Express.js應用程式使用 Azure AI 語音將文字轉換成語音
在本教學課程中,使用 Azure AI 語音服務,將 Azure AI 語音新增至現有的 Express.js 應用程式,以使用 Azure AI 語音服務將文字轉換成語音。 將文字轉換成語音可讓您提供音訊,而不需要手動產生音訊的費用。
本教學課程示範從 Azure AI 語音將文字轉換成語音的 3 種不同的方式:
- 用戶端 JavaScript 直接取得音訊
- 伺服器 JavaScript 會從檔案取得音訊 (*.MP3)
- 伺服器 JavaScript 會從記憶體內部 arrayBuffer 取得音訊
應用程式架構
本教學課程採用最少Express.js應用程式,並使用下列組合新增功能:
- 伺服器 API 的新路由,以提供從文字轉換成語音,並傳回 MP3 資料流
- HTML 表單的新路由,可讓您輸入資訊
- 使用 JavaScript 的新 HTML 窗體會提供語音服務的用戶端呼叫
此應用程式提供三個不同的呼叫,可將語音轉換成文字:
- 第一個伺服器呼叫會在伺服器上建立檔案,然後將它傳回給用戶端。 您通常會將此項目用於您知道的文字或文字應該多次提供。
- 第二個伺服器呼叫適用於較短的文字,並在傳回用戶端之前保留在記憶體中。
- 用戶端呼叫會示範使用SDK直接呼叫語音服務。 如果您有不含伺服器的僅限用戶端應用程式,您可以選擇進行此呼叫。
必要條件
Node.js LTS - 安裝到本機電腦。
Visual Studio Code - 安裝到本機電腦。
VS Code 的 Azure App 服務 延伸模組(從 VS Code 內安裝)。
Git - 用來推送至 GitHub - 會啟動 GitHub 動作。
使用 Bash 使用 Azure Cloud Shell

如果想要,請安裝 Azure CLI 以執行 CLI 參考命令。
- 如果您使用本機安裝,請使用 az login 命令以 Azure CLI 登入。 請遵循您終端機上顯示的步驟,完成驗證程序。 如需更多登入選項,請參閱 使用 Azure CLI 登入。
- 出現提示時,請在第一次使用時安裝 Azure CLI 擴充功能。 如需延伸模組詳細資訊,請參閱使用 Azure CLI 延伸模組。
- 執行 az version 以尋找已安裝的版本和相依程式庫。 若要升級至最新版本,請執行 az upgrade。
下載範例Express.js存放庫
使用 git,將Express.js範例存放庫複製到本機計算機。
git clone https://github.com/Azure-Samples/js-e2e-express-server變更為範例的新目錄。
cd js-e2e-express-server在 Visual Studio Code 中開啟專案。
code .在 Visual Studio Code 中開啟新的終端機,並安裝專案相依性。
npm install
安裝適用於 JavaScript 的 Azure AI 語音 SDK
從 Visual Studio Code 終端機安裝 Azure AI 語音 SDK。
npm install microsoft-cognitiveservices-speech-sdk
建立 Express.js 應用程式的語音模組
若要將語音 SDK 整合到Express.js應用程式中,請在名為
azure-cognitiveservices-speech.js的src資料夾中建立檔案。新增下列程式代碼以提取相依性,並建立函式將文字轉換成語音。
// azure-cognitiveservices-speech.js const sdk = require('microsoft-cognitiveservices-speech-sdk'); const { Buffer } = require('buffer'); const { PassThrough } = require('stream'); const fs = require('fs'); /** * Node.js server code to convert text to speech * @returns stream * @param {*} key your resource key * @param {*} region your resource region * @param {*} text text to convert to audio/speech * @param {*} filename optional - best for long text - temp file for converted speech/audio */ const textToSpeech = async (key, region, text, filename)=> { // convert callback function to promise return new Promise((resolve, reject) => { const speechConfig = sdk.SpeechConfig.fromSubscription(key, region); speechConfig.speechSynthesisOutputFormat = 5; // mp3 let audioConfig = null; if (filename) { audioConfig = sdk.AudioConfig.fromAudioFileOutput(filename); } const synthesizer = new