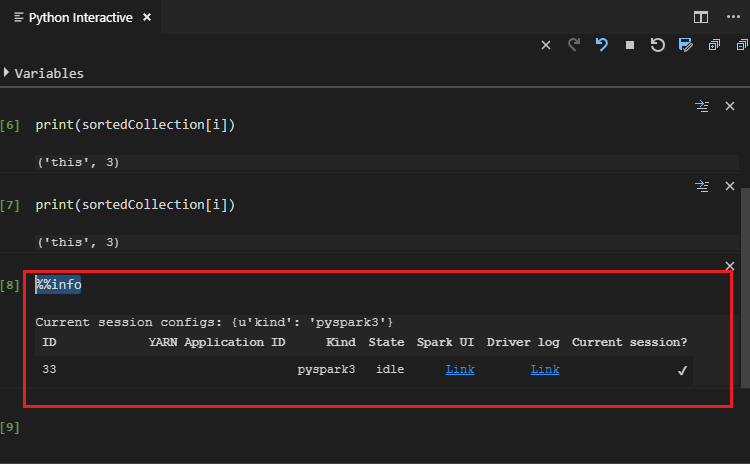
工具也支援 Spark SQL 查詢:
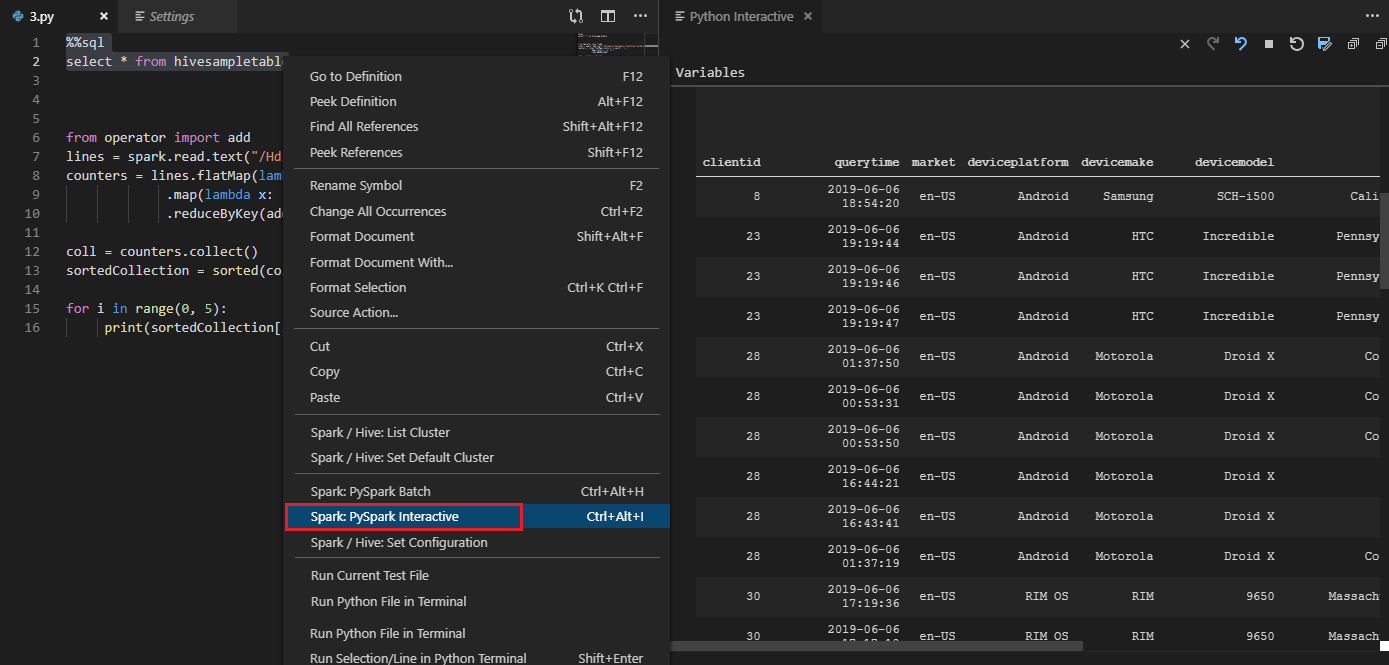
使用 #%% 註解在 PY 檔案中執行互動式查詢
在 Py 程式碼前面加上 #%% 以獲得筆記本體驗。
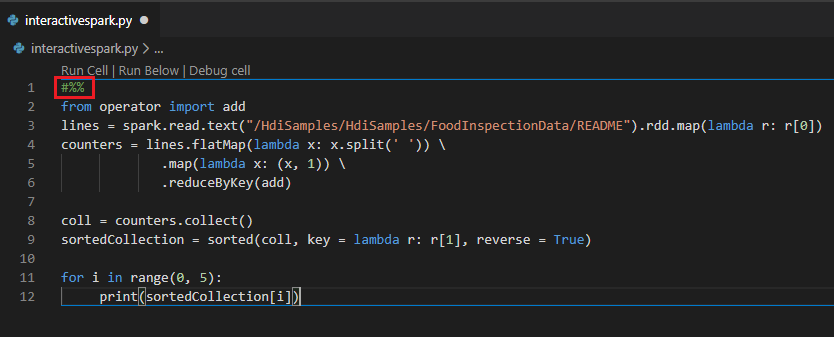
按一下 [執行資料格]。 幾分鐘后,Python 互動式結果會出現在新索引標籤中。單擊 [PySpark] 將核心切換至 PySpark/Synapse PySpark,然後按兩下 [再次執行 數據格 ],程式代碼將會順利執行。
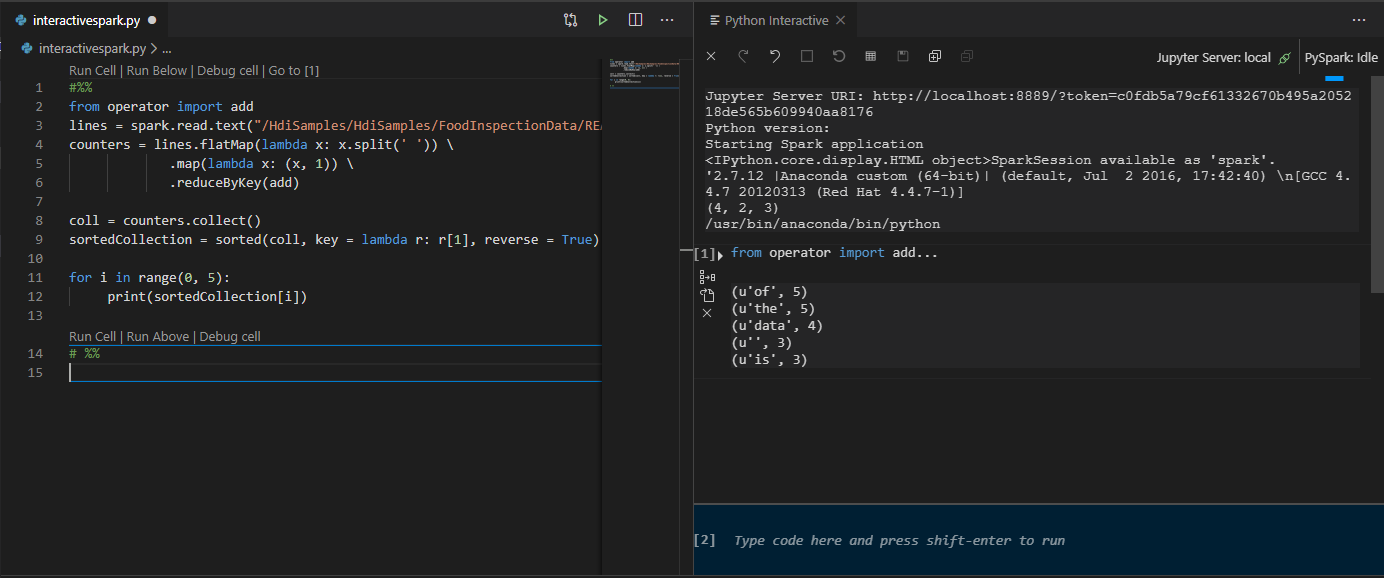
運用 Python 延伸模組的 IPYNB 支援
您可以從命令選擇區或在您的工作區中建立新
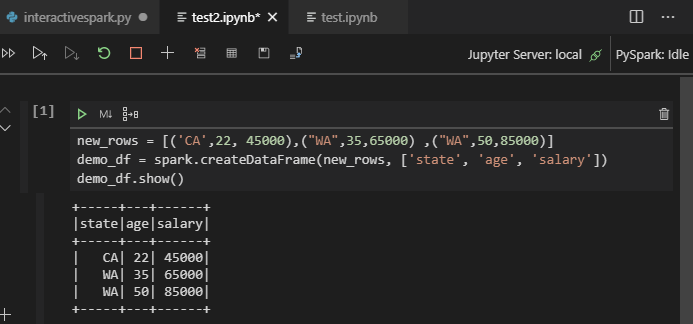
.ipynb檔案,藉此建立 Jupyter Notebook。 如需詳細資訊,請參閱在 Visual Studio Code 中使用 Jupyter Notebook按兩下 [ 執行數據格 ] 按鈕,依照提示設定 預設Spark集 區(我們建議您在開啟筆記本之前每次設定預設叢集/集區),然後重 載 視窗。
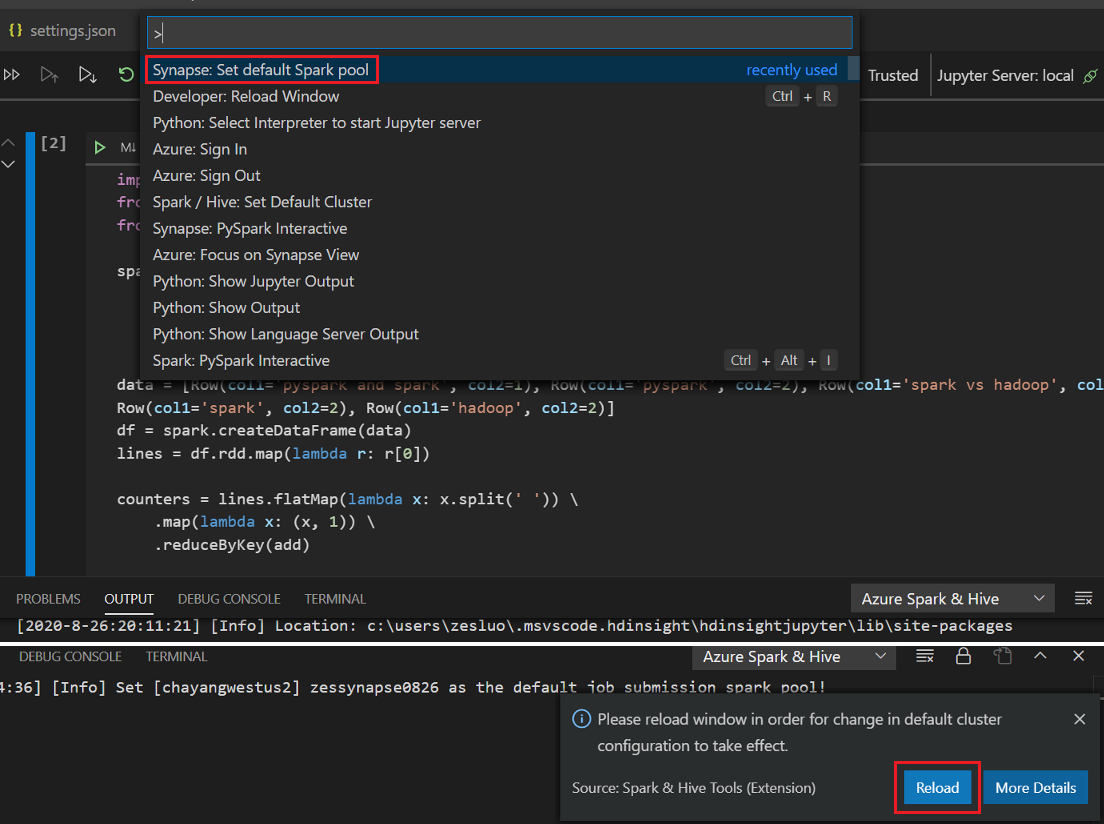
按一下 [PySpark] 將核心切換至 PySpark / Synapse Pyspark,然後按一下 [執行資料格],不久後就會顯示結果。
注意
