教學課程 - 使用 Azure HDInsight 中的 Apache HBase
本教學課程示範如何使用 Apache Hive 在 Azure HDInsight 中建立 Apache HBase 叢集、建立 HBase 資料表,以及查詢資料表。 如需一般 HBase 資訊,請參閱 HDInsight HBase 概觀。
在本教學課程中,您會了解如何:
- 建立 Apache HBase 叢集
- 建立 HBase 資料表並插入資料
- 使用 Apache Hive 查詢 Apache HBase
- 使用 Curl 來使用 HBase REST API
- 檢查叢集狀態
必要條件
SSH 用戶端。 如需詳細資訊,請參閱使用 SSH 連線至 HDInsight (Apache Hadoop)。
Bash。 本文中的命令列範例會在 Windows 10 上使用 Bash 殼層執行 curl 命令。 如需安裝步驟,請參閱 Windows 10 適用於 Linux 的 Windows 子系統的安裝指南。 其他 Unix 殼層也可正常運作。 curl 範例只需要略為修改,即可在 Windows 命令提示字元上使用。 或者,您也可以使用 Windows PowerShell Cmdlet Invoke-RestMethod。
建立 Apache HBase 叢集
下列程式會使用 Azure Resource Manager 範本來建立 HBase 叢集。 此範本也會建立相依的預設 Azure 儲存體帳戶。 若要了解此程序與其他叢集建立方法中使用的參數,請參閱 在 HDInsight 中建立以 Linux 為基礎的 Hadoop 叢集。
選取以下影像,在 Azure 入口網站中開啟範本。 範本位於 Azure 快速入門範本中。
![新叢集的 [部署至 Azure] 按鈕](media/apache-hbase-tutorial-get-started-linux/hdi-deploy-to-azure1.png)
從 [自訂部署] 對話方塊中,輸入下列值:
屬性 描述 訂用帳戶 選取用來建立叢集的 Azure 訂用帳戶。 資源群組 建立 Azure 資源管理群組,或使用現有的群組。 Location 指定資源群組的位置。 ClusterName 輸入 HBase 叢集的名稱。 叢集登入名稱和密碼 預設登入名稱為 admin。SSH 使用者名稱和密碼 預設的使用者名稱為 sshuser。其他參數都是選擇性的。
每個叢集都具備 Azure 儲存體帳戶相依性。 刪除叢集之後,資料會留在儲存體帳戶中。 叢集預設儲存體帳戶名稱是附加 "store" 的叢集名稱。 其會硬式編碼在範本變數區段中。
選取 [我同意上方所述的條款及條件],然後選取 [購買]。 大約需要 20 分鐘的時間來建立叢集。
刪除 HBase 叢集之後,您可以使用相同的預設 Blob 容器來建立另一個 HBase 叢集。 這個新叢集會挑選您在原始叢集中建立的 HBase 資料表。 為了避免不一致,建議您在刪除叢集之前,先停用 HBase 資料表。
建立資料表和插入資料
您可以使用 SSH 來連線到 HBase 叢集,然後使用 Apache HBase Shell 來建立 HBase 資料表、插入及查詢資料。
對大多數人而言,資料會以表格形式出現:

在 HBase (實作 Cloud BigTable) 中,相同的資料看起來如下:

使用 HBase Shell
使用
ssh命令來連線至您的 HBase 叢集。CLUSTERNAME取代為您的叢集名稱以編輯下列命令,然後輸入 命令:ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.net使用
hbase shell命令來啟動 HBase 互動式殼層。 在您的 SSH 連線中輸入下列命令:hbase shell使用
create命令建立具有兩個數據行系列的 HBase 數據表。 資料表和資料行名稱會區分大小寫。 輸入下列命令:create 'Contacts', 'Personal', 'Office'使用
list命令來列出 HBase 中的所有資料表。 輸入下列命令:list使用
put命令來將值插入特定資料表中之指定資料列的指定資料行。 輸入下列命令:put 'Contacts', '1000', 'Personal:Name', 'John Dole' put 'Contacts', '1000', 'Personal:Phone', '1-425-000-0001' put 'Contacts', '1000', 'Office:Phone', '1-425-000-0002' put 'Contacts', '1000', 'Office:Address', '1111 San Gabriel Dr.'使用