sdk.SpeechSynthesizer(speechConfig, audioConfig); synthesizer.speakTextAsync( text, result => { const { audioData } = result; synthesizer.close(); if (filename) { // return stream from file const audioFile = fs.createReadStream(filename); resolve(audioFile); } else { // return stream from memory const bufferStream = new PassThrough(); bufferStream.end(Buffer.from(audioData)); resolve(bufferStream); } }, error => { synthesizer.close(); reject(error); }); }); }; module.exports = { textToSpeech };- 參數 - 檔案會提取相依性,以便使用 SDK、數據流、緩衝區和文件系統 (fs)。 函
textToSpeech式接受四個自變數。 如果傳送具有本機路徑的檔名,文字會轉換成音訊檔案。 如果未傳送檔名,則會建立記憶體內部音訊數據流。 - 語音 SDK 方法 - 語音 SDK 方法 合成器.speakTextAsync 會根據收到的組態傳回不同的類型。
方法會傳回結果,其會根據要求方法執行的動作而有所不同:
- 建立檔案
- 建立記憶體內部數據流作為緩衝區陣列
- 音訊格式 - 選取的音訊格式為 MP3,但其他格式存在,以及其他音訊組態方法。
本機方法 、
textToSpeech會包裝 SDK 回呼函式,並將其轉換成 Promise。- 參數 - 檔案會提取相依性,以便使用 SDK、數據流、緩衝區和文件系統 (fs)。 函
建立Express.js應用程式的新路由
開啟
src/server.js檔案。將
azure-cognitiveservices-speech.js模組新增為檔案頂端的相依性:const { textToSpeech } = require('./azure-cognitiveservices-speech');新增 API 路由,以呼叫 教學課程上一節中建立的 textToSpeech 方法。 在路由之後新增
/api/hello此程序代碼。// creates a temp file on server, the streams to client /* eslint-disable no-unused-vars */ app.get('/text-to-speech', async (req, res, next) => { const { key, region, phrase, file } = req.query; if (!key || !region || !phrase) res.status(404).send('Invalid query string'); let fileName = null; // stream from file or memory if (file && file === true) { fileName = `./temp/stream-from-file-${timeStamp()}.mp3`; } const audioStream = await textToSpeech(key, region, phrase, fileName); res.set({ 'Content-Type': 'audio/mpeg', 'Transfer-Encoding': 'chunked' }); audioStream.pipe(res); });這個方法會從 querystring 取得
textToSpeech方法的必要和選擇性參數。 如果需要建立檔案,則會開發唯一的檔名。 方法textToSpeech會以異步方式呼叫,並將結果傳送至回應 (res) 物件。
使用表單更新用戶端網頁
使用收集必要參數的表單來更新用戶端 HTML 網頁。 選擇性參數會根據用戶選取的音訊控件傳入。 由於本教學課程提供從用戶端呼叫 Azure 語音服務的機制,因此也會提供該 JavaScript。
/public/client.html開啟檔案,並以下列內容取代其內容:
<!DOCTYPE html>
<html lang="en">
<head>
<title>Microsoft Cognitive Services Demo</title>
<meta charset="utf-8" />
</head>
<body>
<div id="content" style="display:none">
<h1 style="font-weight:500;">Microsoft Cognitive Services Speech </h1>
<h2>npm: microsoft-cognitiveservices-speech-sdk</h2>
<table width="100%">
<tr>
<td></td>
<td>
<a href="https://docs.microsoft.com/azure/cognitive-services/speech-service/get-started" target="_blank">Azure
Cognitive Services Speech Documentation</a>
</td>
</tr>
<tr>
<td align="right">Your Speech Resource Key</td>
<td>
