串流數據表的運作方式
串流數據表是一般 Delta 數據表,可額外支援串流或累加數據處理。
串流數據表是數據擷取的絕佳選擇,原因如下:
- 每個輸入數據行只會處理一次,這樣可模擬絕大多數資料擷取工作負載(也就是說,藉由將數據行附加或更新插入到數據表中)。
- 它們可以處理大量只能附加的資料。
串流數據表也是低延遲串流轉換的絕佳選擇,原因如下:
- 數據列和時間範圍的原因
- 處理大量數據
- 低延遲
下圖說明串流數據表的運作方式。
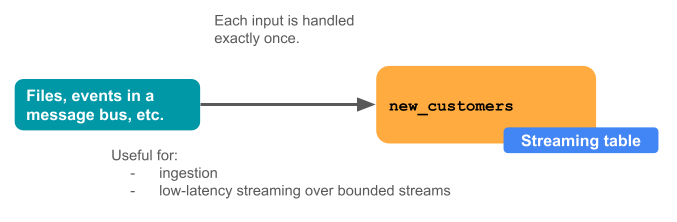
串流數據表是由單一 Delta Live Tables 管線所定義和更新。 當您建立 Delta Live Tables 管線時,您可以在管線的原始碼中明確定義串流數據表。 這些數據表接著由這個管線定義,無法由任何其他管線變更或更新。 當您在 Databricks SQL 中建立串流數據表時,Databricks 會建立用來更新此數據表的 Delta Live Tables 管線。
串流數據表以進行擷取
串流數據表是專為僅附加數據源所設計,且只會處理輸入一次。
完整重新整理可讓串流數據表重新處理已處理的數據。 完整重新整理動作會讓串流數據表重新處理所有輸入,包括先前已處理過的輸入。
下列範例示範如何使用串流數據表從雲端記憶體擷取新的檔案。 當您在數據集定義中使用一或多個 spark.readStream 調用時,它會導致 Delta Live Tables 將數據集視為串流數據表,而不是具體化檢視。
import dlt
@dlt.table
def raw_customers():
return (
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.load("/Volumes/path/to/files")
)
下圖說明僅附加串流數據表的運作方式。
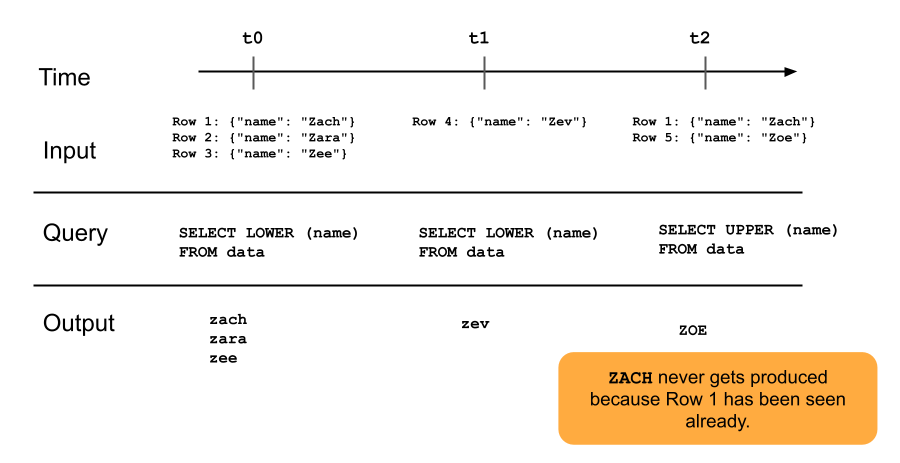
串流數據表和低延遲串流
串流數據表是針對透過限定狀態進行低延遲串流所設計。 串流數據表會使用 RocksDB 進行檢查點管理,使其非常適合低延遲串流。 不過,它們預期自然受限或受限於水印的數據流。
自然系結數據流是由具有妥善定義開始和結束的串流數據源所產生。 自然系結數據流的範例是從檔案目錄讀取數據,其中在放置初始檔案批次之後,不會新增任何新檔案。 數據流會被視為限定,因為檔案數目有限,然後,數據流會在處理所有檔案之後結束。
您也可以使用水印來綁定資料流。 Spark 結構化串流中的浮水印是一種機制,可藉由指定系統應該等候延遲事件的時間長度,再將時間範圍視為完成,來協助處理延遲數據。 沒有水印的無界數據流可能會導致 Delta Live Tables 管道因為記憶體壓力而失敗。
串流快照集聯結
串流快照集聯結是數據流與數據流啟動時快照集的維度之間的聯結。 如果維度在數據流啟動之後變更,這些聯結不會重新計算,因為維度數據表會被視為時間快照集,而且除非重載或重新整理維度數據表,否則數據流開始之後維度數據表的變更不會反映。 如果您接受聯結中的小差異,這樣的行為是合理的。 例如,當交易數目的大小比客戶數目大許多個數量級時,可以接受近似聯結。
在下列程式代碼範例中,我們將一個包含兩條記錄的維度表「客戶」與不斷增加的數據集「交易」進行聯結。 我們將這兩個數據集之間的聯結具體化為名為 sales_report的數據表。 請注意,如果外部進程藉由新增數據列來更新客戶數據表(customer_id=3, name=Zoya),這個新數據列將不會出現在聯結中,因為當數據流啟動時,靜態維度數據表已快照集。
import dlt
@dlt.view
# assume this table contains an append-only stream of rows about transactions
# (customer_id=1, value=100)
# (customer_id=2, value=150)
# (customer_id=3, value=299)
# ... <and so on> ...
def v_transactions():
return spark.readStream.table("transactions")
# assume this table contains only these two rows about customers
# (customer_id=1, name=Bilal)
# (customer_id=2, name=Olga)
@dlt.view
def v_customers():
return spark.read.table("customers")
@dlt.table
def sales_report():
facts = spark.readStream.table("v_transactions")
dims = spark.read.table("v_customers")
return (
facts.join(dims, on="customer_id", how="inner"
)
串流數據表限制
串流資料表有下列限制:
- 有限的演進: 您可以變更查詢,而不需重新計算整個數據集。 由於串流數據表只會看到一次數據列,因此您可以在不同的數據列上執行不同的查詢。 這表示您必須注意數據集上執行的所有舊版查詢。 需要完整重新整理,才能讓串流數據表看到已再次看到的數據。
- 狀態管理: 串流數據表是低延遲的,因此您必須確保其運作的數據流自然系結或系結於浮水印。
- 聯結不會重新計算: 不同於具體化檢視,其結果一律正確,因為它們會自動重新計算,串流數據表中的聯結不會在維度變更時重新計算。 此特性適用於「快速但錯誤的」案例。