scan命令來掃描並傳回Contacts資料表資料。 輸入下列命令:scan 'Contacts'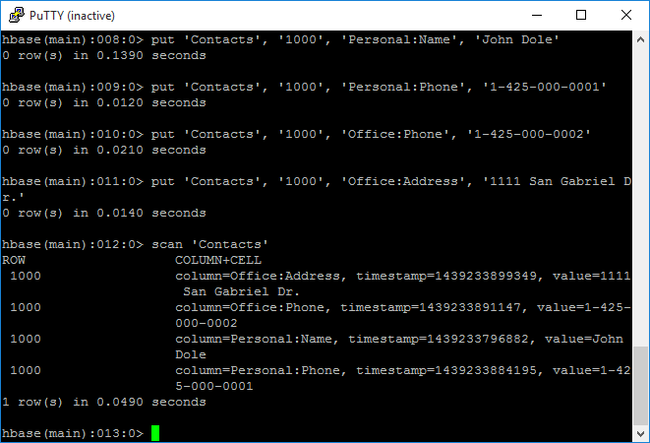
使用
get命令來擷取資料列的內容。 輸入下列命令:get 'Contacts', '1000'您會看到與使用
scan命令類似的結果,因為只有一個資料列。如需 HBase 資料表結構描述的詳細資訊,請參閱 Apache HBase 結構描述設計簡介 \(英文\)。 如需其他 HBase 命令,請參閱 Apache HBase 參考指南 \(英文\)。
使用
exit命令來停止 HBase 互動式殼層。 輸入下列命令:exit
將資料大量載入連絡人 HBase 資料表中
HBase 包含數個將資料載入資料表的方法。 如需詳細資訊,請參閱 大量載入。
您可以在公用 Blob 容器中找到資料檔案範例 (wasb://hbasecontacts@hditutorialdata.blob.core.windows.net/contacts.txt)。 資料檔案的內容:
8396 Calvin Raji 230-555-0191 230-555-0191 5415 San Gabriel Dr.
16600 Karen Wu 646-555-0113 230-555-0192 9265 La Paz
4324 Karl Xie 508-555-0163 230-555-0193 4912 La Vuelta
16891 Jonn Jackson 674-555-0110 230-555-0194 40 Ellis St.
3273 Miguel Miller 397-555-0155 230-555-0195 6696 Anchor Drive
3588 Osa Agbonile 592-555-0152 230-555-0196 1873 Lion Circle
10272 Julia Lee 870-555-0110 230-555-0197 3148 Rose Street
4868 Jose Hayes 599-555-0171 230-555-0198 793 Crawford Street
4761 Caleb Alexander 670-555-0141 230-555-0199 4775 Kentucky Dr.
16443 Terry Chander 998-555-0171 230-555-0200 771 Northridge Drive
您可以選擇性地建立文字檔,並將檔案上載至自己的儲存體帳戶。 如需指示,請參閱在 HDInsight 中將 Apache Hadoop 作業的資料上傳。
此程序使用您在上一個程序中建立的 Contacts 資料表。
從開啟的 SSH 連線執行下列命令,將資料檔案轉換成 StoreFiles,並存放在
Dimporttsv.bulk.output所指定的相對路徑上。hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.columns="HBASE_ROW_KEY,Personal:Name,Personal:Phone,Office:Phone,Office:Address" -Dimporttsv.bulk.output="/example/data/storeDataFileOutput" Contacts wasb://hbasecontacts@hditutorialdata.blob.core.windows.net/contacts.txt執行下列命令,將資料從
/example/data/storeDataFileOutput上傳至 HBase 資料表:hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles /example/data/storeDataFileOutput Contacts您可以開啟 HBase 殼層,並使用
scan命令列出資料表內容。
使用 Apache Hive 查詢 Apache HBase
您可以使用 Apache Hive 查詢 HBase 資料表中的資料。 在本節中,您會建立對應至 HBase 資料表的 Hive 資料表,並用以查詢您 HBase 資料表中的資料。
從開啟的 SSH 連線,使用下列命令啟動 Beeline:
beeline -u 'jdbc:hive2://localhost:10001/;transportMode=http' -n admin如需有關 Beeline 的詳細資訊,請參閱利用 Beeline 搭配使用 Hive 與 HDInsight 中的 Hadoop。