針對 Synapse PySpark 安裝錯誤,因為其他小組將不再維護其相依性,因此也不會再對此進行維護。 如果您嘗試使用 Synapse Pyspark 互動式,請改用 Azure Synapse Analytics 。 這是一種長期變更。
提交 PySpark 批次工作
HDexample如果已關閉,請重新開啟您稍早討論的資料夾。依照先前的步驟建立新檔案 BatchFile.py。
將下列程式碼複製並貼到該指令檔:
from __future__ import print_function import sys from operator import add from pyspark.sql import SparkSession if __name__ == "__main__": spark = SparkSession\ .builder\ .appName("PythonWordCount")\ .getOrCreate() lines = spark.read.text('/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv').rdd.map(lambda r: r[0]) counts = lines.flatMap(lambda x: x.split(' '))\ .map(lambda x: (x, 1))\ .reduceByKey(add) output = counts.collect() for (word, count) in output: print("%s: %i" % (word, count)) spark.stop()連線至 Azure 帳戶,或連結至叢集 (如果您尚未這樣做)。
以滑鼠右鍵按一下指令碼編輯器,然後選取 [Spark: PySpark Batch] 或 [Synapse: PySpark Batch]*。
選取您 PySpark 作業要提交到的叢集/Spark 集區:
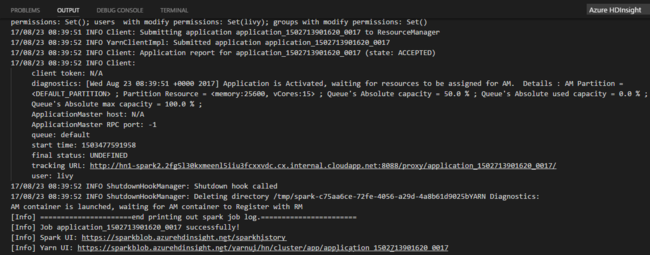
在您提交 Python 作業之後,提交記錄便會出現在 Visual Studio Code 的 [輸出] 視窗中。 此外也會顯示 Spark UI URL 和 Yarn UI URL。 如果您將批次作業提交至 Apache Spark 集區,則也會顯示 Spark 歷程記錄 UI URL 和 Spark 作業應用程式 UI URL。 您可以在網頁瀏覽器中開啟該 URL 來追蹤作業狀態。
與 HDInsight Identity Broker (HIB) 整合
連線至 HDInsight ESP cluster with ID Broker (HIB)
您可以遵循一般步驟來登入 Azure 訂用帳戶,以連線至 HDInsight ESP cluster with ID Broker (HIB)。 登入之後,您將在 Azure Explorer 中看到叢集清單。 如需詳細,請參閱連線至 HDInsight 叢集。
在 HDInsight ESP cluster with ID Broker (HIB) 上執行 Hive/PySpark 作業
若要執行 Hive 作業,您可以遵循一般步驟,將作業提交至 HDInsight ESP cluster with ID Broker (HIB)。 如需更多指示,請參閱提交 interactive Hive 查詢和 Hive batch 指令碼。
