如何建置簡單、有效率且低延遲的數據管線
現今的數據驅動企業會持續產生數據,這需要持續內嵌和轉換此數據的工程數據管線。 這些管線應該能夠處理和傳遞數據一次,產生延遲少於 200 毫秒的結果,並一律嘗試將成本降至最低。
本文說明工程數據管線的批次和增量串流處理方法、為什麼累加串流處理是更好的選項,以及開始使用 Databricks 累加數據流處理供應專案的後續步驟、Azure Databricks 上的串流處理 和 什麼是 DLT?。 這些功能可讓您快速撰寫和執行管線,以確保傳遞語意、延遲、成本等等。
重複批次作業的陷阱
設定資料管線時,您一開始可能會撰寫重複的批次作業來導入您的資料。 例如,每小時您可以執行一個 Spark 作業,從來源讀取,並將數據寫入到像是 Delta Lake 的接收中。 這種方法的挑戰是以累加方式處理您的來源,因為每小時執行的Spark作業必須從最後一個作業結束的地方開始。 您可以記錄所處理資料的最新時間戳,然後選取時間戳比該時間戳還新的所有數據列,但有陷阱:
若要執行連續資料管線,您可以嘗試排定每小時批次作業,以逐步的方式從來源讀取資料,進行轉換,並將結果寫入接收端,例如 Delta Lake。 這種方法可能會有陷阱:
- 在時間戳之後查詢所有新數據的 Spark 作業將會遺漏延遲數據。
- 如果未小心處理,失敗的 Spark 作業可能會導致破壞完全一次性保證。
- 列出要尋找新檔案之雲端儲存位置內容的 Spark 作業會變得昂貴。
您仍然需要重複轉換此資料。 您可以撰寫重複的批次作業,以匯總您的數據或套用其他作業,進一步使管線效率複雜化並降低。
批次範例
若要完整瞭解批次資料擷取和轉換過程中的陷阱,請考慮以下範例。
遺漏的數據
假設有一個包含使用數據的 Kafka 主題,您可以藉此來決定向客戶收取多少費用,而您的管線是以批次匯入的方式操作,則事件的順序可能如下所示:
- 您的第一批在上午8點和8點30分有兩筆記錄。
- 您將最新的時間戳更新為上午 8:30。
- 你在上午8點15分得到另一個記錄。
- 第二批會在上午 8:30 之後查詢所有專案,因此您在上午 8:15錯過記錄。
此外,您不想對使用者收費過高或過低,因此您必須確保每筆記錄僅被處理一次。
冗餘處理
接下來,假設您的數據包含使用者購買的數據列,而您想要匯總每小時的銷售量,讓您知道市集中最受歡迎的時間。 如果同一小時的購買訂單以不同的批次抵達,這樣的話就會有多個批次在同一小時產生輸出。
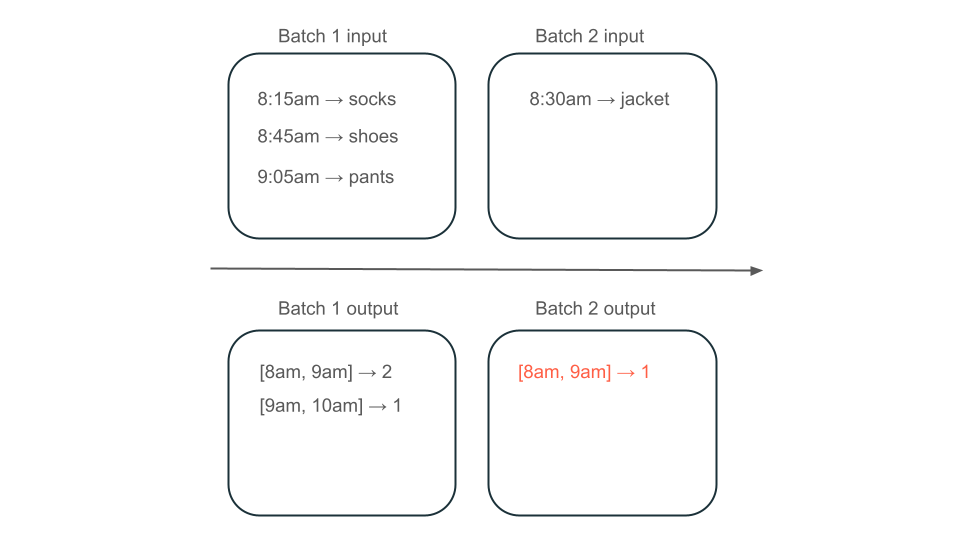
上午 8 點到上午 9 點的視窗是否有兩個元素(第 1 批的輸出)、一個元素(第 2 批的輸出),還是三個元素(沒有批次的輸出)? 產生指定時間範圍所需的數據會出現在多個轉換批次中。 若要解決此問題,您可以每天分割數據,並在需要計算結果時重新處理整個分割區。 然後,您可以覆寫您的匯集結果:
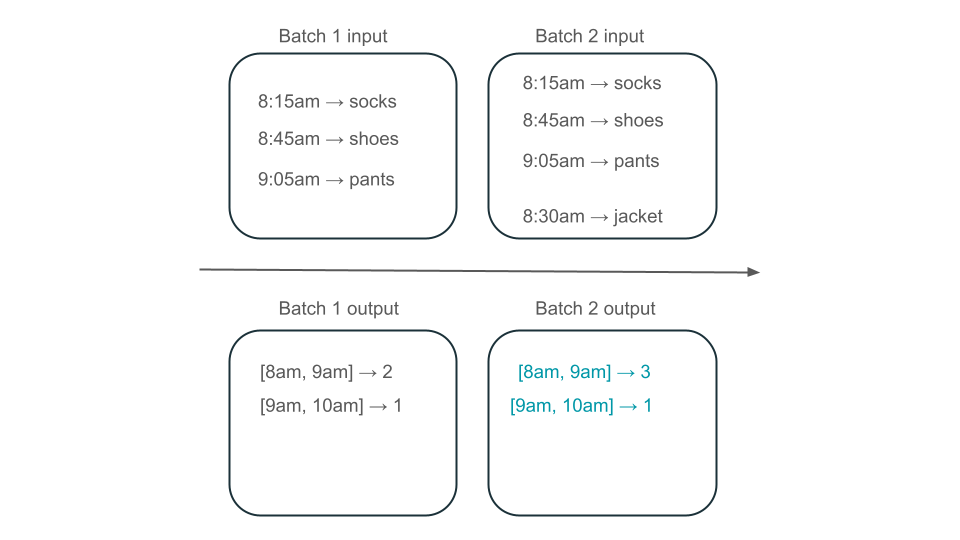
不過,這會犧牲延遲的效率和資源成本,因為第二個批次可能需要進行已經處理的數據的多餘工作。
漸進式流處理無任何陷阱
增量流處理可以讓您輕鬆避免重複批次作業在接收和轉換數據時的所有陷阱。 Databricks 結構化串流 和 DLT 管理串流實作複雜度,讓您只專注於商業規則。 您只需要指定要連線的來源、應該對資料執行哪些轉換,以及寫入結果的位置。
增量擷取
Databricks 中的漸進式擷取是由 Apache Spark 結構化串流驅動,能漸進地擷取數據源並將其寫入目的地。 結構化串流引擎可以完全取用數據一次,而且引擎可以處理順序錯亂的數據。 引擎可以在筆記本中執行,或使用 DLT 中的串流數據表。
Databricks 上的結構化串流引擎提供專屬串流來源,例如 AutoLoader,其可以以符合成本效益的方式累加處理雲端檔案。 Databricks 也為其他熱門訊息總線提供連接器,例如 Apache Kafka、Amazon Kinesis、Apache Pulsar,以及 Google Pub/Sub。
逐步轉化
在 Databricks 中使用結構化串流的增量轉換,讓您以與批次查詢相同的 API 來指定 DataFrame 的轉換,同時自動追蹤各批次的數據和隨時間累加的匯總值,讓您無需手動處理。 它永遠不需要重新處理數據,因此比重複的批次作業更快且更具成本效益。 結構化串流會生成可附加到資料儲存端的資料串流,例如 Delta Lake、Kafka 或其他任何支援的連接器。
DLT 中的實體化視圖 由 Enzyme 引擎提供動力。 Enzyme 仍然逐步增量地處理您的來源,但與其產生數據流,而是建立 物化視圖,這是預先計算的數據表,可儲存您給予的查詢結果。 酶能夠有效率地判斷新數據如何影響查詢的結果,並將預先計算的數據表保持在 up-to日期。
具體化視圖會針對您的匯總建立一個視圖,能夠持續且有效率地自我更新,例如,在上述案例中,您知道上午 8 點到 9 點的窗口有三個元素。
結構化串流或 DLT?
結構化串流和 DLT 之間的顯著差異在於您運作串流查詢的方式。 在 [結構化串流] 中,您可以手動指定許多組態,而且您必須手動將查詢拼湊在一起。 您必須明確啟動查詢、等待查詢終止、在失敗時取消查詢,以及其他動作。 在 DLT 中,您以宣告的方式提供管線予 DLT 執行,並保持它們持續運行。
DLT 也有 具體化檢視等功能,可有效率且累加地預先計算數據的轉換。
如需這些功能的詳細資訊,請參閱 在 Azure Databricks 上的串流 和 什麼是 DLT?。
後續步驟
- 使用 DLT 建立您的第一個管線。 請參閱 教學:運行您的第一個 DLT 資料管道。
- 在 Databricks 上執行您的第一個結構化串流查詢。 參見 運行首次結構化串流工作負載。
- 使用具體化檢視。 請參閱 在 Databricks SQL中使用具體化檢視。