<input id="resourceKey" type="text" size="40" placeholder="Your resource key (32 characters)" value=""
onblur="updateSrc()">
</tr>
<tr>
<td align="right">Your Speech Resource region</td>
<td>
<input id="resourceRegion" type="text" size="40" placeholder="Your resource region" value="eastus"
onblur="updateSrc()">
</td>
</tr>
<tr>
<td align="right" valign="top">Input Text (max 255 char)</td>
<td><textarea id="phraseDiv" style="display: inline-block;width:500px;height:50px" maxlength="255"
onblur="updateSrc()">all good men must come to the aid</textarea></td>
</tr>
<tr>
<td align="right">
Stream directly from Azure Cognitive Services
</td>
<td>
<div>
<button id="clientAudioAzure" onclick="getSpeechFromAzure()">Get directly from Azure</button>
</div>
</td>
</tr>
<tr>
<td align="right">
Stream audio from file on server</td>
<td>
<audio id="serverAudioFile" controls preload="none" onerror="DisplayError()">
</audio>
</td>
</tr>
<tr>
<td align="right">Stream audio from buffer on server</td>
<td>
<audio id="serverAudioStream" controls preload="none" onerror="DisplayError()">
</audio>
</td>
</tr>
</table>
</div>
<!-- Speech SDK reference sdk. -->
<script
src="https://cdn.jsdelivr.net/npm/microsoft-cognitiveservices-speech-sdk@latest/distrib/browser/microsoft.cognitiveservices.speech.sdk.bundle-min.js">
</script>
<!-- Speech SDK USAGE -->
<script>
// status fields and start button in UI
var phraseDiv;
var resultDiv;
// subscription key and region for speech services.
var resourceKey = null;
var resourceRegion = "eastus";
var authorizationToken;
var SpeechSDK;
var synthesizer;
var phrase = "all good men must come to the aid"
var queryString = null;
var audioType = "audio/mpeg";
var serverSrc = "/text-to-speech";
document.getElementById('serverAudioStream').disabled = true;
document.getElementById('serverAudioFile').disabled = true;
document.getElementById('clientAudioAzure').disabled = true;
// update src URL query string for Express.js server
function updateSrc() {
// input values
resourceKey = document.getElementById('resourceKey').value.trim();
resourceRegion = document.getElementById('resourceRegion').value.trim();
phrase = document.getElementById('phraseDiv').value.trim();
// server control - by file
var serverAudioFileControl = document.getElementById('serverAudioFile');
queryString += `%file=true`;
const fileQueryString = `file=true®ion=${resourceRegion}&key=${resourceKey}&phrase=${phrase}`;
serverAudioFileControl.src = `${serverSrc}?${fileQueryString}`;