若要執行 interactive PySpark 作業,您可以遵循一般步驟,將作業提交至 HDInsight ESP cluster with ID Broker (HIB)。 請參閱「提交 interactive PySpark 查詢」。
若要執行 PySpark batch 作業,您可以遵循一般步驟,將作業提交至 HDInsight ESP cluster with ID Broker (HIB)。 如需更多指示,請參閱提交 PySpark batch 作業。
Apache Livy 設定
支援 Apache Livy 設定。 您可以在工作區資料夾的 VSCode\settings.json 檔案中進行設定。 目前 Livy 設定僅支援 Python 指令碼。 如需詳細資訊,請參閱 Livy 讀我檔案。
方法 1
- 從功能表列,瀏覽至 [檔案]>[喜好設定]>[設定]。
- 在 [搜尋設定] 方塊中,輸入 HDInsight Job Submission: Livy Conf。
- 選取 [在 settings.json 中編輯] 以取得相關的搜尋結果。
方法 2
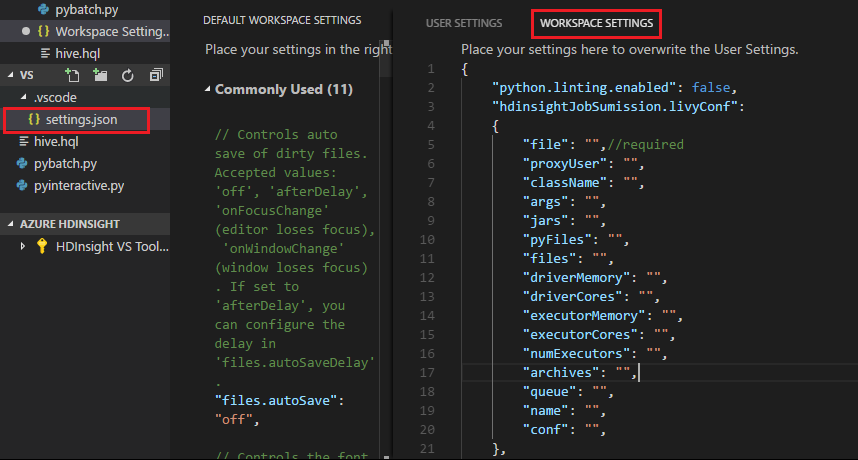
提交檔案。此外請注意,系統會自動將 .vscode 資料夾新增至工作資料夾。 您可以選取 .vscode\settings.json 來查看 Livy 設定。
專案設定:
注意
針對 driverMemory 和 executorMemory 設定,設定值和單位。 例如:1g 或 1024m。