執行下列 HiveQL 指令碼,以建立對應至 HBase 資料表的 Hive 資料表。 在執行此陳述式前,請確定您已使用 HBase 殼層建立本文先前參考的範例資料表。
CREATE EXTERNAL TABLE hbasecontacts(rowkey STRING, name STRING, homephone STRING, officephone STRING, officeaddress STRING) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ('hbase.columns.mapping' = ':key,Personal:Name,Personal:Phone,Office:Phone,Office:Address') TBLPROPERTIES ('hbase.table.name' = 'Contacts');執行下列 HiveQL 指令碼,以查詢 HBase 資料表中的資料:
SELECT count(rowkey) AS rk_count FROM hbasecontacts;若要結束 Beeline,請使用
!exit。若要結束程式 SSH 連線,請使用
exit。
個別的 Hive 和 Hbase 叢集
不需要從 HBase 叢集執行用以存取 HBase 資料的 Hive 查詢。 Hive 隨附的任何叢集 (包括 Spark、Hadoop、HBase 或互動式查詢) 都可用於查詢 HBase 資料,但前提是已完成下列步驟:
- 這兩個叢集都必須連結到相同的虛擬網路和子網路
- 從 HBase 叢集前端節點複製到
/usr/hdp/$(hdp-select --version)/hbase/conf/hbase-site.xmlHive 叢集前端節點和背景工作節點。
安全叢集
您也可使用已啟用 ESP 的 HBase,從 Hive 查詢 HBase 資料:
- 當您遵循多叢集模式時,兩個叢集都必須已啟用 ESP。
- 若要允許 Hive 查詢 HBase 資料,請確定已透過 Hbase Apache Ranger 外掛程式授與
hive使用者存取 HBase 資料的權限。 - 當您使用個別且啟用 ESP 的叢集時,必須將 HBase 叢集前端節點的內容
/etc/hosts附加至/etc/hostsHive 叢集前端節點和背景工作節點。
注意
在調整任一叢集之後,必須再次附加 /etc/hosts
透過 Curl 使用 HBase REST API
透過基本驗證來保護 HBase REST API 的安全。 您應該一律使用安全 HTTP (HTTPS) 提出要求,確保認證安全地傳送至伺服器。
若要在 HDInsight 叢集中啟用 HBase REST API,請將下列自訂啟動指令碼新增至 [指令碼動作] 區段。 您可以在建立叢集時或在建立叢集後新增啟動指令碼。 針對 [節點類型],選取 [區域伺服器] 以確保指令碼只會在 HBase 區域伺服器中執行。 腳本會在區域伺服器上的 8090 埠上啟動 HBase REST Proxy。
#! /bin/bash THIS_MACHINE=`hostname` if [[ $THIS_MACHINE != wn* ]] then printf 'Script to be executed only on worker nodes' exit 0 fi RESULT=`pgrep -f RESTServer` if [[ -z $RESULT ]] then echo "Applying mitigation; starting REST Server" sudo python /usr/lib/python2.7/dist-packages/hdinsight_hbrest/HbaseRestAgent.py else echo "REST server already running" exit 0 fi設定方便使用的環境變數。 將 取代
MYPASSWORD為叢集登入密碼,以編輯下列命令。 將MYCLUSTERNAME取代為您的 HBase 叢集名稱。 然後輸入命令。export PASSWORD='MYPASSWORD' export CLUSTER_NAME=MYCLUSTERNAME使用下列命令列出現有的 HBase 資料表:
curl -u admin:$PASSWORD \ -G https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/使用下列命令建立含兩個資料欄系列的新 HBase 資料表:
curl -u admin:$PASSWORD \ -X PUT "https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Contacts1/schema" \ -H "Accept: application/json" \ -H "Content-Type: application/json" \ -d "{\"@name\":\"Contact1\",\"ColumnSchema\":[{\"name\":\"Personal\"},{\"name\":\"Office\"}]}" \ -v架構是以 JSON 格式提供。
使用下列命令插入一些資料:
curl -u admin:$PASSWORD \ -X PUT "https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Contacts1/false-row-key" \ -H "Accept: application/json" \ -H "Content-Type: application/json" \ -d "{\"Row\":[{\"key\":\"MTAwMA==\",\"Cell\": [{\"column\":\"UGVyc29uYWw6TmFtZQ==\", \"$\":\"Sm9obiBEb2xl\"}]}]}" \ -vBase64 編碼 -d 參數中指定的值。 在下列範例中:
MTAwMA==: 1000
UGVyc29uYWw6TmFtZQ==: Personal: Name
Sm9obiBEb2xl: John Dole
false-row-key 可讓您插入多個 (批次) 值。
使用下列命令取得資料列:
curl -u admin:$PASSWORD \ GET "https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Contacts1/1000" \ -H "Accept: application/json" \ -v
注意
尚不支援掃描叢集端點。
如需 HBase Rest 的詳細資訊,請參閱 Apache HBase 參考指南。
注意
Thrift 不受 HDInsight 中的 HBase 所支援。
當您使用 Curl 或任何其他 REST 與 WebHCat 通訊時,您必須提供 HDInsight 叢集管理員的使用者名稱和密碼來驗證要求。 您也必須在用來將要求傳送至伺服器的統一資源識別項 (URI) 中使用叢集名稱:
curl -u <UserName>:<Password> \
-G https://<ClusterName>.azurehdinsight.net/templeton/v1/status
您應該會收到類似下列的回應:
{"status":"ok","version":"v1"}
檢查叢集狀態
HDInsight 中的 HBase 隨附於 Web UI,以供監視叢集。 使用 Web UI,您可要求關於區域的統計資料或資訊。
存取 HBase 主要 UI
在
https://CLUSTERNAME.azurehdinsight.net登入 Ambari Web UI,其中CLUSTERNAME是您 HBase 叢集的名稱。選取左側功能表中的 [HBase]。
選取頁面頂端的 [快速連結],指向作用中的 Zookeeper 節點連結,然後選取 [HBase Master UI]。 UI 會在另一個瀏覽器索引標籤中開啟:
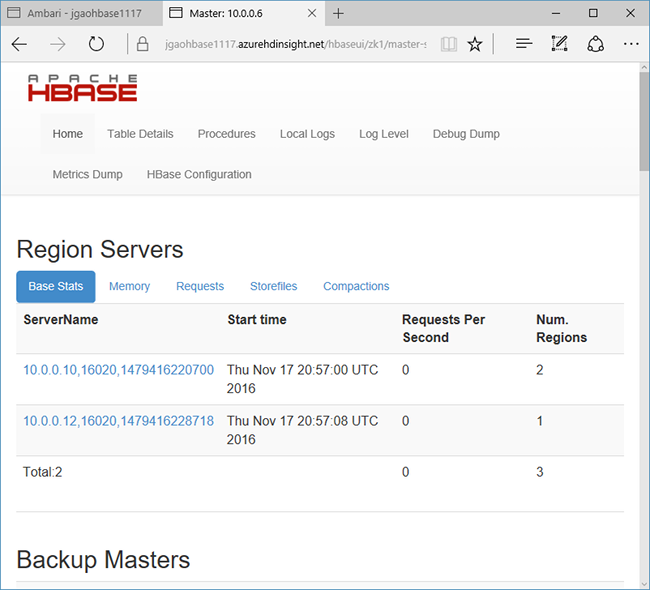
HBase 主要 UI 包含下列區段:
- 區域伺服器
- 備份主機
- 資料表
- 工作
- 軟體屬性
叢集重新建立
刪除 HBase 叢集之後,您可以使用相同的預設 Blob 容器來建立另一個 HBase 叢集。 這個新叢集會挑選您在原始叢集中建立的 HBase 資料表。 但為了避免不一致,建議您在刪除叢集之前,先停用 HBase 資料表。
您可以使用 HBase 命令 disable 'Contacts'。
清除資源
如果您不打算繼續使用此應用程式,請使用下列步驟來刪除所建立的 HBase 叢集:
- 登入 Azure 入口網站。
- 在頂端的 [搜尋] 方塊中,輸入 HDInsight。
- 在 [服務] 底下,選取 [HDInsight 叢集]。
- 從出現的 HDInsight 叢集清單中,在您為本教學課程建立的叢集旁按一下 [...]。
- 按一下刪除。 按一下 [是] 。
下一步
在本教學課程中,您已了解如何建立 Apache HBase 叢集。 以及如何建立資料表,並從 HBase 殼層檢視這些資料表中的資料。 您也已了解如何對 HBase 資料表中的資料使用 Hive 查詢, 以及如何使用 HBase C# REST API 來建立 HBase 數據表,並從數據表擷取數據。 若要深入了解,請參閱: