Delta tables 的運作方式
在 Databricks 中,所有新的 tables 預設都會被建立為 Delta tables。 Delta table 會將資料儲存為雲端物件記憶體中的檔案目錄,並將 table元數據註冊至 catalog 內的中繼存放區,並 schema。 所有的 Unity Catalog 管理的 tables 和串流的 tables 都是 Delta tables。
Delta tables 包含可使用 SQL、Python 和 Scala APIs 查詢和更新的資料列。 Delta tables 以開放原始碼 Delta Lake 格式儲存元數據。 身為使用者,您可以像在資料庫中處理 tables 一樣,處理這些 tables——您可以 insert、update、刪除和合併數據。 Databricks 會負責以支援有效率作業的方式儲存和組織數據。 由於數據是以開放式 Delta Lake 格式儲存,因此您可以讀取數據,並從 Databricks 以外的許多其他產品加以寫入。
雖然可以在不使用 Delta Lake 的 Databricks 上建立 tables,但這些 tables 不提供 Delta tables的交易性保障或優化效能。 如需使用 Delta Lake 以外格式之其他 table 類型的詳細資訊,請參閱 什麼是 table?。
下列範例程式碼會從 NYC 計程車車程的範例數據集中建立一個名為 "table" 的 Delta 表,並篩選出費用大於 $10 的數據列。 當在 samples.nyctaxi.trips中新增或更新資料列時,此 table 不會被更新。
filtered_df = (
spark.read.table("samples.nyctaxi.trips")
.filter(col("fare_amount") > 10.0)
)
filtered_df.write.saveAsTable("catalog.schema.filtered_taxi_trips")
您現在可以使用 SQL 或 Python 等語言來查詢此 Delta table。
差異 tables 和一般 views
在 Unity Catalog中,視圖是對一個或多個 tables 和 views 進行查詢的結果。 您可以在多個架構中,從 tables 和其他 views 建立檢視,並 catalogs。
一般檢視是每次查詢檢視時都會重新計算其結果的查詢。 檢視的主要優點在於,它可以隱藏查詢的複雜性,因為使用者可以像查詢常規 table那樣查詢檢視。 不過,由於每次查詢執行時一般 views 都會被重新計算,因此對於處理大量數據的複雜查詢而言,這可能導致較高的成本。
下圖顯示一般 views 的運作方式。
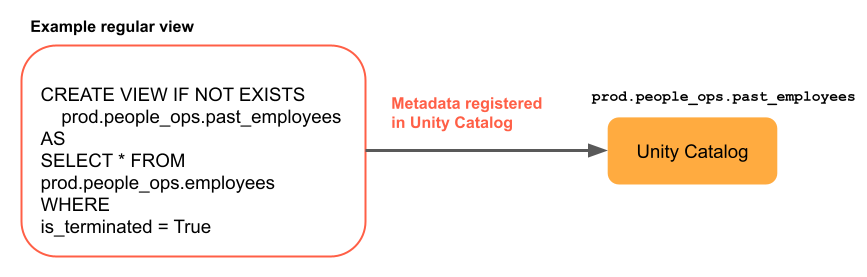
下列範例程式代碼會從範例 NYC 計程車車程數據集建立一般檢視,並篩選為包含大於 $10 費用的數據列。 即使已在 中新增數據列或現有數據列更新 samples.nyctaxi.trips,此檢視一律會傳回正確的結果:
filtered_df = (
spark.read.table("samples.nyctaxi.trips")
.filter(col("fare_amount") > 10.0)
)
filtered_df.write.createOrReplaceTempView("catalog.schema.v_filtered_taxi_trips")
您現在可以使用 SQL 或 Python 等語言來查詢此一般檢視。