支援的 Livy 設定:
POST/批次
要求本文
名稱 description 類型 file 包含要執行之應用程式的檔案 路徑 (必要) proxyUser 執行作業時要模擬的使用者 String className 應用程式 Java/Spark 主要類別 String args 適用於應用程式的命令列引數 字串清單 jars 要用於此工作階段的 JAR 字串清單 pyFiles 要用於此工作階段的 Python 檔案 字串清單 files 要用於此工作階段的檔案 字串清單 driverMemory 要用於驅動程式程序的記憶體數量 String driverCores 要用於驅動程式程序的核心數目 int executorMemory 要用於每個執行程式程序的記憶體數量 String executorCores 要用於每個執行程式的核心數目 int numExecutors 要針對此工作階段啟動的執行程式數目 int archives 要用於此工作階段的封存 字串清單 queue 要提交至的 YARN 佇列名稱 String NAME 此工作階段的名稱 String conf Spark 設定屬性 key=val 的對應 回應本文建立的 Batch 物件。
NAME description 類型 識別碼 工作階段識別碼 int appId 此工作階段的應用程式識別碼 String appInfo 詳細的應用程式資訊 key=val 的對應 log Log lines 字串清單 state 批次狀態 String 注意
當您提交指令碼時,指派的 Livy 設定會顯示在輸出窗格中。