console.log(serverAudioFileControl.src)
serverAudioFileControl.type = "audio/mpeg";
serverAudioFileControl.disabled = false;
// server control - by stream
var serverAudioStreamControl = document.getElementById('serverAudioStream');
const streamQueryString = `region=${resourceRegion}&key=${resourceKey}&phrase=${phrase}`;
serverAudioStreamControl.src = `${serverSrc}?${streamQueryString}`;
console.log(serverAudioStreamControl.src)
serverAudioStreamControl.type = "audio/mpeg";
serverAudioStreamControl.disabled = false;
// client control
var clientAudioAzureControl = document.getElementById('clientAudioAzure');
clientAudioAzureControl.disabled = false;
}
function DisplayError(error) {
window.alert(JSON.stringify(error));
}
// Client-side request directly to Azure Cognitive Services
function getSpeechFromAzure() {
// authorization for Speech service
var speechConfig = SpeechSDK.SpeechConfig.fromSubscription(resourceKey, resourceRegion);
// new Speech object
synthesizer = new SpeechSDK.SpeechSynthesizer(speechConfig);
synthesizer.speakTextAsync(
phrase,
function (result) {
// Success function
// display status
if (result.reason === SpeechSDK.ResultReason.SynthesizingAudioCompleted) {
// load client-side audio control from Azure response
audioElement = document.getElementById("clientAudioAzure");
const blob = new Blob([result.audioData], { type: "audio/mpeg" });
const url = window.URL.createObjectURL(blob);
} else if (result.reason === SpeechSDK.ResultReason.Canceled) {
// display Error
throw (result.errorDetails);
}
// clean up
synthesizer.close();
synthesizer = undefined;
},
function (err) {
// Error function
throw (err);
audioElement = document.getElementById("audioControl");
audioElement.disabled = true;
// clean up
synthesizer.close();
synthesizer = undefined;
});
}
// Initialization
document.addEventListener("DOMContentLoaded", function () {
var clientAudioAzureControl = document.getElementById("clientAudioAzure");
var resultDiv = document.getElementById("resultDiv");
resourceKey = document.getElementById('resourceKey').value;
resourceRegion = document.getElementById('resourceRegion').value;
phrase = document.getElementById('phraseDiv').value;
if (!!window.SpeechSDK) {
SpeechSDK = window.SpeechSDK;
clientAudioAzure.disabled = false;
document.getElementById('content').style.display = 'block';
}
});
</script>
</body>
</html>
檔案中反白顯示的行:
- 第 74 行:Azure 語音 SDK 會使用
cdn.jsdelivr.net月臺傳遞 NPM 套件,提取到客戶端連結庫。 - 第 102 行:方法