從總管整合 Azure HDInsight
您可以直接透過 Azure HDInsight 總管預覽叢集中的 Hive 資料表:
連線到 Azure 帳戶 (如果您尚未這樣做)。
從最左邊的資料行選取 Azure 圖示。
從左窗格中,展開 AZURE: HDINSIGHT。 系統會列出可用的訂用帳戶和叢集。
展開叢集以檢視 Hive 中繼資料資料庫和資料表結構描述。
以滑鼠右鍵按一下 Hive 資料表。 例如:hivesampletable。 選取預覽。
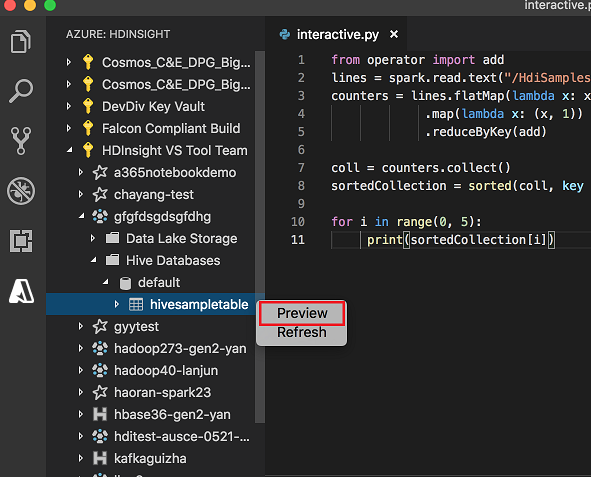
[預覽結果] 視窗隨即開啟:
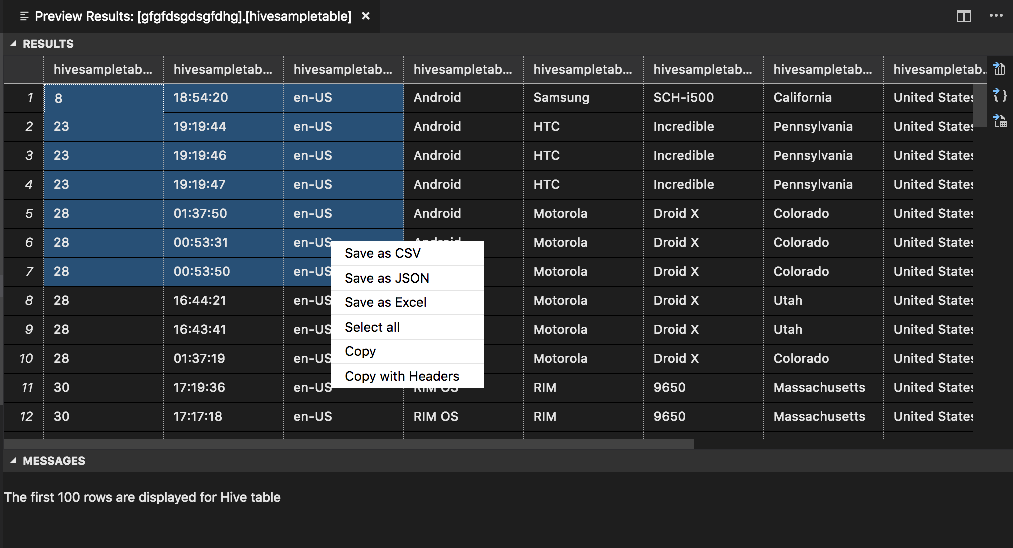
[結果] 面板
您可以將整個結果以 CSV、JSON 或 Excel 檔案的形式儲存到本機路徑,或只選取多行。
[訊息] 面板
當資料表中的資料列數目大於 100 時,您會看到下列訊息:「針對 Hive 資料表顯示前 100 個資料列。」
當資料表中的資料列數目小於或等於 100 時,您會看到下列訊息:「針對 Hive 資料表顯示 60 個資料列。」
當資料表中沒有內容時,您會看到下列訊息:「
0 rows are displayed for Hive table.」注意
在 Linux 中,安裝 xclip 以啟用複製資料表資料。
其他功能
適用於 Visual Studio Code 的 Spark 與 Hive 也支援下列功能:
IntelliSense 自動完成。 關鍵字、方法、變數和其他程式設計元素的建議快顯視窗。 不同圖示代表不同類型的物件:
IntelliSense 錯誤標記。 語言服務會為 Hive 指令碼中的編輯錯誤加上底線。
語法醒目提示。 語言服務會使用不同的色彩來區分變數、關鍵字、資料類型、函式,以及其他程式設計元素:
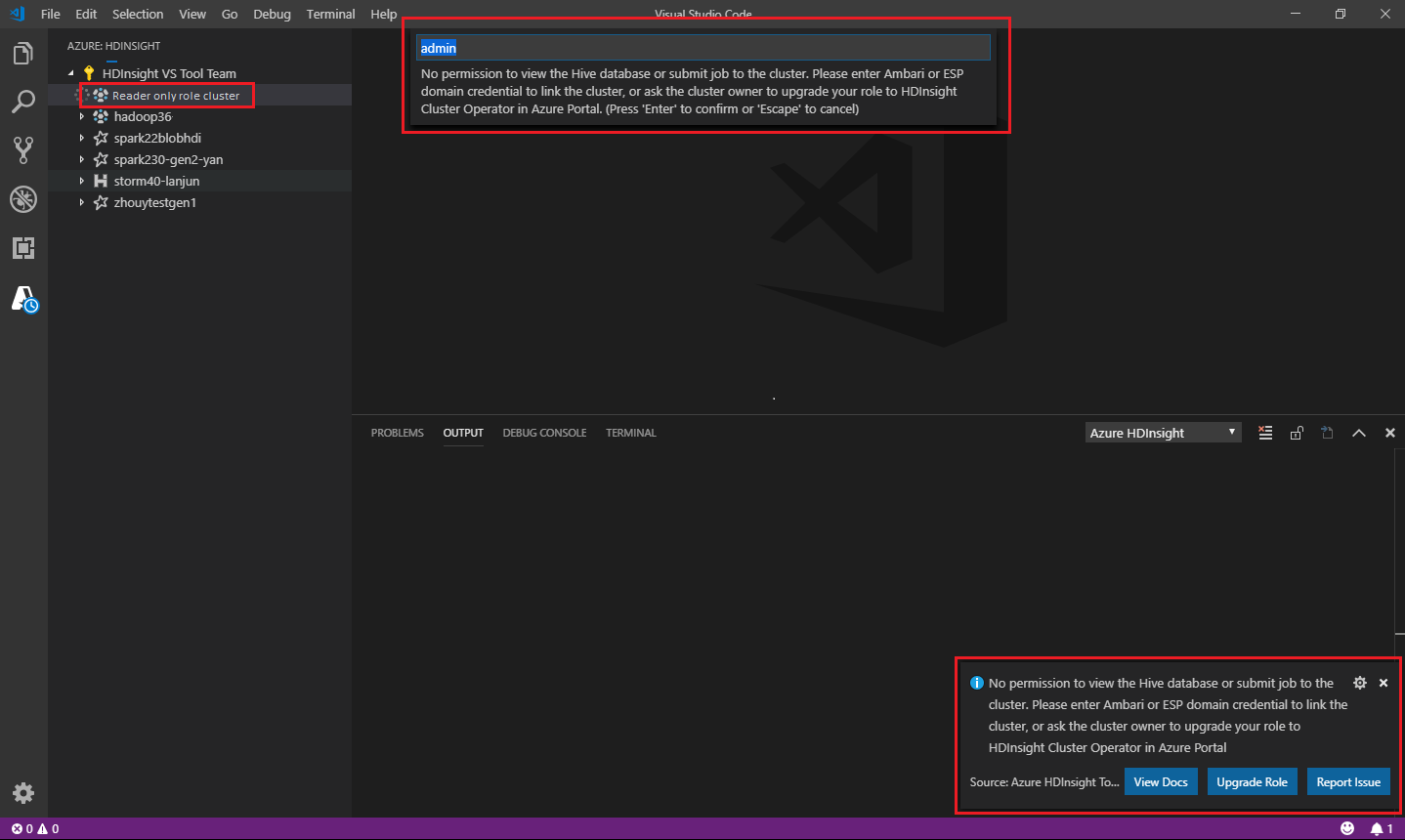
僅限讀取者角色
獲指派叢集唯讀角色的使用者無法將作業提交至 HDInsight 叢集,也無法檢視 Hive 資料庫。 請連絡叢集管理員,將角色升級至 Azure 入口網站中的 HDInsight 叢集操作員。 如果您擁有有效的 Ambari 認證,則可以使用下列指導手動連結叢集。
瀏覽 HDInsight 叢集
當您選取 Azure HDInsight 總管來展開 HDInsight 叢集時,如果您擁有叢集的唯讀角色,系統會提示您連結叢集。 透過使用您的 Ambari 認證,以使用下列方法來連結至叢集。
將作業提交至 HDInsight 叢集
將作業提交至 HDInsight 叢集時,如果您在叢集的唯讀角色中,系統會提示您連結叢集。 透過使用 Ambari 認證,以使用下列步驟來連結至叢集。
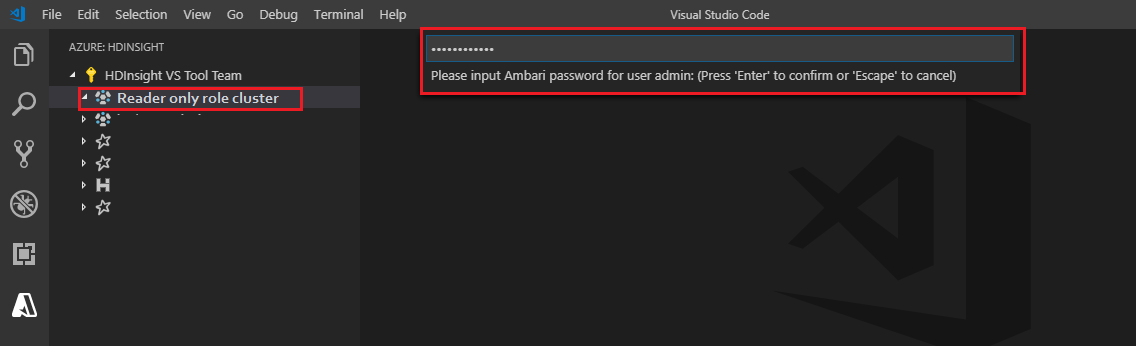
連結至叢集
輸入有效的 Ambari 使用者名稱。
請輸入有效的密碼。
注意
您可以使用
Spark / Hive: List Cluster來檢查連結的叢集:
Azure Data Lake Storage Gen2
瀏覽 Data Lake Storage Gen2 帳戶