updateSrc會使用查詢字串來更新音訊控件的srcURL,包括索引鍵、區域和文字。 - 第 137 行:如果使用者選取
Get directly from Azure按鈕,網頁會直接從用戶端頁面呼叫 Azure 並處理結果。
建立 Azure AI 語音資源
在 Azure Cloud Shell 中使用 Azure CLI 命令建立語音資源。
登入 Azure Cloud Shell。 這需要您在瀏覽器中使用具有有效 Azure 訂用帳戶許可權的帳戶進行驗證。
為您的語音資源建立資源群組。
az group create \ --location eastus \ --name tutorial-resource-group-eastus在資源群組中建立語音資源。
az cognitiveservices account create \ --kind SpeechServices \ --location eastus \ --name tutorial-speech \ --resource-group tutorial-resource-group-eastus \ --sku F0如果您唯一的免費語音資源已建立,此命令將會失敗。
使用 命令來取得新語音資源的索引鍵值。
az cognitiveservices account keys list \ --name tutorial-speech \ --resource-group tutorial-resource-group-eastus \ --output table複製其中一個金鑰。
您可以將金鑰貼到 Express 應用程式的 Web 表單中,以向 Azure 語音服務進行驗證,以使用金鑰。
執行Express.js應用程式,將文字轉換成語音
使用下列bash命令啟動應用程式。
npm start在瀏覽器中開啟 Web 應用程式。
http://localhost:3000將您的語音鍵貼到醒目提示的文字框中。
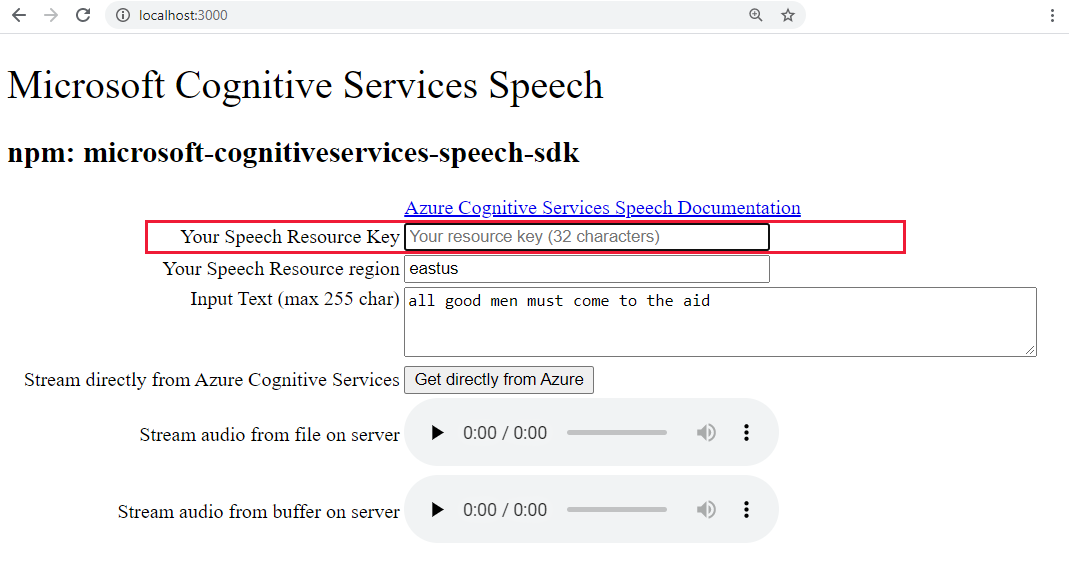
或者,將文字變更為新的內容。
選取三個按鈕之一,開始轉換成音訊格式:
- 直接從 Azure 取得 - 對 Azure 的用戶端呼叫
- 來自檔案的音訊控件
- 來自緩衝區音訊的音訊控件
您可能會注意到選取控件與音訊播放之間的輕微延遲。
在 Visual Studio Code 中建立新的 Azure App Service
從命令選擇區 (Ctrl+Shift+P), 輸入 “create web”,然後選取 [Azure App 服務:建立新的 Web 應用程式...進階。 您可以使用進階命令完全控制部署,包括資源群組、App Service 方案和作業系統,而不是使用 Linux 預設值。
如下所示地回應提示:
- 選取您的訂用帳戶。
- 針對 [輸入全域唯一名稱 ],例如
my-text-to-speech-app。- 輸入所有 Azure 中唯一的名稱。 只使用英數位元 ('A-Z'、'a-z' 和 '0-9') 和連字元 ('-')
- 選取
tutorial-resource-group-eastus資源群組。 - 選取包含
Node和LTS的版本運行時間堆疊。 - 選取 Linux 作業系統。
- 選取 [建立新的 App Service 方案],提供類似
my-text-to-speech-app-plan的名稱。 - 選取 F1 免費定價層。 如果您的訂用帳戶已經有免費的 Web 應用程式,請選取階層
Basic。 - 針對 Application Insights 資源選取 [暫時略過]。
eastus選取位置。
不久之後,Visual Studio Code 會通知您建立已完成。 使用 [X ] 按鈕關閉通知。
在 Visual Studio Code 中將本機Express.js應用程式部署至遠端 App Service
使用 Web 應用程式就地,從本機電腦部署您的程式代碼。 選取 Azure 圖示以開啟 Azure App 服務 總管、展開您的訂用帳戶節點、以滑鼠右鍵按兩下您剛才建立的 Web 應用程式名稱,然後選取 [部署至 Web 應用程式]。
如果有部署提示,請選取Express.js應用程式的根資料夾,再次選取您的 訂 用帳戶帳戶,然後選取稍早建立的 Web 應用程式
my-text-to-speech-app名稱。如果系統提示您在部署至 Linux 時執行
npm install,如果系統提示您更新組態以在目標伺服器上執行npm install,請選取 [是]。
部署完成後,請在提示中選取 [瀏覽網站 ],以檢視您剛部署的 Web 應用程式。
(選擇性):您可以變更程式碼檔案,然後使用 Azure App Service 延伸模組中的 [部署至 Web 應用程式] 來更新 Web 應用程式。
在 Visual Studio Code 中串流遠端服務記錄
檢視執行中應用程式透過呼叫 console.log所產生的任何輸出。 此輸出會出現在 Visual Studio Code 的 [輸出 ] 視窗中。
在 Azure App 服務 總管中,以滑鼠右鍵按下新的應用程式節點,然後選擇 [啟動串流記錄]。
Starting Live Log Stream ---
在瀏覽器中重新整理網頁幾次,以查看其他記錄輸出。
拿掉資源群組以清除資源
完成本教學課程之後,您必須移除包含資源的資源群組,以確保您不會再支付使用量的費用。
在 Azure Cloud Shell 中,使用 Azure CLI 命令 來刪除資源群組:
az group delete --name tutorial-resource-group-eastus -y
此命令可能需要幾分鐘的時間。