選取 Azure HDInsight 總管以展開 Data Lake Storage Gen2 帳戶。 如果您的 Azure 帳戶無法存取 Gen2 儲存體,系統會提示您輸入儲存體存取金鑰。 驗證存取金鑰之後,就會自動展開 Data Lake Storage Gen2 帳戶。
使用 Data Lake Storage Gen2 將作業提交至 HDInsight 叢集
使用 Data Lake Storage Gen2 將作業提交至 HDInsight 叢集。 如果您的 Azure 帳戶沒有 Gen2 儲存體的寫入權限,系統會提示您輸入儲存體存取金鑰。 驗證存取金鑰之後,作業將會成功提交。

注意
您可以從 Azure 入口網站取得儲存體帳戶的存取金鑰。 如需詳細資訊,請參閱管理儲存體帳戶存取金鑰。
將叢集取消連結
從功能表列,瀏覽至 [檢視] > [命令選擇區],然後輸入 Spark / Hive: Unlink a Cluster。
選取要取消連結的叢集。
查看 [輸出] 檢視以確認。
登出
從功能表列中,瀏覽至 [檢視] > [命令選擇區],然後輸入 [Azure:登出]。
已知問題
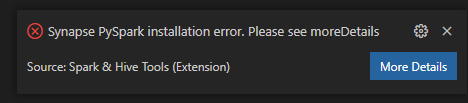
Synapse PySpark 安裝錯誤。
針對 Synapse PySpark 安裝錯誤,因為其他小組將不再維護其相依性,因此將不會再對此進行維護。 如果您嘗試使用 Synapse Pyspark 互動式,請改用 Azure Synapse Analytics 。 這是一種長期變更。
下一步
如需針對 Visual Studio Code 示範使用 Spark 與 Hive 的影片,請參閱適用於 Visual Studio Code 的 Spark 與 Hive。